









之前有基于igb来分析page reuse,现在再基于ixgbe(kernel 6.2)分析一遍,顺便解析一下ixgbe的网卡收包函数 ixgbe_clean_rx_irq。这一次会有一些新的内容。
目录
1 next_to_use 和 next_to_clean的初始化
1 next_to_use 和 next_to_clean的初始化
ixgbe_setup_rx_resources中有初始化next_to_use和next_to_clean为0。之后会在调用ixgbe_configure_rx_ring函数时,第一次执行ixgbe_alloc_rx_buffers函数。精简如下:
ixgbe_alloc_rx_buffers(ring, ixgbe_desc_unused(ring));
==> ixgbe_alloc_rx_buffers(ring, ring->count - 1);/**
* ixgbe_alloc_rx_buffers - Replace used receive buffers
* @rx_ring: ring to place buffers on
* @cleaned_count: number of buffers to replace
**/
void ixgbe_alloc_rx_buffers(struct ixgbe_ring *rx_ring, u16 cleaned_count)
{
union ixgbe_adv_rx_desc *rx_desc;
struct ixgbe_rx_buffer *bi;
u16 i = rx_ring->next_to_use; //0
u16 bufsz;
/* nothing to do */
if (!cleaned_count)
return;
rx_desc = IXGBE_RX_DESC(rx_ring, i);
bi = &rx_ring->rx_buffer_info[i];
//i = 0 - rx_ring->count
i -= rx_ring->count;
bufsz = ixgbe_rx_bufsz(rx_ring);
do {
//第一次,需要alloc page,填充rx_buffer_info
if (!ixgbe_alloc_mapped_page(rx_ring, bi))
break;
/* sync the buffer for use by the device */
dma_sync_single_range_for_device(rx_ring->dev, bi->dma,
bi->page_offset, bufsz,
DMA_FROM_DEVICE);
/*
* Refresh the desc even if buffer_addrs didn't change
* because each write-back erases this info.
*/
rx_desc->read.pkt_addr = cpu_to_le64(bi->dma + bi->page_offset);
rx_desc++;
bi++;
i++;
//初始化第一次执行这个函数,不会执行到这里
if (unlikely(!i)) {
rx_desc = IXGBE_RX_DESC(rx_ring, 0);
bi = rx_ring->rx_buffer_info;
i -= rx_ring->count;
}
/* clear the length for the next_to_use descriptor */
rx_desc->wb.upper.length = 0;
cleaned_count--;
} while (cleaned_count);//rx_ring->count - 1
//把之前减掉的再加上
i += rx_ring->count;
//0 != 1023
if (rx_ring->next_to_use != i) {
rx_ring->next_to_use = i; //1023
/* update next to alloc since we have filled the ring */
rx_ring->next_to_alloc = i; 1023
/* Force memory writes to complete before letting h/w
* know there are new descriptors to fetch. (Only
* applicable for weak-ordered memory model archs,
* such as IA-64).
