







Requests is an elegant and simple HTTP library for Python, built for human beings.
Python requests是最常用的Python第三方库之一,可用于发送HTTP请求,其采用了直观的API设计风格,使用起来非常简单方便。
Requests库是出自于大神 Kenneth Reitz 之手,我之前看过他写的《Python编程之美》,这本书可以让我们编写的代码更Pythonic,工程结构更加优美。Requests库的源码地址在:Github psf/requests,将其源码下载到本地之后,打开工程我们会发现其工程结构和代码规范都非常的优美,而且代码的核心逻辑也非常简洁,特别适合刚开始尝试阅读源码的同学学习。今天这篇文章就对Python requests库进行一个简单的源码分析。
1. 简单实例
首先,我们还是先用requests库编写一个简单的入门实例,然后再从实例作为入口深入分析其源码。
>>> import requests
>>> url = 'https://api.github.com/repos/psf/requests'
>>> r = requests.get(url)
>>> r.ok
True
>>> r.json()['description']
'A simple, yet elegant HTTP library.'
>>>
Requests库将常用的HTTP操作在api层进行了封装,我们可以非常方便地发起get/post/put/delete/head等操作,如果我们的应用场景比较复杂,也可以直接使用其内部对象进行定制化开发。
2. 核心流程
下图呈现了我们上面实例中get请求的核心时序流程,这里将一些非关键的步骤给忽略掉了,有兴趣的话可以自己去细读源码。接下来我们逐层解析时序图中涉及到的对象和流程。
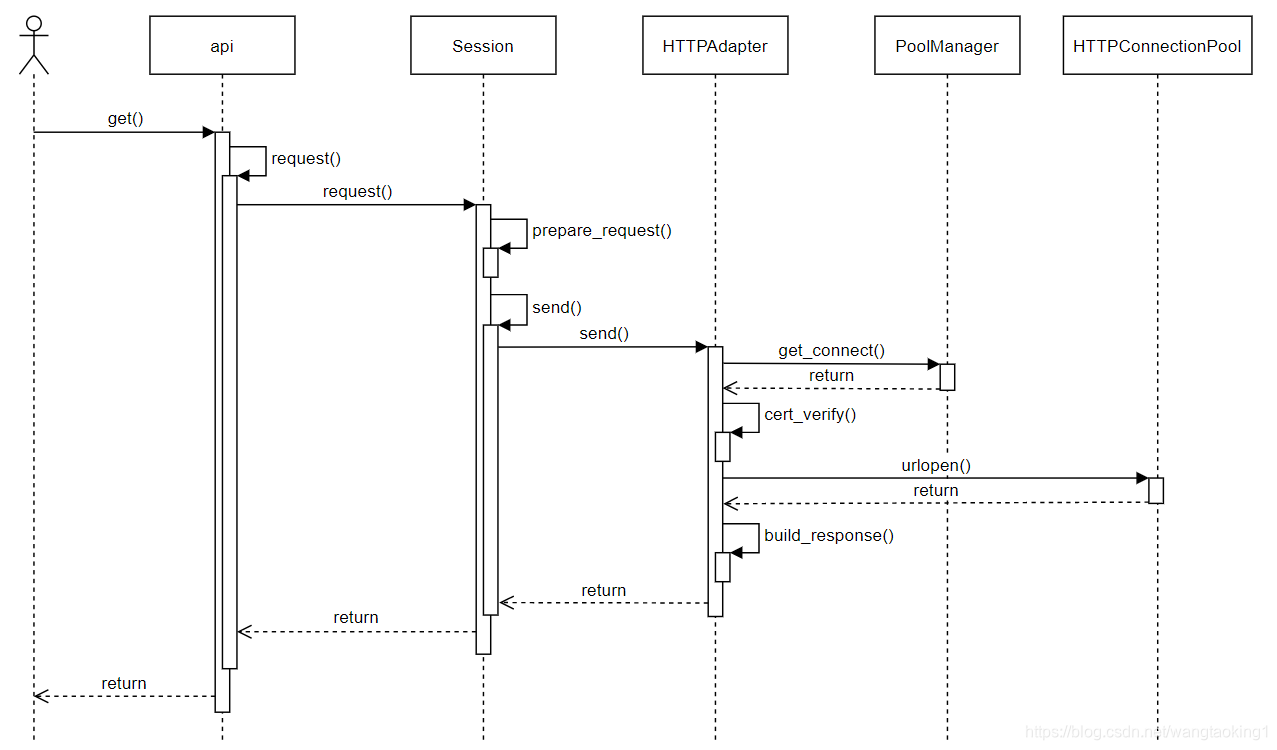
首先是api层,requests库的api模块中封装了 get, post, options, head, put, delete等方法,我们可以直接调用这几个方法发起HTTP请求,这些方法中都调用了request()方法,request方法的代码如下,这里实例化了一个Session对象,然后调用了Session对象的request方法发起请求。
def request(method, url, **kwargs):
with sessions.Session() as session:
return session.request(method=method, url=url, **kwargs)
3. Session
Session对象可用于保存请求的状态,比如证书、cookies、proxy等信息,可实现在多个请求之间保持长连接。如果我们是直接使用的api层的方法发起的请求,那么在请求结束之后,所有的状态都会被清理掉。如果我们需要频繁向服务端发起请求,那么使用Session实现长连接可以大大提升处理性能。
Session类中维护了多个HTTPAdpater对象,分别用于处理不同scheme的请求,代码如下,我们也可以通过Session.mount()方法设置我们自定义的HTTPAdapter,比如根据要求重新设置重试次数等等。
class Session(SessionRedirectMixin):
def __init__(self):
......
self.adapters = OrderedDict()
self.mount('https://', HTTPAdapter())
self.mount('http://', HTTPAdapter())
Session类继承自SessionRedirectMixin类,SessionRedirectMixin类中实现了用于进行HTTP重定向的能力,这块就不细看了。
我们来看Session对象的request()方法,该方法主要用于发送请求,方法中首先调用了prepare_request()方法将一些请求数据提前封装到了一个PreparedRequest对象中,然后在后面请求的过程中都是使用的该对象。PreparedRequest对象中将请求的method, url, header, cookie, body等数据进行了预处理。
class PreparedRequest(...):
......
def prepare(self,
method=None, url=None, headers=None, files=None, data=None,
params=None, auth=None, cookies=None, hooks=None, json=None):
self.prepare_method(method)
self.prepare_url(url, params)
self.prepare_headers(headers)
self.prepare_cookies(cookies)
self.prepare_body(data, files, json)
self.prepare_auth(auth, url)
self.prepare_hooks(hooks)
