






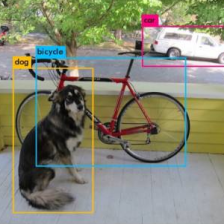



SSD Keras版源码史上最详细解读系列之数据生成与解析
object_detection_2d_data_generator.py
这个文件主要是做一些训练数据的预处理,我们先来看看这个类DataGenerator的作用,数据生成器:
def __init__(self,
load_images_into_memory=False,
hdf5_dataset_path=None,
filenames=None,
filenames_type='text',
images_dir=None,
labels=None,
image_ids=None,
eval_neutral=None,
labels_output_format=('class_id', 'xmin', 'ymin', 'xmax', 'ymax'),
verbose=True):
'''
Initializes the data generator. You can either load a dataset directly here in the constructor,
e.g. an HDF5 dataset, or you can use one of the parser methods to read in a dataset.
Arguments:
# 加载图片到内存
load_images_into_memory (bool, optional): If `True`, the entire dataset will be loaded into memory.
This enables noticeably faster data generation than loading batches of images into memory ad hoc.
Be sure that you have enough memory before you activate this option.
# 图片集的路径
hdf5_dataset_path (str, optional): The full file path of an HDF5 file that contains a dataset in the
format that the `create_hdf5_dataset()` method produces. If you load such an HDF5 dataset, you
don't need to use any of the parser methods anymore, the HDF5 dataset already contains all relevant
data.
# 一堆文件名
filenames (string or list, optional): `None` or either a Python list/tuple or a string representing
a filepath. If a list/tuple is passed, it must contain the file names (full paths) of the
images to be used. Note that the list/tuple must contain the paths to the images,
not the images themselves. If a filepath string is passed, it must point either to
(1) a pickled file containing a list/tuple as described above. In this case the `filenames_type`
argument must be set to `pickle`.
Or
(2) a text file. Each line of the text file contains the file name (basename of the file only,
not the full directory path) to one image and nothing else. In this case the `filenames_type`
argument must be set to `text` and you must pass the path to the directory that contains the
images in `images_dir`.
# 文件类型
filenames_type (string, optional): In case a string is passed for `filenames`, this indicates what
type of file `filenames` is. It can be either 'pickle' for a pickled file or 'text' for a
plain text file.
# 图片路径
images_dir (string, optional): In case a text file is passed for `filenames`, the full paths to
the images will be composed from `images_dir` and the names in the text file, i.e. this
should be the directory that contains the images to which the text file refers.
If `filenames_type` is not 'text', then this argument is irrelevant.
# 标签
labels (string or list, optional): `None` or either a Python list/tuple or a string representing
the path to a pickled file containing a list/tuple. The list/tuple must contain Numpy arrays
that represent the labels of the dataset.
# 图片名字
image_ids (string or list, optional): `None` or either a Python list/tuple or a string representing
the path to a pickled file containing a list/tuple. The list/tuple must contain the image
IDs of the images in the dataset.
# 是否是难例
eval_neutral (string or list, optional): `None` or either a Python list/tuple or a string representing
the path to a pickled file containing a list/tuple. The list/tuple must contain for each image
a list that indicates for each ground truth object in the image whether that object is supposed
to be treated as neutral during an evaluation.
# 标签格式
labels_output_format (list, optional): A list of five strings representing the desired order of the five
items class ID, xmin, ymin, xmax, ymax in the generated ground truth data (if any). The expected
strings are 'xmin', 'ymin', 'xmax', 'ymax', 'class_id'.
# 提示
verbose (bool, optional): If `True`, prints out the progress for some constructor operations that may
take a bit longer.
'''
self.labels_output_format = labels_output_format
# 类别索引 左上角和右下角
self.labels_format={'class_id': labels_output_format.index('class_id'),
'xmin': labels_output_format.index('xmin'),
'ymin': labels_output_format.index('ymin'),
'xmax': labels_output_format.index('xmax'),
'ymax': labels_output_format.index('ymax')} # This dictionary is for internal use.
# 没加载数据到内存的时候
self.dataset_size = 0 # As long as we haven't loaded anything yet, the dataset size is zero.
self.load_images_into_memory = load_images_into_memory
# 没加载数据到内存的时候
self.images = None # The only way that this list will not stay `None` is if `load_images_into_memory == True`.
