







编程总结
在刷题之前需要反复练习的编程技巧,尤其是手写各类数据结构实现,它们好比就是全真教的上乘武功

栈是限制插入和删除只能在一个位置上进行的线性表。其中,允许插入和删除的一端位于表的末端,叫做栈顶(top),不允许插入和删除的另一端叫做栈底(bottom)。对栈的基本操作有 PUSH(压栈)和 POP (出栈),前者相当于表的插入操作(向栈顶插入一个元素),后者则是删除操作(删除一个栈顶元素)。栈是一种后进先出(LIFO)的数据结构,最先被删除的是最近压栈的元素。栈就像是一个箱子,往里面放入一个小盒子就相当于压栈操作,往里面取出一个小盒子就是出栈操作,取盒子的时候,最后放进去的盒子会最先被取出来,最先放进去的盒子会最后被取出来,这即是后入先出。下面是一个栈的示意图:
手写完成后,我们针对性的进行练习,练习题如下:

115. 最小栈

/-------------------------------------------分割线--------------------------------------/
栈只有top 统一叫:top
没有 head 和 tail.
#define MAXSIZE 10000
#define MAX_NUM 999999999 // 这个手法并不好,用例绝对有边界值需要覆盖的,不如给INT_MAX
typedef struct {
int stack[MAXSIZE];
int top;
int min;
} MinStack;
/** initialize your data structure here. */
MinStack *minStackCreate()
{
MinStack *obj = (MinStack *)malloc(sizeof(MinStack));
memset(obj->stack, 0, sizeof(int)*MAXSIZE);
obj->top = -1;
obj->min = INT_MAX; // 直接使用INT_MAX
return obj;
}
void minStackPush(MinStack *obj, int val)
{
obj->min = fmin(obj->min, val);
obj->stack[++obj->top] = val;
}
void minStackPop(MinStack *obj)
{
int i;
obj->top--;
obj->min = INT_MAX;
for (i = 0; i <= obj->top; i++) {
// obj->min = (obj->stack[i] < obj->min ? obj->stack[i] : obj->min);
obj->min = fmin(obj->stack[i], obj->min); // 使用 fmin 来优化编程
}
}
int minStackTop(MinStack *obj)
{
int ret = obj->stack[obj->top];
return ret;
}
int minStackGetMin(MinStack *obj)
{
return obj->min;
}
void minStackFree(MinStack *obj)
{
memset(obj->stack, 0, sizeof(int)*MAXSIZE);
obj->top = 0;
free(obj);
}
手法1:INT 的最值可以直接使用 INT_MIN 和 INT_MAX;

手法2:比较函数可以直接使用 fmin 或者 fmax;
20. 有效的括号

重新二刷这题,有两点需要注意是:
“}{” 这个是“”无效“的”括号,题目没有明确说明,但从条件2和用例可以获取到该信息;
首元素尽量不要选 -1 开始,容易出现stack[-1]. – cnt 统一从 0 开始;
#define MAXSIZE 10001
int isMatch(char s1, char s2);
int isMatch(char s1, char s2)
{
int ret;
if (s1 == '(' && s2 == ')') {
ret = 0;
} else if (s1 == '{' && s2 == '}') {
ret = 0;
} else if (s1 == '[' && s2 == ']') {
ret = 0;
} else {
ret = 1;
}
return ret;
}
bool isValid(char *s)
{
char stack[MAXSIZE] = {0};
int len = strlen(s);
int cnt = 0; // 首元素尽量不要选 -1 开始,容易出现stack[-1]
char topChar;
if (len % 2 == 1) {
return false;
}
for (int i = 0 ; i < len; i++) {
topChar = stack[cnt];
if (topChar > 0 && isMatch(topChar, s[i]) == 0) {
cnt--;
continue; // 这个 continue 是精髓,如果匹配成功则无需进栈,直接进入下一次.
}
stack[++cnt] = s[i]; // 没有匹配上,则进栈. 先++,再赋值,为了让top能获得最新的值。
}
if (cnt == 0) {
return true;
} else {
return false;
}
}
739. 每日温度

int* dailyTemperatures(int* T, int TSize, int* returnSize)
{
*returnSize = TSize;
int top = -1; // 栈顶下标
int stack[TSize]; // 创建TSize大小的数据 模拟栈 存储值为T的下标
int *result = (int *)malloc(sizeof(int)*TSize);
int cur = 0;
int index = 0;
int data = 0;
memset(result, 0, TSize*sizeof(int));
memset(stack, 0, TSize*sizeof(int));
for (int i = 0; i < TSize; i++) {
cur = T[i];
while (top >= 0) {
index = stack[top];
data = T[index];
if (cur > data) {
top--;
result[index] = i - index;
} else {
break;
}
}
top++;
stack[top] = i;
}
while (top >= 0) {
index = stack[top];
result[index] = 0;
top--;
}
return result;
}
1047. 删除字符串中的所有相邻重复项

