




本篇文章不讲有关主成分分析的理论知识,只讲实际操作。
实例:(中学生身体四项指标的主成分分析)
在某中学随机抽取某年级30名学生,测量其身高(X1)、体重(X2)、胸围(X3)和坐高(X4),数据如下。试对这30名中学生身体四项指标数据做主成分分析。
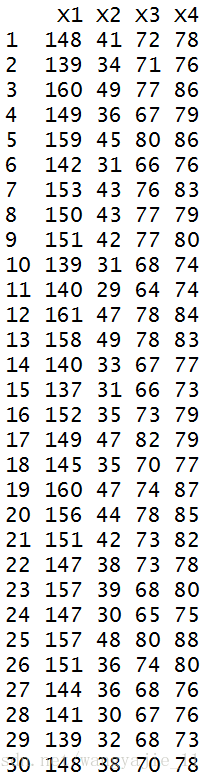
这些数据保存保存在students_data.csv中,该文件中的部分数据截图如下:
现在开始做主成分分析
第一步:将students_data.csv中的数据读入到程序中
data <- read.csv('本篇文章不讲有关主成分分析的理论知识,只讲实际操作。
实例:(中学生身体四项指标的主成分分析)
在某中学随机抽取某年级30名学生,测量其身高(X1)、体重(X2)、胸围(X3)和坐高(X4),数据如下。试对这30名中学生身体四项指标数据做主成分分析。
data <- read.csv(' 4万+
615
4万+
615

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言




 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章






