# `self.filenames` is a list containing all file names of the image samples (full paths).
# Note that it does not contain the actual image files themselves. This list is one of the outputs of the parser methods.
# In case you are loading an HDF5 dataset, this list will be `None`.
# 如果存在,根据不同格式来加载图片数据
if not filenames is None:
if isinstance(filenames, (list, tuple)):
self.filenames = filenames
elif isinstance(filenames, str):
with open(filenames, 'rb') as f:
if filenames_type == 'pickle':
self.filenames = pickle.load(f)
elif filenames_type == 'text':
self.filenames = [os.path.join(images_dir, line.strip()) for line in f]
else:
raise ValueError("`filenames_type` can be either 'text' or 'pickle'.")
else:
raise ValueError("`filenames` must be either a Python list/tuple or a string representing a filepath (to a pickled or text file). The value you passed is neither of the two.")
self.dataset_size = len(self.filenames)
self.dataset_indices = np.arange(self.dataset_size, dtype=np.int32)
# 是否是预加载到内存
if load_images_into_memory:
self.images = []
# 如果有提示就给出加载的进度条
if verbose: it = tqdm(self.filenames, desc='Loading images into memory', file=sys.stdout)
else: it = self.filenames
for filename in it:
with Image.open(filename) as image:
# 图片数据都加载进images
self.images.append(np.array(image, dtype=np.uint8))
else:
self.filenames = None
# In case ground truth is available, `self.labels` is a list containing for each image a list (or NumPy array)
# of ground truth bounding boxes for that image.
# 标签不为空时加载标签
if not labels is None:
if isinstance(labels, str):
with open(labels, 'rb') as f:
self.labels = pickle.load(f)
elif isinstance(labels, (list, tuple)):
self.labels = labels
else:
raise ValueError("`labels` must be either a Python list/tuple or a string representing the path to a pickled file containing a list/tuple. The value you passed is neither of the two.")
else:
self.labels = None
# 图片名字不为空时
if not image_ids is None:
if isinstance(image_ids, str):
with open(image_ids, 'rb') as f:
self.image_ids = pickle.load(f)
elif isinstance(image_ids, (list, tuple)):
self.image_ids = image_ids
else:
raise ValueError("`image_ids` must be either a Python list/tuple or a string representing the path to a pickled file containing a list/tuple. The value you passed is neither of the two.")
else:
self.image_ids = None
# 中心框不为空时
if not eval_neutral is None:
if isinstance(eval_neutral, str):
with open(eval_neutral, 'rb') as f:
self.eval_neutral = pickle.load(f)
elif isinstance(eval_neutral, (list, tuple)):
self.eval_neutral = eval_neutral
else:
raise ValueError("`image_ids` must be either a Python list/tuple or a string representing the path to a pickled file containing a list/tuple. The value you passed is neither of the two.")
else:
self.eval_neutral = None
# 预加载数据集路径部位空时
if not hdf5_dataset_path is None:
self.hdf5_dataset_path = hdf5_dataset_path
self.load_hdf5_dataset(verbose=verbose)
else:
self.hdf5_dataset = None
初始化方法就是做一些数据的设置,其中有个load_images_into_memory的设置,就是说是不是把图片一次性加载到空内存里,这样就不用后面每次都要加载图片,可以加快速度,但是这样需要比较大的内存,而且是会将数据集预先打包成H5的格式,方便加载到内存,下面就是使用了H5格式的编码后的数据集:

其实在ssd300_training.py里有这个的处理代码,被我注释掉了,我编码了一次,可惜内存不够,用不上:
# 将数据编码提前加载到内存,之后可以快速训练,不然每次都要加载一批数据到内存然后训练
# Optional: Convert the dataset into an HDF5 dataset. This will require more disk space, but will
# speed up the training. Doing this is not relevant in case you activated the `load_images_into_memory`
# option in the constructor, because in that cas the images are in memory already anyway. If you don't
# want to create HDF5 datasets, comment out the subsequent two function calls.
# train_dataset.create_hdf5_dataset(file_path='dataset_pascal_voc_07+12_trainval.h5',
# resize=False,
# variable_image_size=True,
# verbose=True)
#
# val_dataset.create_hdf5_dataset(file_path='dataset_pascal_voc_07_test.h5',
# resize=False,
# variable_image_size=True,
# verbose=True)
下面就是他加载H5数据集的代码,就是把相关的图片信息加载到内存:
# 预加载数据
def load_hdf5_dataset(self, verbose=True):
'''
Loads an HDF5 dataset that is in the format that the `create_hdf5_dataset()` method
produces.
