







爬虫的价值为我所用
基于数据做自己需要的东西
爬虫架构
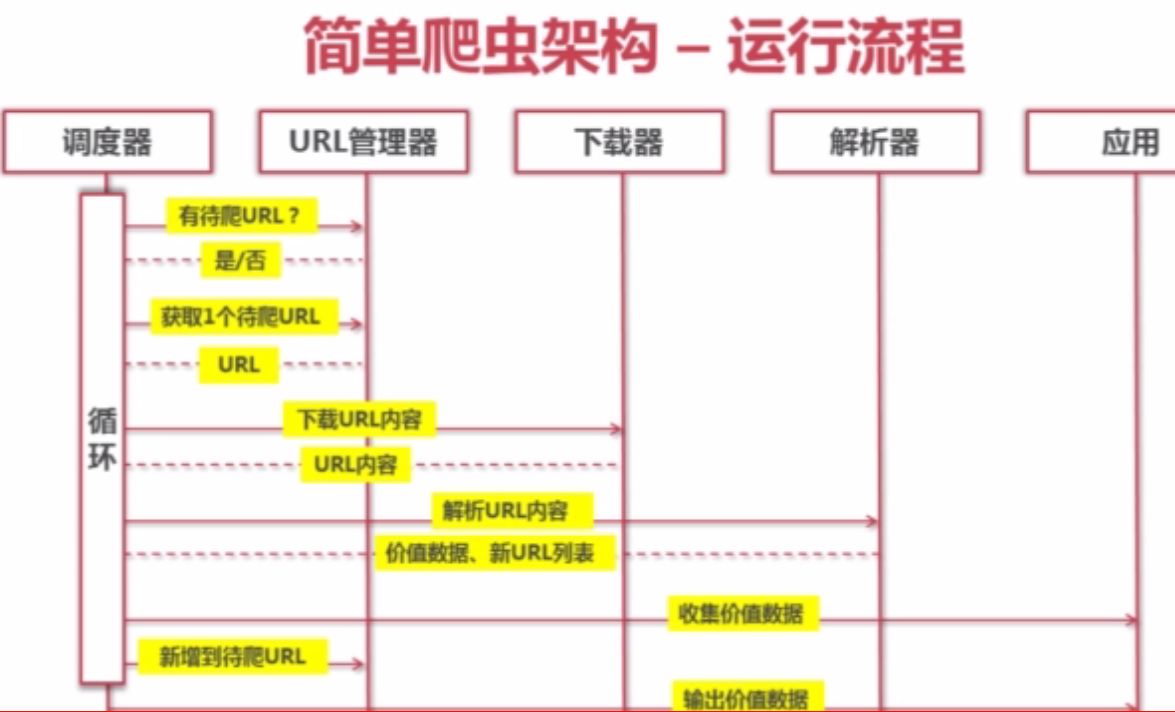
爬虫的调度端 用来启动爬虫,终止爬虫,监视爬虫的运行情况。
|URL管理器 ,对已经爬取的URL和待爬取的URL进行管理。 然后取出一个待爬取的URL传给网页下载器
|网页下载器,网页下载器会将URL指定的网页组成一个字符串。字符串会传给网页解析器
|网页解析器,一方面解析出有价值的东西,另一方面会解析出其他网页的URL,这些URL可以补充进URL管理器
动态运行流程
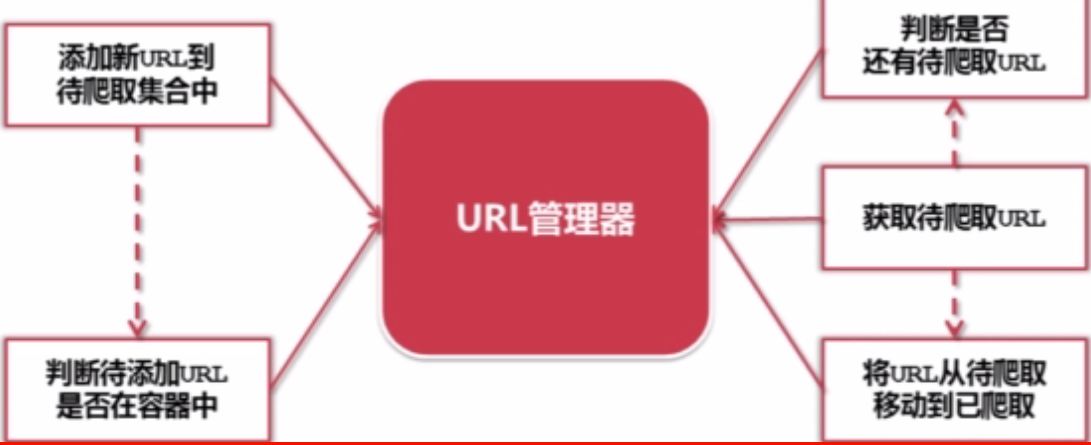
**URL管理器**

