







编程总结
在刷题之前需要反复练习的编程技巧,尤其是手写各类数据结构实现,它们好比就是全真教的上乘武功
本专栏是之前日刻一诗的提升与进阶,是在已经掌握了基本的方法之后,需要考虑性能等因素
哈希表(Hash Table,也叫散列表),是根据键(Key)而直接访问在内存存储位置的数据结构。哈希表通过计算一个关于键值的函数,将所需查询的数据映射到表中一个位置来访问记录,这加快了查找速度。这个映射函数称做哈希函数,存放记录的数组称做哈希表。
参考官方网址:https://troydhanson.github.io/uthash/userguide.html
#include “uthash.h” 提供的函数
1. UT_hash_handle hh hh是内部使用的hash处理句柄
#include "uthash.h"
struct my_struct *users = NULL; /* important! initialize to NULL */
struct my_struct {
int id; /* key */
char name[10];
UT_hash_handle hh; /* makes this structure hashable */
};
2. HASH_FIND_INT
查找键值接口,对应的是int 整型的键值key
HASH_FIND_INT(head, key_ptr, item_ptr)
void find(int ikey)
{
struct my_struct *s;
HASH_FIND_INT(g_users, &ikey, s );
return s;
}
3. HASH_ADD_INT
插入键值的接口,对应的是int 整型的键值key,HASH_ADD_INT(head, keyfield_name, item_ptr) 键值插入到hash表中,HASH_ADD_INT(g_users, key, s );
/* 这里必须明确告诉插入函数,自己定义的hash结构体中键变量的名字 */
void add_user(int user_id, char *name) {
struct my_struct *s;
HASH_FIND_INT(users, &user_id, s); /* id already in the hash? */
if (s == NULL) {
s = (struct my_struct *)malloc(sizeof *s);
s->id = user_id;
HASH_ADD_INT(users, id, s); /* id: name of key field */
}
strcpy(s->name, name);
}
4. HASH_DEL
删除hash键值的接口
HASH_DEL(head, item_ptr)
需要告诉该接口要释放哪个hash表(这里是g_users)里的哪个节点(这里是s), 删除之前可以先通过键值查找一下对应的hash元素。
void delete_user(struct my_struct *user) {
HASH_DEL(users, user); /* user: pointer to deletee */
free(user); /* optional; it's up to you! */
}
void delete_all() {
struct my_struct *current_user, *tmp;
HASH_ITER(hh, users, current_user, tmp) {
HASH_DEL(users, current_user); /* delete; users advances to next */
free(current_user); /* optional- if you want to free */
}
}
5. HASH_COUNT
统计hash表中的已经存在的元素数
unsigned int num_users;
num_users = HASH_COUNT(users);
printf("there are %u users\n", num_users);
6. HASH_ITER
遍历得到的元素存放在current_user变量中
用于依次删除元素,或者打印所有元素
HASH_ITER(hh, *hashSet1, tmp, it)
{
if (find(hashSet2, tmp->key))
{
retArr[*returnSize] = tmp->key;
(*returnSize)++;
}
}
7. HASH_SORT
int by_name(const struct my_struct *a, const struct my_struct *b) {
return strcmp(a->name, b->name);
}
int by_id(const struct my_struct *a, const struct my_struct *b) {
return (a->id - b->id);
}
void sort_by_name() {
HASH_SORT(users, by_name);
}
void sort_by_id() {
HASH_SORT(users, by_id);
}
8. HASH_FIND
struct my_struct *find_user(int user_id)
{
struct my_struct *s;
HASH_FIND_INT(users, &user_id, s); /* s: output pointer */
return s;
}
9. PRINT
void print_users()
{
struct my_struct *s;
for (s = users; s != NULL; s = s->hh.next) {
printf("user id %d: name %s\n", s->id, s->name);
}
}
#include <stdio.h> /* printf */
#include <stdlib.h> /* atoi, malloc */
#include <string.h> /* strcpy */
#include "uthash.h"
struct my_struct {
int id; /* key */
char name[21];
UT_hash_handle hh; /* makes this structure hashable */
};
struct my_struct *users = NULL;
void add_user(int user_id, const char *name)
{
struct my_struct *s;
HASH_FIND_INT(users, &user_id, s); /* id already in the hash? */
if (s == NULL) {
s = (struct my_struct*)malloc(sizeof *s);
s->id = user_id;
HASH_ADD_INT(users, id, s); /* id is the key field */
}
strcpy(s->name, name);
}
struct my_struct *find_user(int user_id)
{
struct my_struct *s;
HASH_FIND_INT(users, &user_id, s); /* s: output pointer */
return s;
}
void delete_user(struct my_struct *user)
{
HASH_DEL(users, user); /* user: pointer to deletee */
free(user);
}
void delete_all()
{
struct my_struct *current_user;
struct my_struct *tmp;
HASH_ITER(hh, users, current_user, tmp) {
HASH_DEL(users, current_user); /* delete it (users advances to next) */
free(current_user); /* free it */
}
}
void print_users()
{
struct my_struct *s;
for (s = users; s != NULL; s = (struct my_struct*)(s->hh.next)) {
printf("user id %d: name %s\n", s->id, s->name);
}
}
int by_name(const struct my_struct *a, const struct my_struct *b)
{
return strcmp(a->name, b->name);
}
int by_id(const struct my_struct *a, const struct my_struct *b)
{
return (a->id - b->id);
}
const char *getl(const char *prompt)
{
static char buf[21];
char *p;
printf("%s? ", prompt); fflush(stdout);
p = fgets(buf, sizeof(buf), stdin);
if (p == NULL || (p = strchr(buf, '\n')) == NULL) {
puts("Invalid input!");
exit(EXIT_FAILURE);
}
*p = '\0';
return buf;
}
int main()
{
int id = 1;
int running = 1;
struct my_struct *s;
int temp;
while (running) {
printf(" 1. add user\n");
printf(" 2. add or rename user by id\n");
printf(" 3. find user\n");
printf(" 4. delete user\n");
printf(" 5. delete all users\n");
printf(" 6. sort items by name\n");
printf(" 7. sort items by id\n");
printf(" 8. print users\n");
printf(" 9. count users\n");
printf("10. quit\n");
switch (atoi(getl("Command"))) {
case 1:
add_user(id++, getl("Name (20 char max)"));
break;
case 2:
temp = atoi(getl("ID"));
add_user(temp, getl("Name (20 char max)"));
break;
case 3:
s = find_user(atoi(getl("ID to find")));
printf("user: %s\n", s ? s->name : "unknown");
break;
case 4:
s = find_user(atoi(getl("ID to delete")));
if (s) {
delete_user(s);
} else {
printf("id unknown\n");
}
break;
case 5:
delete_all();
break;
case 6:
HASH_SORT(users, by_name);
break;
case 7:
HASH_SORT(users, by_id);
break;
case 8:
print_users();
break;
case 9:
temp = HASH_COUNT(users);
printf("there are %d users\n", temp);
break;
case 10:
running = 0;
break;
}
}
delete_all(); /* free any structures */
return 0;
}
825. 适龄的朋友

