






爬虫自学(B站 AV9784617 基础)
Requests 库
anaconda自带requests库,如果使用其他IDE,可以以管理员身份打开cmd,输入pip install requests进行安装。安装后,import requests检查是否安装成功。
| 方法 | 说明(括号内是HTTP协议对资源操作方法的说明) |
|---|---|
| requests.request() | 构造一个请求,支撑以下各方法的基础方法 |
| requests.get() | 获取HTML网页的主要方法,对应于HTTP的GET(请求获取URL位置的资源) |
| requests.head() | 获取HTML网页的头信息的方法,对应于HTTP的HEAD(请求获取URL位置资源的响应消息报告,即获取该资源的头部信息) |
| requests.post() | 向HTML网页提交POST请求的方法,对应于HTTP的POST(请求向URL位置的资源后附加新的数据) |
| requests.put() | 向HTML网页提交PUT请求的方法,对应于HTTP的PUT(请求向URL位置存储一个资源,覆盖原URL位置的资源) |
| requests.patch() | 向HTML网页提交局部修改请求,对应于HTTP的PATCH(请求局部更新URL位置的资源,即改变该处资源的部分内容) |
| requests.delete() | 向HTML页面提交删除请求,对应于HTTP的DELETE(请求删除URL位置存储的资源) |
requests.request()
requests.request(method,url,**kwargs)
“method”:请求方式,对应GET/HEAD/POST/PUT/PATCH/delete(小写!)/OPTIONS
“url”:拟获取页面的url连接
“**kwargs”:13个控制访问参数,可选
- params: 字典或字节序列,作为参数增加到url中
kv={'key1':'value1','key2':'value2'}
r=requests.request('GET','http://python123.io/ws',params=kv)
print(r.url)
#https://python123.io/ws?key1=value1&key2=value2
- data: 字典、字节序列或文件对象,作为Request的内容。向服务器提交资源时使用
kv={'key1':'value1','key2':'value2'}
r=requests.request('POST','http://python123.io/ws',data=kv)
body='主题内容'
r=requests.request('POST','http://python123.io/ws',data=body)
#data包含的内容作为url链接对应位置的数据存储
- json: JSON格式的数据,作为Request的内容。作为内容向服务器提交。
- headers: 字典,HTTP定制头
- cookies: 字典或CookieJar, Request中的cookie
- auth: 元组,支持HTTP认证功能
- files: 字典类型,向服务器传输文件
- timeout: 设定超时时间,秒为单位
- proxies: 字典类型,设定访问代理服务器,可以增加登录认证
- allow_redirects: True/False,默认为True,重定向开关
- stream: True/False,默认为True,获取内容立即下载开关
- verify: True/False,默认为True,认证SSL证书开关
- cert: 保存本地SSL证书路径
requests.get()
requests.get(url,params=None,**kwargs)
“params”:url中的额外参数,字典或字节流格式,可选
“**kwargs”:12个控制访问参数(除了requests.request中的params)
r=requests.get(url) 构造一个向服务器请求资源的Request对象,并返回一个包含服务器资源的Response对象给“r”。Response对象有以下几个属性:
| 属性 | 说明 |
|---|---|
| r.status_code | HTTP请求的返回状态,200表示连接成功,404表示失败(只要不是200都表示失败) |
| r.text | HTTP响应内容的字符串形式,即,url对应的页面内容 |
| r.encoding | 从HTTP header中猜测的响应内容编码方式 |
| r.apparent_encoding | 从内容中分析出的响应内容编码方式(备选编码方式) |
| r.content | HTTP响应内容的二进制形式(如果获得图片,图片资源以二进制存储,可以用r.content还原图片) |
r.encoding:如果header中不存在charset,则认为编码为ISO-8859-1
r.apparent_encoding:根据网页内容分析的编码方式,相对来说比r.encoding更加准确
r=requests.get('https://www.bilibili.com/')
r.status-code
#200
r.encoding
#'utf-8'
r.apparent_encoding
#'utf-8'
r.encoding='utf-8'
r.text
