







Elasticsearch中如何进行排序
背景
最近去兄弟部门的新自定义查询项目组搬砖,项目使用ElasticSearch进行数据的检索和查询。每一个查询页面都需要根据选择的字段进行排序,以为是一个比较简单的需求,其实实现起来还是比较复杂的。这里进行一个总结,加深一下记忆。
前置知识
-
ElasticSearch是什么?
ElasticSearch 简称ES,是一个全文搜索引擎,可以实现类似百度搜索的功能。但她不仅仅能进行全文检索,还可以实现PB级数据的近实时分析和精确检索,还可以作GIS数据库,进行AI机器学习,功能非常强大。 -
ES的数据模型
ES中常用嵌套文档和父子文档两种方法进行数据建模,多层父子文档还可以形成祖孙文档。但是父子文档是一种不推荐的建模方式,这种方式有很多的局限性。如果传统关系型数据库的建模方法是通过“三范式”进行规范化,那么ES的建模方法就是反范式,进行反规范化。关系型数据库的数据是表格模型,ES是JSON树状模型。
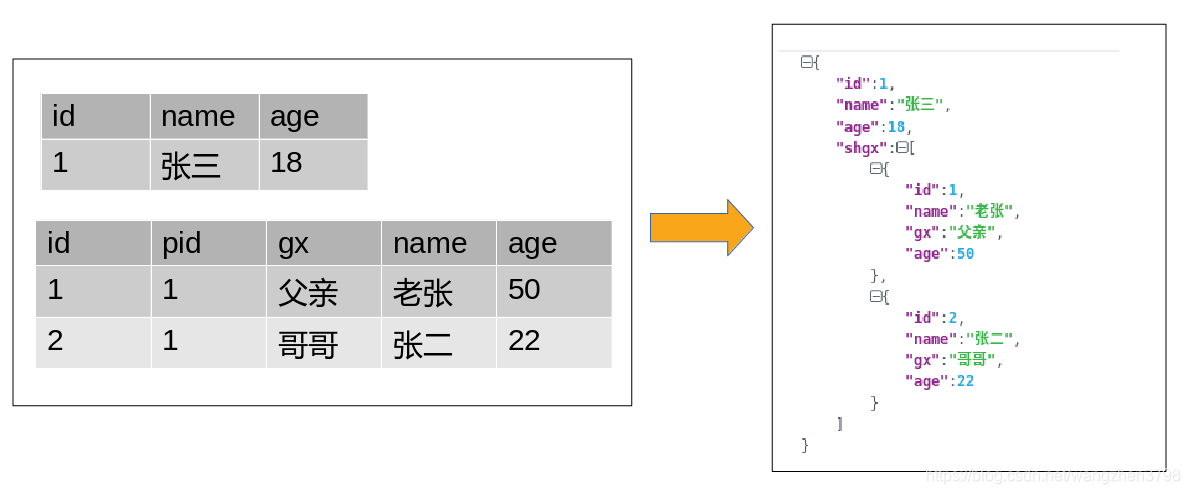
ES中排序的分类
根据建模方法的不同,ES中排序分为以下几种,每种都有不同的排序写法和局限:
- 嵌套文档-根据主文档字段排序
- 嵌套文档-根据内嵌文档字段排序
- 父子文档-查父文档-根据子文档排序
- 父子文档-查子文档-根据父文档排序
- 更复杂的情况,父子文档里又嵌套了文档,然后进行排序
- 更更复杂情况,父子文档里又嵌套了文档,然后进行脚本字段排序
- 更更更复杂情况,父子文档里又嵌套了文档,然后使用自定义脚本进行评分排序
- 更更更更…
下面分别对几种情况,进行测试说明。
测试数据准备
首先,设置索引类型字段映射
PUT /test_sort
{
"mappings": {
"zf":{
"properties": {
"id":{"type": "keyword"},
"name":{"type": "keyword"},
"age":{"type": "integer"},
"shgx":{"type": "nested"}
}
}
}
}
然后新建测试数据
PUT /test_sort/zf/1
{
"id":1,
"name":"张三",
"age":18,
"shgx":[{
"id":1,
"name":"老张",
"age":50,
"gx":"父亲"
},{
"id":2,
"name":"张二",
"age":22,
"gx":"哥哥"
}]
}
PUT /test_sort/zf/2
{
"id":2,
"name":"李四",
"age":25,
"shgx":[{
"id":3,
"name":"李五",
"age":23,
"gx":"弟弟"
}]
}
- 嵌套文档-根据主文档字段排序
根据zf主文档age字段倒叙排列,直接加sort子语句就可以
POST /test_sort/zf/_search
{
"query": {
"match_all": {
}
},
"sort": [
{
"age": {
"order": "desc"
}
}
],
"_source": {"include": ["id","name","age"]}
}
结果:
"hits": [
{
"_index": "test_sort",
"_type": "zf",
"_id": "2",
"_score": null,
"_source": {
"name": "李四",
"id": 2,
"age": 25
},
"sort": [
25
]
},
{
"_index": "test_sort",
"_type": "zf",
"_id": "1",
"_score": null,
"_source": {