Arguments:
verbose (bool, optional): If `True`, prints out the progress while loading
the dataset.
Returns:
None.
'''
self.hdf5_dataset = h5py.File(self.hdf5_dataset_path, 'r')
self.dataset_size = len(self.hdf5_dataset['images'])
self.dataset_indices = np.arange(self.dataset_size, dtype=np.int32) # Instead of shuffling the HDF5 dataset or images in memory, we will shuffle this index list.
if self.load_images_into_memory:
self.images = []
if verbose: tr = trange(self.dataset_size, desc='Loading images into memory', file=sys.stdout)
else: tr = range(self.dataset_size)
for i in tr:
self.images.append(self.hdf5_dataset['images'][i].reshape(self.hdf5_dataset['image_shapes'][i]))
if self.hdf5_dataset.attrs['has_labels']:
self.labels = []
labels = self.hdf5_dataset['labels']
label_shapes = self.hdf5_dataset['label_shapes']
if verbose: tr = trange(self.dataset_size, desc='Loading labels', file=sys.stdout)
else: tr = range(self.dataset_size)
for i in tr:
self.labels.append(labels[i].reshape(label_shapes[i]))
if self.hdf5_dataset.attrs['has_image_ids']:
self.image_ids = []
image_ids = self.hdf5_dataset['image_ids']
if verbose: tr = trange(self.dataset_size, desc='Loading image IDs', file=sys.stdout)
else: tr = range(self.dataset_size)
for i in tr:
self.image_ids.append(image_ids[i])
if self.hdf5_dataset.attrs['has_eval_neutral']:
self.eval_neutral = []
eval_neutral = self.hdf5_dataset['eval_neutral']
if verbose: tr = trange(self.dataset_size, desc='Loading evaluation-neutrality annotations', file=sys.stdout)
else: tr = range(self.dataset_size)
for i in tr:
self.eval_neutral.append(eval_neutral[i])
然后还有一个解析标签文件xml的方法,就是把xml里的相关信息加载到内存里,以便于后面加载具体数据:
# 解析Pascal VOC XML
def parse_xml(self,
images_dirs,
image_set_filenames,
annotations_dirs=[],
classes=['background',
'aeroplane', 'bicycle', 'bird', 'boat',
'bottle', 'bus', 'car', 'cat',
'chair', 'cow', 'diningtable', 'dog',
'horse', 'motorbike', 'person', 'pottedplant',
'sheep', 'sofa', 'train', 'tvmonitor'],
include_classes = 'all',
exclude_truncated=False,
exclude_difficult=False,
ret=False,
verbose=True):
'''
This is an XML parser for the Pascal VOC datasets. It might be applicable to other datasets with minor changes to
the code, but in its current form it expects the data format and XML tags of the Pascal VOC datasets.
Arguments:
文件目录
images_dirs (list): A list of strings, where each string is the path of a directory that
contains images that are to be part of the dataset. This allows you to aggregate multiple datasets
into one (e.g. one directory that contains the images for Pascal VOC 2007, another that contains
the images for Pascal VOC 2012, etc.).
一堆文件名
image_set_filenames (list): A list of strings, where each string is the path of the text file with the image
set to be loaded. Must be one file per image directory given. These text files define what images in the
respective image directories are to be part of the dataset and simply contains one image ID per line
and nothing else.
注释目录
annotations_dirs (list, optional): A list of strings, where each string is the path of a directory that
contains the annotations (XML files) that belong to the images in the respective image directories given.
The directories must contain one XML file per image and the name of an XML file must be the image ID
of the image it belongs to. The content of the XML files must be in the Pascal VOC format.
类别
classes (list, optional): A list containing the names of the object classes as found in the
`name` XML tags. Must include the class `background` as the first list item. The order of this list
defines the class IDs.