#'<!DOCTYPE html><html lang="zh-CN"><head><meta charset="utf-8"><title>哔哩哔哩 (゜-゜)つロ 干杯~-bilibili</title>略其他
其他
-
requests.head(url,**kwargs)
**kwargs: 13个控制访问参数
-
requsts.post(url,data=None,json=None,**kwargs)
data&json: 就是上述控制参数的内容
**kwargs: 11个控制访问参数 -
requests.put(url,data=None,**kwargs)
**kwargs: 12个控制访问参数
-
requests.patch(url,data=None,**kwargs)
**kwargs: 12个控制访问参数
-
requests.delete(url,**kwargs)
**kwargs: 13个控制访问参数
Requests库6种常用连接异常
| 异常 | 说明 |
|---|---|
| requests.ConnectionError | 网络连接错误异常,如DNS查询失败,拒绝连接等(直接访问google主页就会出现这种异常) |
| requests.HTTPError | HTTP错误异常 |
| requests.URLRequired | URL缺失异常 |
| requests.TooManyRedirects | 超过最大重定向(Redirect)次数,产生重定向异常(访问复杂连接时出现)(重定向大概就是由URL转移到新的位置的意思) |
| requests.ConnectTimeout | 连接远程服务器超时异常(连接过程的超时) |
| requests.Timeout | 请求URL超时,产生超时异常(发出URL到获得内容整个过程的超时) |
另外,Response也提供了一种识别异常的方法
r.raise_for_status():如果不是200,产生异常requests.HTTPError。
因此使用这种识别方法就可以搭建爬取网页的通用代码框架,如下:
######通用代码框架#######
import requests
def getHTMLText(url):
try:
r=requests.get(url,timeout=30)
r.raise_for_status()
r.encoding=r.apparent_encoding
return r.text
except:
return '产生异常'
######试验#######
if __name__=='__main__':
url='http://www.bilibili.com'
print(getHTMLText(url))
#正常输出
if __name__=='__main__':
url='www.bilibili.com'
print(getHTMLText(url))
#产生异常
Robots协议
Robots Exclusion Standard 网络爬虫排除标准:网站告知网络爬虫哪些页面可以抓取,哪些不行。
形式:在网站根目录下的robots.txt文件。
查看各网站Robots协议:url/robots.txt(nike的robots.txt确实很有趣)
具体可看什么是robots协议?robots.txt文件怎么写?
BeautifulSoup
BeautifulSoup对应一个HTML/XML文档的全部内容。
Beautiful Soup库解析器
| 解析器 | 使用方法 | 条件 |
|---|---|---|
| bs4的HTML解析器 | BeautifulSoup(mk,‘html.parser’) | 安装bs4库 |
| lxml的HTML解析器 | BeautifulSoup(mk,‘lxml’) | pip install lxml |
| lxml的XML解析器 | BeautifulSoup(mk,‘xml’) | pip install lxml |
| html5lib的解析器 | BeautifulSoup(mk,‘html5lib’) | pip install html5lib |
Beautiful Soup类的基本元素
| 基本元素 | 说明 |
|---|---|
| Tag | 标签,最基本的信息组织单元,分别用<>和</>表明开头和结尾 |
| Name | 标签的名字,<p>…的名字是‘p’,格式:<tag>.name |
| Attributes | 标签的属性,字典形式组织,格式:<tag>.attrs |
| NavigableString | 标签内非属性字符串,<>…</>中字符串,格式:<tag>.string |
| Comment | 标签内字符串的注释部分,一种特殊的Comment类型 |
import requests
from bs4 import BeautifulSoup
r=requests.get('http://python123.io/ws/demo.html')
demo=r.text
soup=BeautifulSoup(demo,'html.parser')
print(soup.prettify())
'''
prettify()为HTML增加换行符,也可以的为每一个标签做处理
返回结果:
<html>
<head>
<title>
This is a python demo page
</title>
</head>
<body>
<p class="title">
<b>
The demo python introduces several python courses.
