







 本文介绍如何在PyTorch中读取LMDB格式的数据集,该数据集常用于深度学习和数据分析任务。通过定义LMDBDataset类,实现了从LMDB文件加载数据并缓存到内存的功能,以便高效访问。
本文介绍如何在PyTorch中读取LMDB格式的数据集,该数据集常用于深度学习和数据分析任务。通过定义LMDBDataset类,实现了从LMDB文件加载数据并缓存到内存的功能,以便高效访问。
python读取特殊格式文件
做深度学习/数据分析,数据读取是基础、必需的一环。特整理,以待后用。
1.pytorch读取lmdb格式文件
内容来源于songlab-cal/tape。
from torch.utils.data import Dataset
from typing import Union, List, Tuple, Sequence, Dict, Any, Optional, Collection
from pathlib import Path
# import torch
import lmdb
import pickle as pkl
import numpy as np
class LMDBDataset(Dataset):
"""Creates a dataset from an lmdb file.
Args:
data_file (Union[str, Path]): Path to lmdb file.
in_memory (bool, optional): Whether to load the full dataset into memory.
Default: False.
"""
def __init__(self,
data_file: Union[str, Path],
in_memory: bool = False):
data_file = Path(data_file)
if not data_file.exists():
raise FileNotFoundError(data_file)
env = lmdb.open(str(data_file), max_readers=1, readonly=True,
lock=False, readahead=False, meminit=False)
with env.begin(write=False) as txn:
num_examples = pkl.loads(txn.get(b'num_examples'))
if in_memory:
cache = [None] * num_examples
self._cache = cache
self._env = env
self._in_memory = in_memory
self._num_examples = num_examples
def __len__(self) -> int:
return self._num_examples
def __getitem__(self, index: int):
if not 0 <= index < self._num_examples:
raise IndexError(index)
if self._in_memory and self._cache[index] is not None:
item = self._cache[index]
else:
with self._env.begin(write=False) as txn:
item = pkl.loads(txn.get(str(index).encode()))
if 'id' not in item:
item['id'] = str(index)
if self._in_memory:
self._cache[index] = item
return item
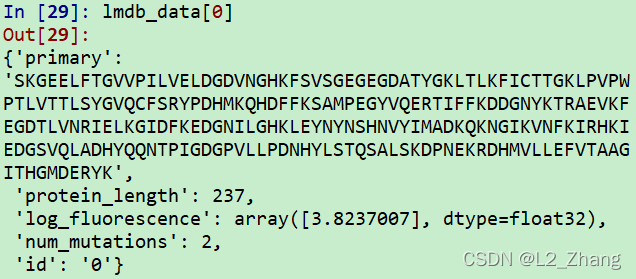
执行下列语句:
lmdb_data = LMDBDataset("../data/fluorescence/fluorescence_train.lmdb")
lmdb_data[0]
参考文献
[1] songlab-cal/tape



















 972
972

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











