







当我们在浏览器的地址栏输入 www.linux178.com ,然后回车,回车这一瞬间到看到页面到底发生了什么呢?
整个流程如下:
1、域名解析
2、发起TCP的3次握手
3、建立TCP连接后发起http请求
4、服务器响应http请求,浏览器得到html代码
5、浏览器解析html代码,并请求html代码中的资源(如js、css、图片等)
6、浏览器对页面进行渲染呈现给用户
以下就是上面过程的一一分析,我们就以Chrome浏览器为例:
域名解析
首先Chrome浏览器会解析 www.linux178.com 这个域名对应的IP地址。怎么解析到对应的IP地址?
Chrome浏览器会首先搜索浏览器自身的DNS缓存(缓存时间比较短,大概只有1分钟,且只能容纳1000条缓存)。
如果浏览器自身缓存找不到则会查看系统的DNS缓存,如果找到且没有过期则停止搜索解析到此结束.
而如果本机没有找到DNS缓存,则浏览器会发起一个DNS的系统调用,就会向本地配置的首选DNS服务器发起域名解析请求(通过的是UDP协议向DNS的53端口发起请求,这个请求是递归的请求,也就是运营商的DNS服务器必须得提供给我们该域名的IP地址),运营商的DNS服务器首先查找自身的缓存,找到对应的条目,且没有过期,则解析成功。
如果没有找到对应的条目,则有运营商的DNS代我们的浏览器发起迭代DNS解析请求,它首先是会找根域的DNS的IP地址(这个DNS服务器都内置13台根域的DNS的IP地址),找打根域的DNS地址,就会向其发起请求(请问www.linux178.com这个域名的IP地址是多少啊?),根域发现这是一个顶级域com域的一个域名,于是就告诉运营商的DNS我不知道这个域名的IP地址,但是我知道com域的IP地址,你去找它去,于是运营商的DNS就得到了com域的IP地址,又向com域的IP地址发起了请求(请问www.linux178.com这个域名的IP地址是多少?),com域这台服务器告诉运营商的DNS我不知道www.linux178.com这个域名的IP地址,但是我知道linux178.com这个域的DNS地址,你去找它去,于是运营商的DNS又向linux178.com这个域名的DNS地址(这个一般就是由域名注册商提供的,像万网,新网等)发起请求(请问www.linux178.com这个域名的IP地址是多少?),这个时候linux178.com域的DNS服务器一查,诶,果真在我这里,于是就把找到的结果发送给运营商的DNS服务器,这个时候运营商的DNS服务器就拿到了www.linux178.com这个域名对应的IP地址,并返回给Windows系统内核,内核又把结果返回给浏览器,终于浏览器拿到了www.linux178.com对应的IP地址,该进行一步的动作了。
发起TCP的3次握手
拿到域名对应的IP地址之后,User-Agent(一般是指浏览器)会以一个随机端口(1024< 端口 < 65535)向服务器的WEB程序(常用的有httpd,nginx等)80端口发起TCP的连接请求。这个连接请求(原始的http请求经过TCP/IP4层模型的层层封包)到达服务器端后(这中间通过各种路由设备,局域网内除外),进入到网卡,然后是进入到内核的TCP/IP协议栈(用于识别该连接请求,解封包,一层一层的剥开),还有可能要经过Netfilter防火墙(属于内核的模块)的过滤,最终到达WEB程序(本文就以Nginx为例),最终建立了TCP/IP的连接。
为什么HTTP协议要基于TCP来实现?
TCP是一个端到端的可靠的面向连接的协议,所以HTTP基于传输层TCP协议不用担心数据的传输的各种问题。
建立TCP连接后发起http请求
进过TCP3次握手之后,浏览器发起了http的请求,使用的http的方法 GET 方法,请求的URL是 / ,协议是HTTP/1.0

上图为3次握手的内容,并且发起get请求。http报文请求如下:
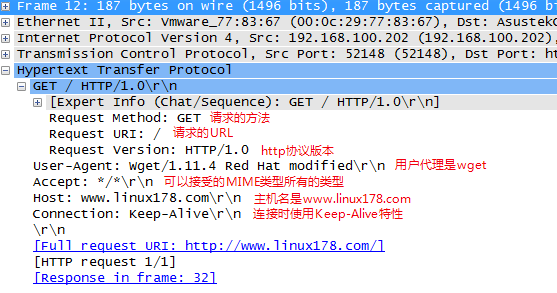
服务器端响应http请求,浏览器得到html代码
服务器端WEB程序接收到http请求以后,就开始处理该请求,处理之后就返回给浏览器html文件。
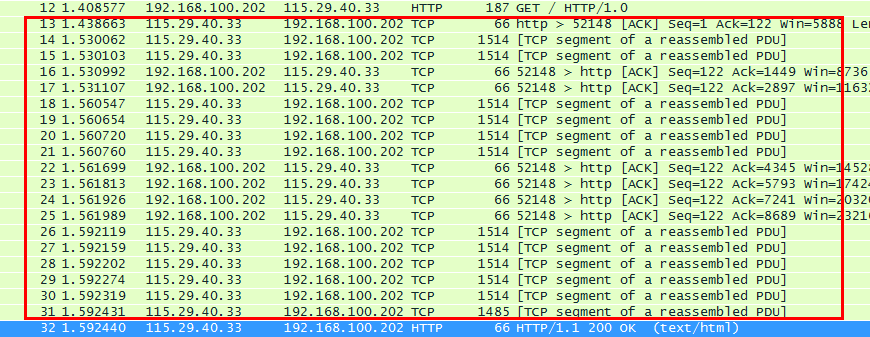
第32号包 是服务器返回给客户端http响应包(200 ok 响应的MIME类型是text/html),代表这一次客户端发起的http请求已成功响应。200 代表是的 响应成功的状态码。
浏览器解析html代码,并请求html代码中的资源
浏览器拿到index.html文件后,就开始解析其中的html代码,遇到js/css/image等静态资源时,就向服务器端去请求下载(会使用多线程下载,每个浏览器的线程数不一样),这个时候就用上keep-alive特性了,建立一次HTTP连接,可以请求多个资源。
浏览器在请求静态资源时(在未过期的情况下),向服务器端发起一个http请求(询问自从上一次修改时间到现在有没有对资源进行修改),如果服务器端返回304状态码(告诉浏览器服务器端没有修改),那么浏览器会直接读取本地的该资源的缓存文件。
浏览器对页面进行渲染呈现给用户
最后,浏览器利用自己内部的工作机制,把请求到的静态资源和html代码进行渲染,渲染之后呈现给用户。















 443
443

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