</b>
</p>
<p class="course">
Python is a wonderful general-purpose programming language. You can learn Python from novice to professional by tracking the following courses:
<a class="py1" href="http://www.icourse163.org/course/BIT-268001" id="link1">
Basic Python
</a>
and
<a class="py2" href="http://www.icourse163.org/course/BIT-1001870001" id="link2">
Advanced Python
</a>
.
</p>
</body>
</html>
'''
tag=soup.a#a链接标签内容,只能返回其中第一个
#<a class="py1" href="http://www.icourse163.org/course/BIT-268001" id="link1">Basic Python</a>
tag.attrs#标签属性,字典
'''
{'href': 'http://www.icourse163.org/course/BIT-268001',
'class': ['py1'],
'id': 'link1'}
'''
tag.string#返回非属性字符串/注释
#'Basic Python'
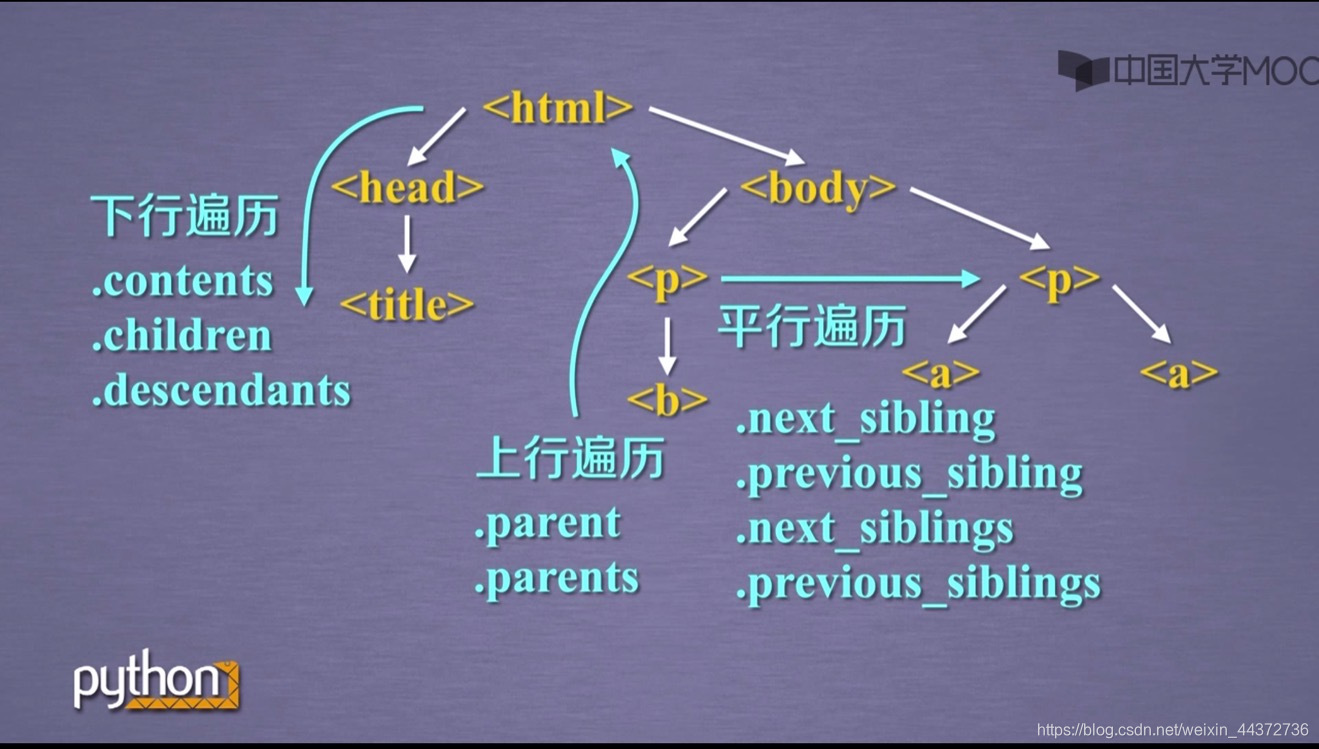
基于bs4库的HTML内容遍历方法
- 标签树的下行遍历:从根节点向叶子节点遍历
| 属性 | 说明 |
|---|---|
| .contents | 子节点的列表,将<tag>所有子节点存入列表 |
| .children | 自己点的迭代类型,与.contents类似,用于循环遍历子节点 |
| .descendants | 子孙节点的迭代类型,包含所有子孙节点,用于循环遍历 |
soup.body.content
'''
返回列表形式
['\n',
<p class="title"><b>The demo python introduces several python courses.</b></p>,
'\n',
<p class="course">Python is a wonderful general-purpose programming language. You can learn Python from novice to professional by tracking the following courses:
<a class="py1" href="http://www.icourse163.org/course/BIT-268001" id="link1">Basic Python</a> and <a class="py2" href="http://www.icourse163.org/course/BIT-1001870001" id="link2">Advanced Python</a>.</p>,
'\n']
'''
len(soup.body.contents) #5
soup.body.contents[0]#'\n'
####遍历#####
for child in soup.body.children(descendants):
print(child)
- 标签树的上行遍历:从叶子节点向根节点遍历
| 属性 | 说明 |
|---|---|
| .parent | 节点的父亲标签 |
| .parents | 节点先辈标签的迭代类型,用于循环遍历先辈节点 |
for parent in soup.a.parents:
if parent is None:
print(parent)
else:
print(parent.name)
'''
p
body
html
[document]
'''
- 标签树的平行遍历:平级节点之间互相遍历
平行遍历需要发生在同一父节点下的各节点之间
| 属性 | 说明 |
|---|---|
| .next_sibling | 返回按照HTML文本顺序的下一个平行节点标签 |
| .previous_sbling | 返回按照HTML文本顺序的上一个平行节点标签 |
| .next_siblings | 迭代类型,返回按照HTML文本顺序的后续所有平行节点标签 |
| .previous_siblings | 迭代类型,返回按照HTML文本顺序的前续所有平行节点标签 |