乍一看,这题难度不小,像是可以递归的消除,感觉就不简单。
但细想,这次和泡泡龙/吐球的祖玛很像,吐出一个弹球,如果能两两消除,就可以出栈首元素;
再来一个弹球,继续与栈顶作判断,一致则出栈,这是一个顺序结构,并非递归的。
“aaa” 想了半天为啥返回"a", 结果发现要一对一对的:
‘a’进栈,‘a’与栈顶一致,则出栈;
第三个‘a’进栈,栈里最终剩余 ‘a’.
做完这题才明白原来 栈 这个数据结构在“计算器”和“泡泡龙”领域有典型的应用场景,哈哈哈,本科学栈,正是死记硬背,没有理解也没有明白为什么有这个东东,以后真正有应用场景再来体会它的魅力吧。
char *removeDuplicates(char *s)
{
int n = strlen(s);
char *stack = malloc(sizeof(char) * (n + 1)); // stack 可以分大一些,用'\0'控制字符串即可
int top = -1;
for (int i = 0; i < n; i++) {
if (top >= 0 && stack[top] == s[i]) { // 如果s[i]与栈顶相等则出栈
top--;
} else {
stack[++top] = s[i]; // 不符合条件入栈,第一次也入栈
}
}
stack[top + 1] = '\0';
return stack;
}
1209. 删除字符串中的所有相邻重复项 II


顺着上题的思路,写完代码还想着一把过呢,结果超时了。。。
int judgeStr(char *stack, int k, int i, char *s, int top)
{
int ret = -1;
for (int j = 0; j < k - 1; j++) {
if (stack[top - j] != s[i]) { // 判断当前元素s[i]是否与stack[top]的前k-1个元素相等
return ret;
}
}
ret = 0;
return ret;
}
char *removeDuplicates(char *s, int k)
{
int n = strlen(s);
char *stack = malloc(sizeof(char) * (n + 1)); // stack 可以分大一些,用'\0'控制字符串即可
int top = -1;
for (int i = 0; i < n; i++) {
if (top >= (k - 2) && (judgeStr(stack, k, i, s, top) == 0)) {
top = top - k + 1;
} else {
stack[++top] = s[i]; // 不符合条件入栈,第一次也入栈
}
}
stack[top + 1] = '\0';
return stack;
}
232. 用栈实现队列

思路:将一个栈当作输入栈,用于压入 push 传入的数据;另一个栈当作输出栈,用于 pop 和 peek 操作。
每次 pop 或 peek 时,若输出栈为空则将输入栈的全部数据依次弹出并压入输出栈,这样输出栈从栈顶往栈底的顺序就是队列从队首往队尾的顺序
1)AppendTail:
增加元素,即直接往stack1里加元素.

