






一、数据降维
对于现在维数比较多的数据,我们首先需要做的就是对其进行降维操作。降维,简单来说就是说在尽量保证数据本质的前提下将数据中的维数降低。降维的操作可以理解为一种映射关系,例如函数
") ,即由原来的二维转换成了一维。处理降维的技术有很多种,如前面的
SVD奇异值分解,主成分分析(PCA),因子分析(FA),独立成分分析(ICA)等等。
,即由原来的二维转换成了一维。处理降维的技术有很多种,如前面的
SVD奇异值分解,主成分分析(PCA),因子分析(FA),独立成分分析(ICA)等等。
,即由原来的二维转换成了一维。处理降维的技术有很多种,如前面的
SVD奇异值分解,主成分分析(PCA),因子分析(FA),独立成分分析(ICA)等等。
二、PCA的概念
PCA是一种较为常用的降维技术,PCA的思想是将
 维特征映射到
维特征映射到
 维上,这
维是全新的正交特征。这
维特征称为主元,是重新构造出来的
维特征。在PCA中,数据从原来的坐标系转换到新的坐标系下,新的坐标系的选择与数据本身是密切相关的。其中,第一个新坐标轴选择的是原始数据中方差最大的方向,第二个新坐标轴选取的是与第一个坐标轴正交且具有最大方差的方向,依次类推,我们可以取到这样的
个坐标轴。
维上,这
维是全新的正交特征。这
维特征称为主元,是重新构造出来的
维特征。在PCA中,数据从原来的坐标系转换到新的坐标系下,新的坐标系的选择与数据本身是密切相关的。其中,第一个新坐标轴选择的是原始数据中方差最大的方向,第二个新坐标轴选取的是与第一个坐标轴正交且具有最大方差的方向,依次类推,我们可以取到这样的
个坐标轴。
维特征映射到
维上,这
维是全新的正交特征。这
维特征称为主元,是重新构造出来的
维特征。在PCA中,数据从原来的坐标系转换到新的坐标系下,新的坐标系的选择与数据本身是密切相关的。其中,第一个新坐标轴选择的是原始数据中方差最大的方向,第二个新坐标轴选取的是与第一个坐标轴正交且具有最大方差的方向,依次类推,我们可以取到这样的
个坐标轴。
三、PCA的操作过程
1、PCA的操作流程大致如下:
假设二维数据为

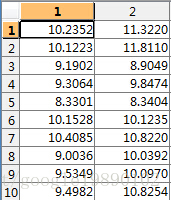
- 取平均值
 为
为
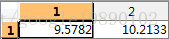
去除均值后的矩阵为

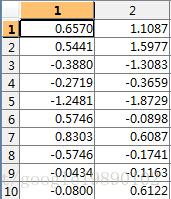
- 计算的协方差矩阵

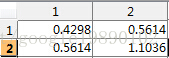
- 计算的特征值与特征向量
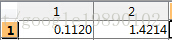
特征向量为
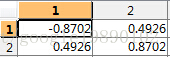
- 对特征值进行排序,显然就两个特征值
- 选择最大的那个特征值对应的特征向量

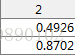
- 转换到新的空间

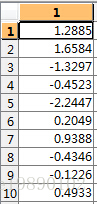
四、实验的仿真
我们队一个数据集进行了测试:
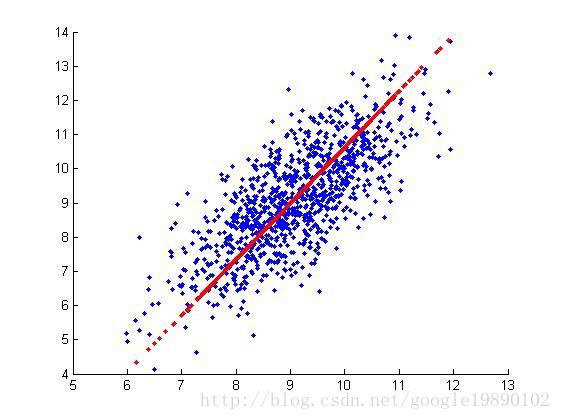
MATLAB实验代码如下:
主程序
- %% pca
- dataSet = load('testSet.txt');%导入数据
- % pca
- [FinalData, reconData] = PCA(dataSet, 1);
- %% 作图
- hold on
- plot(dataSet(:,1), dataSet(:,2), '.');
- plot(reconData(:,1), reconData(:,2), '.r');
- hold off
PCA函数段
- function [ FinalData,reconData ] = PCA( dataSet, k )
- [m,n] = size(dataSet);
- %% 去除平均值
- %取平均值
- dataSetMean = mean(dataSet);
- %减去平均值
- dataSetAdjust = zeros(m,n);
- for i = 1 : m
- dataSetAdjust(i , :) = dataSet(i , :) - dataSetMean;
- end
- %% 计算协方差矩阵
- dataCov = cov(dataSetAdjust);
- %% 计算协方差矩阵的特征值与特征向量
- [V, D] = eig(dataCov);
- % 将特征值矩阵转换成向量
- d = zeros(1, n);
- for i = 1:n
- d(1,i) = D(i,i);
- end
- %% 对特征值排序
- [maxD, index] = sort(d);
- %% 选取前k个最大的特征值
- % maxD_k = maxD(1, (n-k+1):n);
- index_k = index(1, (n-k+1):n);
- % 对应的特征向量
- V_k = zeros(n,k);
- for i = 1:k
- V_k(:,i) = V(:,index_k(1,i));
- end
- %% 转换到新的空间
- FinalData = dataSetAdjust*V_k;
- % 在原图中找到这些点
- reconData = FinalData * V_k';
- for i = 1 : m
- reconData(i , :) = reconData(i , :) + dataSetMean;
- end
- end
原文链接是:http://blog.csdn.net/google19890102/article/details/27969459















 2496
2496











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