基本思路:
int cmp(const void *a, const void *b)
{
return *(int *)b - *(int *)a;
}
int numFriendRequests(int *ages, int agesSize)
{
int cnt = 0;
qsort(ages, agesSize, sizeof(int), cmp);
for (int i = 0; i < agesSize; i++) {
for (int j = i + 1; j < agesSize; j++) {
if ((ages[j] <= (0.5 * ages[i] + 7)) || (ages[j] > ages[i]) || ((ages[j] > 100) && ages[i] < 100)) {
break;
}
if (ages[i] == ages[j]) {
cnt = cnt + 2;
}
else {
cnt++;
}
}
}
return cnt;
}
1109. 航班预订统计

差分数组
今天这题给定的是一个一个的区间范围内的值,所以,我们很容易使用 差分数组 + 前缀和 来实现。
比如,给定数据范围为 [1, 5, 10],表示 1 到 5 号位存储的值为 10,使用差分数组我们要怎么求得结果呢?
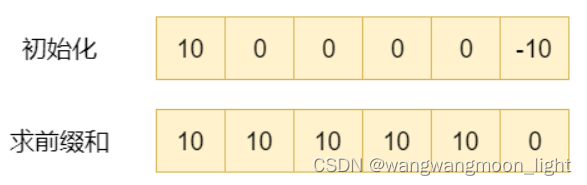
首先,我们可以申请一个长度为 5 的数组,这里为了更好地讲解,我们申请一个长度为 6 的数组,将 1号位(下标为 0)的值设置为 10,将 6号位(5的下一位,下标为 5)设置为 -10,然后再从头到尾求前缀和,就可以得到结果,请看图:
差分数组对应的概念是前缀和数组,对于数组 [1,2,2,4][1,2,2,4],其差分数组为 [1,1,0,2][1,1,0,2],差分数组的第 ii 个数即为原数组的第 i-1i−1 个元素和第 ii 个元素的差值,也就是说我们对差分数组求前缀和即可得到原数组。
差分数组的性质是,当我们希望对原数组的某一个区间 [l,r] 施加一个增量 inc 时,差分数组 d 对应的改变是:d[l] 增加 inc,d[r+1] 减少 inc。这样对于区间的修改就变为了对于两个位置的修改。并且这种修改是可以叠加的,即当我们多次对原数组的不同区间施加不同的增量,我们只要按规则修改差分数组即可。
在本题中,我们可以遍历给定的预定记录数组,每次 O(1) 地完成对差分数组的修改即可。当我们完成了差分数组的修改,只需要最后求出差分数组的前缀和即可得到目标数组。
注意本题中日期从 1 开始,因此我们需要相应的调整数组下标对应关系,对于预定记录 booking =[l,r,inc],我们需要让 d[l−1] 增加 inc,d[r] 减少inc。特别地,当 r 为 n 时,我们无需修改 d[r],因为这个位置溢出了下标范围。如果求前缀和时考虑该位置,那么该位置对应的前缀和值必定为 0。读者们可以自行思考原因,以加深对差分数组的理解。
int *corpFlightBookings(int **bookings, int bookingsSize, int *bookingsColSize, int n, int * returnSize) {
int* nums = malloc(sizeof(int) * n);
memset(nums, 0, sizeof(int) * n);
*returnSize = n;
for (int i = 0; i < bookingsSize; i++) {
nums[bookings[i][0] - 1] += bookings[i][2]; // d[l−1] 增加 inc
if (bookings[i][1] < n) {
nums[bookings[i][1]] -= bookings[i][2]; // d[r] 减少inc
}
}
for (int i = 1; i < n; i++) {
nums[i] += nums[i - 1]; // 将差分数组转为前缀和
}
return nums;
}
853. 车队

