







目录
2、match、match_phrase、multi_math查询
3、简单介绍:must、must_not、should、query/filter
2)must_not(必须不匹配must_not所列举的所有条件)
4、复合查询:bool、boosting、constant_score、dis_max
3)costant_score(Constant score query)
4)dis_max(Disjunction max query)
Elasticsearch提供了一个可以执行查询的Json风格的DSL(domain-specific language领域特定语言)这个被称为Query DSL,该查询语言非常全面;
一个查询语句的典型结构:
//如果针对于某个字段,那么它的结构如下:
{
QUERY_NAME:{ # 使用的功能
FIELD_NAME:{ # 功能参数
ARGUMENT:VALUE,
ARGUMENT:VALUE,...
}
}
}
//示例:
GET bank/_search
{
"query": { # 查询的字段
"match_all": {}
},
"from": 0, # 从第几条文档开始查
"size": 5,
"sort": [
{
"account_number": { # 返回结果按哪个列排序
"order": "desc" # 降序
}
}
],
"_source": ["balance","firstname"] #_source为要返回的字段
}
//结果:
{
"took" : 18, # 花了18ms
"timed_out" : false, # 没有超时
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 1000, # 命令1000条
"relation" : "eq"
},
"max_score" : null,
"hits" : [
{
"_index" : "bank",
"_type" : "account",
"_id" : "999", # 第一条数据id是999
"_score" : null, # 得分信息
"_source" : {
"firstname" : "Dorothy",
"balance" : 6087
},
"sort" : [ # 排序字段的值
999
]
},
省略.....
1、如何通过官网学习Query DSL
es官网学习DSL,官网地址:免费且开放的搜索:Elasticsearch、ELK 和 Kibana 的开发者 | Elastic
1.访问官网地址,点击文档产品指南
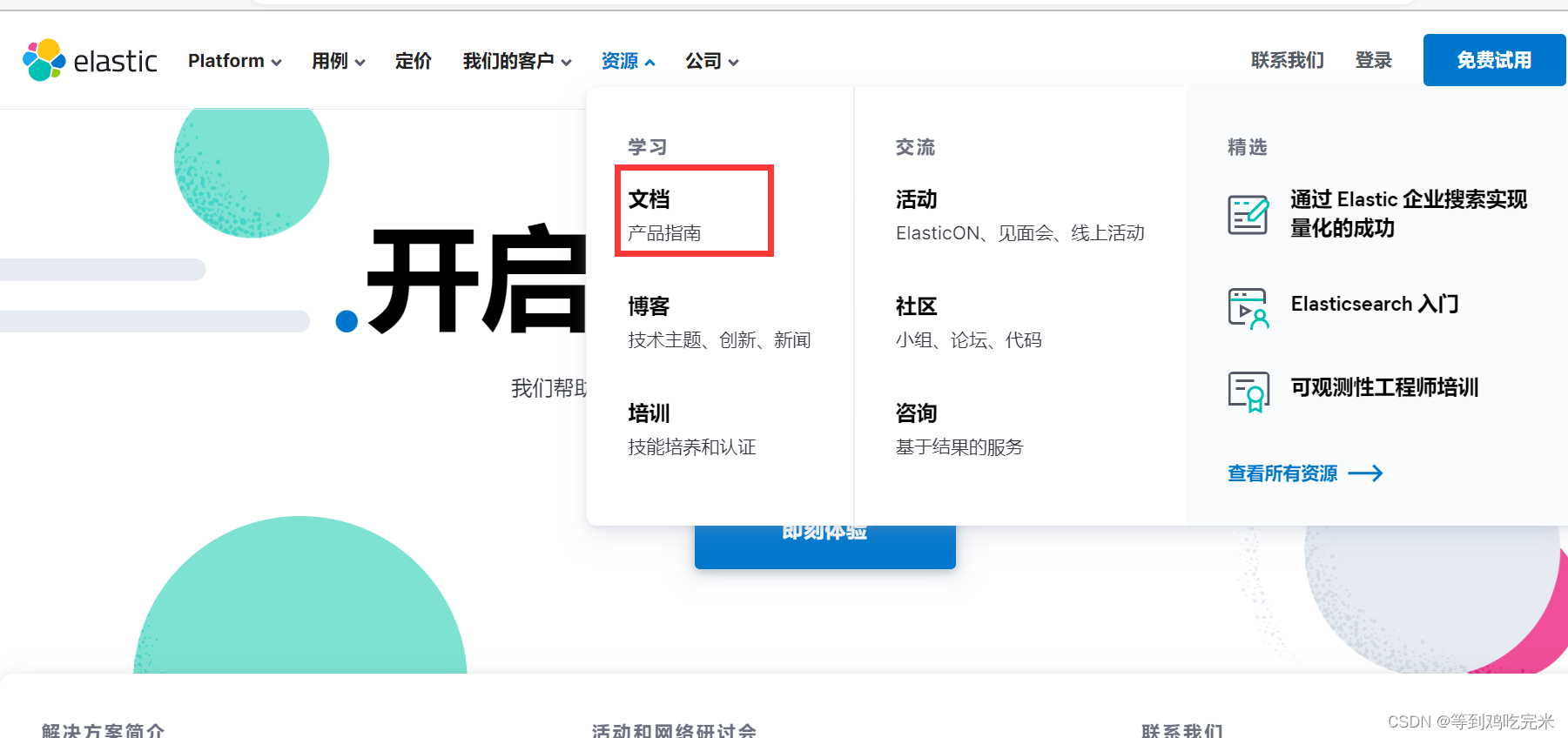
2.找到Elasticsearch: Store, Search, and Analyze,选择other versions
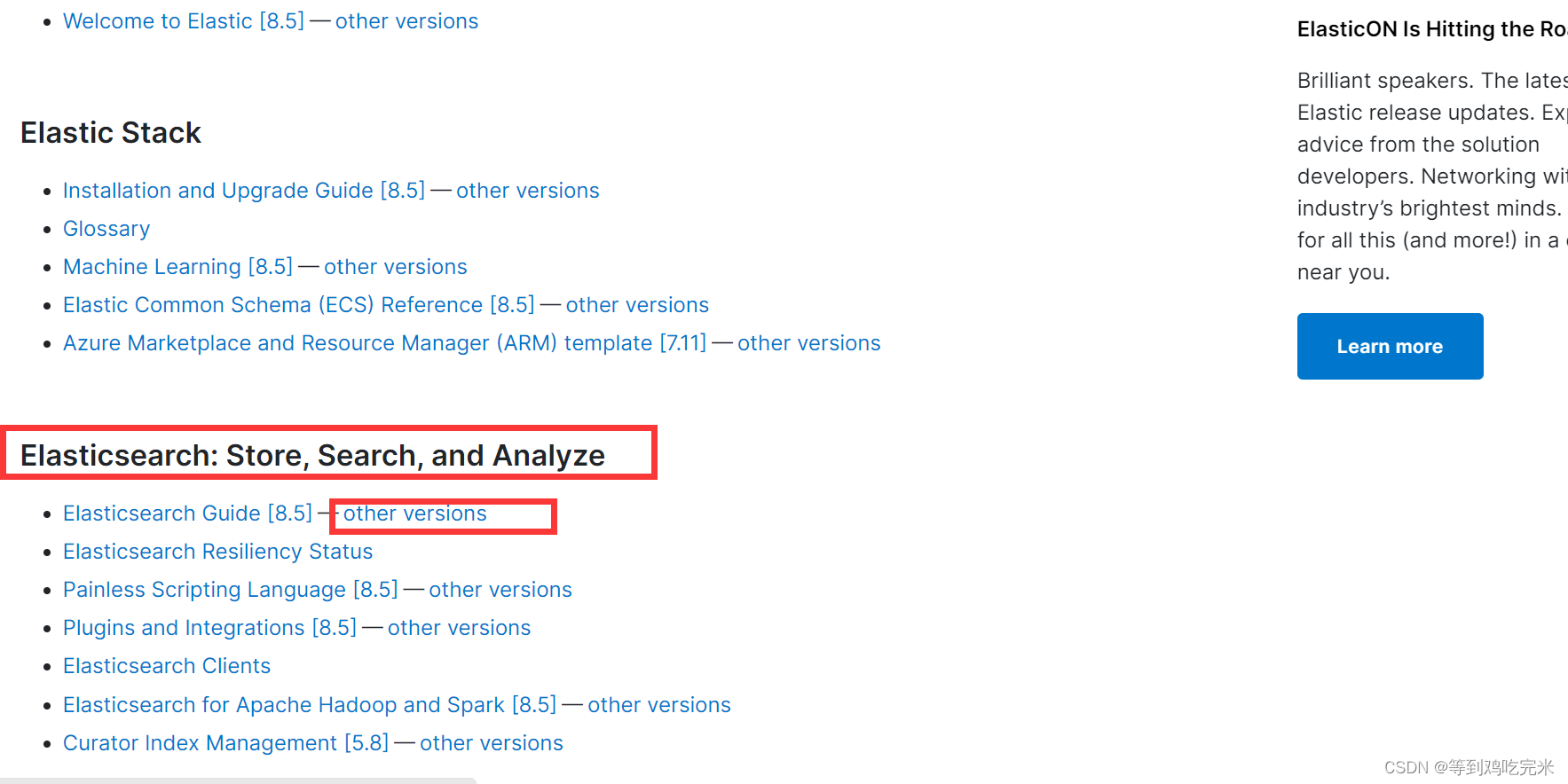
3.根据安装的Elasticsearch版本选择合适的版本
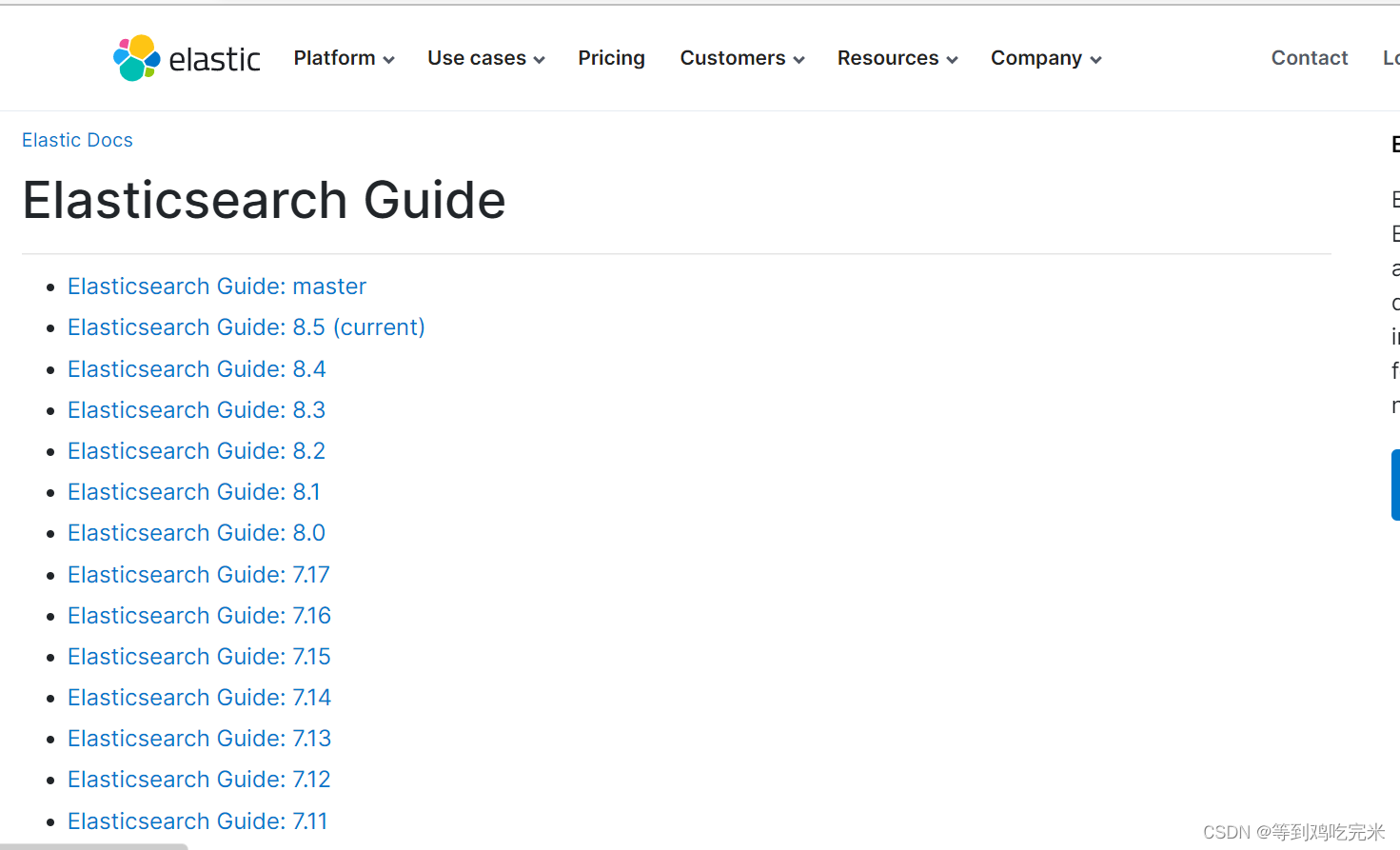
4.点击选择完版本后我们可以看到mapping、DSL等说明
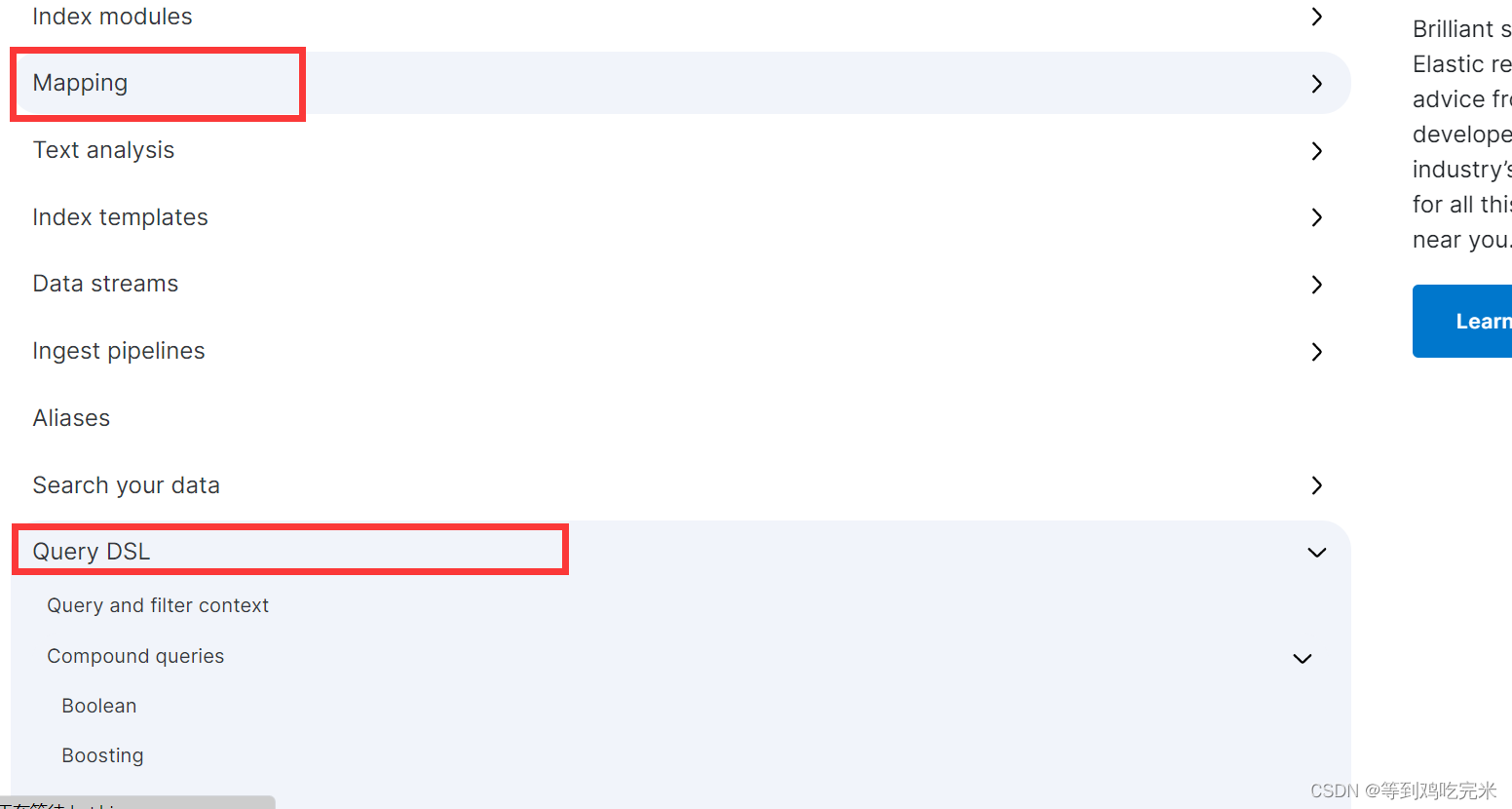
5.我们随便选择一个bool复合查询,可以看到它的详细介绍
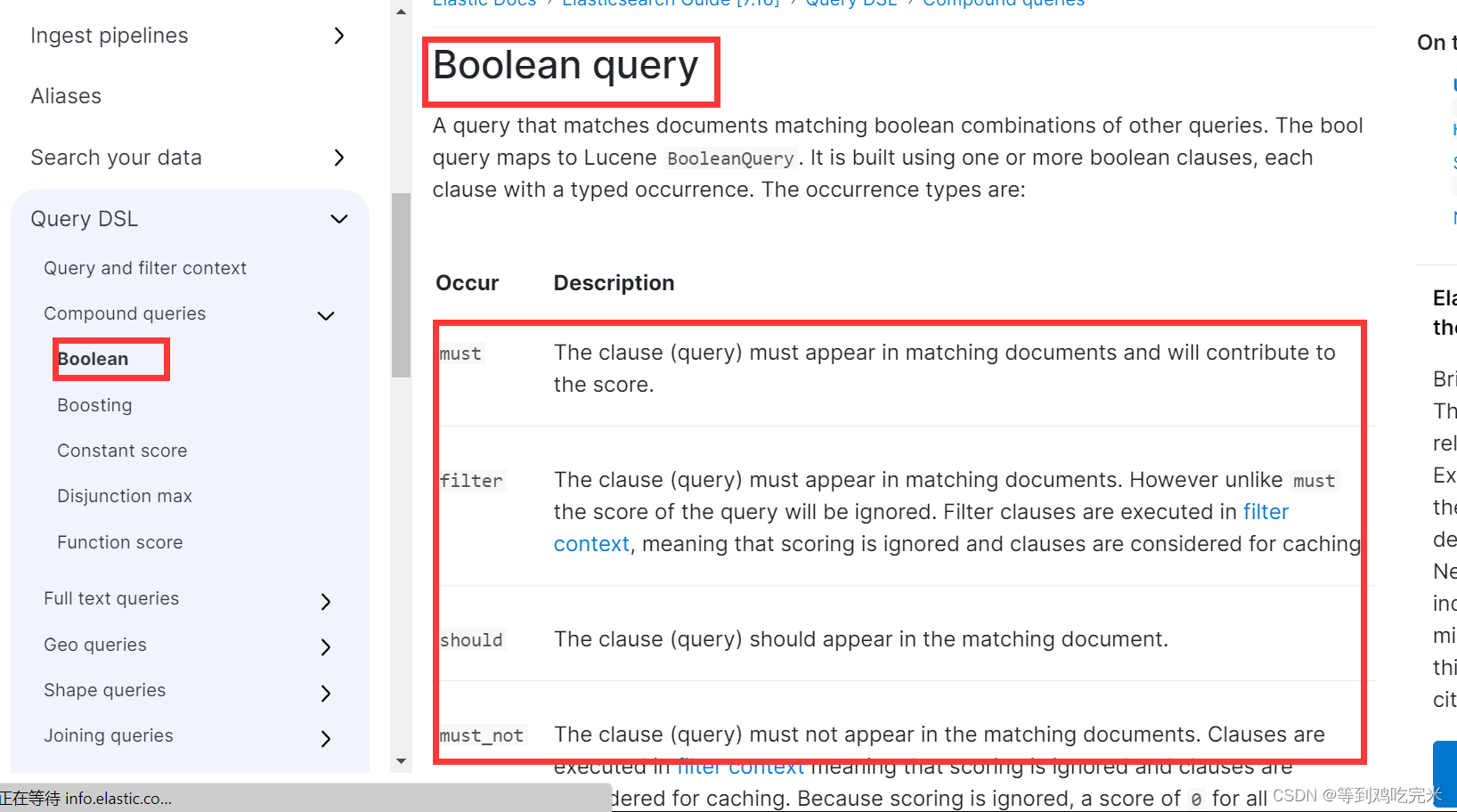
6.往下翻我们还可以看到它的语法DSL语句,点击下边的copy as curl 还可以转化为curl语句
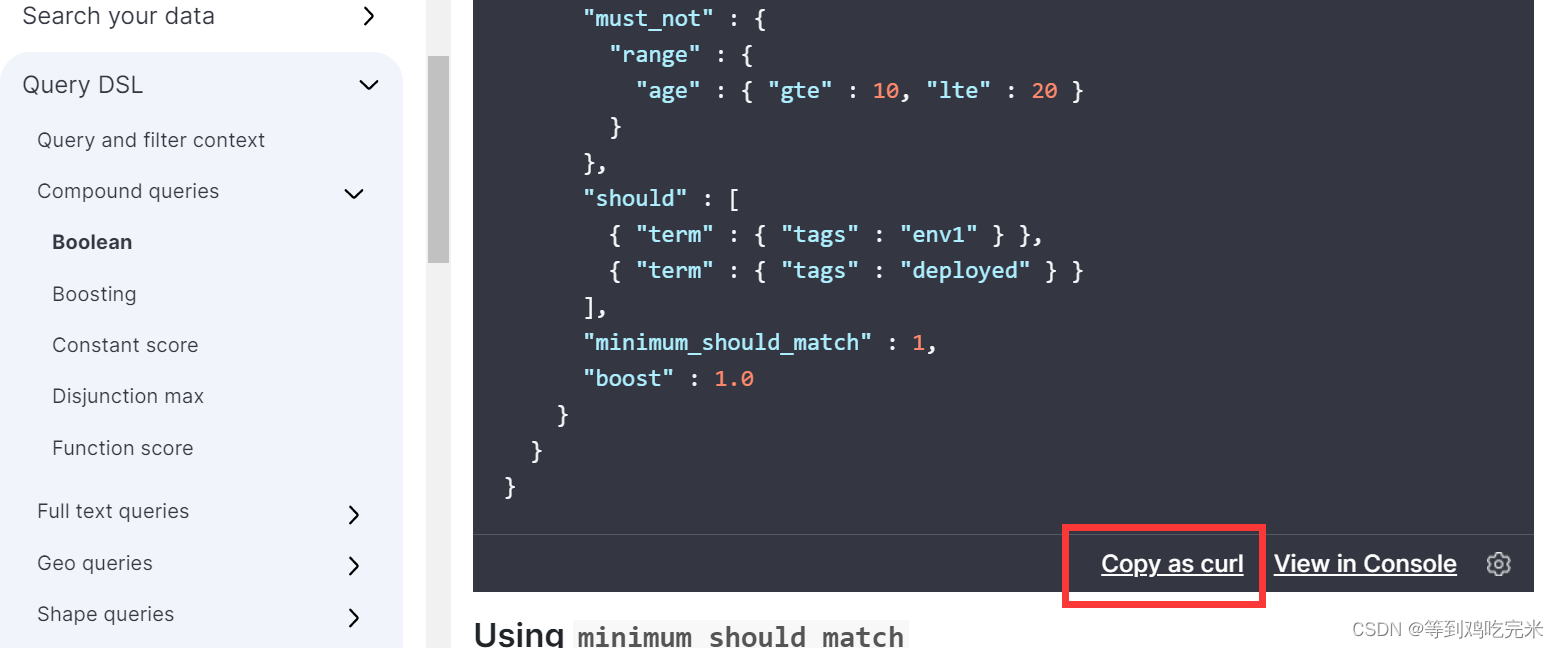
转化curl语句如下:
curl -X POST "localhost:9200/_search?pretty" -H 'Content-Type: application/json' -d'
{
"query": {
"bool" : {
"must" : {
"term" : { "user.id" : "kimchy" }
},
"filter": {
"term" : { "tags" : "production" }
},
"must_not" : {
"range" : {
"age" : { "gte" : 10, "lte" : 20 }
}
},
"should" : [
