







参考一步一步带你训练自己的SSD检测算法
问题 :IndexError: too many indices for array
https://github.com/amdegroot/ssd.pytorch/issues/224
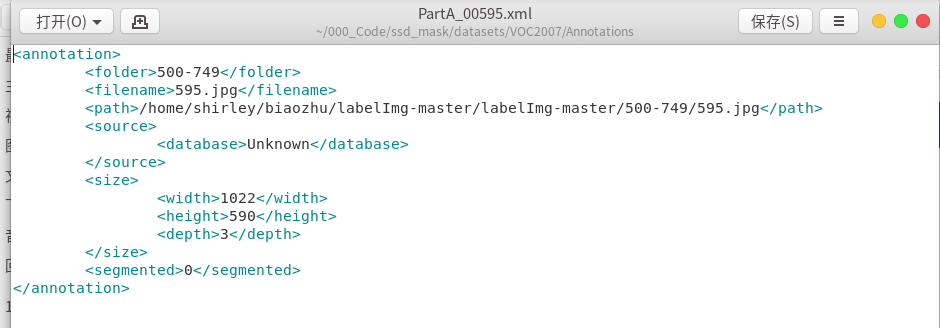
拷贝里面的代码,虽然和我的类是不一样的,我的只有一个person(代码给的类是voc的),但是可以找到里面没有object的xml文件
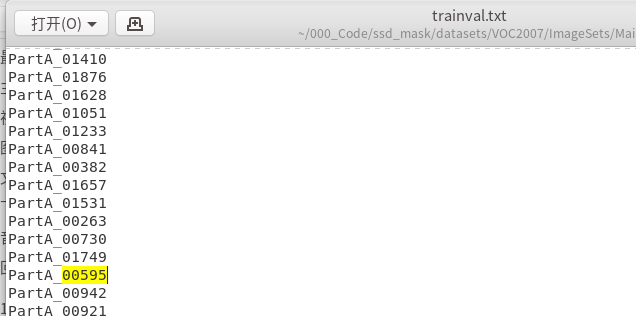
如果没有问题显示的结果如下,有问题会提醒你哪个xml文件里面的object为空

# !usr/bin/env python
# -*- coding:utf-8 _*-
"""
@Author:Linda Lee
@Time:2020/7/10 下午4:56
"""
import argparse
import sys
import cv2
import os
import os.path as osp
import numpy as np
if sys.version_info[0] == 2:
import xml.etree.cElementTree as ET
else:
import xml.etree.ElementTree as ET
parser = argparse.ArgumentParser(
description='Single Shot MultiBox Detector Training With Pytorch')
train_set = parser.add_mutually_exclusive_group()
parser.add_argument('--root', default="datasets/VOC2007", help='Dataset root directory path')
args = parser.parse_args()
CLASSES = ( # always index 0
'person')
annopath = osp.join('%s', 'Annotations', '%s.{}'.format("xml"))
imgpath = osp.join('%s', 'JPEGImages', '%s.{}'.format("jpg"))
if sys.version_info[0] == 2:
import xml.etree.cElementTree as ET
else:
import xml.etree.ElementTree as ET
parser = argparse.ArgumentParser(
description='Single Shot MultiBox Detector Training With Pytorch')
train_set = parser.add_mutually_exclusive_group()
parser.add_argument('--root', help='Dataset root directory path')
args = parser.parse_args()
CLASSES = ( # always index 0
'aeroplane', 'bicycle', 'bird', 'boat',
'bottle', 'bus', 'car', 'cat', 'chair',
'cow', 'diningtable', 'dog', 'horse',
'motorbike', 'person', 'pottedplant',
'sheep', 'sofa', 'train', 'tvmonitor')
annopath = osp.join('%s', 'Annotations', '%s.{}'.format("xml"))
imgpath = osp.join('%s', 'JPEGImages', '%s.{}'.format("jpg"))
def vocChecker(image_id, width, height, keep_difficult = False):
target = ET.parse(annopath % image_id).getroot()
res = []
for obj in target.iter('object'):
difficult = int(obj.find('difficult').text) == 1
if not keep_difficult and difficult:
continue
name = obj.find('name').text.lower().strip()
bbox = obj.find('bndbox')
pts = ['xmin', 'ymin', 'xmax', 'ymax']
bndbox = []
for i, pt in enumerate(pts):
cur_pt = int(bbox.find(pt).text) - 1
# scale height or width
cur_pt = float(cur_pt) / width if i % 2 == 0 else float(cur_pt) / height
bndbox.append(cur_pt)
print(name)
label_idx = dict(zip(CLASSES, range(len(CLASSES))))[name]
bndbox.append(label_idx)
res += [bndbox] # [xmin, ymin, xmax, ymax, label_ind]
# img_id = target.find('filename').text[:-4]
print(res)
try :
print(np.array(res)[:,4])
print(np.array(res)[:,:4])
except IndexError:
print("\nINDEX ERROR HERE !\n")
exit(0)
return res # [[xmin, ymin, xmax, ymax, label_ind], ... ]
if __name__ == '__main__' :
i = 0
for name in sorted(os.listdir(osp.join(args.root,'Annotations'))):
# as we have only one annotations file per image
i += 1
img = cv2.imread(imgpath % (args.root,name.split('.')[0]))
height, width, channels = img.shape
print("path : {}".format(annopath % (args.root,name.split('.')[0])))
res = vocChecker((args.root, name.split('.')[0]), height, width)
print("Total of annotations : {}".format(i))
SSD

