基于大数据的机器学习原理与最佳实践
 分享
分享

文章平均质量分 91
主要是针对,在大数据环境下进行机器学习的相关内容介绍子目录,总体内容和目录还是以 《大数据处理实践探索》 为准, 本子目录的内容主要以spark 尤其是pyspark 进行机器学习为主线,围绕机器学习,深度学习全流程进行介绍。
 超级会员免费看
超级会员免费看
shiter
CSDN博客专家,人工智能与大数据领域优秀创作者,累计近500W人次访问。 熟悉自然语言处理(NLP)、大数据(Spark 、Elasticsearch)、数据分析(Scala,Python),计算机视觉(OpenCV、立体匹配)等领域的研发工作。世界500强,高级算法工程师, 曾参与并负责国家级大数据项目,负责大健康平台相关开发与管理工作,负责金融行业AI与大数据平台产品设计、开发与落地。编程不仅仅是技术,还是艺术!talk is cheap,show me the code!
展开
-
《基于大数据的机器学习原理与最佳实践》 ---- 总目录
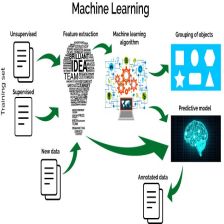
 本子目录主要是针对,在大数据环境下进行机器学习的相关内容介绍子目录,总体内容和目录还是以 《大数据处理实践探索》 为准, 本子目录的内容主要以spark 尤其是pyspark 进行机器学习为主线,围绕机器学习,深度学习全流程进行介绍。机器学习强调三个关键词:算法、经验、性能,其处理过程如上图所示。在数据的基础上,通过算法构建出模型并对模型进行评估。评估的性能如果达到要求,就用该模型来测试其他的数据;如果达不到要求,就要调整算法来重新建立模型,再次进行评估。如此循环往复,最终获得满意的经验来处理原创 2021-04-09 22:24:12 · 1084 阅读 · 0 评论
本子目录主要是针对,在大数据环境下进行机器学习的相关内容介绍子目录,总体内容和目录还是以 《大数据处理实践探索》 为准, 本子目录的内容主要以spark 尤其是pyspark 进行机器学习为主线,围绕机器学习,深度学习全流程进行介绍。机器学习强调三个关键词:算法、经验、性能,其处理过程如上图所示。在数据的基础上,通过算法构建出模型并对模型进行评估。评估的性能如果达到要求,就用该模型来测试其他的数据;如果达不到要求,就要调整算法来重新建立模型,再次进行评估。如此循环往复,最终获得满意的经验来处理原创 2021-04-09 22:24:12 · 1084 阅读 · 0 评论
-
初学者如何入门深度学习:以手写数字字符识别为例看AI 的学习路径,一图胜千言!超多高清大图收集整理
深度神经网络进行线性不可分的数据2分类通过池化操作,图片中的黑色特征在输出图片中,仍然被保留了下来,虽然有些许的误差。原创 2023-11-29 23:40:14 · 242 阅读 · 0 评论 -
使用PySpark 结合Apache SystemDS 进行信号处理分析 (离散傅立叶变换)的简单例子
我们将使用ApacheSystemML来实现离散傅立叶变换。通过这种方式,所有计算都继续在ApacheSpark集群上进行,以获得高级可扩展性和性能。,用线性代数编程语言实现离散傅立叶变换很简单。原创 2023-11-23 00:14:58 · 963 阅读 · 0 评论 -
使用 pyspark 进行 Clustering 的简单例子 -- KMeans
K-means算法适合于简单的聚类问题,但可能不适用于复杂的聚类问题。此外,在使用K-means算法之前,需要对数据进行预处理和缩放,以避免偏差。K-means是一种聚类算法,它将数据点分为不同的簇或组。原理简介:K-Means算法通过迭代寻找数据集中的k个簇,每个簇内的数据点尽可能相似(即,簇内距离最小),不同簇之间的数据点尽可能不同(即,簇间距离最大)。算法首先随机选择k个数据点作为初始的聚类中心(也称为质心),然后对数据集中的每个数据点,根据其与聚类中心的距离将其分配到最近的簇中。原创 2023-11-01 00:05:26 · 1261 阅读 · 0 评论 -
python 线程池,进程池
网上关于python 的线程池,进程池相关的资料较少,很多都是参考官方例子的代码。我们这篇文章就给出一些基于计算机视觉的代码实例。实际上GIL 限制了线程池的使用场景,但是从发展的眼光看,使用线程池是非常必要的。尤其是正儿八经的生产系统。可以使用3种方法避免全局锁的限制: 多进程,cython,使用非CPython解释器。原创 2023-10-24 10:59:10 · 133 阅读 · 0 评论 -
使用 pyspark 进行 Classification 的简单例子 -- RandomForestClassifier
【代码】使用 pyspark 进行 Classification 的简单例子。原创 2023-10-21 03:57:50 · 743 阅读 · 1 评论 -
高级机器学习与信号处理 (Advanced Machine Learning and Signal Processing)双语版 -- 简介与基于Spark的实验环境搭建