*/
wmb();
writel(i, rx_ring->tail);
}
}
static bool ixgbe_alloc_mapped_page(struct ixgbe_ring *rx_ring,
struct ixgbe_rx_buffer *bi)
{
struct page *page = bi->page;
dma_addr_t dma;
/* since we are recycling buffers we should seldom need to alloc */
if (likely(page))
return true;
/* alloc new page for storage */
//这里要计算order,进而确定alloc的页面大小,比如涉及jumbo的话,就需要分配更大的页面
page = dev_alloc_pages(ixgbe_rx_pg_order(rx_ring));
if (unlikely(!page)) {
rx_ring->rx_stats.alloc_rx_page_failed++;
return false;
}
/* map page for use */
dma = dma_map_page_attrs(rx_ring->dev, page, 0,
ixgbe_rx_pg_size(rx_ring),
DMA_FROM_DEVICE,
IXGBE_RX_DMA_ATTR);
/*
* if mapping failed free memory back to system since
* there isn't much point in holding memory we can't use
*/
if (dma_mapping_error(rx_ring->dev, dma)) {
__free_pages(page, ixgbe_rx_pg_order(rx_ring));
rx_ring->rx_stats.alloc_rx_page_failed++;
return false;
}
bi->dma = dma;
bi->page = page;
bi->page_offset = rx_ring->rx_offset;
//强制增加 USHRT_MAX - 1 页的引用计数,但忽略组合页。USHRT_MAX = unsigned short类型的最大值 = 65535
page_ref_add(page, USHRT_MAX - 1);
bi->pagecnt_bias = USHRT_MAX;
rx_ring->rx_stats.alloc_rx_page++;
return true;
}
从上面的code可以知道next_to_use = next_to_alloc = rx_ring->count -1,而next_to_clean仍然为0。 如下图所示,
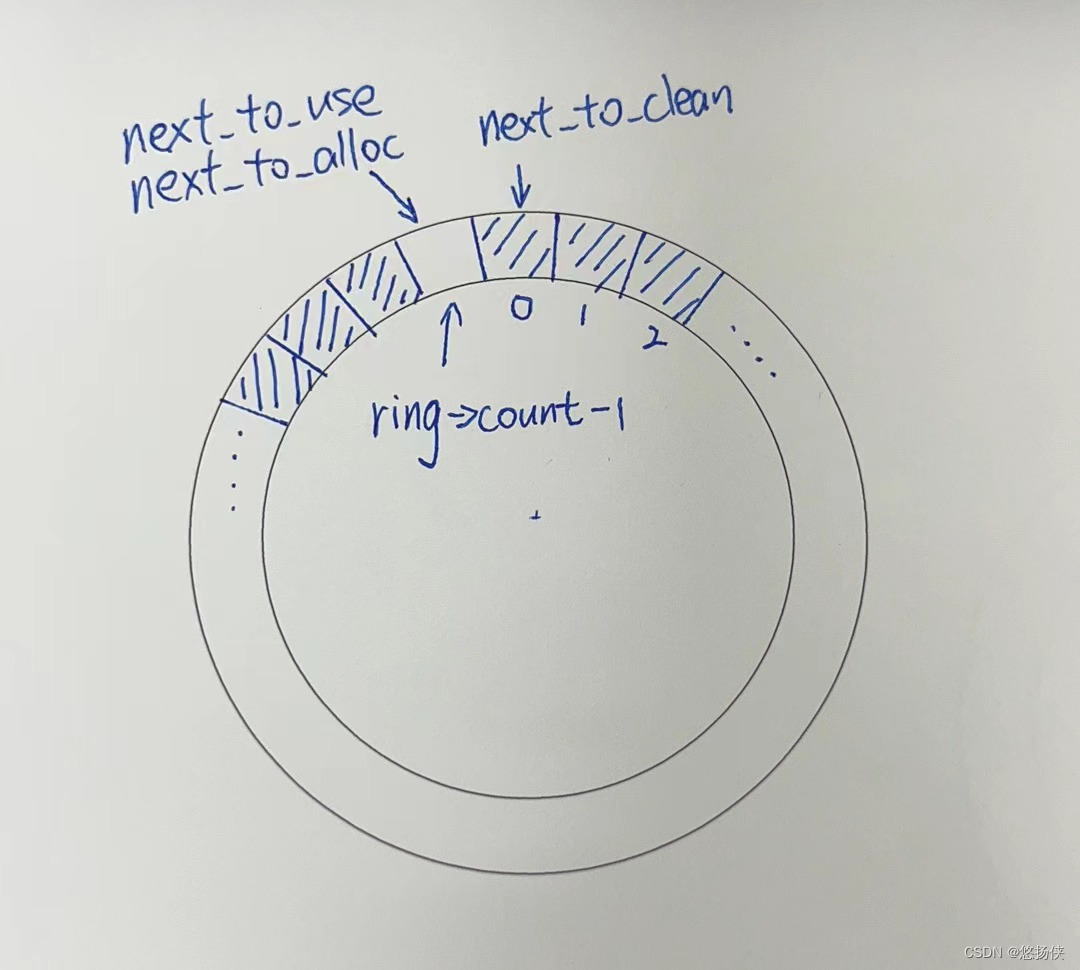
2 什么是page reuse?