soup.a.next_sibling
#' and '
'''平行节点直接是存在NavigableString类型,获得的不一定是标签类型'''
for sibling in soup.a.next_siblings(previous_siblings):
print(sibling)
基于bs4库的HTML内容查找方法
<>.find_all(name,attrs,recursive,string,**kwargs)(跟正则表达式一起)
返回一个列表类型,存储查找的结果
name:对标签名称的检索字符串
attrs:对标签属性值的检索字符串,可标注属性检索
recursive:是否对子孙全部检索,默认True
string:<>…</>中字符串区域的检索字符串
<>.find_all() [soup.find_all()] ⟺ \Longleftrightarrow ⟺ <>()[soup()]
######打印所有标签######
for tag in soup.find_all(True):
print(tag.name)
############提取HTML中所有URL链接##############
for link in soup.find_all('a'):
print(link.get('href'))
#http://www.icourse163.org/course/BIT-268001
#http://www.icourse163.org/course/BIT-1001870001
正则表达式
正则表达式常用操作符
| 操作符 | 说明 | 实例 |
|---|---|---|
| . | 表示任何单个字符 | |
| [ ] | 字符集,对单个字符给出取值范围 | [abc]表示a、b、c,[a-z]表示a到z单个字符 |
| [^] | 非字符集,对单个字符给出排除范围 | [^abc]表示非a或b或c的单个字符 |
| * | 前一个字符0次或无限次扩展 | abc*表示ab、abc、abcc、abccc等 |
| + | 前一个字符1次或无限次扩展 | abc+表示abc、abcc、abccc等 |
| ? | 前一个字符0次或1次扩展 | abc?表示ab、abc |
| | | 左右表达式任意一个 | abc|def表示abc、def |
| {m} | 扩展前一个字符m次 | ab{2}c表示abbc |
| {m,n} | 扩展前一个字符m至n次(含n) | ab{1,2}c表示abc,abbc |
| ^ | 匹配字符串开头 | ^abc表示abc且在一个字符串的开头 |
| $ | 匹配字符串结尾 | abc$表示abc且在一个字符串的结尾 |
| ( ) | 分组标记,内部只能使用 | 操作符 | (abc)表示abc,(abc|def)表示abc、def |
| \d | 数字,等价于[0-9] | |
| \w | 单词字符,等价于[A-Za-z0-9_] |
最小匹配操作符
Re库默认贪婪匹配
| 操作符 | 说明 |
|---|---|
| *? | 前一个字符0次或无限次扩展,最小匹配 |
| +? | 前一个字符1次或无限次扩展,最小匹配 |
| ?? | 前一个字符0次或1次扩展,最小匹配 |
| {m,n}? | 扩展前一个字符m至n次(含n),最小匹配 |
实际上就是’?'前面操作符的最小匹配。相当于在原先操作上进行限制。
Re库
re库采用raw string 类型表示正则表达式,表示为:r’text’
raw string是不包含转义符的字符串。(转义符不被解释为转义符)
当正则表达式包含转义符时,使用raw string
Re库主要功能函数
| 函数 | 说明 |
|---|---|
| re.search() | 在一个字符串中搜索匹配正则表达式的第一个位置,返回match对象 |
| re.match() | 从一个字符串的开始位置起匹配正则表达式,返回match对象 |
| re.findall() | 搜索字符串,以列表类型返回全部能匹配的子串 |
| re.split() | 将一个字符串按照正则表达式匹配结果进行分割,返回列表类型 |
| re.finditer() | 搜索字符串,返回一个匹配结果的迭代类型,每个迭代元素是match对象(用于循环) |
| re.sub() | 在一个字符串中替换所有匹配正则表达式的子串,返回替换后的字符串 |
-
re.search(pattern,string,flags=0)
pattern:正则表达式的字符串或原生字符串表示
string:待匹配字符串
flags:正则表达式使用时的控制标记
| 常用标记 | 说明 |
|---|---|
