






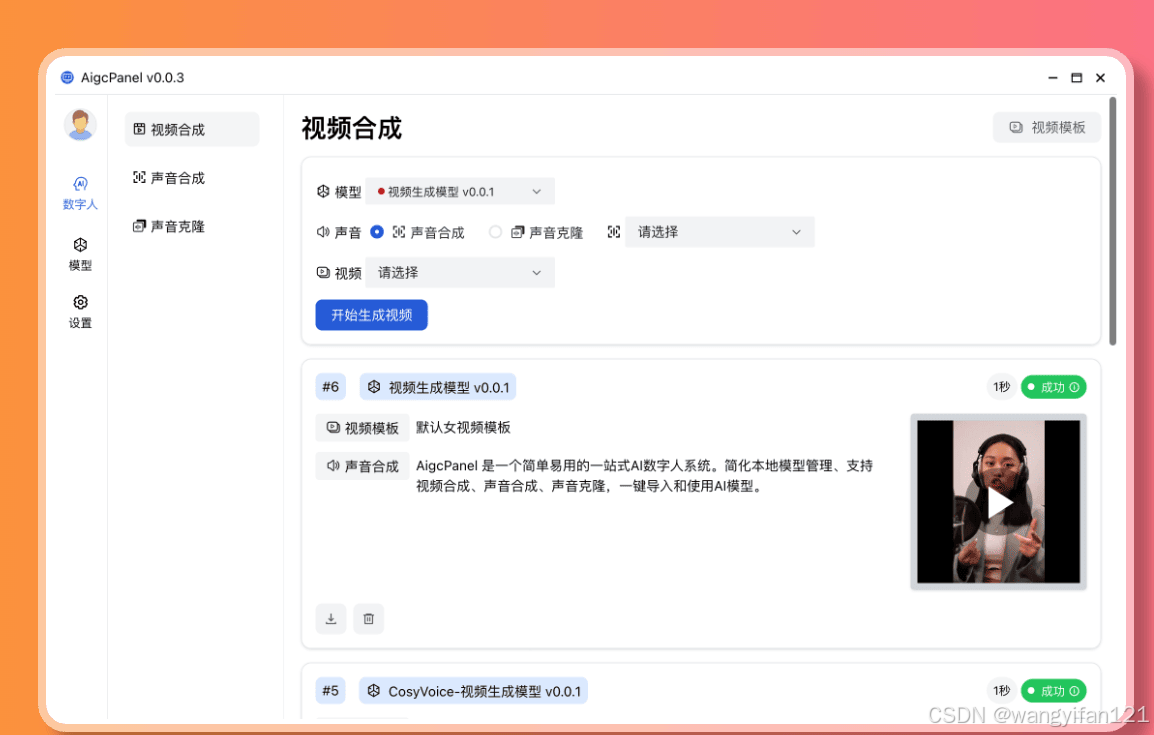
AIGCPANEL PRO版是一个简单易用的一站式AI数字人/数字分身系统,支持视频合成、声音合成、声音克隆,简化本地模型管理、一键导入和使用AI模型。功能特性
- 支持视频数字人合成,支持视频画面和声音换口型匹配
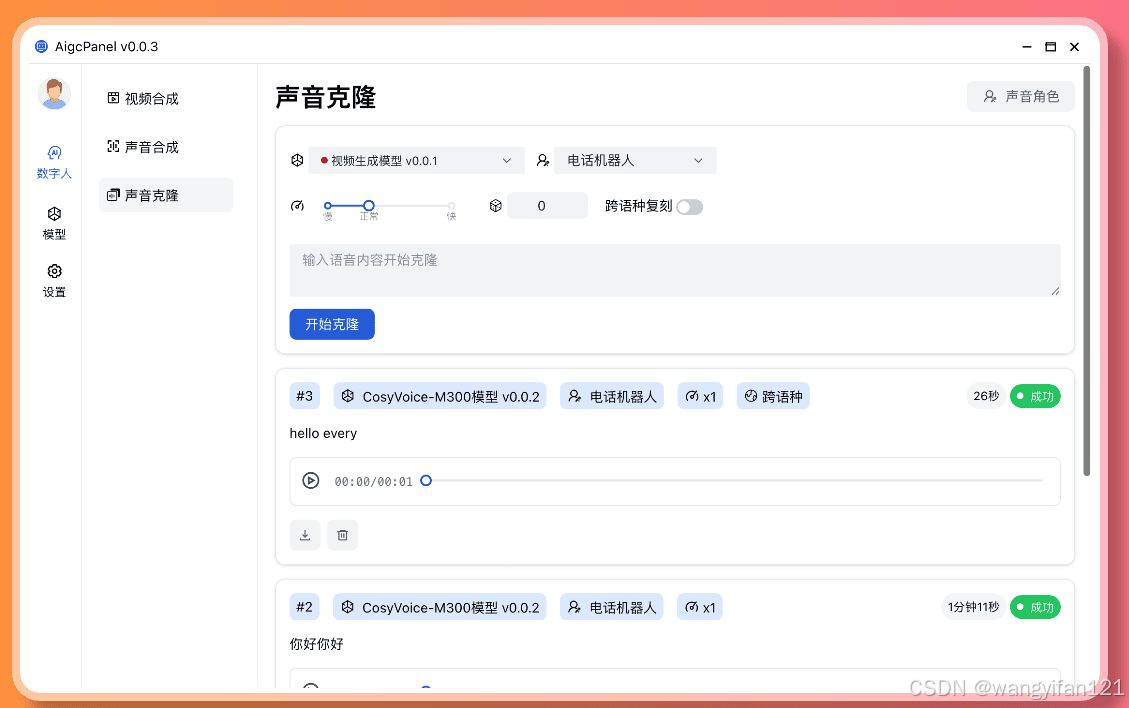
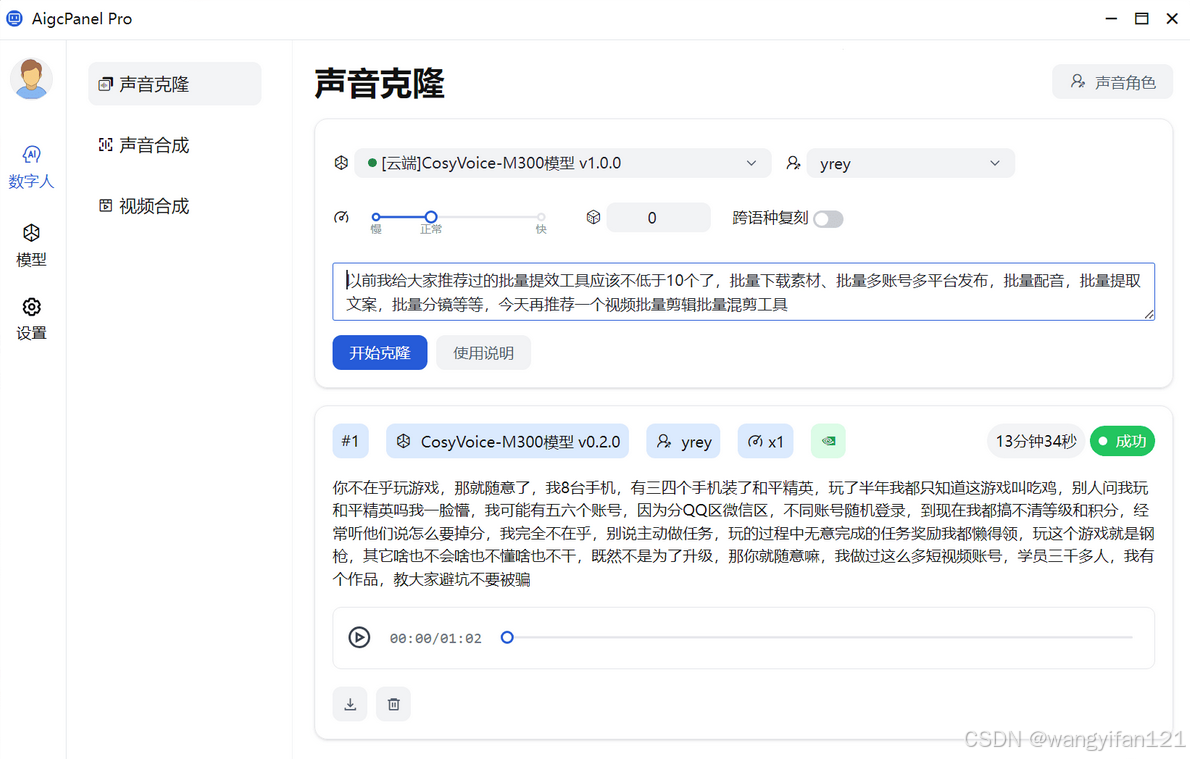
- 支持语音合成、语音克隆,多种声音参数可设置
- 支持多模型导入、一键启动、模型设置、模型日志查看
- 支持国际化,支持简体中文、英语
- 支持多种模型一键启动包:MuseTalk、cosyvoice
有本地模型/云端模型,云端模型相当于按量付费,本地模型自己算力,完全免费。
安装使用载 Windows 安装包,一键安装即可安装完成后,打开软件,下载模型一键启动包,即可使用。
模型自定义接入
如果有第三方一键启动的模型,可以按照以下方式接入。模型文件夹格式,只需要编写 config.json 和 server.js 两个文件即可。
2025-2-19更新
- 新增:模型运行完成后显示CPU、CUDA加速信息
- 新增:等待中状态,同一模型只允许一个任务运行
- 新增:启动新版本检测,支持新版本检测开关
- 新增:用户接口请求支持异常捕获配置 catchException
- 新增:任务提交验证弹窗
- 优化:MuseTalk模型性能优化
- 优化:弹窗父窗口逻辑优化
- 优化:声音模型调用重构,支持 0.2.0 版本
- 优化:模型调用错误提示更加友好
- 优化:本地模型加载由选择目录变为选择config.json文件
- 修复:跨设备文件rename异常问题
下载地址:

















 919
919

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