对于函数ixgbe_clean_rx_irq的介绍,这次就提到了bounce buf。
This function provides a "bounce buffer" approach to Rx interrupt processing. The advantage to this is that on systems that have expensive overhead for IOMMU access this provides a means of avoiding it by maintaining the mapping of the page to the syste.
我对这部分的理解是这样的:
假设原先是每一次收包都需要拿一张新的A4纸来使用,CPU就需要不停地“拿”纸。而使用page reuse就好比你一次性拿了一列A3纸来,每次只用半面,也就是一个A4。用完之后,就需要bounce,bounce之后把没用的那一面A4放到这一列的末尾。这样就不需要不停地“拿”,CPU不就“省事”了吗?
好了,下面我们要开始收包和page reuse了
3 ixgbe_clean_rx_irq
首先是一些变量的定义和初始化,其中要注意cleaned_count。
u16 cleaned_count = ixgbe_desc_unused(rx_ring);
static inline u16 ixgbe_desc_unused(struct ixgbe_ring *ring)
{
u16 ntc = ring->next_to_clean;
u16 ntu = ring->next_to_use;
return ((ntc > ntu) ? 0 : ring->count) + ntc - ntu - 1;
}然后进入while循环,首先检查cleaned_count 是否大于等于 IXGBE_RX_BUFFER_WRITE,如果是的话那代表可以使用的desc的数目不够了,那么就需要重新执行ixgbe_alloc_rx_buffers。
/* return some buffers to hardware, one at a time is too slow */
if (cleaned_count >= IXGBE_RX_BUFFER_WRITE) {
ixgbe_alloc_rx_buffers(rx_ring, cleaned_count);
cleaned_count = 0;
}现在不看Descriptor Done Bit了,直接看packet length,之后dma_sync_single_range_for_cpu还能使用到。
rx_desc = IXGBE_RX_DESC(rx_ring, rx_ring->next_to_clean);
size = le16_to_cpu(rx_desc->wb.upper.length);
if (!size)
break;接下来ixgbe_get_rx_buffer赋值了rx_buffer、skb,sync this buffer for CPU use。这里额外关注一下*rx_buffer_pgcnt = page_count(rx_buffer->page),因为前面强制增加了USHRT_MAX - 1 页的引用计数,所以正常值为USHRT_MAX 。还有就是rx_buffer->pagecnt_bias--,在自减后,值为USHRT_MAX - 1。这是page reuse更新的一个方面,在后面都会用到。
rx_buffer = ixgbe_get_rx_buffer(rx_ring, rx_desc, &skb, size, &rx_buffer_pgcnt);紧接着,按照正常的流程走,那就是ixgbe_add_rx_frag。该函数会将rx_buffer->page中包含的数据添加到skb中。 如果缓冲区中的数据小于 skb header大小,则通过直接复制来完成,否则它只会将页面作为frag附加到 skb。另外,它还会更新page offset。这也就是我们之前说的bounce。
ixgbe_add_rx_frag(rx_ring, rx_buffer, skb, size);接下来就是page reuse的重头戏了,函数ixgbe_put_rx_buffer。ixgbe_can_reuse_rx_page需要做两次判断,看是否可以reuse。这里的第二次判断如下:
#if (PAGE_SIZE < 8192)
/* if we are only owner of page we can reuse it */
if (unlikely((rx_buffer_pgcnt - pagecnt_bias) > 1))
return false;
#else
/* The last offset is a bit aggressive in that we assume the
* worst case of FCoE being enabled and using a 3K buffer.
* However this should have minimal impact as the 1K extra is
* still less than one buffer in size.