{ "term" : { "tags" : "env1" } },
{ "term" : { "tags" : "deployed" } }
],
"minimum_should_match" : 1,
"boost" : 1.0
}
}
}
'
7.通过搜索栏直接搜索自己想要的DSL语法
2、match、match_phrase、multi_math查询
1)match(分字符串和非字符串)
1.如果是非字符串,会进行精确匹配
基本类型(非字符串),精确控制
GET bank/_search
{
"query": {
"match": {
"account_number": "20"
}
}
}
match返回account_number=20的数据
查询结果:
{
"took" : 1,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 1, // 得到一条
"relation" : "eq"
},
"max_score" : 1.0, # 最大得分
"hits" : [
{
"_index" : "bank",
"_type" : "account",
"_id" : "20",
"_score" : 1.0,
"_source" : { # 该条文档信息
"account_number" : 20,
"balance" : 16418,
"firstname" : "Elinor",
"lastname" : "Ratliff",
"age" : 36,
"gender" : "M",
"address" : "282 Kings Place",
"employer" : "Scentric",
"email" : "elinorratliff@scentric.com",
"city" : "Ribera",
"state" : "WA"
}
}
]
}
}
2. 如果是字符串,会进行全文检索,全文检索按照评分进行排序
字符串,全文检索
GET bank/_search
{
"query": {
"match": {
"address": "kings"
}
}
}
全文检索,最终会按照评分进行排序,会对检索条件进行分词匹配
{
"took" : 30,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 2,
"relation" : "eq"
},
"max_score" : 5.990829,
"hits" : [
{
"_index" : "bank",
"_type" : "account",
"_id" : "20",
"_score" : 5.990829,
"_source" : {
"account_number" : 20,
"balance" : 16418,
"firstname" : "Elinor",
"lastname" : "Ratliff",
"age" : 36,
"gender" : "M",
"address" : "282 Kings Place",
"employer" : "Scentric",
"email" : "elinorratliff@scentric.com",
"city" : "Ribera",
"state" : "WA"
}
},
{
"_index" : "bank",
"_type" : "account",
"_id" : "722",
"_score" : 5.990829,
"_source" : {
"account_number" : 722,
"balance" : 27256,
"firstname" : "Roberts",
"lastname" : "Beasley",
"age" : 34,
"gender" : "F",
"address" : "305 Kings Hwy",
"employer" : "Quintity",
"email" : "robertsbeasley@quintity.com",
"city" : "Hayden",
"state" : "PA"
}
}
]
}
}
2)match_phrase(不拆分匹配)
match_phrase将需要匹配的值当成一整个单词(不分词)进行检索(短语匹配),字段.keyword:必须全匹配上才检索成功(精确匹配);
# 前面的是包含mill或road就查出来,我们现在要都包含才查出
GET bank/_search