| re.I re.IGNORECASE | 忽略正则表达式的大小写,[A-Z]能够匹配小写字符 |
| re.M re.MULTILINE | 正则表达式中的 ^ 操作符能够将给定字符串的每行当做匹配开始 |
| re.S re.DOTALL | 正则表达式中 . 操作符能够匹配所有字符,默认匹配除换行外的所有字符 |
import re
match = re.search(r'[1-9]\d{5}','BIT 100081')
if match:
print(match.group(0))#match 对象的使用
#100081
#match 输出‘<re.Match object; span=(4, 10), match='100081'>’
- re.match(pattern,string,flags=0)
import re
match = re.match(r'[1-9]\d{5}','BIT 100081')
if match:
print(match.group(0))
#输出为空,因为match是从符合正则表达式的起始位置开始,而改字段起始不符合正则表达式
'''
match.group(0)会报错
所以在输出时最好使用if语句,排除‘空’的情况,防止报错
'''
import re
match = re.match(r'[1-9]\d{5}','100081 BIT')
if match:
print(match.group(0))
#100081
- re.findall(pattern,string,flags=0)
import re
ls = re.findall(r'[1-9]\d{5}','BIT100081 TSU100084')
#['100081', '100084'] 与上述不同,返回一个列表
-
re.split(pattern,string,maxsplit=0,flags=0)
maxsplit:最大分割数,剩余部分作为最后一个元素输出
re.split(r'[1-9]\d{5}','BIT100081 TSU100084')
#['BIT', ' TSU', '']
#匹配的正则表达式去掉,剩下的部分分别作为字符串放入列表
re.split(r'[1-9]\d{5}','BIT100081 TSU100084',maxsplit=1)
#['BIT', ' TSU100084']
#只匹配第一个,剩下部分不再进行正则表达式匹配,以一个完整的部分作为列表最后部分
re.split(r'[1-9]\d{5}','BIT100081 TSU100084 BJF100083',maxsplit=1)
#['BIT', ' TSU100084 BJF100083']
- re.finditer(pattern,string,flags=0)
import re
for m in re.finditer(r'[1-9]\d{5}','BIT100081 TSU100084'):
if m:
print(m.group(0))
#100081
#100084
- re.sub(pattern,repl,string,count=0,flags=0)
repl:替换匹配字符串的字符串
count:匹配的最大替换次数
import re
re.sub(r'[1-9]\d{5}',':zipcode','BIT100081 TSU100084')
#'BIT:zipcode TSU:zipcode'
re.sub(r'[1-9]\d{5}',':zipcode','BIT100081 TSU100084',count=1)
#'BIT:zipcode TSU100084'
Re库的等价用法
- 函数式用法:一次性操作
rst = re.search(r’[1-9]\d{5}’,‘100081 BIT’)
- 面向对象用法:编译后的多次操作
pat = re.compile(r’[1-9]\d{5}’)
rst = pat.search(‘100081 BIT’)
regex=re.compile(pattern,flags=0)
将正则表达式的字符串形式编译成正则表达式对象,regex就可以使用各种函数方法
Re库的Match对象
Match对象的属性
match=re.search(r’[1-9]\d{5}’,‘BIT 100081’)
| 属性 | 说明 |
|---|---|
| .string | 待匹配的文本 ‘BIT 100081’ |
| .re | 匹配时使用的pattern对象(正则表达式) re.compile(r’[1-9]\d{5}’, re.UNICODE) |
| .pos | 正则表达式搜索文本的开始位置 0 |