是否包含所有类别
include_classes (list, optional): Either 'all' or a list of integers containing the class IDs that
are to be included in the dataset. If 'all', all ground truth boxes will be included in the dataset.
exclude_truncated (bool, optional): If `True`, excludes boxes that are labeled as 'truncated'.
exclude_difficult (bool, optional): If `True`, excludes boxes that are labeled as 'difficult'.
是否输出解析结果
ret (bool, optional): Whether or not to return the outputs of the parser.
打印信息
verbose (bool, optional): If `True`, prints out the progress for operations that may take a bit longer.
Returns:
None by default, optionally lists for whichever are available of images, image filenames, labels, image IDs,
and a list indicating which boxes are annotated with the label "difficult".
'''
# Set class members.
# 设置参数
self.images_dirs = images_dirs
self.annotations_dirs = annotations_dirs
self.image_set_filenames = image_set_filenames
self.classes = classes
self.include_classes = include_classes
# Erase data that might have been parsed before.
# 清空缓存
self.filenames = []
self.image_ids = []
self.labels = []
self.eval_neutral = []
if not annotations_dirs:
self.labels = None
self.eval_neutral = None
annotations_dirs = [None] * len(images_dirs)
for images_dir, image_set_filename, annotations_dir in zip(images_dirs, image_set_filenames, annotations_dirs):
# Read the image set file that so that we know all the IDs of all the images to be included in the dataset.
# 获取要文件名字
with open(image_set_filename) as f:
image_ids = [line.strip() for line in f] # Note: These are strings, not integers.
self.image_ids += image_ids
# 打印信息 返回名字迭代器 每个数据集都会有打印进度
if verbose: it = tqdm(image_ids, desc="Processing image set '{}'".format(os.path.basename(image_set_filename)), file=sys.stdout)
else: it = image_ids
# Loop over all images in this dataset.
# 迭代所有图片名字
for image_id in it:
filename = '{}'.format(image_id) + '.jpg'
# 拼成路径
self.filenames.append(os.path.join(images_dir, filename))
# 用BeautifulSoup解析xml
if not annotations_dir is None:
# Parse the XML file for this image.
with open(os.path.join(annotations_dir, image_id + '.xml')) as f:
soup = BeautifulSoup(f, 'xml')
folder = soup.folder.text # In case we want to return the folder in addition to the image file name. Relevant for determining which dataset an image belongs to.
#filename = soup.filename.text
# 真实框信息
boxes = [] # We'll store all boxes for this image here.
# 放难识别的框
eval_neutr = [] # We'll store whether a box is annotated as "difficult" here.
# 获取所有物体标签
objects = soup.find_all('object') # Get a list of all objects in this image.
# Parse the data for each object.
for obj in objects:
class_name = obj.find('name', recursive=False).text
class_id = self.classes.index(class_name)
# Check whether this class is supposed to be included in the dataset.
if (not self.include_classes == 'all') and (not class_id in self.include_classes): continue
pose = obj.find('pose', recursive=False).text
truncated = int(obj.find('truncated', recursive=False).text)
if exclude_truncated and (truncated == 1): continue
difficult = int(obj.find('difficult', recursive=False).text)