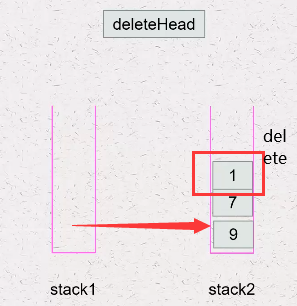
2)DeleteHead:
要想删除队首元素,需要先将stack1元素都搬运到stack2中,再删除stack2的top元素即可.
typedef struct {
int *stack;
int top;
int size;
} Stack;
Stack *stackCreate(int capacity)
{
Stack *obj = (Stack *)malloc(sizeof(Stack));
obj->stack = (int *)malloc(sizeof(int) * capacity);
obj->size = capacity;
obj->top = -1;
return obj;
}
void stackPush(Stack *obj, int x)
{
obj->stack[++obj->top] = x;
}
void stackPop(Stack *obj)
{
obj->top--;
}
int stackTop(Stack *obj)
{
return obj->stack[obj->top];
}
bool stackEmpty(Stack *obj)
{
return obj->top == -1;
}
void stackFree(Stack *obj)
{
free(obj->stack);
}
/** Initialize your data structure here. */
typedef struct {
Stack *stack1;
Stack *stack2;
} MyQueue;
MyQueue *myQueueCreate()
{
MyQueue *obj = (MyQueue *)malloc(sizeof(MyQueue));
obj->stack1 = stackCreate(100);
obj->stack2 = stackCreate(100);
return obj;
}
// stack1 -> stack2.
void stack12stack2(MyQueue *obj)
{
while (!stackEmpty(obj->stack1)) {
stackPush(obj->stack2, stackTop(obj->stack1)); // 1. stack1 Top元素入stack2
stackPop(obj->stack1); // 2. stack1 Pop元素
} // 3. stack2 入栈stack1的Top元素
}
/** Push element x to the back of queue. */
void myQueuePush(MyQueue *obj, int x) {
stackPush(obj->stack1, x); // 入队列就入stack1就行
}
/** Removes the element from in front of queue and returns that element. */
int myQueuePop(MyQueue *obj) { // 要出队列:
if (stackEmpty(obj->stack2)) { // 1.要把stack1元素搬运到stack2
stack12stack2(obj);
}
int x = stackTop(obj->stack2); // 2. 取stack2栈顶元素,即为需要pop的队首元素
stackPop(obj->stack2); // 3. Pop stack2栈顶元素
return x;
}
/** Get the front element. */
int myQueuePeek(MyQueue *obj) { // 要取队首元素
if (stackEmpty(obj->stack2)) { // 1. 要把stack1元素搬运到stack2
stack12stack2(obj);
}
return stackTop(obj->stack2); // 2. 此时stack2的Top元素即为Queue的队首元素
}
/** Returns whether the queue is empty. */
bool myQueueEmpty(MyQueue *obj) {
return stackEmpty(obj->stack1) && stackEmpty(obj->stack2);
}
void myQueueFree(MyQueue *obj) {
stackFree(obj->stack1);
stackFree(obj->stack2);
}
224. 基本计算器

#define MAX_LEN 100001
int calculate(char *s)
{
int len = strlen(s);
int ops[MAX_LEN], top = -1;
int sign = 1;
int result = 0;
int i = 0;
long num = 0;
ops[++top] = sign; // 取值为{−1,+1} 的整数 sign 代表「当前」的符号,栈顶 -- 只有加号和减号两种运算符
while (i < len) {
switch (s[i]) {
case ' ':
i++;
break;
case '+':
sign = ops[top];
i++;
break;
case '-':
sign = -ops[top];
i++;
break;
case '(':
// 标记这组括号内的数据的正负值
ops[++top] = sign;
i++;
break;
case ')':
// 每当遇到 ) 时,都从栈中弹出一个元素, 代表左括号进栈的sign没有用了
top--;
i++;
break;
default:
num = 0;
// 处理超过1bit的数据
while (i < len && s[i] >= '0' && s[i] <= '9') {
num = num * 10 + s[i] - '0';
i++;
}
result += sign * num; // 计算当前结果
break;
}
}
return result;
}
227. 基本计算器 II

手法1:有个 库函数可以使用需要包含 #include <ctype.h> – isdigit(s[i])

/*
加号:将数字压入栈;
减号:将数字的相反数压入栈;
乘除号:计算数字与栈顶元素,并将栈顶元素替换为计算结果
没有括号的出现,可以直接计算数值
*/
int calculate(char* s)
{
int n = strlen(s);
int stack[MAX_LEN], top = -1;
char preSign = '+';
int num = 0;
int ret = 0;
for (int i = 0; i < n; ++i) {
if (isdigit(s[i])) {
num = num * 10 + (int)(s[i] - '0');
}
if (!isdigit(s[i]) && s[i] != ' ' || i == n - 1) { // i == n -1 最后一次需要进来算一次
switch (preSign) {
case '+':
stack[++top] = num;
break;
case '-':
stack[++top] = -num;
break;
case '*':
stack[top] *= num;
break;
default:
stack[top] /= num;
break;
}
preSign = s[i];
num = 0;
}
}
ret = 0;
for (int i = 0; i <= top; i++) {
ret += stack[i];
}
return ret;
}
496. 下一个更大元素 I

To Do 单调栈;















 1346
1346











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