{
"query": {
"match_phrase": {
"address": "mill road" # 就是说不要匹配只有mill或只有road的,要匹配mill road一整个子串
}
}
}
# 查处address中包含mill road的所有记录,并给出相关性得分
{
"took" : 32,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 1,
"relation" : "eq"
},
"max_score" : 8.926605,
"hits" : [
{
"_index" : "bank",
"_type" : "account",
"_id" : "970",
"_score" : 8.926605,
"_source" : {
"account_number" : 970,
"balance" : 19648,
"firstname" : "Forbes",
"lastname" : "Wallace",
"age" : 28,
"gender" : "M",
"address" : "990 Mill Road", # "mill road"
"employer" : "Pheast",
"email" : "forbeswallace@pheast.com",
"city" : "Lopezo",
"state" : "AK"
}
}
]
}
}
GET bank/_search
{
"query": {
"match_phrase": {
"address.keyword": "mill road"
}
}
}
{
"took" : 0,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 0,
"relation" : "eq"
},
"max_score" : null,
"hits" : [ ]
}
}
3)query/multi_match(多字段匹配)
state或者address中包含mill,并且在查询过程中,会对于查询条件,进行分词处理;
GET bank/_search
{
"query": {
"multi_match": { # 前面的match仅指定了一个字段。
"query": "Mill",
"fields": [ # state和address有mill子串 不要求都有
"state",
"address"
]
}
}
}
查询结果:
{
"took" : 28,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 4,
"relation" : "eq"
},
"max_score" : 5.4032025,
"hits" : [
{
"_index" : "bank",
"_type" : "account",
"_id" : "970",
"_score" : 5.4032025,
"_source" : {
"account_number" : 970,
"balance" : 19648,
"firstname" : "Forbes",
"lastname" : "Wallace",
"age" : 28,
"gender" : "M",
"address" : "990 Mill Road", # 有mill
"employer" : "Pheast",
"email" : "forbeswallace@pheast.com",
"city" : "Lopezo",
"state" : "AK" # 没有mill
}
},
{
"_index" : "bank",
"_type" : "account",
"_id" : "136",
"_score" : 5.4032025,
"_source" : {
"account_number" : 136,
"balance" : 45801,
"firstname" : "Winnie",
"lastname" : "Holland",
"age" : 38,
"gender" : "M",
"address" : "198 Mill Lane", # mill
"employer" : "Neteria",
"email" : "winnieholland@neteria.com",
"city" : "Urie",