if exclude_difficult and (difficult == 1): continue
# Get the bounding box coordinates.
bndbox = obj.find('bndbox', recursive=False)
xmin = int(bndbox.xmin.text)
ymin = int(bndbox.ymin.text)
xmax = int(bndbox.xmax.text)
ymax = int(bndbox.ymax.text)
item_dict = {'folder': folder,
'image_name': filename,
'image_id': image_id,
'class_name': class_name,
'class_id': class_id,
'pose': pose,
'truncated': truncated,
'difficult': difficult,
'xmin': xmin,
'ymin': ymin,
'xmax': xmax,
'ymax': ymax}
box = []
# 跟key放入对应的value
for item in self.labels_output_format:
box.append(item_dict[item])
boxes.append(box)
# 是否是难例
if difficult: eval_neutr.append(True)
else: eval_neutr.append(False)
self.labels.append(boxes)
self.eval_neutral.append(eval_neutr)
# 数据集大小 把所有数据集的样本全加起来的
self.dataset_size = len(self.filenames)
# 索引
self.dataset_indices = np.arange(self.dataset_size, dtype=np.int32)
# 如果是缓存的话就读取缓存
if self.load_images_into_memory:
self.images = []
if verbose: it = tqdm(self.filenames, desc='Loading images into memory', file=sys.stdout)
else: it = self.filenames
for filename in it:
with Image.open(filename) as image:
self.images.append(np.array(image, dtype=np.uint8))
if ret:
return self.images, self.filenames, self.labels, self.image_ids, self.eval_neutral
其实最关键的是训练时候的这两个生成器:
train_generator = train_dataset.generate(batch_size=batch_size,
shuffle=True,
transformations=[ssd_data_augmentation],
label_encoder=ssd_input_encoder,
returns={'processed_images',
'encoded_labels'},
keep_images_without_gt=False)
val_generator = val_dataset.generate(batch_size=batch_size,
shuffle=False,
transformations=[convert_to_3_channels,
resize],
label_encoder=ssd_input_encoder,
returns={'processed_images',
'encoded_labels'},
keep_images_without_gt=False)
对应的generate方法,其实他做的就是每次批量生产数据,然后把相关的数据增强和标签编码用上去,把不合格的数据给丢弃,最后把需要的数据返回,不过可能会少于定好的批量数:
def generate(self,
batch_size=32,
shuffle=True,
transformations=[],
label_encoder=None,
returns={'processed_images', 'encoded_labels'},
keep_images_without_gt=False,
degenerate_box_handling='remove'):
'''
Generates batches of samples and (optionally) corresponding labels indefinitely.
Can shuffle the samples consistently after each complete pass.
Optionally takes a list of arbitrary image transformations to apply to the
samples ad hoc.
Arguments:
# 批量数
batch_size (int, optional): The size of the batches to be generated.
# 是否混洗数据 当然你要调试的话先关闭
shuffle (bool, optional): Whether or not to shuffle the dataset before each pass.
This option should always be `True` during training, but it can be useful to turn shuffling off
for debugging or if you're using the generator for prediction.
# 一些数据增强的东西
transformations (list, optional): A list of transformations that will be applied to the images and labels
in the given order. Each transformation is a callable that takes as input an image (as a Numpy array)
and optionally labels (also as a Numpy array) and returns an image and optionally labels in the same
format.
# 标签编码器 输出一些处理过的标签编码
label_encoder (callable, optional): Only relevant if labels are given. A callable that takes as input the
labels of a batch (as a list of Numpy arrays) and returns some structure that represents those labels.
The general use case for this is to convert labels from their input format to a format that a given object
detection model needs as its training targets.
# 返回的数据
returns (set, optional): A set of strings that determines what outputs the generator yields. The generator's output
is always a tuple that contains the outputs specified in this set and only those. If an output is not available,
it will be `None`. The output tuple can contain the following outputs according to the specified keyword strings:
* 'processed_images': An array containing the processed images. Will always be in the outputs, so it doesn't
matter whether or not you include this keyword in the set.
* 'encoded_labels': The encoded labels tensor. Will always be in the outputs if a label encoder is given,
so it doesn't matter whether or not you include this keyword in the set if you pass a label encoder.
* 'matched_anchors': Only available if `labels_encoder` is an `SSDInputEncoder` object. The same as 'encoded_labels',
but containing anchor box coordinates for all matched anchor boxes instead of ground truth coordinates.
This can be useful to visualize what anchor boxes are being matched to each ground truth box. Only available
in training mode.
* 'processed_labels': The processed, but not yet encoded labels. This is a list that contains for each
batch image a Numpy array with all ground truth boxes for that image. Only available if ground truth is available.
* 'filenames': A list containing the file names (full paths) of the images in the batch.
* 'image_ids': A list containing the integer IDs of the images in the batch. Only available if there
are image IDs available.
* 'evaluation-neutral': A nested list of lists of booleans. Each list contains `True` or `False` for every ground truth
bounding box of the respective image depending on whether that bounding box is supposed to be evaluation-neutral (`True`)
or not (`False`). May return `None` if there exists no such concept for a given dataset. An example for
evaluation-neutrality are the ground truth boxes annotated as "difficult" in the Pascal VOC datasets, which are
usually treated to be neutral in a model evaluation.
* 'inverse_transform': A nested list that contains a list of "inverter" functions for each item in the batch.
