







原文链接:
https://www.sciencedirect.com/science/article/pii/S0950705122013247?via%3Dihub
Knowledge-Based Systems 2023
介绍
作者认为当前基于span的关系提取方法都太关注于span内部的语义,忽略了span与span之间以及span与其他模态之间(比如tokens和labels)的交互。
因此作者提出了SMAN结构,该结构使用了cloze mechanism(完型机制)来同时提取上下文和span位置的信息,并在关系提取阶段对span和标签进行建模。
方法
SMAN模型的整体结构如下图所示:
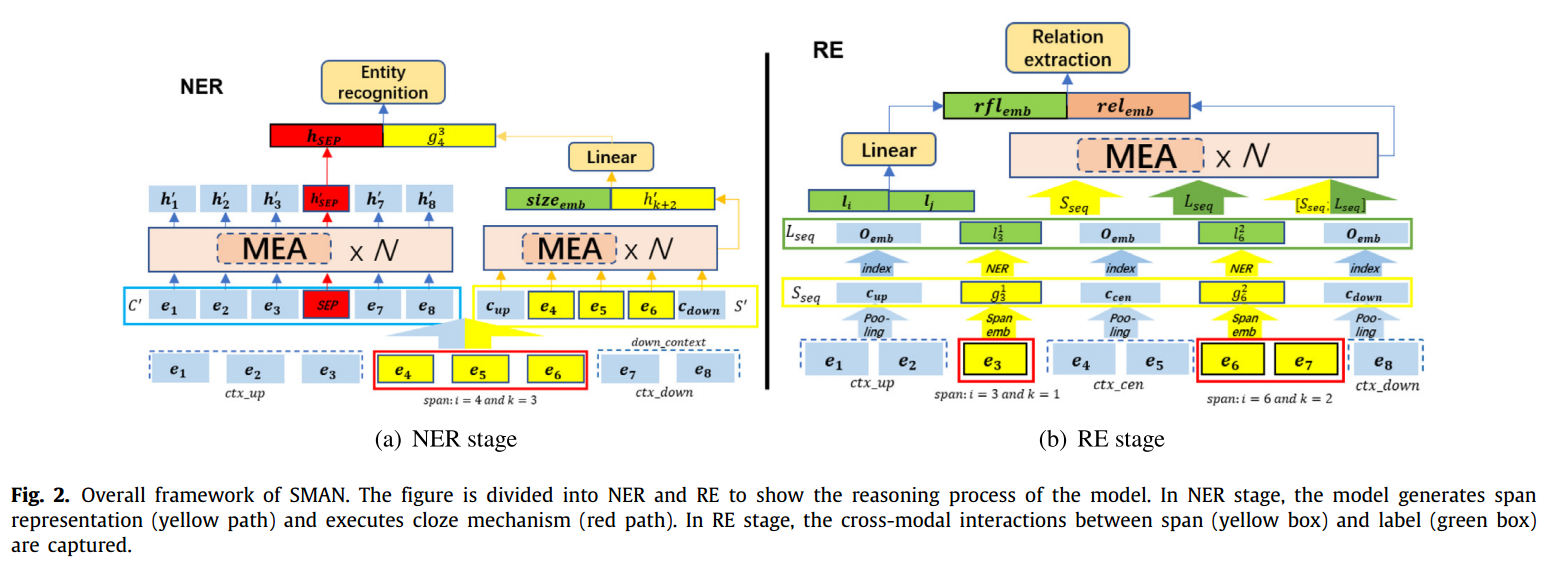
输入文件,
。在NER阶段,每个句子中枚举出的span set(最大长度设定为K的情况下)表示为:
![]()
在NER阶段,整个句子以枚举出的span为界分为3部分,以span ={e4、e5、e6}为例,则ctx_up={e1、e2,e3},ctx_down={e7,e8}。
在RE阶段,以span pair为界,分为5个子序列(如图b所示):
![]()
Modal-Enhanced Attention
该模块用于提取输入序列的高维特征,针对单模态和多模态序列提出了两种模式。结构如下图所示:
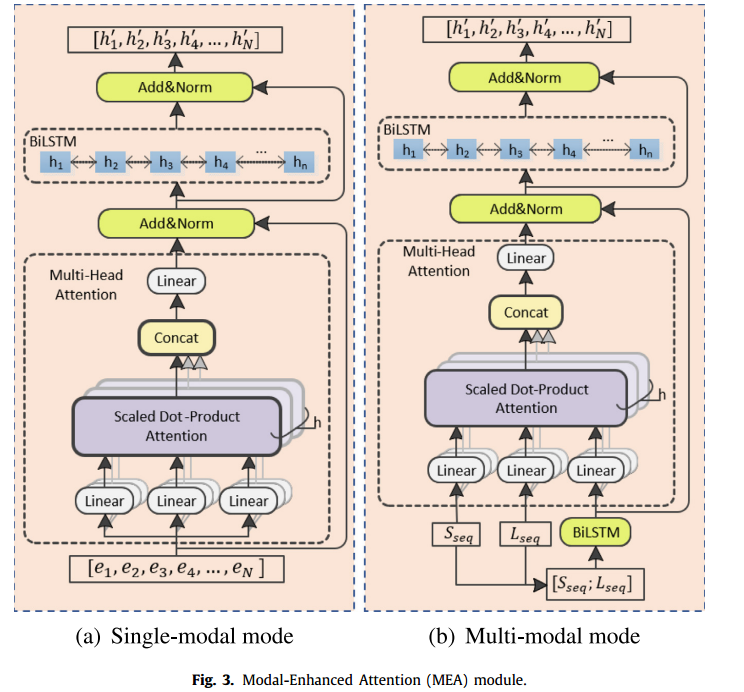
第一层是一个多头注意力块,对输入序列的全局信息进行编码。第二层是BiLSTM,重建第一层的输出并提取高维度特征,同时在每一层的后面都会使用残差连接和归一化。
Single-modal input sequence
该模块级联一个多头注意力模块和BiLSTM网络,同时加入残差连接和层归一化,来防止模型在训练过程中退化。具体的计算过程如下所示,给定输入E={e1,e2,,,eN},