"state" : "IL" # 没有mill
}
},
{
"_index" : "bank",
"_type" : "account",
"_id" : "345",
"_score" : 5.4032025,
"_source" : {
"account_number" : 345,
"balance" : 9812,
"firstname" : "Parker",
"lastname" : "Hines",
"age" : 38,
"gender" : "M",
"address" : "715 Mill Avenue", #
"employer" : "Baluba",
"email" : "parkerhines@baluba.com",
"city" : "Blackgum",
"state" : "KY" # 没有mill
}
},
{
"_index" : "bank",
"_type" : "account",
"_id" : "472",
"_score" : 5.4032025,
"_source" : {
"account_number" : 472,
"balance" : 25571,
"firstname" : "Lee",
"lastname" : "Long",
"age" : 32,
"gender" : "F",
"address" : "288 Mill Street", #
"employer" : "Comverges",
"email" : "leelong@comverges.com",
"city" : "Movico",
"state" : "MT" # 没有mill
}
}
]
}
}
4)wildcard (通配符查询)
wildcard查询是使用通配符进行查询,其中?代表任意一个字符*代表任意的一个或多个字符,下面的语句会把包含“公主”这个词语的内容检索出来。
{
"query": {
"wildcard": {
"title":"\*公主\*"
}
}
}
3、简单介绍:must、must_not、should、query/filter
1)must(必须达到must所列举的所有条件)
实例:查询gender=m,并且address=mill的数据
GET bank/_search
{
"query":{
"bool":{ #
"must":[ # 必须有这些字段
{"match":{"address":"mill"}},
{"match":{"gender":"M"}}
]
}
}
}
查询结果
{
"took" : 1,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 3,
"relation" : "eq"
},
"max_score" : 6.0824604,
"hits" : [
{
"_index" : "bank",
"_type" : "account",
"_id" : "970",
"_score" : 6.0824604,
"_source" : {
"account_number" : 970,
"balance" : 19648,
"firstname" : "Forbes",
"lastname" : "Wallace",
"age" : 28,
"gender" : "M", # M
"address" : "990 Mill Road", # mill
"employer" : "Pheast",
"email" : "forbeswallace@pheast.com",
"city" : "Lopezo",
"state" : "AK"
}
},
{
"_index" : "bank",
"_type" : "account",
"_id" : "136",
"_score" : 6.0824604,
"_source" : {
"account_number" : 136,
"balance" : 45801,
"firstname" : "Winnie",
"lastname" : "Holland",
"age" : 38,
"gender" : "M", #
"address" : "198 Mill Lane", #
"employer" : "Neteria",
"email" : "winnieholland@neteria.com",
"city" : "Urie",