两个爬虫同时获取护具的时候的情况
下面是URL管理器流程
实现方式
1.待爬取的URL和已经爬取的URL集合存储在内存,将存储在待爬取的URL:set();已经爬取的URL集合:set();
2.mysql关系型数据库 urls(url,is_crawled)待爬取的URL和已经爬取的URL集合
3.redis缓存数据库 待爬取的URL set;已经爬取的URL集 set.
网页下载器
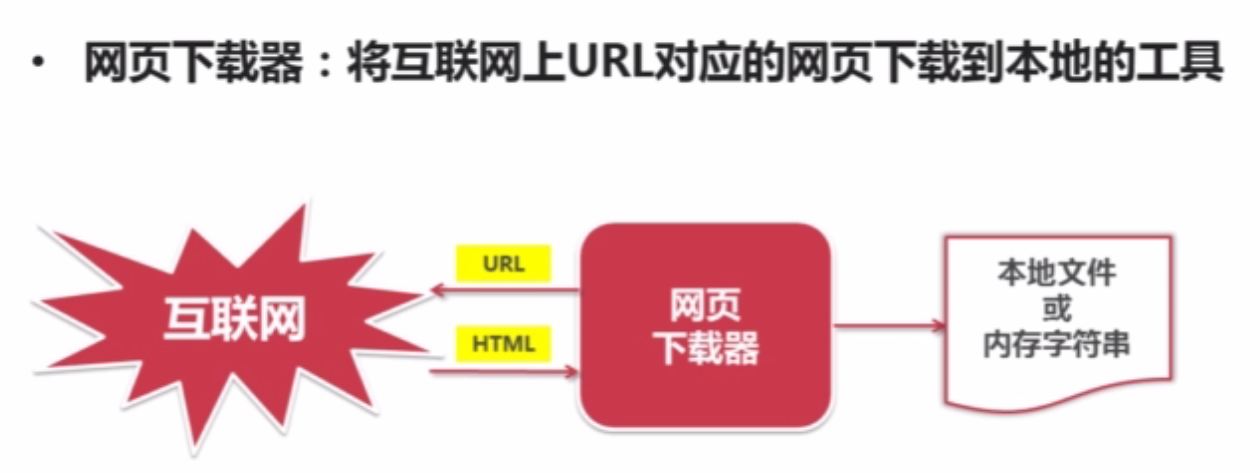
下载器:
urllib2(python官方的基础模块)
rquest
urllib2
方法1:
import urllib2
#直接请求
response = urllib2. urlopen('http://www.csdn.net.com')
#获取状态码
print response.getcode()
cont response.read()方法2:
添加data ,http header
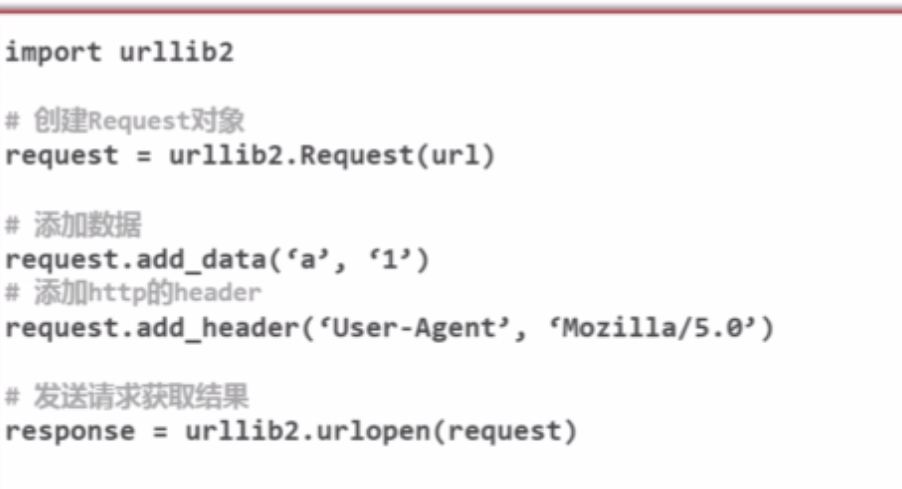
方法3:
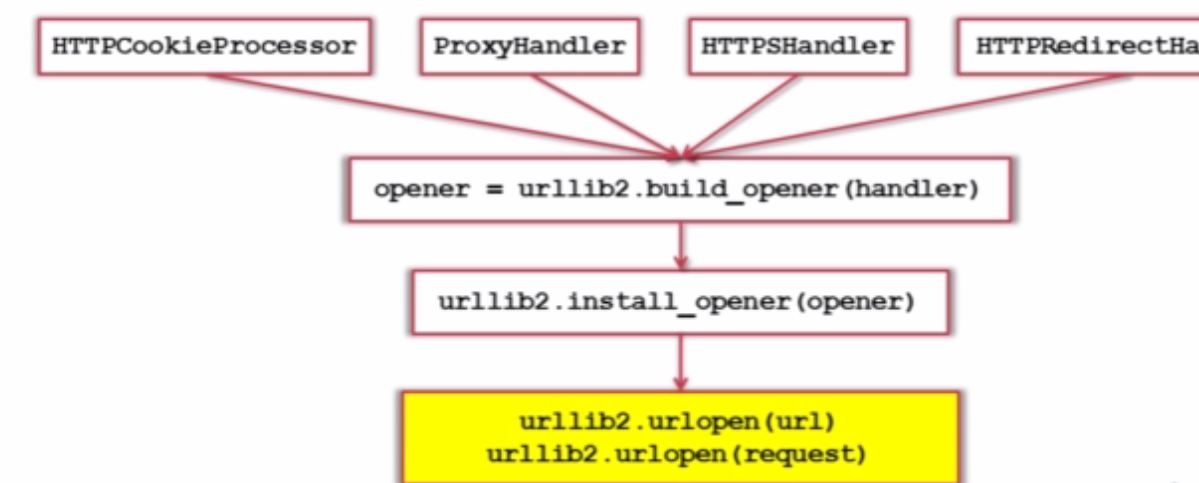
添加特殊情景处理器
















 9065
9065

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









