







 本文介绍了机器学习的基础概念,强调了何时使用机器学习,并详细阐述了机器学习问题的形式化描述,包括输入输出空间、训练数据、目标函数和假设空间。文章探讨了学习策略,特别是学习算法的选择及其在有限数据情况下的表现,讨论了过拟合现象和如何选择合适的假设空间,提出了正则化和交叉验证等克服过拟合的方法。
本文介绍了机器学习的基础概念,强调了何时使用机器学习,并详细阐述了机器学习问题的形式化描述,包括输入输出空间、训练数据、目标函数和假设空间。文章探讨了学习策略,特别是学习算法的选择及其在有限数据情况下的表现,讨论了过拟合现象和如何选择合适的假设空间,提出了正则化和交叉验证等克服过拟合的方法。
学习:“如果一个系统能够通过执行某个过程改进它的性能,这就是学习。”按照这一观点,统计学习就是计算机系统通过运用数据及统计方法提供系统性能的机器学习。
机器学习的对象是数据,它从数据出发,提取数据特征,抽象出数据模型,发现数据中的知识,又回到对数据的分析和预测中去。[机器学习关于数据的基本假设是:同类数据具有一定的统计规律性。由于它们具有统计规律性,所以可以用概率统计方法来处理。]
1. 何时使用机器学习?
根据机器学习的性质,我们可以得出:
- 存在“underlying pattern”需要我们学习,因为机器学习依靠的就是从数据中抽象模型。
- 没有programmable(easy)definition。这可以类比于:编程方法是问题的精确解、规则化的解;而机器学习是概率统计上的解。那么,可以用编程方式解决的问题,传统编程方式自然是首选。
- 必须有data,因为机器学习的对象就是data。
2. 机器学习问题的形式化描述
2.1 机器学习形式化描述图
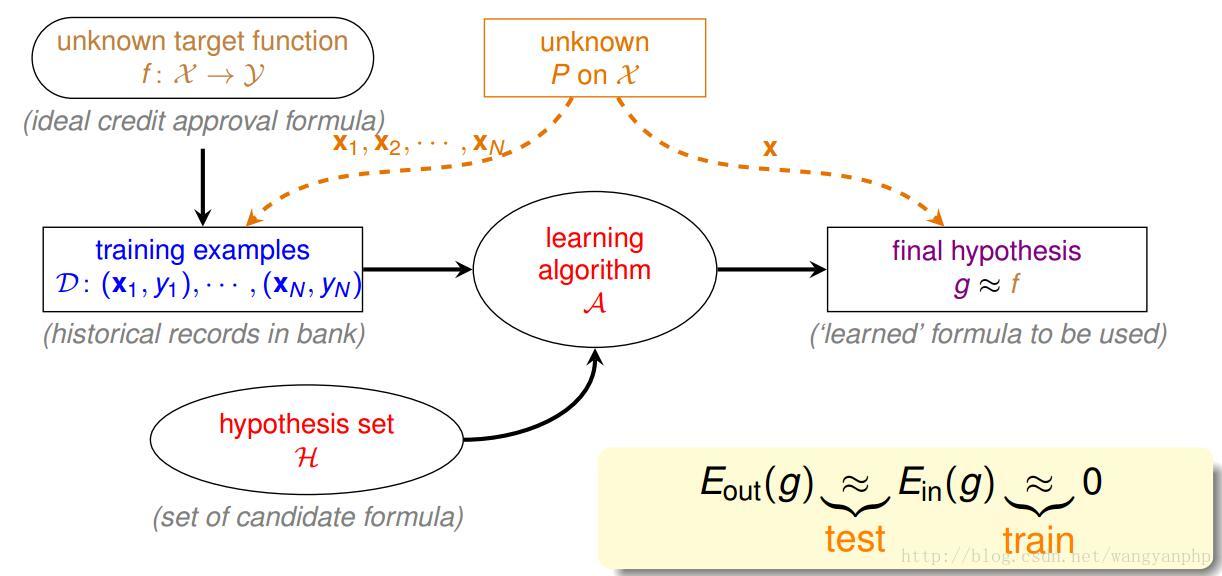
几个术语:[输入输出变量用大写表示;输入输出变量所取的值用小写表示]
- 输入空间X:输入x的所有可能取值的集合;
- 输出空间Y:输出y的所有可能取值集合;
- 训练数据D;
- 未知的目标函数 f:X−>Y (这也是机器学习想要求的理想解);
- 假设空间H:由输入空间到输出空间的映射的集合。H的确定意味着学习范围的确定
监督学习问题的文字描述:假设存在某目标函数 f:X−>Y ,我们有从f按P(x)产生的N个数据,我们要使用这N个数据+学习算法A,来从假设空间中寻找一个函数g,使得: g≈f
2.2 机器学习方法的步骤