"state" : "IL"
}
},
{
"_index" : "bank",
"_type" : "account",
"_id" : "345",
"_score" : 6.0824604,
"_source" : {
"account_number" : 345,
"balance" : 9812,
"firstname" : "Parker",
"lastname" : "Hines",
"age" : 38,
"gender" : "M", #
"address" : "715 Mill Avenue", #
"employer" : "Baluba",
"email" : "parkerhines@baluba.com",
"city" : "Blackgum",
"state" : "KY"
}
}
]
}
}
2)must_not(必须不匹配must_not所列举的所有条件)
实例:查询gender=m,并且address=mill的数据,但是age不等于38的
GET bank/_search
{
"query": {
"bool": {
"must": [
{ "match": { "gender": "M" }},
{ "match": {"address": "mill"}}
],
"must_not": [ # 不可以是指定值
{ "match": { "age": "38" }}
]
}
}
查询结果:
{
"took" : 4,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 1,
"relation" : "eq"
},
"max_score" : 6.0824604,
"hits" : [
{
"_index" : "bank",
"_type" : "account",
"_id" : "970",
"_score" : 6.0824604,
"_source" : {
"account_number" : 970,
"balance" : 19648,
"firstname" : "Forbes",
"lastname" : "Wallace",
"age" : 28, # 不是38
"gender" : "M", #
"address" : "990 Mill Road", #
"employer" : "Pheast",
"email" : "forbeswallace@pheast.com",
"city" : "Lopezo",
"state" : "AK"
}
}
]
}
}
3)should(应该满足should所列举的条件)
应该满足should所列举的条件,满足条件最好,不满足也可以,满足得分更高,并不会改变查询的结果。如果query中只有should且只有一种匹配规则,那么should的条件就会被作为默认匹配条件而去改变查询结果;
实例:匹配lastName应该等于Wallace的数据
GET bank/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"gender": "M"
}
},
{
"match": {
"address": "mill"
}
}
],
"must_not": [
{
"match": {
"age": "18"
}
}
],
"should": [
{
"match": {
"lastname": "Wallace"
}
}
]
}
}
}
查询结果:
{
"took" : 5,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 3,
"relation" : "eq"
},
"max_score" : 12.585751,
"hits" : [
{
"_index" : "bank",
"_type" : "account",
"_id" : "970",
"_score" : 12.585751,
"_source" : {
"account_number" : 970,
"balance" : 19648,
"firstname" : "Forbes",
"lastname" : "Wallace", # 因为匹配了should,所以得分第一
"age" : 28, # 不是18
"gender" : "M", #
"address" : "990 Mill Road", #
