









李航《统计学习方法》第二版-第2章 感知机 浅见
2.1 感知机模型
感知机是二分类线性模型,输入为实例的特征向量,输出为类别,-1和1。
目的是求出将数据分离的超平面,基于误分类的损失函数,用梯度下降法进行最小化,求得感知机模型。
感知机的定义简单就是输入空间X,输出Y={1,-1}。即:
f
(
x
)
=
s
i
g
n
(
w
⋅
x
+
b
)
f(x)=sign(w\cdot x+b)
f(x)=sign(w⋅x+b)
w叫权重,就是影响程度,b叫偏置,就是修正偏差用的。其实后面更新的就这两个参数,w就是斜率,旋转多少,w就是平移多少,sign是符号函数,即:
s
i
g
n
(
x
)
=
{
+
1
,
x
≥
0
−
1
,
<
0
sign(x)=\left\{ \begin{aligned} &+1,x \geq 0 \\ &-1 ,< 0 \\ \end{aligned} \right.
sign(x)={+1,x≥0−1,<0
线性方程
w
⋅
x
+
b
=
0
w\cdot x+b=0
w⋅x+b=0对应于特征空间的一个超平面,w是法向量,b是截距。二维就是一条线将样本分成两类,三维空间就是一个平面分割成两部分。简单可以如图所示:
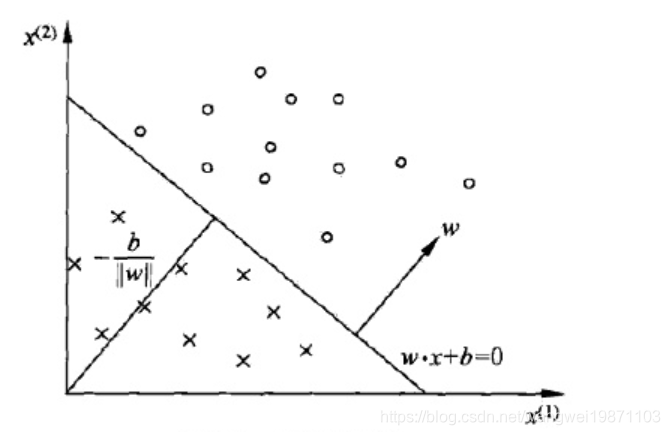
2.2 感知机学习策略
我们应该选择怎么样的感知机呢,就是要定个损失函数。我们当然希望能够分清所有的样本,没有偏差,所以损失函数可以定义成有偏差,就是某个样本到超平面的距离,首先要先选出分类分错的样本,即做
(
x
i
,
y
i
)
(x_i,y_i)
(xi,yi),则分错就是真实的类别和错分的类别相反了,也就是相乘是<0。所以可以是这样:
−
y
i
(
w
⋅
x
i
+
b
)
>
0
-y_i(w\cdot x_i+b)>0
−yi(w⋅xi+b)>0
即真实的和预测的结果异号。因此到超平面的距离是:
−
1
∣
∣
w
∣
∣
y
i
(
w
⋅
x
i
+
b
)
-{\frac {1} {||w||}y_i(w\cdot x_i+b)}
−∣∣w∣∣1yi(w⋅xi+b)
这样所有分类错的点的集合设为M,到超平面的总距离为: − 1 ∣ ∣ w ∣ ∣ ∑ x i ∈ M y i ( w ⋅ x i + b ) -\frac{1}{||w||} \sum_{x_i \in M} y_i(w\cdot x_i+b) −∣∣w∣∣1xi∈M∑yi(w⋅xi+b)
不考虑 1 ∣ ∣ w ∣ ∣ \frac {1} {||w||} ∣∣w∣∣1,这个是常数,就得可以得到感知机学习的损失函数。
对于给定训练集
T
=
(
x
1
,
y
1
)
,
(
x
2
,
y
2
)
,
.
.
.
,
(
x
N
,
y
N
)
T={(x_1,y_1),(x_2,y_2),...,(x_N,y_N)}
T=(x1,y1),(x2,y2),...,(xN,yN)
其中
x
i
∈
X
=
R
n
x_i \in X=R^n
xi∈X=Rn,
y
i
∈
Y
=
{
1
,
−
1
}
y_i\in Y=\{1,-1\}
yi∈Y={1,−1},
i
=
1
,
2
,
.
.
,
N
i=1,2,..,N
i=1,2,..,N。则损失函数定义为:
L
(
w
,
b
)
=
−
∑
x
i
∈
M
y
i
(
w
⋅
x
i
+
b
)
L(w,b)=- \sum_{x_i \in M} y_i(w\cdot x_i+b)
L(w,b)=−xi∈M∑yi(w⋅xi+b)
其中M为分类错误点的集合。
2.3 感知机学习方法
当然采用梯度下降法啦,而且是随机梯度下降法,每次随机选一个错分类的点来进行梯度下降,损失函数的梯度由:
∇
w
L
(
w
,
b
)
=
−
∑
x
i
∈
M
y
i
x
i
\nabla_wL(w,b)=-\sum_{x_i \in M} y_ix_i
∇wL(w,b)=−xi∈M∑yixi
∇
b
L
(
w
,
b
)
=
−
∑
x
i
∈
M
y
i
\nabla_bL(w,b)=-\sum_{x_i \in M} y_i
∇bL(w,b)=−xi∈M∑yi
给出。
随机选取一个错分类点
(
x
i
,
y
i
)
(x_i,y_i)
(xi,yi),对w,b进行更新:
w
←
w
+
η
y
i
x
i
w \leftarrow w+\eta y_ix_i
w←w+ηyixi
b
←
b
+
η
y
i
b \leftarrow b+\eta y_i
b←b+ηyi
其中 η \eta η是步长,也就是学习率,这样就不断的进行,使得最后损失函数不断减小,直到为0。
基本算法就是:
1.选取初值
w
0
,
b
0
w_0,b_0
w0,b0;
2.在训练集上选取数据
(
x
i
,
y
i
)
(x_i,y_i)
(xi,yi);
3.如果
1
∣
∣
w
∣
∣
y
i
(
w
⋅
x
i
+
b
)
≤
0
{\frac {1} {||w||}y_i(w\cdot x_i+b)} \leq0
∣∣w∣∣1yi(w⋅xi+b)≤0,
w
←
w
+
η
y
i
x
i
w \leftarrow w+\eta y_ix_i
w←w+ηyixi
b
←
b
+
η
y
i
b \leftarrow b+\eta y_i
b←b+ηyi
4.转至2,直至训练集中没有错分类的.
很容易理解,就不多说了。做实验会发现,采取不同的初值或者选取不同的错分类点,解可以不同,并且该算法也右收敛性的理论证明,具体可以去看书,我就不写了,因为写了大多人也不会看的哈哈。
还有中算法就是叫对偶形式,名字比较奇怪,其实因为是收敛的,那必定是有限次更新可以完成,所以可以写出训练集之间内积的形式,而且内积可以服用,存在一个矩阵里,其他原理和上面的算法一样。
总结
感知就模型就是二分类的线性模型,利用梯度下降法将错分类降到最低。
好了,今天就到这里了,希望对学习理解有帮助,大神看见勿喷,仅为自己的学习理解,能力有限,请多包涵,部分图片来自网络,侵删。














 572
572











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