![]()
Multi-modal input sequence
输入多模态的数据时,输入就不再是单一的序列,而是具有相同形状表示不同模态特征的多个序列:Sseq表示语义特征、Lseq表示label特征、SLseq由这两种特征concate通过一个BiLSTM得到。注意这里的多头注意力层只将SLseq进行了残差连接。
同样在多头注意力中,Ssqe、Lseq和SLseq分别用特征矩阵Q、K、V进行矩阵变换,完成多模态联合建模。
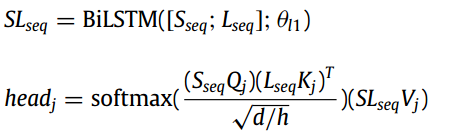
NER
如上所示,s={e4、e5、e6}是枚举出的一个实体span,为了保持word之间的顺序,同时获取到整个句子的全局和局部特征,这里就使用一个单模型的MEA来得到span表征。
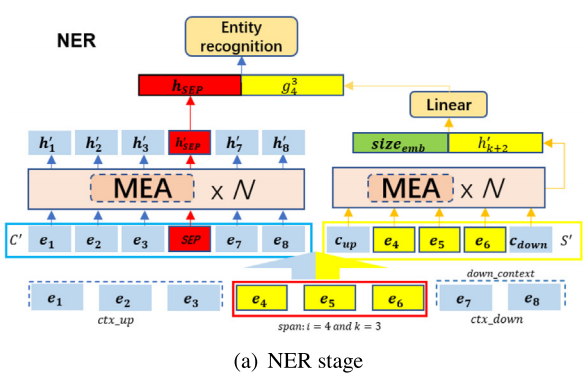
具体的,先将句子以span为界分为三个部分:ctx_up、s、ctx_down,然后对ctx_up和ctx_down分别进行最大池化,得到粗粒度的表征。