"employer" : "Pheast",
"email" : "forbeswallace@pheast.com",
"city" : "Lopezo",
"state" : "AK"
}
},
{
"_index" : "bank",
"_type" : "account",
"_id" : "136",
"_score" : 6.0824604,
"_source" : {
"account_number" : 136,
"balance" : 45801,
"firstname" : "Winnie",
"lastname" : "Holland",
"age" : 38,
"gender" : "M",
"address" : "198 Mill Lane",
"employer" : "Neteria",
"email" : "winnieholland@neteria.com",
"city" : "Urie",
"state" : "IL"
}
},
{
"_index" : "bank",
"_type" : "account",
"_id" : "345",
"_score" : 6.0824604,
"_source" : {
"account_number" : 345,
"balance" : 9812,
"firstname" : "Parker",
"lastname" : "Hines",
"age" : 38,
"gender" : "M",
"address" : "715 Mill Avenue",
"employer" : "Baluba",
"email" : "parkerhines@baluba.com",
"city" : "Blackgum",
"state" : "KY"
}
}
]
}
}
能够看到相关度越高,得分也越高。
4)query/filter(不会计算相关性得分)
并不是所有的查询都需要产生分数,特别是哪些仅用于filtering过滤的文档。为了不计算分数,elasticsearch会自动检查场景并且优化查询的执行(filter不会计算相关性得分)
GET bank/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"address": "mill"
}
}
],
"filter": {
"range": {
"balance": {
"gte": "10000",
"lte": "20000"
}
}
}
}
}
}
{
"took" : 1,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 213,
"relation" : "eq"
},
"max_score" : 0.0,
"hits" : [
{
"_index" : "bank",
"_type" : "account",
"_id" : "20",
"_score" : 0.0,
"_source" : {
"account_number" : 20,
"balance" : 16418,
"firstname" : "Elinor",
"lastname" : "Ratliff",
"age" : 36,
"gender" : "M",
"address" : "282 Kings Place",
"employer" : "Scentric",
"email" : "elinorratliff@scentric.com",
"city" : "Ribera",
"state" : "WA"
}
},
{
"_index" : "bank",
"_type" : "account",
"_id" : "37",
"_score" : 0.0,
"_source" : {
"account_number" : 37,
"balance" : 18612,
"firstname" : "Mcgee",
"lastname" : "Mooney",
"age" : 39,
"gender" : "M",
"address" : "826 Fillmore Place",
"employer" : "Reversus",
"email" : "mcgeemooney@reversus.com",
"city" : "Tooleville",
"state" : "OK"
}
},
省略......
