








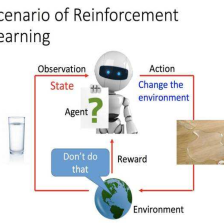

回归的介绍
回归简单来说就是给了输入,然后输出是一个数值,比如下面举的几个例子。
预测股票,输入为以往的很多股票数据,输入是明天的股票指数:
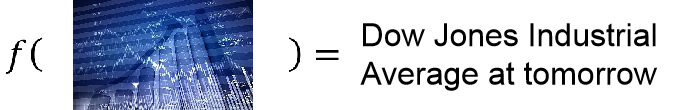
自动驾驶,输入是很多传感器给的信号,比如测距的,摄像头目标检测的等等,输出的一部分可能就是方向盘的转角:
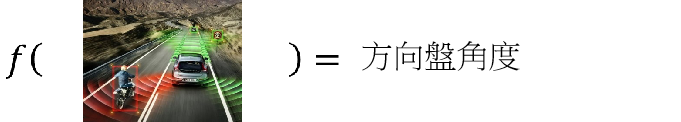
推荐系统,输入是以往购买的产品和用户,输出是购买新产品的可能性。
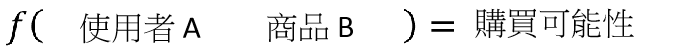
精灵宝可梦的例子
精灵宝可梦大家应该都不陌生吧,一款AR抓宠物的游戏:
 现在我们想预测一只宠物进化后的Combat Power (CP)值是多少,我们先看下宝可梦的样本是怎么样的,如下图:
现在我们想预测一只宠物进化后的Combat Power (CP)值是多少,我们先看下宝可梦的样本是怎么样的,如下图:

可以看到,他有一些属性,比如名字,CP,HP,Weight,Height。我们想通过特征来预测下进化后的CP值。我们把样本即做x,属性分别记作
x
s
,
x
c
p
,
x
h
p
,
x
w
,
x
h
x_{s},x_{cp},x_{hp},x_{w},x_{h}
xs,xcp,xhp,xw,xh,那我们想做的事就是这样:

定义模型
那我们就用上次将的机器学习的方法,定义模型集合,定义最优模型,找出最优模型的方法来解决这个问题。首先当然是定义模型集合啦。我们先简单的定义一个线性模型
y
=
b
+
w
x
y=b+wx
y=b+wx,x是特征,比如HP,CP等等,w可以理解为斜率也叫权重,b可以理解为截距也叫偏置,w和b可以是任何值,因此这个模型的集合是无限的。

给定训练集和损失函数
可以看到,有无穷个模型,上面列出了3个,但是明显
f
3
f_3
f3是不合适的,因为CP不可能是负的。那我们怎么从那么多模型里找出最合适的呢,就要定义一个找出最好模型的方法,也就是损失函数,所以我们需要有训练数据,来告诉模型,真正的数据和结果是怎么样的:

我们收集了10个数据,为了简单,先用一个CP来当特征,
x
c
p
i
x^i _{cp}
xcpi的上标表示第
i
i
i个样本,下标表示用样本的特征CP,我们有10个,同样有10个
y
^
i
\hat{y} ^i
y^i表示第
i
i
i个真实样本进化后CP值。
然后我们要定义一个损失函数,是来衡量模型有多不好,因此我们希望这个函数越小,说明模型越好。

损失函数输入是一个方法,输出是一个值,我们可以把所有样本的预测和真实CP值误差平方累加起来,所以我们可以定义为:
L
(
f
)
=
∑
n
=
1
10
(
y
^
n
−
f
(
x
c
p
n
)
)
2
L(f)=\sum_{n=1}^{10} (\hat y^n -f(x^n _{cp}))^2
L(f)=n=1∑10(y^n−f(xcpn))2
因为模型是跟参数w和b有关的,把f表达式代入,可以转换为:
L
(
w
,
b
)
=
∑
n
=
1
10
(
y
^
n
−
(
b
+
w
⋅
x
c
p
n
)
)
2
L(w,b)=\sum_{n=1}^{10} (\hat y^n -(b+w \cdot x^n _{cp}))^2
L(w,b)=n=1∑10(y^n−(b+w⋅xcpn))2
当然你说找个损失函数要取平均,也对,但是我们这里先按找个简单的来做。
我们可以看下参数和误差之间的关系图:

上图里面的每个点都是一个模型f,对应着的w和b,颜色越浅的区域说明损失越小,可以看到红色的部分是损失大的,上面紫色的是损失小的,比如
y
=
−
180
−
2
⋅
x
c
p
y=-180-2 \cdot x_{cp}
y=−180−2⋅xcp对应的损失就比较大,而上面’X’号对应的损失是比较小的。
选择最好的模型
那我们怎么把最小的那个模型选出来呢,简单说就是选出w和b的值,使得损失函数最小,也就是下面图中的的意思:

那用什么方法选出来呢,我们可以用梯度下降法,这个我在其他文章里有介绍,有兴趣的可以看看,这里来介绍下比较理论的。梯度下降法要做的事可以简单认为一个人要下山,希望找最快的路径下去。这个山的样子就是损失函数,因此那个人希望找到斜率下降最大的地方,然后往下走,每一步都这么走,直到走到下面为止:

我们先假设一个简单的情况,不考虑b,只有w,我们希望找到
w
∗
w^*
w∗,让
L
(
w
)
L(w)
L(w)最小,即
w
∗
=
a
r
g
min
w
L
(
w
)
\displaystyle w^*= arg \min_{w} L(w)
w∗=argwminL(w)接着我们初始化
w
=
w
0
w=w^0
w=w0,然后计算
w
0
w^0
w0点的导数,即
d
L
d
w
∣
w
=
w
0
\left. \frac{dL}{dw} \right| _{w=w^0}
dwdL∣∣w=w0。发现这个斜率是负的,刚好向下山方向,应该右边移动,w增加,如果发现导数是正的,那应该反方向移动,即向左边移动,w减少。所以总结起来就是如果导数是负的,就增加w,如果是正的,就减少w。那应该怎么样去减少或者增加w呢,于是提出了
η
\eta
η学习率,也就是改变的步长,至于改变多少就看导数,所以w的改变就像这样从
w
0
w^0
w0变成了
w
1
w^1
w1,:
w
1
←
w
0
−
η
d
L
d
w
∣
w
=
w
0
w^1\leftarrow w^0-\eta \left. \frac{dL}{dw} \right| _{w=w^0}
w1←w0−ηdwdL∣∣∣∣w=w0
因为导数是负的,根据上面的公式刚好w是增大的,向右走,同理如果是正的,向左走。

如果我们用同样的方法对
w
1
w^1
w1进行更新,会的到
w
2
,
w
3
.
.
.
,
w
n
w^2,w^3...,w^n
w2,w3...,wn,或许我们会达到局部最小值,或许会达到全局最小值,不过在线性回归下,会达到最小值,应为这个函数是凸函数,只有一个最小值。

上面的情况是只有一个参数的时候,如果考虑两个参数,原理也是一样的,见下图,就不多说了:

我们再来看看损失函数图:

可以看到颜色浅的地方损失最小,在中间,我们的梯度下降法就是一步步更新到中间去,梯度方向就是等高线的法线方向,这个可以根据隐函数求导来证明,具体可以查阅百度。有关于梯度下降法的一些可视化的文章,可以看看我的篇文章。上面这个是一种比较理想的情况,很多情况可能不是这样,会比较尴尬:

上面可以看到,如果初始的值运气不好的话,很可能是走到局部最小点去了,而不是全局最小点。当然前面说了线性回归不用担心这个,因为这个是没有局部最小的,右下角等高线图展示了这点。
我们来看下这个损失函数的偏导数计算,学过微积分的应该没啥问题,很简单的求导:

结果
最后的结果也计算出来了,可以看到w和b的值,还有平均的训练集的误差是31.9:

看起来好像还可以,但是我们最终是要求在测试集上测试,要看泛化能力,我们又拿了10个新的数据进行测试,结果如下,测试集的平均误差是35,好像还可以:

那能不能做的更好呢,我们发现在CP比较小和大的时候,测试不太准,所以想是不是模型的能力还不够,或许任天堂在设计的时候不是用一个线性的模型,可能是更加复杂的,所以我们会想要不要试试引入二次式呢,于是我们引入了
x
c
p
2
x_{cp}^2
xcp2项,结果如图,训练和测试的平均误差都小了,右边的两个图是训练集和测试集的拟合情况:

好像好了不少,那我们继续加强模型复杂度,再加三次式,结果跟二次式相差不多:

继续加四次项,这次发现训练集误差依旧小,但是测试集的误差就变大了,结果好像变坏了:

可能是偶然吧,继续加五次想呢,测试集结果更加坏了:

进过上面的一些测试,我们总结下,画出他们的训练集误差图,分析下,这个还是合理的,因为多项式多的肯定包含少的,所以复杂的模型肯定有简单模型的能力,而且可以做的更好,所以训练集误差越来越小:

但是训练集上效果好没用啊,我们还是要看测试集的,训练集上表现好,测试集上不好,这种叫做过拟合,我们可以从表格看到,第三个模型是比较好的:

那为什么会在训练集上表现好,测试集上不好呢,可能是因为模型太复杂,导致输入有一点点变化,输出就变化很大,也就说不平滑,可能是因为训练集样本不够,模型也只学习了一点点东西,以偏概全等等,就像我们考数学,复习的时候都去复习计算题,计算题做的很溜,但是考试的时候遇到应用题了,就尴尬了。所以我们应该选一个不太复杂的,刚刚好的模型,符合奥卡姆剃刀定律。
如果我们收集更多数据,会不会有上面新发现呢:

我们发现好像是有类别的区分,蓝色的点是波波,绿色和黄色的是绿毛虫和独角虫,红色的是伊布,原来样本跟类别特征也有关系,所以只考虑CP值可能是不够的:

所以我们应该重新设计模型,把类别给加进去:

那能不能整个成一个呢,当然可以,可以利用
δ
\delta
δ函数来整合:

如果现在输入的类别
x
s
=
P
i
d
g
e
y
x_s=Pidgey
xs=Pidgey,那式子就变成这样,就是一个线性模型,:

测试结果也还行,但是也是有一些样本误差比较大,或许跟其他特征,比如HP,Weight,Heigh也有关系:

可以看看其他特征的一些分布:

所以我们又开始重新设计模型,把很多特征
x
s
,
x
c
p
,
x
h
p
,
x
w
,
x
h
x_{s},x_{cp},x_{hp},x_{w},x_{h}
xs,xcp,xhp,xw,xh都加进去了,很复杂,果然过拟合了:

那怎么来解决这个问题呢,我们可以用正则化,就是加入一个惩罚项,我也相关的文章,可以参考。

我们再损失函数后面加了一项,是参数的平方项乘以一个
λ
\lambda
λ,
λ
\lambda
λ表示惩罚系数,越大就是惩罚力度越大,参数就会越小,就等于给了参数限制范围,不能太大。为什么我们希望参数越小越好呢,很直观的理解就是,参数越小,当输入有变化的时候,输出不会变化太大,也就是不会太敏感,因此模型就比较平滑,为什么希望不敏感呢,因为这样也比较好的抗噪性,因为很多时候会有噪声样本,可能会影响我们的输出,如果有比较好的抗噪性,就不会造成太大影响:

那我们加入正则化之后,会对结果有什么影响呢,我们来看看实验结果:

可以看到
λ
\lambda
λ的选择很重要,不能太大,也不能太小,当
λ
\lambda
λ增加时训练集误差会增加,因为
λ
\lambda
λ很大的时候,我们就会考虑
λ
∑
(
w
i
)
2
\lambda \sum(w_i)^2
λ∑(wi)2这项,因为我们要最小,当然会先考虑把大的变小,所以会暂时不管前面的项,而前面的项就是训练误差。当
λ
\lambda
λ很大时,模型就很平滑了,参数很小了,极限就变成一个水平线了,是个常数,模型就没啥能力了,所以太大的时候测试误差也变大了。所以我们需要调整
λ
\lambda
λ来选择一个尽可能平滑的模型。
为什么正则化想没有考虑b呢,因为b是偏置,跟平滑程度没什么关系,你可以用最简单的线性模型 y = w x + b y=wx+b y=wx+b来理解,w就是斜率,b就是截距,这个线多平滑,只跟斜率w有关,跟截距b没关系,w越小,线就越水平,越平滑,截距只是一个上下的平移啦。或者你理解成w是一个旋转系数,b是一个平移系数,线的平滑与陡峭只跟w旋转系数有关,w=1比w=0.5陡峭吧,跟平移没关系。
总结
本篇介绍了回归,梯度下降法及其一些问题,过拟合的原因及其解决方法,正则化的原理,通过一个比较接地气的例子把他们都涵盖了,希望能有比较好的理解,对后面的内容学习有帮助。附上思维导图:

好了,今天就到这里了,希望对学习理解有帮助,大神看见勿喷,仅为自己的学习理解,能力有限,请多包涵,图片来自李宏毅课件或者网络,侵删。















 1423
1423











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