typedef struct car_info {
int pos;
int speed;
} CAR_INFO;
int cmp(const void *a, const void *b)
{
CAR_INFO *bInfo = (CAR_INFO *)b;
CAR_INFO *aInfo = (CAR_INFO *)a;
return bInfo->pos - aInfo->pos;
}
int carFleet(int target, int *position, int positionSize, int *speed, int speedSize)
{
// 以后二维数组需要排序都可以利用结构体的思路来排序
CAR_INFO *pcarInfo = (CAR_INFO *)malloc(sizeof(CAR_INFO)*positionSize);
for (int i = 0; i < positionSize; i++) {
pcarInfo[i].pos = position[i];
pcarInfo[i].speed = speed[i];
}
// 按距离Target降序排列,先计算离终点近的,近的会阻塞后面的车队,远的不会阻塞
qsort(pcarInfo, positionSize, sizeof(CAR_INFO), cmp);
// 计算每个位置达到终点的时间
float *times = (float *)malloc(sizeof(float *) * positionSize);
for (int i = 0; i < positionSize; i++) {
times[i] = (float)(target - pcarInfo[i].pos) / pcarInfo[i].speed;
}
// 重要的一步,如果后面的速度快于前面的,需要以前面的耗时为做参考(Delay)
for (int i = 1; i < positionSize; i++) {
if (times[i] < times[i - 1]) {
times[i] = times[i - 1];
}
}
// 计算车队数量
int count = 1;
for (int i = 1; i < positionSize; i++) {
if (times[i] != times[i - 1]) {
count++;
}
}
free(times);
return count;
}
1094. 拼车