4、复合查询:bool、boosting、constant_score、dis_max
1)bool(Boolean Query)
在ES中有一种查询,叫做bool查询,他可以组合多个查询字句,然后将结果输出,并且他是支持嵌套子句的。我们可能想要通过多个条件去做检索,比如说豆瓣搜索一部电影,我们可能会限定根据电影的类型、年份、豆瓣评分等多个条件去查询,那么这种场景其实就是多个检索条件和多个字段匹配的一种场景。
bool支持的查询字句可以分为四种类型:
- must:必须匹配,会影响算分结果
- should:选择性匹配,也会影响算分结果
- must_not:必须不能匹配,不会影响算分
- filter:必须匹配,不会影响算分
bool查询可以通过minimum_should_match来指定should查询中的term子查询必须匹配几个才可以算是真正的匹配到这条数据。假设现在就是查询一部电影,我们搜索限定评分要大于9分,类型是文艺片,上映时间是2021年,演员有张国荣。那么如果不指定minimum_should_match,可能这四个条件中有一个满足就能查到,但是如果指定了minimum_should_match=3,那么这四个条件中必须满足三个才会返回。
官网案例:
POST _search
{
"query": {
"bool" : {
"must" : {
"term" : { "user.id" : "kimchy" }
},
"filter": {
"term" : { "tags" : "production" }
},
"must_not" : {
"range" : {
"age" : { "gte" : 10, "lte" : 20 }
}
},
"should" : [ # 一个数组,包括了两个term查询,如果没有指定must条件,那么should查询中的term必须至少满足一条查询
{ "term" : { "tags" : "env1" } },
{ "term" : { "tags" : "deployed" } }
],
"minimum_should_match" : 1,
"boost" : 1.0
}
}
}
2)boosting(Boosting query)
假设现在我们有下面这样一个索引,包括三个文档,其中前两条是Apple公司的电子产品介绍,后面一条是水果Apple的百科介绍,那么如果我们通过下面的查询条件去匹配,会既查询到苹果手机,也会查询到水果里的苹果。
POST /baike/_search
{
"query": {
"bool": {
"must": {
"match":{"title":"Apple"}
}
}
}
}
"hits" : {
"total" : {
"value" : 3,
"relation" : "eq"
},
"max_score" : 0.1546153,
"hits" : [
{
"_index" : "baike",
"_type" : "_doc",
"_id" : "1",
"_score" : 0.1546153,
"_source" : {
"title" : "Apple Pad"
}
},
{
"_index" : "baike",
"_type" : "_doc",
"_id" : "2",
"_score" : 0.1546153,
"_source" : {
"title" : "Apple Mac"
}
},
{
"_index" : "baike",
"_type" : "_doc",
"_id" : "3",
"_score" : 0.1546153,
"_source" : {
"title" : "Apple Pie and Apple Fruit"
}
}
]
}
但是也许我们的用户关注的并不是水果的苹果,而是电子产品,那么我们应该如何进行更精确的匹配呢?当然我们可以对前面的查询做一些修改,通过mast_not来排除title中包括pie或者fruit的文档,只返回Apple Pad和Apple Mac。
POST /baike/_search
{
"query": {
"bool": {
"must": {
"match":{"title":"Apple"}
},
"must_not": {
"match":{"title":"Pie"}
}
}
}
}
但是这么做又似乎有一点绝对,虽然很多人确实是想找苹果手机,但是也总有人是要看看什么苹果好吃,那么有没有什么折中的办法呢?
在ES中,为我们提供了Boosting query这种查询方式(boosting:boost的现在分词形式,有提高,助推的意思,这里我理解是提高_score这个分值),他可以为我们匹配到用户最关心的苹果手机,也可以匹配到吃的苹果。并且可以指定让最受关注的苹果手机展示在搜索结果的最前面。
Boosting query有以下几个属性:
- positive:翻译过来有积极地意思,用来指定我们最关心的,希望靠前展示,算分高的文档
- negative:翻译过来有消极地意思,用来指定我们不是很关心,但是还是希望他能被匹配到的文档
- negative_boost:这个是为negative里面的条件指定一个boost值,用来降低他们的算分,在0.0-1.0之间的一个float数字
写法大概如下:
POST /baike/_search
{
"query": {
"boosting": {
"positive": {
"match": {
"title": "Apple"
}
},
"negative": {
"match": {
"title": "fruit"
}
},
"negative_boost": 0.5 # 通过这个字段结合上面的negative里的条件,在查询的时候就会将包含fruit的那条数据的算分打的很低,让他排在最后展示
}
}
}
3)costant_score(Constant score query)
filter查询是不会进行算分的,而且es会自动缓存一些filter查询,以此来提高一个效率。有时候可能确实需要返回一个期望的算分,那么constant_score可以用来做这件事,他可以对filter查询进行一次包装,然后通过boost这个参数来指定返回一个常量的算分。
POST /baike/_search
{
"query": {
"constant_score": {
"filter": {"term": {"title.keyword": "Quick brown rabbits"}},
"boost": 1.2
}
}
}
"hits" : {
"total" : {
"value" : 1,
"relation" : "eq"
},
"max_score" : 1.2,
"hits" : [
{
"_index" : "baike",
"_type" : "_doc",
"_id" : "4",
"_score" : 1.2, # 通过上面查询,这里返回的算分和我们指定的boost分值相等
"_source" : {
"title" : "Quick brown rabbits",
"body" : "Brown rabbits are commonly seen."
}
}
]
}
4)dis_max(Disjunction max query)
有下面两条数据:
POST baike/_doc/4
{
"title": "Quick brown rabbits",
"body": "Brown rabbits are commonly seen."
}
POST baike/_doc/5
{
"title": "Keeping pets healthy",
"body": "My quick brown fox eats rabbits on a regular basis."
}
假设我们现在要在title或者body里查询brown fox相关的内容,那么我们通过观察发现ID为5的这条数据应该是相关性更高的,因为他的body里出现了完整的brown fox这个搜索条件,那么我们当然希望他能获得更高的算分,稍微靠前一点展示,接下来我们用bool查询试试看会不会和我们想的一样,下面是结果:
POST /baike/_search
{
"query": {
"bool": {
"should": [
{"match": {"title": "Brown fox"}},
{"match": {"body": "Brown fox"}}
]
}
}
}
# 查询结果
"hits" : {
"total" : {
"value" : 2,
"relation" : "eq"
},
"max_score" : 1.5974034,
"hits" : [
{
"_index" : "baike",
"_type" : "_doc",
"_id" : "4",
"_score" : 1.5974034,
"_source" : {
"title" : "Quick brown rabbits",
"body" : "Brown rabbits are commonly seen."
}
},
{
"_index" : "baike",
"_type" : "_doc",
"_id" : "5",
"_score" : 0.77041256,
"_source" : {
"title" : "Keeping pets healthy",
"body" : "My quick brown fox eats rabbits on a regular basis."
}
}
]
}
实际操作过程中我们发现ID为5的这条数据并没有得到更高的算分,这是为什么呢?为了回答这个问题,我们要知道在es中也可以类似mysql查询sql的执行计划一样,通过explain这个关键字来展示dsl的执行计划,包括算分方式。
POST /baike/_search
{
"query": {
"bool": {
"should": [
{"match": {"title": "Brown fox"}},
{"match": {"body": "Brown fox"}}
]
}
},
"explain": true
}
# 查询结果
"hits" : {
"total" : {
"value" : 2,
"relation" : "eq"
},
"max_score" : 1.5974034,
"hits" : [
{
"_shard" : "[baike][0]",
"_node" : "aPt8G7vHTzOJU_L2FdLBpA",
"_index" : "baike",
"_type" : "_doc",
"_id" : "4",
"_score" : 1.5974034,
"_source" : {
"title" : "Quick brown rabbits",
"body" : "Brown rabbits are commonly seen."