These inverter functions take (predicted) labels for an image as input and apply the inverse of the transformations
that were applied to the original image to them. This makes it possible to let the model make predictions on a
transformed image and then convert these predictions back to the original image. This is mostly relevant for
evaluation: If you want to evaluate your model on a dataset with varying image sizes, then you are forced to
transform the images somehow (e.g. by resizing or cropping) to make them all the same size. Your model will then
predict boxes for those transformed images, but for the evaluation you will need predictions with respect to the
original images, not with respect to the transformed images. This means you will have to transform the predicted
box coordinates back to the original image sizes. Note that for each image, the inverter functions for that
image need to be applied in the order in which they are given in the respective list for that image.
* 'original_images': A list containing the original images in the batch before any processing.
* 'original_labels': A list containing the original ground truth boxes for the images in this batch before any
processing. Only available if ground truth is available.
The order of the outputs in the tuple is the order of the list above. If `returns` contains a keyword for an
output that is unavailable, that output omitted in the yielded tuples and a warning will be raised.
# 是否保留没有对应真实框的锚框
keep_images_without_gt (bool, optional): If `False`, images for which there aren't any ground truth boxes before
any transformations have been applied will be removed from the batch. If `True`, such images will be kept
in the batch.
# 数据增强后把一些不合适的去掉
degenerate_box_handling (str, optional): How to handle degenerate boxes, which are boxes that have `xmax <= xmin` and/or
`ymax <= ymin`. Degenerate boxes can sometimes be in the dataset, or non-degenerate boxes can become degenerate
after they were processed by transformations. Note that the generator checks for degenerate boxes after all
transformations have been applied (if any), but before the labels were passed to the `label_encoder` (if one was given).
Can be one of 'warn' or 'remove'. If 'warn', the generator will merely print a warning to let you know that there
are degenerate boxes in a batch. If 'remove', the generator will remove degenerate boxes from the batch silently.
Yields:
The next batch as a tuple of items as defined by the `returns` argument.
'''
if self.dataset_size == 0:
raise DatasetError("Cannot generate batches because you did not load a dataset.")
#############################################################################################
# Warn if any of the set returns aren't possible.
#############################################################################################
if self.labels is None:
if any([ret in returns for ret in ['original_labels', 'processed_labels', 'encoded_labels', 'matched_anchors', 'evaluation-neutral']]):
warnings.warn("Since no labels were given, none of 'original_labels', 'processed_labels', 'evaluation-neutral', 'encoded_labels', and 'matched_anchors' " +
"are possible returns, but you set `returns = {}`. The impossible returns will be `None`.".format(returns))
elif label_encoder is None:
if any([ret in returns for ret in ['encoded_labels', 'matched_anchors']]):
warnings.warn("Since no label encoder was given, 'encoded_labels' and 'matched_anchors' aren't possible returns, " +
"but you set `returns = {}`. The impossible returns will be `None`.".format(returns))
elif not isinstance(label_encoder, SSDInputEncoder):
if 'matched_anchors' in returns:
warnings.warn("`label_encoder` is not an `SSDInputEncoder` object, therefore 'matched_anchors' is not a possible return, " +
"but you set `returns = {}`. The impossible returns will be `None`.".format(returns))
#############################################################################################
# Do a few preparatory things like maybe shuffling the dataset initially.
#############################################################################################
# 进行数据的混洗
if shuffle:
objects_to_shuffle = [self.dataset_indices]
if not (self.filenames is None):
objects_to_shuffle.append(self.filenames)
if not (self.labels is None):
objects_to_shuffle.append(self.labels)
if not (self.image_ids is None):
objects_to_shuffle.append(self.image_ids)
if not (self.eval_neutral is None):
objects_to_shuffle.append(self.eval_neutral)
shuffled_objects = sklearn.utils.shuffle(*objects_to_shuffle)
for i in range(len(objects_to_shuffle)):
objects_to_shuffle[i][:] = shuffled_objects[i]
# 锚框过滤器
if degenerate_box_handling == 'remove':
box_filter = BoxFilter(check_overlap=False,
check_min_area=False,
check_degenerate=True,
labels_format=self.labels_format)
# Override the labels formats of all the transformations to make sure they are set correctly.
if not (self.labels is None):
for transform in transformations:
transform.labels_format = self.labels_format
#############################################################################################
# Generate mini batches.
#############################################################################################
current = 0
while True:
batch_X, batch_y = [], []
if current >= self.dataset_size:
current = 0
#########################################################################################