Visdom
时间原因首先读了摘要
readme里的visdom我一直不知道是什么
jupyter
而且这个代码是demo.ipynb,要使用jupyter
ipynb interactive python notebook 也就是交互式python记事本, 这个i 代表的 interactive,也就是交互式,我理解为用户可以在这个notebook上操作,比如运行和编辑,然后控制台也会返回给你结果
安装的代码
pip install jupyter
调用的代码,之后会打开浏览器jupyter
jupyter notebook

jupyter让我这个新手小白放弃了
转战b站发现了keras,从此往后是keras的,再搭环境
装好keras之后没有用source activate keraspy36直接在bash环境了装包,然后就把conda整没了,重新安装了anoconda解决了问题
keras搭环境安装依赖
因为参考的代码是参考一下这两个代码的,一个有具体的要求,一个有模糊的要求,所以就按照有具体要求的版本安装了,用==就可以。跑这些会二次利用的网络大代码的时候,还是创建独立的环境比较好,不然跑通一个,另外一个把它的环境更新了,还需要重新安装太费时间。再次强调用清华镜像会很快



conda install keras==2.2.0
conda install opencv-python==3.3.0
如上图安装了对应版本的tensorflow和keras之后,发现存在版本不匹配的问题,readme指定版本的环境真的不要太多坑
这意味着您必须运行在这方面一致的TF和Keras版本,即以相同名称调用此参数的版本。如果运行Keras 2.1.5或更高版本,则还必须运行TF 1.5 / 1.6或更高版本。相反,如果运行TF 1.4或更早版本,则还必须运行Keras 2.1.4或更早版本。
conda uninstall tensorflow
只要一遇到tensorflow我就会把conda整没,如下
source activate keraspy36
Traceback (most recent call last):
File "/home/lyl/anaconda3/bin/conda", line 7, in <module>
from conda.cli import main
ModuleNotFoundError: No module named 'conda'
本来好好的,提出让我更新conda,得我按照shell的命令更新之后,说我的conda又没有了,同样的问题出现过3次,上午的时候,我重新安装旧版本的
就是这个有毒的警告,其实警告不是error不要管也可的,而且很多最新版本的conda对于tensorflow 的兼容并不好,所以不用非更新到最新版本的。

bash Anaconda3-5.1.0-Linux-x86_64.sh -u
完美解决,重新安装anaconda相关信息,但是env中的自定义环境中的安装包不会受影响影响
这次继续安装这个旧版本的就不行了,到网上下载了新的版本
上面是清华镜像的,下面是官网的,但是清华的更新版本不快,相差一年,还是开手机的热点下载比较快
















 3000
3000











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