},
"_explanation" : {
"value" : 1.5974034, # 这个值约等于38行的value + 49行的value
"description" : "sum of:", # !!! 求和
"details" : [
{
"value" : 1.3862942,
"description" : "weight(title:brown in 0) [PerFieldSimilarity], result of:", # title中有关键字brown,算一次
"details" : [
{
"value" : 1.3862942,
"description" : "score(freq=1.0), computed as boost * idf * tf from:",
"details" : [] # 算分细节,因为太长省略
}
]
},
{
"value" : 0.21110919,
"description" : "weight(body:brown in 0) [PerFieldSimilarity], result of:", # body中有关键字brown,算一次分
"details" : [
{
"value" : 0.21110919,
"description" : "score(freq=1.0), computed as boost * idf * tf from:",
"details" : []
}
]
}
]
}
},
{
"_shard" : "[baike][0]",
"_node" : "aPt8G7vHTzOJU_L2FdLBpA",
"_index" : "baike",
"_type" : "_doc",
"_id" : "5",
"_score" : 0.77041256,
"_source" : {
"title" : "Keeping pets healthy",
"body" : "My quick brown fox eats rabbits on a regular basis."
},
"_explanation" : {
"value" : 0.77041256,
"description" : "sum of:",
"details" : [
{
"value" : 0.160443,
"description" : "weight(body:brown in 0) [PerFieldSimilarity], result of:", # body中有关键字brown,算一次分
"details" : [
{
"value" : 0.160443,
"description" : "score(freq=1.0), computed as boost * idf * tf from:",
"details" : []
}
]
},
{
"value" : 0.60996956,
"description" : "weight(body:fox in 0) [PerFieldSimilarity], result of:", # body中有关键字fox,算一次分
"details" : [
{
"value" : 0.60996956,
"description" : "score(freq=1.0), computed as boost * idf * tf from:",
"details" : []
}
]
}
]
}
}
]
}
通过对执行计划的分析,我们发现在bool查询会将should里面两个子查询分别进行算分,然后做加法,得到一个总的分数,在ID为4的文档中,title和body中分别包含了brown这个关键字,而ID为5的文档呢,因为title中没有包含查询条件中任何一个字符,因此它的算分下来就偏低,最终排在了后面。
这种结局并不是我们想要看到的,那么有没有什么办法呢?es中就提供了一种解决方案,叫做dis_max;dis也就是Disjunction的缩写,有分离,提取的意思,max是最大的意思,因此他就是将组合查询分离成多个子查询,去算分最高的作为最终得分。他是一个帮助我们选取最佳匹配的一种有效手段。
接下来我们用他再做一次查询,看看有什么结果:
POST /baike/_search
{
"query": {
"dis_max": {
"queries": [
{"match": {"title": "Brown fox"}},
{"match": {"body": "Brown fox"}}
]
}
}
"hits" : {
"total" : {
"value" : 2,
"relation" : "eq"
},
"max_score" : 0.77041256,
"hits" : [
{
"_index" : "baike",
"_type" : "_doc",
"_id" : "5",
"_score" : 0.77041256,
"_source" : {
"title" : "Keeping pets healthy",
"body" : "My quick brown fox eats rabbits on a regular basis."
}
},
{
"_index" : "baike",
"_type" : "_doc",
"_id" : "4",
"_score" : 0.6931471,
"_source" : {
"title" : "Quick brown rabbits",
"body" : "Brown rabbits are commonly seen."
}
}
]
}
}
很明显ID为5的这条数据这一次获得了一个较高的算分。我们再用explain看看他的执行计划,发现他这次不是单纯的将两个子查询的算分加起来,而是选了两个子查询中算分的最大值做为他的最终得分。
"hits" : {
"total" : {
"value" : 2,
"relation" : "eq"
},
"max_score" : 0.77041256,
"hits" : [
{
"_shard" : "[baike][0]",
"_node" : "tc1MvVwdRcO-2A5L6j_l0Q",
"_index" : "baike",
"_type" : "_doc",
"_id" : "5",
"_score" : 0.77041256,
"_source" : {
"title" : "Keeping pets healthy",
"body" : "My quick brown fox eats rabbits on a regular basis."
},
"_explanation" : {
"value" : 0.77041256,
"description" : "max of:", # !!! 求最大值
"details" : [
{
"value" : 0.77041256,
"description" : "sum of:",
"details" : [
{
"value" : 0.160443,
"description" : "weight(body:brown in 1) [PerFieldSimilarity], result of:",
"details" : []
},
{
"value" : 0.60996956,
"description" : "weight(body:fox in 1) [PerFieldSimilarity], result of:",
"details" : []
}
]
}
]
}
},
{
"_shard" : "[baike][0]",
"_node" : "tc1MvVwdRcO-2A5L6j_l0Q",
"_index" : "baike",
"_type" : "_doc",
"_id" : "4",
"_score" : 0.6931471,
"_source" : {
"title" : "Quick brown rabbits",
"body" : "Brown rabbits are commonly seen."
},
"_explanation" : {
"value" : 0.6931471,
"description" : "max of:",
"details" : [
{
"value" : 0.6931471,
"description" : "sum of:",
"details" : [
{
"value" : 0.6931471,
"description" : "weight(title:brown in 0) [PerFieldSimilarity], result of:",
"details" : []
}
]
},
{
"value" : 0.21110919,
"description" : "sum of:",
"details" : [
{
"value" : 0.21110919,
"description" : "weight(body:brown in 0) [PerFieldSimilarity], result of:",
"details" : []
}
]
}
]
}
}
]
}
但是有时候完全取最高的,直接忽略掉其他查询字句的分值,也不是很合理。ES也为我们提供了一个参数:tie_breaker。
他的有效值在0.0-1.0之间的一个浮点数,默认是0.0,如果我们设置了这个字段,那么在算分的时候,首先他会取最高分,然后和所有子查询的得分乘以tie_breaker的值相加,求取一个最终的算分,给了最高算分和其他子查询算分一个权重;
参考原文地址:http://t.csdn.cn/8GRxa
参考原文地址:http://t.csdn.cn/rx8oi

















 748
748











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