| .endpos | 正则表达式搜索文本的结束位置 10 |
Match对象的方法
| 方法 | 说明 |
|---|---|
| .group(0) | 获得匹配后的字符串 ‘100081’ |
| .start() | 匹配字符串在原始字符串的开始位置 4 |
| .end() | 匹配字符串在原始字符串的结束位置 10 |
| .span() | 返回(.start(0,.end()) (4, 10) |
Scrapy
重新开了一篇,Scrapy会不断往里面加东西。
(逐渐开始套娃)
使用fake-useragent对User-Agent进行伪装
pip install fake-useragent#安装
from fake_useragent import UserAgent
ua=UserAgent()
#这个时候可能报错
#“fake_useragent.errors.FakeUserAgentError: Maximum amount of retries reached”
#只要“pip install -U fake-useragent”更新一下就可以
print(ua.random)
#Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:21.0) Gecko/20130331 Firefox/21.0
print(ua.random)
#Mozilla/5.0 (Windows NT 6.3; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/41.0.2225.0 Safari/537.36
#使用时
headers={'User-Agent':str(ua.random)}
r=requests.get(url,headers=headers)
例子
获取图片/视频
import requests
path='F:/abc.jpg'
url='http://img0.dili360.com/ga/M00/03/DB/wKgBzFRvBHyAdJRkAAaKCZvDQSA769.tub.jpg@!rw14'
r=requests.get(url)
with open(path,'wb') as f:#传入标识符'w'或者'wb'表示写文本文件或写二进制文件,读是'r'或'rb'
f.write(r.content)
#在对应path位置已保存该图片
#可用if循环
中国大学排名定向爬虫
import requests
import bs4
from bs4 import BeautifulSoup
# 爬取网络信息,返回html信息
def getHTMLText(url):
try:
r=requests.get(url, timeout = 30)
r.raise_for_status()
r.encoding = r.apparent_encoding
return r.text
except:
return ''
return ''
# 提取html关键数据,并添到一个列表中
def fillUnivList(ulist,html):
soup=BeautifulSoup(html,'html.parser')
for tr in soup.find('tbody').children:
if isinstance(tr, bs4.element.Tag):#检测tr类型
tds = tr('td')
ulist.append([tds[0].string,tds[1].string,tds[3].string])
def printUnivList(ulist,num):
tplt='{0:<10}\t{1:{3}<15}\t{2:<10}'#{3}是指填充时按照format[3]填充,即中文
print(tplt.format('排名','学校名称','总分',chr(12288)))
for i in range(num):
u=ulist[i]
print(tplt.format(u[0],u[1],u[2],chr(12288)))
def main():
uinfo = []#大学信息
url='http://www.zuihaodaxue.com/zuihaodaxuepaiming2019.html'
html=getHTMLText(url)
fillUnivList(uinfo,html)
printUnivList(uinfo,20)# 20 univs
main()
股票数据定向爬虫
目标:获取上交所和深交所所有股票的名称和交易信息
输出:保存到文件中
选取网站原则:股票信息静态存在于HTML页面中,非js代码生成,没有Robots协议限制