# Maybe shuffle the dataset if a full pass over the dataset has finished.
#########################################################################################
# 遍历完所有数据后都要混洗一次
if shuffle:
objects_to_shuffle = [self.dataset_indices]
if not (self.filenames is None):
objects_to_shuffle.append(self.filenames)
if not (self.labels is None):
objects_to_shuffle.append(self.labels)
if not (self.image_ids is None):
objects_to_shuffle.append(self.image_ids)
if not (self.eval_neutral is None):
objects_to_shuffle.append(self.eval_neutral)
shuffled_objects = sklearn.utils.shuffle(*objects_to_shuffle)
for i in range(len(objects_to_shuffle)):
objects_to_shuffle[i][:] = shuffled_objects[i]
#########################################################################################
# Get the images, (maybe) image IDs, (maybe) labels, etc. for this batch.
#########################################################################################
# We prioritize our options in the following order:
# 1) If we have the images already loaded in memory, get them from there.
# 2) Else, if we have an HDF5 dataset, get the images from there.
# 3) Else, if we have neither of the above, we'll have to load the individual image
# files from disk.
# 获取相应的索引 后加载图片和名字
batch_indices = self.dataset_indices[current:current+batch_size]
if not (self.images is None):
for i in batch_indices:
batch_X.append(self.images[i])
if not (self.filenames is None):
batch_filenames = self.filenames[current:current+batch_size]
else:
batch_filenames = None
elif not (self.hdf5_dataset is None):
for i in batch_indices:
batch_X.append(self.hdf5_dataset['images'][i].reshape(self.hdf5_dataset['image_shapes'][i]))
if not (self.filenames is None):
batch_filenames = self.filenames[current:current+batch_size]
else:
batch_filenames = None
else:
batch_filenames = self.filenames[current:current+batch_size]
for filename in batch_filenames:
with Image.open(filename) as image:
batch_X.append(np.array(image, dtype=np.uint8))
# 加载其他信息 直接复制一份
# Get the labels for this batch (if there are any).
if not (self.labels is None):
batch_y = deepcopy(self.labels[current:current+batch_size])
else:
batch_y = None
if not (self.eval_neutral is None):
batch_eval_neutral = self.eval_neutral[current:current+batch_size]
else:
batch_eval_neutral = None
# Get the image IDs for this batch (if there are any).
if not (self.image_ids is None):
batch_image_ids = self.image_ids[current:current+batch_size]
else:
batch_image_ids = None
if 'original_images' in returns:
batch_original_images = deepcopy(batch_X) # The original, unaltered images
if 'original_labels' in returns:
batch_original_labels = deepcopy(batch_y) # The original, unaltered labels
current += batch_size
#########################################################################################
# Maybe perform image transformations.
#########################################################################################
# 存要删除的锚框
batch_items_to_remove = [] # In case we need to remove any images from the batch, store their indices in this list.
batch_inverse_transforms = []
# 处理要删除的图片
for i in range(len(batch_X)):
if not (self.labels is None):
# Convert the labels for this image to an array (in case they aren't already).
batch_y[i] = np.array(batch_y[i])
# If this image has no ground truth boxes, maybe we don't want to keep it in the batch.
# 没有对应真实框的锚框就不处理了,准备删除
if (batch_y[i].size == 0) and not keep_images_without_gt:
batch_items_to_remove.append(i)
batch_inverse_transforms.append([])
continue
# 如果做另一些数据增强,那就要检查,不合格的删除
# Apply any image transformations we may have received.
if transformations:
inverse_transforms = []
for transform in transformations:
if not (self.labels is None):
if ('inverse_transform' in returns) and ('return_inverter' in inspect.signature(transform).parameters):
batch_X[i], batch_y[i], inverse_transform = transform(batch_X[i], batch_y[i], return_inverter=True)
inverse_transforms.append(inverse_transform)
else:
batch_X[i], batch_y[i] = transform(batch_X[i], batch_y[i])
if batch_X[i] is None: # In case the transform failed to produce an output image, which is possible for some random transforms.
