








 超级会员免费看
超级会员免费看

 GRU是LSTM的一种简化变体,解决了RNN处理长距离依赖的问题。它拥有更新门和重置门,通过这两门控制信息流动。GRU的前向传播涉及更新门和重置门的计算,训练时需要学习权重参数。文章还提及了GRU的损失函数和与其相关的神经网络知识。
GRU是LSTM的一种简化变体,解决了RNN处理长距离依赖的问题。它拥有更新门和重置门,通过这两门控制信息流动。GRU的前向传播涉及更新门和重置门的计算,训练时需要学习权重参数。文章还提及了GRU的损失函数和与其相关的神经网络知识。
前面已经详细讲了LSTM神经网络(文末有链接回去),接着往下讲讲LSTM的一个很流行的变体。
GRU是什么
GRU即Gated Recurrent Unit。前面说到为了克服RNN无法很好处理远距离依赖而提出了LSTM,而GRU则是LSTM的一个变体,当然LSTM还有有很多其他的变体。GRU保持了LSTM的效果同时又使结构更加简单,所以它也非常流行。
GRU模型
回顾一下LSTM的模型,LSTM的重复网络模块的结构很复杂,它实现了三个门计算,即遗忘门、输入门和输出门。
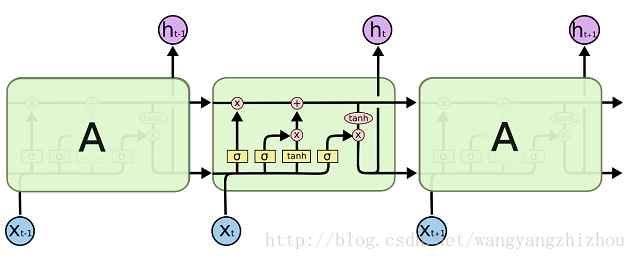
而GRU模型如下,它只有两个门了,分别为更新门和重置门,即图中的

 订阅专栏 解锁全文
订阅专栏 解锁全文



















 6013
6013

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