最后将、
与
进行concate作为MEA模块的输入,另外作者对span的表征还考虑了span大小的embedding
:
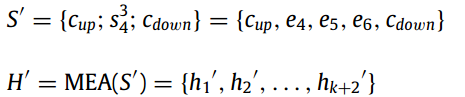
![]()
在NER阶段,引入了完型机制来充分利用上下文信息来进行辅助。如图左边部分,即将枚举的span进行maks,来使模型在上下文特征建模过程中更多的关注剩余token组成的上下文序列。
同样使用单一模型的MEA来实现,将枚举的span使用一个特殊标记SEP代替,并将最后一层中SEP的隐藏状态作为输出,最后与span的表征相结合,使用NER分类器进行分类:
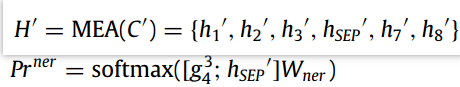
Relation extraction with multi-modal information
假设句子中存在两个实体分别是和
,同样的使用最大池化来获取两个span上下文的粗粒度特征,用于构建Seq,然后将每个span预测的label embedding与上下文的label embedding(non-entity)得到Lseq,如图中绿色框所示。

具体计算过程如下:
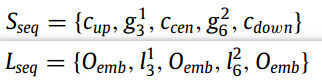
使用多模态的MEA对span pair的label和语义进行建模,将最后一层的隐藏状态作为关系过滤向量
,进入sigmoid函数(不使用softmax的原因是因为:实体对之间可能存在多种关系)来得到span之间的关系)来得到span之间的关系:
![]()
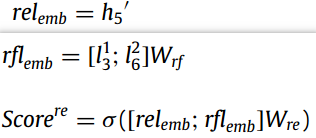
Training
主要由两部分的loss组成:NER的交叉熵损失和关系提取的二值交叉熵损失。
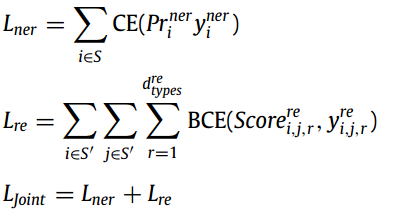
实验
对比实验
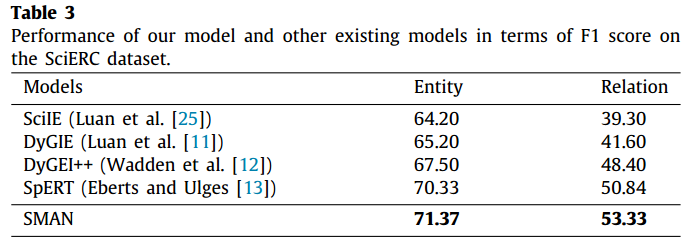
在SciERC数据集上进行实验,结果如下所示:
在CoNLL04数据集上的结果:

在ADE数据集上的结果:

分析
由于模型在RE阶段是将预测的label与span的语义进行交互,作者为了探究他提出的这种label与语义的交互的效果,在CoNLL04数据集上进行了实验,即将gold label与span的语义信息进行交互(要是这个span不是真是的span 哪里去找它的gold label?分配一个?),实验结果如下所示:
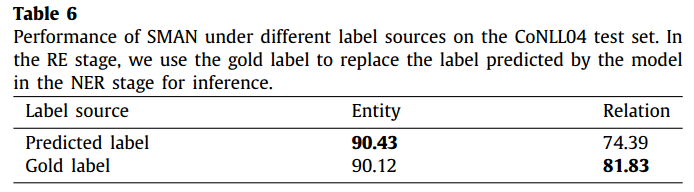
可以看出使用gold label对NER任务有副作用,但是在RE任务上有一个较大的提升,表示实体label在RE上起着重要的作用,同时作者提出的这种多模态信息交互也能提升RE任务的效果。
作者探究了该模型在不同长度句子上的表现,结果如下所示:
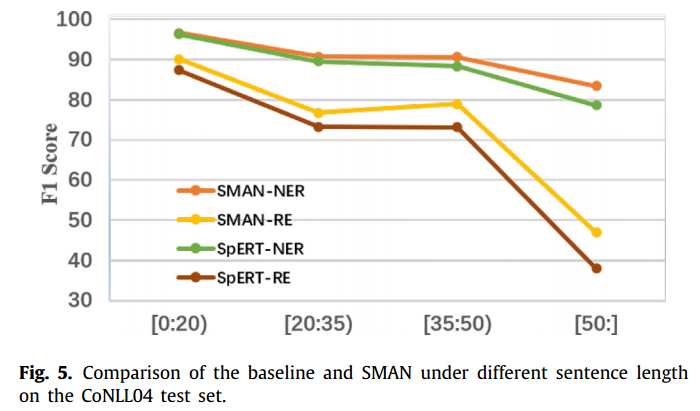
可以看出句子越长的情况下,SMAN模型的效果更好,作者认为这不仅得益与多模态之间的交互,还得益于注意力机制,使模型能够注意到全局的一个信息。
为了探究模型在不同size的span上的表现,在CoNLL04数据集上进行了实验,结果如下:
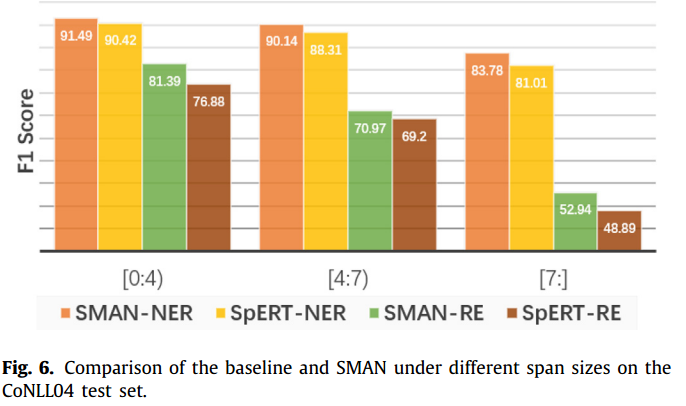
作者认为这是MAE模块中多级级联BiLSTM的效果,在捕获span表征的同时也会注意到单词顺序信息。
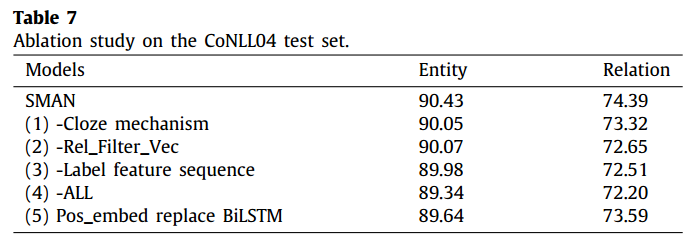
消融实验
作者对主要模块进行了消融实验,结果如下所示:
结论
作者提出了SMAN结构,主要创新点在于对上下文新的建模方式,充分利用了文本中的多模态信息。1)完型机制使得模型更好的关注于上下文信息;2)两种形式的MEA用于获取不同模态之间的信息。
将span进行mask得到上下文表征,来辅助进行NER任务,还挺有意思的,但是从消融实验的结果来看,对于NER任务的提升并不是很大(≈0.4%)。现在很多基于span的NER任务都是在丰富Span表征这一块做工作,有用到上下文表征的,有去构建句法树的。作者还使用用残差和多头注意力,根据实验结果也能看出来这两者对于长句有一定的优势,另外使用BiLSTM是一个比较普遍的方法,消融实验也可以看出来这个网络对于NER还比较有帮助的。















 1349
1349











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









