







公司希望使用spark on yarn 模式管理spark应用,在搭建hadoop当中碰到的问题分享一下:
Hadoop Version : 2.7.2
1、Report:Call from linux151 to linux152:9000 failed on connection exception : connection refused
自己碰到的情况是没有启动hdfs服务导致无法连接。 网上还有一种情况说的是配置了core-site.xml 当中的defaultFS 配置项对应的value为主机名时该主机名没有假如到/etc/hosts文件当中,配置hostname即可解决
2、启动hdfs服务后,datanode没有启动,并且日志当中输出:All specified directories are failed to load.
该问题一般是由于name node 节点当中的clusterId 与data node 当中的 clusterId不一致造成,解决方法:比如我配置的namenode位置为/home/wwd/hadoop/dfs/name,datanode位置为/home/wwd/hadoop/dfs/data,那么修改 dfs/data/current/VERSION 文件当中clusterId项,与namenode当中dfs/name/current/VERSION当中的clusterId一致即可,如果为完全集群模式,则所有的namenode和datanode当中的clusterId 应该与master当中一致。
3、集群模式下启动yarn资源管理器后访问http://master:8088 ,点击nodes 后发现某些节点无法正常启动
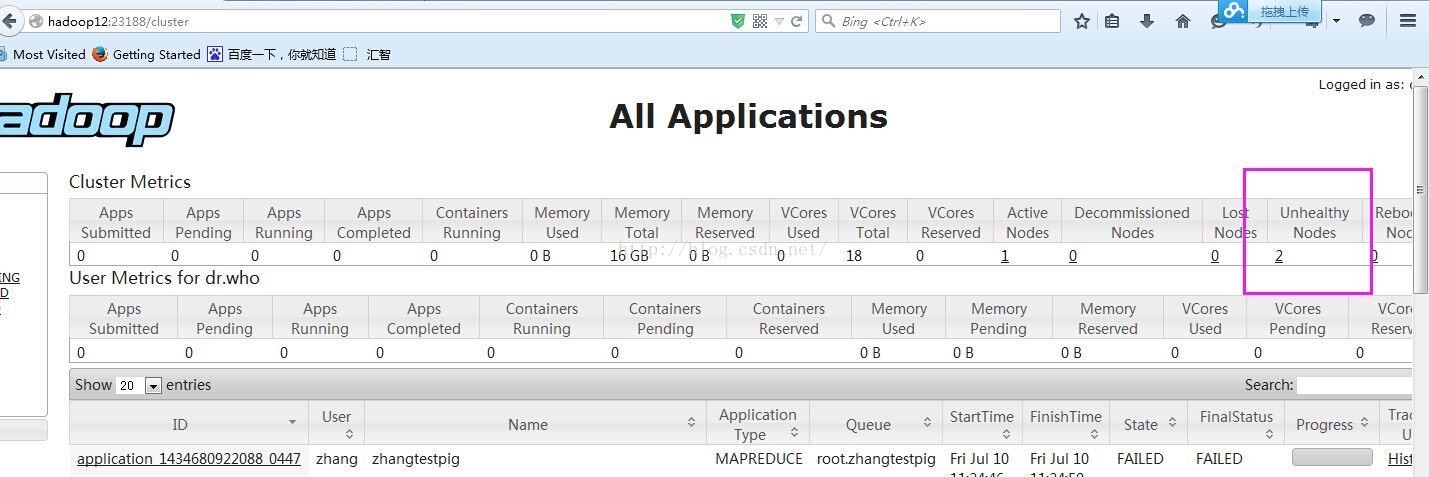
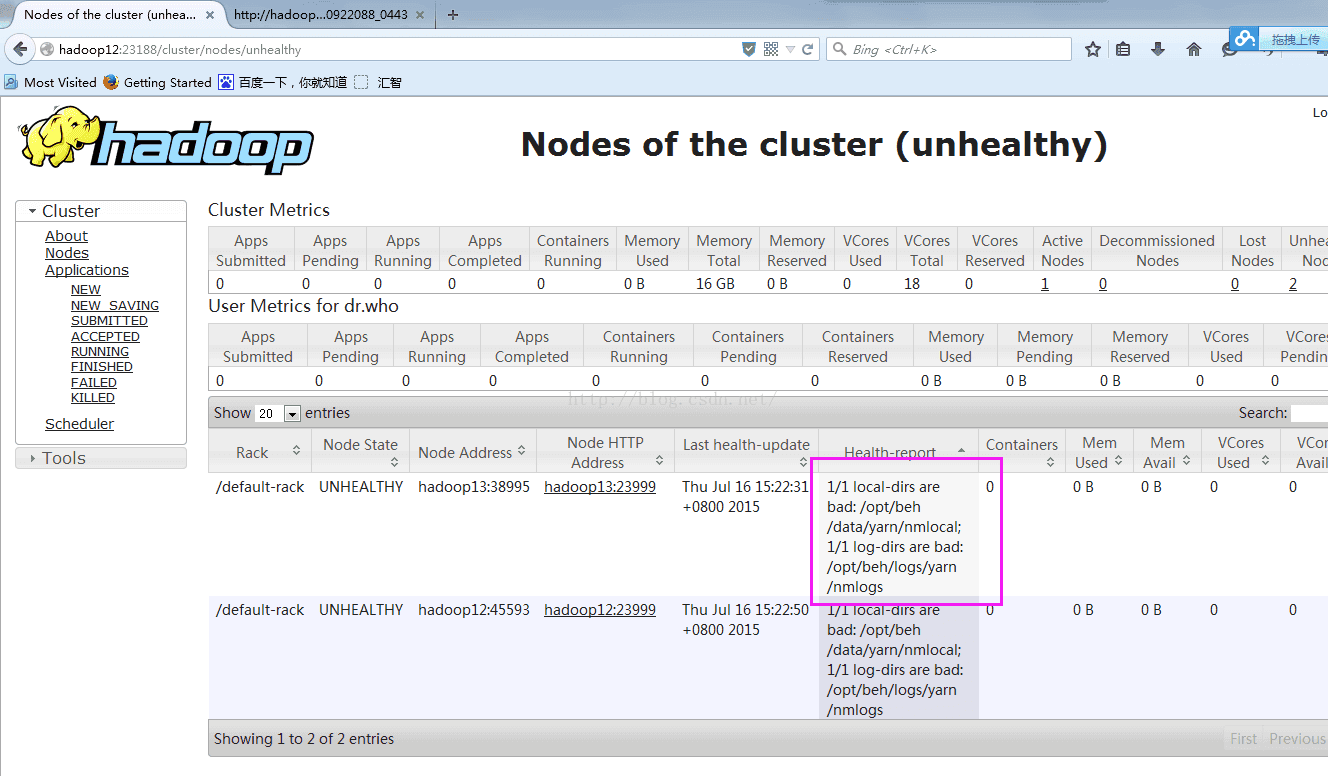
去问题节点上查看Nodemanager相关日志可以发现是由于文件系统使用率达到了90%导致的

删除不需要的垃圾文件,将磁盘使用率降到90%以下即可,注意不需要重启,满足注册条件后hadoop会自动将该节点注册到yarn资源管理器上
注:图片来自其他博主博客















 219
219

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









