







 本文详细描述了一个使用CUDA的内核,通过共享内存减少矩阵乘法的全局内存访问,实现性能优化。内核利用线程块和共享内存技术,以及strip-mining策略,显著降低内存带宽需求。然而,文章也提到了简化假设,如矩阵宽度需为线程块宽度的倍数及矩阵需为方形,后续章节将探讨带边界检查的改进版本。
本文详细描述了一个使用CUDA的内核,通过共享内存减少矩阵乘法的全局内存访问,实现性能优化。内核利用线程块和共享内存技术,以及strip-mining策略,显著降低内存带宽需求。然而,文章也提到了简化假设,如矩阵宽度需为线程块宽度的倍数及矩阵需为方形,后续章节将探讨带边界检查的改进版本。
我们现在准备展示一个tiled矩阵乘法内核,该内核使用共享内存来减少对全局内存的流量。图中4.16显示的内核。实施图4.15.中所示的阶段。在图4.16中,第1行和第2行声明Mds和Nds为共享内存变量。回想一下,共享内存变量的范围是一个块。因此,将为每个块创建一对Mds和Nds,并且一个块的所有线程都可以访问相同的Mds和Nds。这很重要,因为块中的所有线程都必须能够访问加载的M和N元素由同行进入Mds和Nds,以便他们可以使用这些值来满足他们的输入需求。
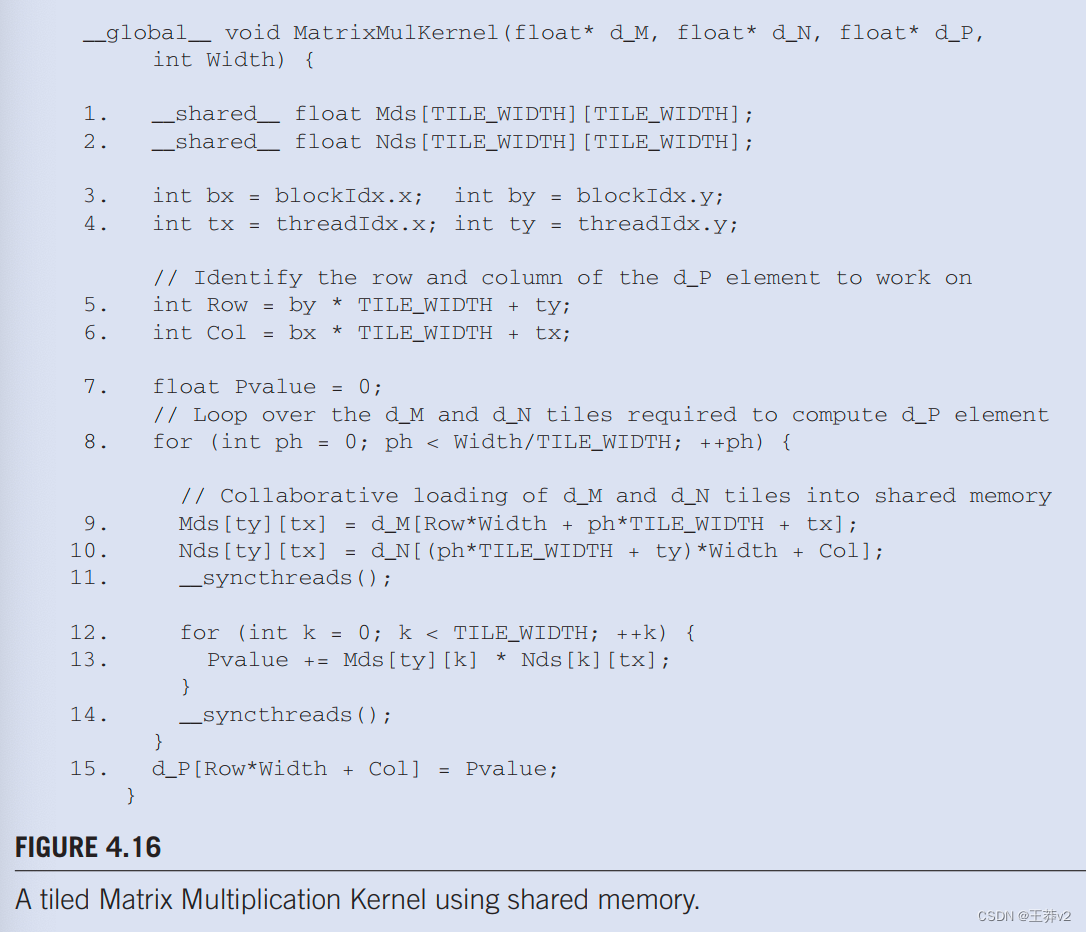
第3行和第4行将threadIdx和blockIdx值保存到自动变量中,从而保存到寄存器中,以便快速访问。回想一下,自动标量变量被放置在寄存器中。它们的范围在每个线程中;即一个tx、ty、bx和by的私有版本由运行时系统为每个线程创建,并将驻留在线程可访问的寄存器中。它们使用threadIdx和blockIdx值初始化,并在线程生命周期内多次使用。一旦线程结束,这些变量的值将不复存在。
第5行和第6行确定了线程要生成的P元素的行和列索引。该代码假设每个线程负责计算一个P元素。如第6行所示,水平(x)位置或由线程生成的P元素的列索引可以计算为bxTILE_WIDTH+ tx,因为每个块都涵盖了水平维度中的TILE_WIDTH元素。块bx中的线程在它之前会有bx线程块,或(bxTILE_WIDTH)线程;它们涵盖了P的bxTILE_WIDTH元素。同一块中的另一个tx线程将覆盖另一个tx元素。因此,带有bx和tx的线程应该负责计算x索引为bxTILE_WIDTH+ tx的P元素。这个水平索引保存
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