!!!!!!!!!!!!!!原创 2023-09-24 01:23:48 · 173 阅读 · 0 评论 -
机器视觉行业实践技巧 -- OpenCV技巧与方法:避坑指南
在机器视觉检测时,经常会遇到需要检测反光的物品,例如:金属、铝箔表面、反光膜片、光滑表面的物品等,这类物品都有同样的特点,就是会发出炫光,这样在检测的时候会影响被测物的特征提取,这个时候需要怎么处理呢?沃德普机器视觉就不一一在这里详细介绍了,如果您在使用机器视觉光源检测的时候,发现特征不明显,也许您需要为您的机器视觉系统重新选择合适的机器视觉光源,或者添加合适的偏振片。(4).采用同轴光源照明:使物体表面反射光和CCD相机在同一轴线上,有效消除图像重影,非常适合与镜面光滑表面的检测。原创 2022-10-09 16:57:04 · 911 阅读 · 0 评论 -
最长递减子序列问题
最长递减子序列的求解,可能在目标检测,工程计数等实际场景中使用,我们一块来看看怎么做原创 2022-10-08 14:33:50 · 1008 阅读 · 0 评论 -
windows 借助 wsl 使用pyheif 和 PIL Pillow实现对苹果 heif 格式的图像批量转换,不在Linux 下是否能够完成转换?当然了,我们还有库:pillow_heif
用苹果拍摄了一堆图片发现格式不对,如何在windows下使用python 脚本进行转换呢?原创 2022-07-25 23:17:58 · 867 阅读 · 0 评论 -
使用 拓扑排序进行有向无环图 任务关系拆解,实现任务编排
在图论中,拓扑排序(Topological Sorting)是一个有向无环图(DAG, Directed Acyclic Graph)的所有顶点的线性序列。原创 2022-07-09 00:35:56 · 313 阅读 · 0 评论 -
通过python扩展spark mllib 算法包(e.g.基于spark使用孤立森林进行异常检测)
如何通过python 脚本的方式扩展spark 的 处理能力呢?原创 2022-07-08 00:50:26 · 349 阅读 · 0 评论 -
python开发简介:【jupyter notebook】实战配置
由于anaconda自带了jupyter notebook,所以只需要一些简单的配置我们既可以进行实战开发,主要包括使用密码登录,外部访问,及root 角色启动等。原创 2022-07-06 23:40:17 · 463 阅读 · 0 评论 -
python开发简介:python 集成开发环境 IDE
进入实战环节,需要首先准备python开发环境的搭建,本书挑选工程中经常用到的IDE原创 2022-07-06 23:37:58 · 1223 阅读 · 0 评论 -
python开发简介:【Conda,Pip】虚环境搭建、配置与工程基础实践
有了集成开发环境,数据科学工具箱,我们还要准备搭建python 的虚拟环境。这是由于开源软件目前更新换代非常快,不同开发包之间相互依赖和更新可能引起的冲突及连锁反应。原创 2022-07-06 23:37:14 · 665 阅读 · 0 评论 -
python开发简介:编码规范与工程基础实践
工欲善其事,必先利其器,熟练掌握python开发环境,虚拟环境,anaconda 等数据科学软件的使用技巧才能令自然语言处理工作游刃有余。原创 2021-12-17 23:43:00 · 976 阅读 · 0 评论 -
使用跨平台的visual studio code 进行python 开发
visual studio code 应该是目前最快速的轻量级文本IDE 开发工具了吧!原创 2022-06-26 23:24:36 · 1836 阅读 · 0 评论 -
机器学习模型高性能、高并发部署实践探索
高并发系统设计的目标有三个:高性能,高可用,高可扩展!原创 2022-06-18 23:51:07 · 634 阅读 · 0 评论 -
《自然语言处理实战入门》---- 使用Docker TensorFlow TF.Serving 搭建文本情感分析在线服务(高并发)
文章大纲wsl2 下使用DockerTFserving拉取 TF.Serving 镜像运行容器模型服务RESTful apiflask 服务端代码高并发方式部署gPRC 和 RESTful 的区别高并发的选择参考文献wsl2 下使用Docker如果没有wsl2 的话就用虚拟机或者其他方式吧,在windows 下的话,wsl2 实在是太好用了!下面这两篇文章对wsl2 和 基本的Docker 都有简单的介绍:使用 WSL 进行pyspark + xgboost 分类+特征重要性 简单实践 – 离线原创 2022-05-23 00:11:30 · 362 阅读 · 0 评论 -
时间序列预测初探:Kats,SARIMA,Prophet,deepAR 等
时间序列的应用其实也挺广,我们这个文章来略探一二原创 2022-05-19 18:25:05 · 545 阅读 · 0 评论 -