回到request方法中,下一步会将该request对象和一些请求配置信息一起通过调用Session.send()方法将请求发送出去。send方法的逻辑比较简单,就是先获取对应的HTTPAdapter,然后调用adapter的send方法发起请求,最后收到应答之后再判断是否要进行重定向。方法中包含了很多非关键代码,这里就不贴源码了。
4. HTTPAdapter
接下来看HTTPAdapter类,之前讲了Session对象主要是用来保存请求的状态的,其实HTTPAdapter才是实际用于发送请求的组件。
我们看HTTPAdapter类的构建方法可以知道,Adapter中主要维护了三个对象,max_retries用于请求重试,proxy_manager用于维护与proxy的连接,poolmanager属性维护了一个连接池PoolManager对象。我们在创建HTTPAdapter的时候可以指定连接池的大小和请求最大重试次数。
这里之所以使用连接池,是为了对连接到相同服务端的请求的连接进行复用,我们知道在一次请求过程中,TCP连接的建立和断开是非常耗时的,如果能够把建立连接这一步省掉那将会大大提升请求性能。连接池的细节我们在下一小节再详细解析。
def send(self, request, ...):
conn = self.get_connection(request.url, proxies)
self.cert_verify(conn, request.url, verify, cert)
resp = conn.urlopen(...)
return self.build_response(request, resp)
接下来我们来看HTTPAdapter类的send方法,该方法的代码比较长,清除掉其他非核心代码,主要包括以下四步,代码如上。
- 首先是调用
get_connection()方法从proxy_manager或者poolmanager中获取到连接,这里代码中用的虽然是connection变量名,但是实际上这里获取的是一个连接池HTTPConnectionPool对象,具体使用的是哪个连接发送请求其实是在连接池HTTPConnectionPool中去自动选择的。这里如果有使用proxy,那么这里就是获取的连接到proxy的一个连接池。 - 然后下一步就是调用
cert_verify()方法将TLS证书设置到连接中去,如果使用HTTPS的话。 - 接下来就是调用连接池HTTPConnectionPool的
urlopen()方法,获取一个连接,发送请求,获取响应,这里获取到的响应还是urllib3库中的原生response对象。 - 最后一步是调用
build_response()方法将urllib3库中的原生response对象封装为requests库中的Response对象。
5. PoolManager
PoolManager对象是urllib3库中的成员,requests库直接在HTTPAdapater类中封装了urllib3库的组件实现了连接池。我们这里对PoolManager对象进行一个简单的解析。
PoolManager中维护了若干个连接池HTTPConnectionPool或者HTTPSConnectionPool,每个连接池又维护了若干条Connection,这里默认的大小是10个连接池,每个连接池10条连接,但是我们可以在创建PoolManager的时候自行指定。
PoolManager中针对具有scheme、host、port三个属性相同的请求使用同一个连接池,每个连接池维护了一个连接队列,当获取连接时会优先从队列中获取一条现成的连接,如果没有现成的则新创建一条连接,连接使用完成之后会再次添加回队列中,以便后续可以继续使用。
6. 优秀工程实践
其实requests库除了代码非常优美值得我们学习之外,其使用到的工程实践也是值得我们在自己的项目中学习借鉴的。
Requests项目的主目录下除了requests目录用于放置源码外,还包含了docs目录存放文档的网页源码,一个项目除了源码,清晰准确的文档也是非常重要的。在tests目录下存放的是在编码过程中同步编写的测试用例,另外主目录下还有CI脚本,每次往项目中集成新代码时都会执行CI,自动运行测试用例,保证新合入代码未破坏之前的功能。另外主目录下还有HISTORY文件,用于详细记录每个版本的变更内容,方便版本发布,另外还有项目依赖包文件、README等。
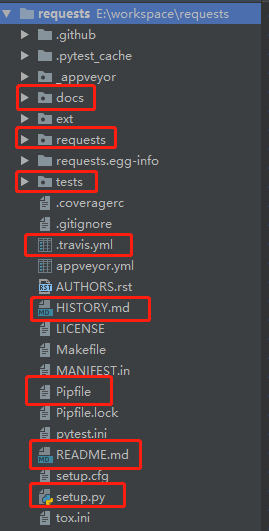
Requests库的代码组织结构也是值得学习的,模块根据功能组织,清晰明确。另外__version__模块存放了项目的版本相关信息,在__init__中将api层的接口方法以及一些核心模型直接暴露出去,这样对于使用者使用起来会更加的方便。
7. 总结
这篇文章从源码的核心流程以及工程实践对Python requests库进行了基本的解析,如果想进一步学习其中优美的地方可以自己深度阅读源码。我觉得requests库在Python开发者中之所以这么受欢迎,最主要的原因就是其功能简洁并稳定,接口使用非常方便,另外其清晰的文档也起到了很重要的作用。















 2966
2966











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