*/
#define IXGBE_LAST_OFFSET \
(SKB_WITH_OVERHEAD(PAGE_SIZE) - IXGBE_RXBUFFER_3K)
if (rx_buffer->page_offset > IXGBE_LAST_OFFSET)
return false;
#endif这里就用到了之前所提到的rx_buffer_pgcnt和rx_buffer->pagecnt_bias,通过比较这两个数的差值,可以看到是否“we are only owner of page”,只有满足这个条件才可以reuse page。这一条件是对以前的判定的一种改进,采用了local variable的做法,而不是always在global做atomic。
接下来,执行reuse的函数,这里看着就很简单,因为很多工作在之前已经做完了,现在更像是单纯的赋值。这里还往前推动了next_to_alloc。
/**
* ixgbe_reuse_rx_page - page flip buffer and store it back on the ring
* @rx_ring: rx descriptor ring to store buffers on
* @old_buff: donor buffer to have page reused
*
* Synchronizes page for reuse by the adapter
**/
static void ixgbe_reuse_rx_page(struct ixgbe_ring *rx_ring,
struct ixgbe_rx_buffer *old_buff)
{
struct ixgbe_rx_buffer *new_buff;
u16 nta = rx_ring->next_to_alloc;
new_buff = &rx_ring->rx_buffer_info[nta];
/* update, and store next to alloc */
nta++;
rx_ring->next_to_alloc = (nta < rx_ring->count) ? nta : 0;
/* Transfer page from old buffer to new buffer.
* Move each member individually to avoid possible store
* forwarding stalls and unnecessary copy of skb.
*/
new_buff->dma = old_buff->dma;
new_buff->page = old_buff->page;
new_buff->page_offset = old_buff->page_offset;
new_buff->pagecnt_bias = old_buff->pagecnt_bias;
}接下来一句,cleaned_count++,这是用于在多次执行循环后,推进next_to_use。