差分数组:差分数组主要的适用场景是对原始数组进行频繁的区间增减操作,这个时候适用差分数组能够快速的完成,同时能够快速获得更新后的数组各个位置的值。假设原始数组为 arr, 数组长度为 len
问题背景
如果给你一个包含5000万个元素的数组,然后会有频繁区间修改操作,那什么是频繁的区间修改操作呢?比如让第1个数到第1000万个数每个数都加上1,而且这种操作时频繁的。
此时你应该怎么做?很容易想到的是,从第1个数开始遍历,一直遍历到第1000万个数,然后每个数都加上1,如果这种操作很频繁的话,那这种暴力的方法在一些实时的系统中可能就拉跨了。
因此,今天的主角就出现了——差分数组。
算法原型
比如我们现在有一个数组arr,arr={0,2,5,4,9,7,10,0}
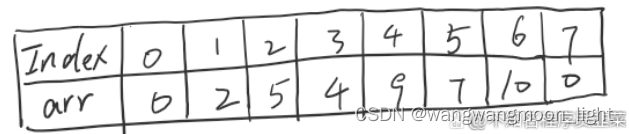
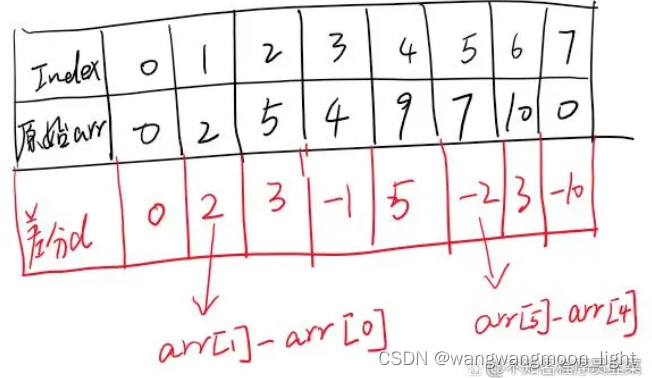
那么差分数组是什么呢?其实差分数组本质上也是一个数组,我们暂且定义差分数组为d,差分数组d的大小和原来arr数组大小一样,而且di=arri-arri-1,且di=0,它的含义是什么?就是原来数组i位置上的元素和i-1位置上的元素作差,得到的值就是di的值。
所以,例子中的arr数组其对应的差分数组值如下图所示。
那么构造了这么个玩意有什么用呢?难道是来浪费宝贵的内存空间的?嗯,确实是来浪费宝贵的内存了,但是却换了时间上的高效。
现在我们有这么一个区间修改操作,即在区间1~4上,所有的数值都加上3
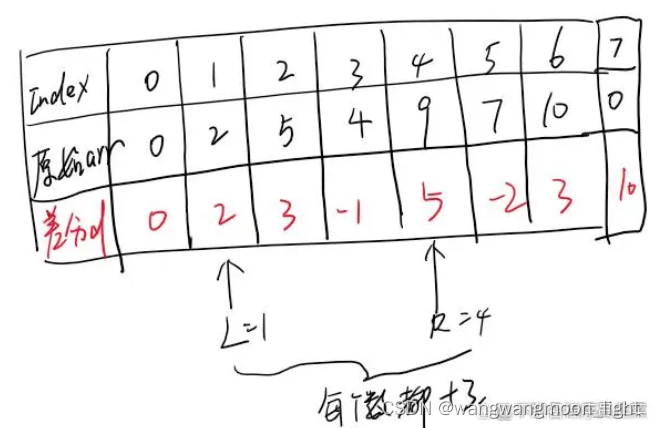
我们不要傻傻地遍历arr数组的1,4范围,然后再分别给每个值加上3,我们此时更改差分数组d即可。
显而易见,差分数组d在2,4范围内的值都不用改变,只需要改变差分数组位置1和位置5的值即可,即d1=d1+3,而d5=d5-3,其余不变,为什么呢?因为差分数组的定义——di=arri-arri-1
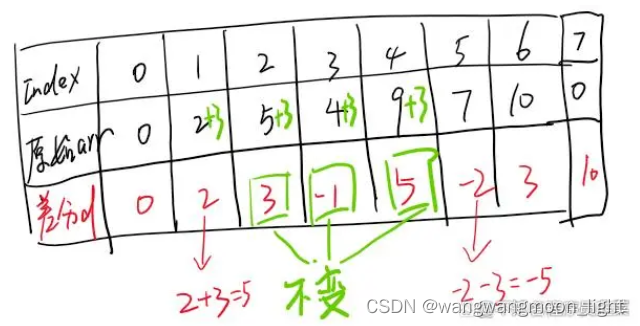
现在,我们如何根据差分数组d来推测arr中某一个位置的值呢?
比如,此时,我们想知道arr1的值,我们不能直接通过arr1得到原来的值,因为在区间修改的操作中我们并没有修改arr的值,因此我们必须从前往后遍历递推,由于d0=arr0-0(我们定义arr0的前一个数为0),那么arr0=d0=0,又由于d1=arr1-arr0=5,那么arr1=5+arr0=5。以此类推,由于d2=arr2-arr1=3,所以arr2=3+arr1=8。
总结
可以看到,如果需要对 L-R 范围内所有数都进行相同的操作,我们不需要从L~R 遍历 arr 然后在每个值上进行相同操作,只需要在差分数组 d 中改变 L 和 R+1 的值即可。但是在查询 arr 数组中某个位置的数时,却要根据差分数组从前往后递推求值。所以,该方法适用于区间频繁修改,而且这个区间范围是比较大的,离线查询的情况
本题拼车也即如此,区间频繁修改,区间范围为1000,也可以不用差分数组,但是效率会低,可能会超时;

bool carPooling(int **trips, int tripsSize, int *tripsColSize, int capacity)
{
int *diff = (int *)malloc(sizeof(int) * 1001);
int res[1000] = { 0 };
memset(diff, 0, sizeof(int) * 1001);
for (int i = 0; i < tripsSize; ++i) {
diff[trips[i][1]] += trips[i][0];
diff[trips[i][2]] -= trips[i][0];
}
/* // 将差分数组还原为原前缀和数组,也能解,只是效率低点
for (int i = 1; i < 10; ++i) {
diff[i] = diff[i] + diff[i - 1];
}
*/
int cur = 0;
for (int i = 0; i < 1001; ++i) {
cur += diff[i];
if (cur > capacity) {
return false;
}
}
return true;
}















 1129
1129











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