batch_items_to_remove.append(i)
batch_inverse_transforms.append([])
continue
else:
if ('inverse_transform' in returns) and ('return_inverter' in inspect.signature(transform).parameters):
batch_X[i], inverse_transform = transform(batch_X[i], return_inverter=True)
inverse_transforms.append(inverse_transform)
else:
batch_X[i] = transform(batch_X[i])
batch_inverse_transforms.append(inverse_transforms[::-1])
#########################################################################################
# Check for degenerate boxes in this batch item.
#########################################################################################
# 坐标有问题的也不要了
if not (self.labels is None):
xmin = self.labels_format['xmin']
ymin = self.labels_format['ymin']
xmax = self.labels_format['xmax']
ymax = self.labels_format['ymax']
if np.any(batch_y[i][:,xmax] - batch_y[i][:,xmin] <= 0) or np.any(batch_y[i][:,ymax] - batch_y[i][:,ymin] <= 0):
if degenerate_box_handling == 'warn':
warnings.warn("Detected degenerate ground truth bounding boxes for batch item {} with bounding boxes {}, ".format(i, batch_y[i]) +
"i.e. bounding boxes where xmax <= xmin and/or ymax <= ymin. " +
"This could mean that your dataset contains degenerate ground truth boxes, or that any image transformations you may apply might " +
"result in degenerate ground truth boxes, or that you are parsing the ground truth in the wrong coordinate format." +
"Degenerate ground truth bounding boxes may lead to NaN errors during the training.")
elif degenerate_box_handling == 'remove':
batch_y[i] = box_filter(batch_y[i])
if (batch_y[i].size == 0) and not keep_images_without_gt:
batch_items_to_remove.append(i)
#########################################################################################
# Remove any items we might not want to keep from the batch.
#########################################################################################
# 进行删除操作
if batch_items_to_remove:
for j in sorted(batch_items_to_remove, reverse=True):
# This isn't efficient, but it hopefully shouldn't need to be done often anyway.
batch_X.pop(j)
batch_filenames.pop(j)
if batch_inverse_transforms: batch_inverse_transforms.pop(j)
if not (self.labels is None): batch_y.pop(j)
if not (self.image_ids is None): batch_image_ids.pop(j)
if not (self.eval_neutral is None): batch_eval_neutral.pop(j)
if 'original_images' in returns: batch_original_images.pop(j)
if 'original_labels' in returns and not (self.labels is None): batch_original_labels.pop(j)
#########################################################################################
# CAUTION: Converting `batch_X` into an array will result in an empty batch if the images have varying sizes
# or varying numbers of channels. At this point, all images must have the same size and the same
# number of channels.
batch_X = np.array(batch_X)
if (batch_X.size == 0):
raise DegenerateBatchError("You produced an empty batch. This might be because the images in the batch vary " +
"in their size and/or number of channels. Note that after all transformations " +
"(if any were given) have been applied to all images in the batch, all images " +
"must be homogenous in size along all axes.")
#########################################################################################
# If we have a label encoder, encode our labels.
#########################################################################################
# 标签进行编码
if not (label_encoder is None or self.labels is None):
if ('matched_anchors' in returns) and isinstance(label_encoder, SSDInputEncoder):
batch_y_encoded, batch_matched_anchors = label_encoder(batch_y, diagnostics=True)
else:
batch_y_encoded = label_encoder(batch_y, diagnostics=False)
batch_matched_anchors = None
else:
batch_y_encoded = None
batch_matched_anchors = None
#########################################################################################
# Compose the output.
#########################################################################################
# 根据需求返回
ret = []
if 'processed_images' in returns: ret.append(batch_X)
if 'encoded_labels' in returns: ret.append(batch_y_encoded)
if 'matched_anchors' in returns: ret.append(batch_matched_anchors)
if 'processed_labels' in returns: ret.append(batch_y)
if 'filenames' in returns: ret.append(batch_filenames)
if 'image_ids' in returns: ret.append(batch_image_ids)
if 'evaluation-neutral' in returns: ret.append(batch_eval_neutral)
if 'inverse_transform' in returns: ret.append(batch_inverse_transforms)
if 'original_images' in returns: ret.append(batch_original_images)
if 'original_labels' in returns: ret.append(batch_original_labels)
yield ret
好了,今天就到这里了,希望对学习理解有帮助,大神看见勿喷,仅为自己的学习理解,能力有限,请多包涵。















 1371
1371











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