《自然语言处理实战入门》第二章:NLP 前置技术(深度学习) ---- Keras
Keras是一个意在降低机器学习编程入门门槛的项目,其在业界拥有众多的拥护者和使用者。经过Keras社区的多年发展,Keras集成了很多符合工业和研究需求的高阶API,使用这些API只需要几行代码就可以构建和运行一个非常复杂的神经网络。原创 2020-12-16 11:21:38 · 685 阅读 · 0 评论 -
pyspark 原理、源码解析与优劣势分析(1) ---- 架构与java接口
文章大纲01. PySpark 的多进程架构02. Python Driver 如何调用 Java 的接口pyspark 优势参考文献Spark 框架主要是由 Scala 语言实现,同时也包含少量 Java 代码。Spark 面向用户的编程接口,也是 Scala。然而,在数据科学领域,Python 一直占据比较重要的地位,仍然有大量的数据工程师在使用各类 Python 数据处理和科学计算的库,例如 numpy、Pandas、scikit-learn 等。同时,Python 语言的入门门槛也显著低于 S原创 2021-05-20 17:59:06 · 968 阅读 · 6 评论 -
spark 随机森林 源码解析
文章大纲随机森林算法源代码参考文献随机森林算法树相关的基础知识:面试、笔试题集:集成学习,树模型,Random Forests,GBDT,XGBoost源代码spark 随机森林的训练步骤具体的训练步骤如下:1.将每个树模型的根节点取出,加入栈中2.将k个节点从栈中取出,组成一个训练集合group,k值由内存限制决定,确定特征采样3.从各分区上计算并汇合分布信息,并计算待切分节点的最优切分点4.根据切分点生成新的叶子节点,并更新nodeIdCache5.若新生成的叶子节点没原创 2022-05-07 18:05:46 · 866 阅读 · 0 评论 -
spark 分布式训练原理解析
文章大纲有哪几种分布式训练方式spark 分布式训练源码解读DEMO SPARK 训练xgboost参考文献基于spark的分布式机器学习框架都有哪些有哪几种分布式训练方式数据分布模型分布混合分布我们来回顾一下,spark 分布式计算的原理在分布式训练中,用于训练模型的工作负载会在多个微型处理器之间进行拆分和共享,这些处理器称为工作器节点,通过这些工作器节点并行工作以加速模型训练。 分布式训练可用于传统的 ML 模型,但更适用于计算和时间密集型任务,如用于训练深度神经网络。原创 2022-04-25 12:46:11 · 2049 阅读 · 0 评论 -
《自然语言处理实战入门》 ---- 笔试、面试题:机器学习基础(81-100)
我们想要训练一个 ML 模型,样本数量有 100 万个,特征维度是 5000,面对如此大数据,如何有效地训练模型原创 2022-04-19 22:18:05 · 433 阅读 · 0 评论 -
《自然语言处理实战入门》 ---- 笔试、面试题:机器学习基础(61-80)
51. 假如使用一个较复杂的回归模型来拟合样本数据,使用 Ridge 回归,调试正则化参数 λ,来降低模型复杂度。若 λ 较小时,关于偏差(bias)和方差(variance),下列说法正确的是?A. 若 λ 较小时,偏差减小,方差减小B. 若 λ 较小时,偏差减小,方差增大C. 若 λ 较小时,偏差增大,方差减小D. 若 λ 较小时,偏差增大,方差增大答案:B解析:见 题5。52. 下列关于 Ridge 回归,说法正确的是(多选)?A. 若 λ=0,则等价于一般的线性回归B. 若 λ=.翻译 2021-02-25 15:34:15 · 10401 阅读 · 0 评论 -
《自然语言处理实战入门》 ---- 笔试、面试题:机器学习基础(41-60)
笔试、面试题:机器学习基础(41-60)原创 2022-04-19 21:29:08 · 255 阅读 · 0 评论 -
《自然语言处理实战入门》 ---- 笔试、面试题:机器学习基础(21-40)
《自然语言处理实战入门》 ---- 笔试、面试题:机器学习基础(21-40)原创 2022-04-18 22:02:17 · 311 阅读 · 0 评论 -
《自然语言处理实战入门》 ---- 笔试、面试题:机器学习基础(1-20)
1. 下列说法正确的是?(多选)A. AdaGrad 使用的是一阶导数B. L-BFGS 使用的是二阶导数C. AdaGrad 使用的是二阶导数D. L-BFGS 使用的是一阶导数答案:AB解析:AdaGrad 是基于梯度下降算法的,AdaGrad算法能够在训练中自动的对学习速率 α 进行调整,对于出现频率较低参数采用较大的 α 更新;相反,对于出现频率较高的参数采用较小的 α 更新。Adagrad非常适合处理稀疏数据。很明显,AdaGrad 算法利用的是一阶导数。L-BFGS 是基于牛顿优翻译 2021-02-22 00:58:35 · 1577 阅读 · 0 评论 -
使用 jupyter hub /lab搭建机器学习工作台