cleaned_count++;ixgbe_is_non_eop更新了next_to_clean。EOP即End of packet,如果缓冲区是 EOP 缓冲区,则此函数退出并返回 false,否则它将把 sk_buff 放入下一个要链接的缓冲区并返回 true,表明这实际上是一个非 EOP 缓冲区。如果返回的是true,那就continue,立刻开始下一次循环,否则继续执行。
/* place incomplete frames back on ring for completion */
if (ixgbe_is_non_eop(rx_ring, rx_desc, skb))
continue;接下来的ixgbe_cleanup_headers和ixgbe_process_skb_fields都没什么,最后执行gro合并入口函数napi_gro_receive,一次循环结束。在执行完所有循环后,函数也就执行完毕了。
同样地,本文通过图示来演示一下整个函数的执行过程。
4 流程分析
最开始的情况,如下,在上面已经展示过一次。
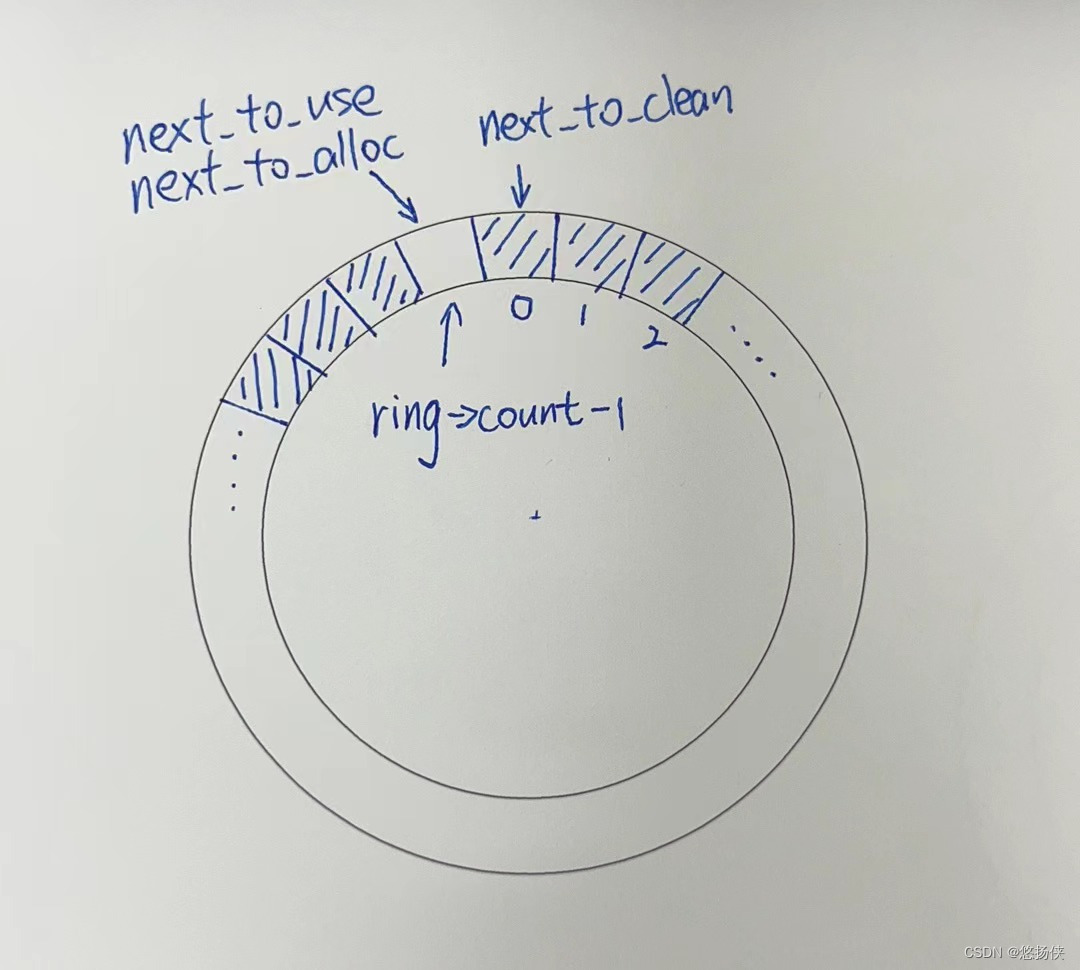
第一次循环
一开始next_to_clean = 0,取了desc 0,随后进入函数ixgbe_get_rx_buffer,被赋值,
的 pagecnt_bias = USHRT_MAX -1。
随后调用函数ixgbe_add_rx_frag,这里翻转了rx_buffer->page_offset。
在判断can reuse page之后,开始reuse page,这时next_to_alloc朝前推进一个,next_to_alloc = 0。把的反面给到了
。
的 pagecnt_bias = USHRT_MAX -1。
然后开始判断是否是EOP,这里假设不是,那么next_to_clean = 1,重新开始循环。
第二次循环
next_to_clean = 1,取了desc 1,随后进入函数ixgbe_get_rx_buffer,被赋值,
的 pagecnt_bias = USHRT_MAX -1。
随后调用函数ixgbe_add_rx_frag,这里翻转了rx_buffer->page_offset。
在判断can reuse page之后,开始reuse page,这时next_to_alloc朝前推进一个,next_to_alloc = 1。把的反面给到了
。
的 pagecnt_bias = USHRT_MAX -1。
然后开始判断是否是EOP,这里假设是,那么结束。
什么时候cleaned_count >= IXGBE_RX_BUFFER_WRITE,这时候才会推进next_to_use的值。
5 总结语
这篇文章其实是对上一篇文章的一个补充,因为随着驱动版本的升级,总会有一些优化的内容,所以额外分析一下,也是一次复习。
如果觉得这篇文章有用的话,可以点赞、评论或者收藏,万分感谢,goodbye~

















 2529
2529

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