根据上面的描述,我们可以得到实现机器学习方法的步骤:
1. 得到一个有限的训练数据集合;
2. 确定包含所有可能的模型的假设空间,即学习模型的集合;
3. 确定模型选择的准则,即学习的策略;
4. 确定求解最优模型的算法,即学习的算法;
5. 通过学习方法选择最优模型;[3、4、5合起来就是学习算法A]
6. 利用学习的最优模型对新数据进行预测和分析。
上述的6个步骤都很重要,我们会逐个讲解,其中模型的假设空间、模型选择的准则和魔性学习的算法称为机器学习算法三要素,简称:模型(model)、策略(strategy)和算法(algorithm)。
2.3 进阶版机器学习形式化描述图
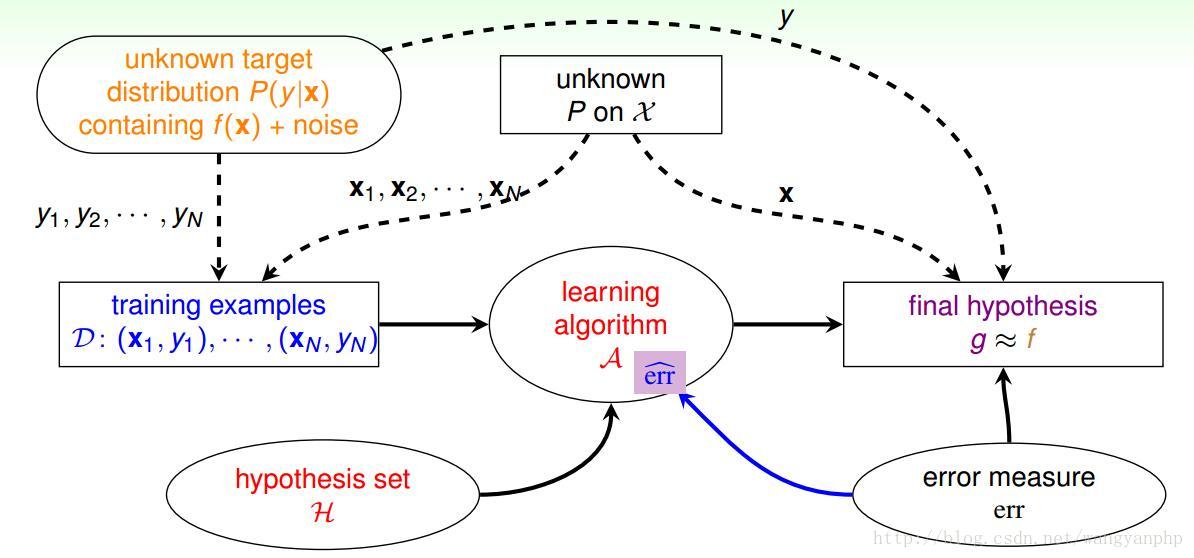
这与之间的图有两点不同;
1. 之前的training data D的来源是:(x,f(x))。其中x从服从某一概率分布P(x);现在我们假设D来源于(x,f(x)),其中x服从某一P(x),f(x)+Noise服从某一P(y);也即:X和Y服从某一联合概率分布P(x,y)。
2. 加入了error measure err和学习算法A中的 eˆrr 。[先忽视它们,后面会讲解]
根据上述的形式化描述,我们自然而然的产生如下问题:
3. Q1:学习策略是怎么的?
也即给定假设空间H,按照什么样的准则学习或选择出最优的模型g?
对于监督学习问题,假设从H中选择了一个决策函数f,那么f(X)与Y可能有差距,用一个损失函数(loss function)或代价函数(cost function)来度量预测错误的程度。
- 0-1损失函数
- 平方损失函数 L(Y,f(X))=(Y−f(X))2
- 绝对损失函数 L(Y,f(X))=|Y−f(X)|
- 对数损失函数 L(Y,P(Y|X))=−logP(Y|X)
对于y={-1,1}的二分类问题有:
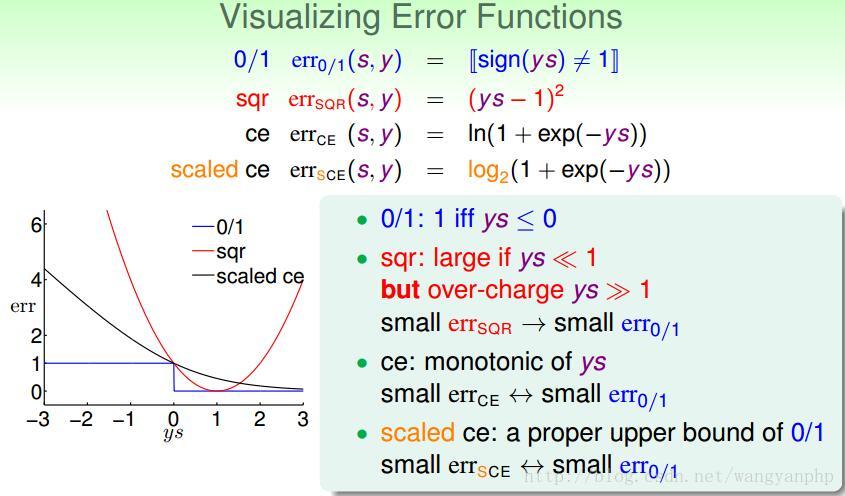
损失函数越小,模型就越好。损失函数的期望是:
Rexp(f)=Ep[L(Y,f(X))]=∫X×YL(y,f(x))P(x,y)dxdy
问题是 Rexp(f) 并不能直接计算,因为P未知。所以我们使用训练集的平均损失,称为经验风险或经验损失,来估计:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