AI workbench 也叫 AI 工作台,jupyter notebook 套件 可以基本满足一个机器学习工程师的全部要求。他所见即所得的编程方式受到广大分析师们的喜爱。本文主要讲解jupyter lab 的安装与使用配置,结合官网的docker 使用方式,一探究竟。原创 2022-04-08 22:58:35 · 2286 阅读 · 0 评论 -
使用迁移学习进行金融小样本风控实践(基于tradaboost进行个贷违约迁移学习比赛)---- 代码
文章大纲数据简介时间外样本集的生成import warningsimport pandas as pd# warnings.filterwarnings('ignore')import numpy as npimport lightgbmfrom sklearn import metricspd.set_option('display.max_columns', None)pd.set_option('display.max_rows', None)数据简介训练数据:train原创 2022-03-28 18:14:51 · 2057 阅读 · 0 评论 -
使用迁移学习进行金融小样本风控实践 ---- 原理简介
迁移学习(Transfer Learning,TL)对于人类来说,就是掌握举一反三的学习能力。原创 2022-03-26 11:05:51 · 2650 阅读 · 0 评论 -
spark 数据处理 -- 数据采样【随机抽样、分层抽样、权重抽样】
文章大纲简介分层抽样随机抽样代码样例scala 版本 sampleBypython版本参考文献简介spark scala最新版文档:http://spark.apache.org/docs/latest/api/scala/org/apache/spark/sql/DataFrameStatFunctions.htmlspark scala老版本的文档:http://spark.apache.org/docs/2.4.7/api/scala/index.html#org.apache.sp原创 2021-09-18 15:46:53 · 3593 阅读 · 0 评论 -
大数据ETL实践探索(5)---- 大数据ETL利器之 pandas
文章大纲文件加载一些参数的解释索引的那些坑杂项jupyter notebook 显示所有行和列文件加载path = r'./data/ren_pd.csv'df_pifu = pd.read_csv(path,low_memory=False,dtype={'MBR_NO':np.str})一些参数的解释索引的那些坑杂项jupyter notebook 显示所有行和列pd.s...原创 2019-02-03 23:51:57 · 2555 阅读 · 2 评论 -
聚类算法 ---- 大数据聚类算法综述
文章大纲简介聚类算法的分类相似性度量方法大数据聚类算法聚类算法对比参考文献简介随着数据量的迅速增加如何对大规模数据进行有效的聚类成为挑战性的研究课题,面向大数据的聚类算法对传统金融行业的股票投资分析、 互联网金融行业中的客户细分等金融应用领域具有重要价值, 本文对已有的大数据聚类算法,以及普通聚类算法做一个简单介绍聚类分析是伴随着统计学、计算机学与人工智能等领域科学的发展而逐步发展起来的,为此,这些领域若有较大的研究进展,必然促进聚类分析算法的快速发展。比如机器学习领域的人工神经网络与支持向量机原创 2021-08-19 23:39:46 · 1613 阅读 · 0 评论 -
spark dataframe 和 scala Map互相转换
spark 和scala 之间的数据转换,真是非常令人头疼,但是使用场景又非常的多,拆箱装箱实在是浪费时间,这篇文章我们来看看spark dataframe 和 scala Map互相转换原创 2022-01-20 00:07:06 · 3693 阅读 · 0 评论 -
spark 【scala and pyspark 】如何统计 Dataframe 列中的空值比例
机器学习在进行数据预处理的时候,经常需要统计某一列的缺失值比例。这个功能,spark 有多种的实现方式,我们一起来看看。原创 2022-01-13 22:23:40 · 2367 阅读 · 0 评论 -
机器学习中数据集的划分
其实一说到机器学习的数据集划分,我们往往都知道,有训练集、测试集。验证集、调优集一般来说不太常用。这篇博客来逐一探讨一下。原创 2022-01-11 20:34:32 · 478 阅读 · 0 评论 -
spark 等频 等宽 分箱的一个小问题
当分箱数比较多的时候,多于数据数量,箱子编号是从1 开始编号的,这是为什么呢?原创 2022-01-05 23:42:30 · 1804 阅读 · 0 评论 -
单机版 xgboost 回归算法 demo: 通过 x 拟合 y
如何使用单机版的xgboost 拟合 数据呢,我们给而出一个demo,让大家快速掌握它的用法原创 2021-12-14 12:59:52 · 1741 阅读 · 0 评论