使用网站:http://quote.eastmoney.com/stock_list.html & https://www.laohu8.com/stock
import requests
from bs4 import BeautifulSoup
import re
import traceback
from fake_useragent import UserAgent
def getHTMLText(url,headers):
try:
r = requests.get(url,headers=headers,timeout=30)
r.raise_for_status()
r.encoding = r.apparent_encoding
return r.text
except:
return ''
#输出股票列表和股票网站
def getStockList(lst,stockURL,headers):
html = getHTMLText(stockURL,headers)
soup = BeautifulSoup(html, 'html.parser')
a = soup.find_all('a')
for i in a:
try:
href = i.attrs['href']#获得href下内容
lst.append(re.findall(r'[s][hz]\d{6}',href)[0])#本来返回一个列表,将内容提取出来再存放入列表
#对于demo来说
#re.findall(r'\d{6}',tag.attrs['href'])
#['268001']
# re.findall(r'\d{6}',tag.attrs['href'])[0]
#'268001'
except:
continue
#获得个股信息
def getStockInfo(lst,stockURL,fpath,headers):
for stock in lst:
num = re.findall(r'\d{6}',stock)[0]
url = stockURL + num
html = getHTMLText(url, headers)
try:
if html == '':
continue
infoDict = {}
soup = BeautifulSoup(html,'html.parser')
stockInfo = soup.find('div',attrs={'class':'stock-main'})
name = stockInfo.find_all(attrs={'class':'stock-name'})[0]
infoDict.update({'股票名称':name.text.split()[0]})
#所有信息分装在<dt>和<dd>中
keyList = stockInfo.find_all('dt')
valueList = stockInfo.find_all('dd')
for i in range(len(keyList)):
key = keyList[i].text
val = valueList[i].text
infoDict[key] = val
with open(fpath,'a',encoding='utf-8') as f:
f.write(str(infoDict)+'\n')
except:
traceback.print_exc()
continue
def main():
stock_list_url = 'http://quote.eastmoney.com/stock_list.html'
stock_info_url = 'https://www.laohu8.com/stock/'
output_file = 'F://LaoHuStockInfo.txt'
slist = []#股票信息
ua = UserAgent()
header = {'User-Agent':str(ua.random)}
getStockList(slist,stock_list_url,header)
getStockInfo(slist,stock_info_url,output_file,header)
main()
结语
这一篇关于北理嵩天老师的爬虫笔记就结束辽。总的来说还是比较基础的视频,但是还是有很多内容需要我慢慢消化。然后就是踏上了自学之路。
笔记有一点乱,看的朋友多担待,大佬们有什么建议的欢迎来提啊,小白在这里先感谢一波!














 7781
7781











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