"name": "张三",
"id": 1,
"age": 18
},
"sort": [
18
]
}
]
- 嵌套文档-根据内嵌文档字段排序
根据age小于50岁的亲属排序,理论上李四应该排第一位,因为50岁以下的亲属,李五最大。,凭直觉先这样写
POST /test_sort/zf/_search
{
"query": {
"nested": {
"path": "shgx",
"query": {
"range": {
"shgx.age": {
"lt": 50
}
}
}
}
},
"sort": [
{
"shgx.age": {
"nested_path": "shgx",
"order": "desc"
}
}
]
}
看结果:
"hits": [
{
"_index": "test_sort",
"_type": "zf",
"_id": "1",
"_score": null,
"_source": {
"id": 1,
"name": "张三",
"age": 18,
"shgx": [
{
"id": 1,
"name": "老张",
"age": 50,
"gx": "父亲"
},
{
"id": 2,
"name": "张二",
"age": 22,
"gx": "哥哥"
}
]
},
"sort": [
50
]
},
{
"_index": "test_sort",
"_type": "zf",
"_id": "2",
"_score": null,
"_source": {
"id": 2,
"name": "李四",
"age": 25,
"shgx": [
{
"id": 3,
"name": "李五",
"age": 23,
"gx": "弟弟"
}
]
},
"sort": [
23
]
}
]
非常重要 and 非常重要 这样写的结果是错误的,原因是嵌套文档是作为主文档的一部分返回的。在主查询中的过滤条件并没有把不符合条件的内部嵌套文档过滤调,以至于排序嵌套文档时,*还是按照全部的嵌套文档排序的。要想避免这种情况,要把主查询中有关嵌套文档的查询条件,在排序中再写一遍。
正确的写法:
POST /test_sort/zf/_search
{
"query": {
"nested": {
"path": "shgx",
"query": {
"range": {
"shgx.age": {
"lt": 50
}
}
}
}
},
"sort": [
{
"shgx.age": {
"nested_path": "shgx",
"order": "desc",
"nested_filter": {
"range": {
"shgx.age": {
"lt": 50
}
}
}
}
}
]
}
- 父子文档-查父文档-根据子文档排序
构造测试数据,首先设置父子文档的映射关系
PUT /test_sort_2
{
"mappings": {
"zf_parent":{
"properties": {
"id":{"type": "keyword"},
"name":{"type": "keyword"},
"age":{"type": "integer"}
}
},
"shgx":{
"_parent": {
"type": "zf_partent"
}
}
}
}
然后,添加数据。
PUT /test_sort_2/zf_parent/1
{
"id":1,
"name":"张三",
"age":18
}
PUT /test_sort_2/zf_parent/2
{
"id":2,
"name":"李四",
"age":25
}
PUT /test_sort_2/shgx/1?parent=1
{
"id":1,
"name":"老张",
"age":50,
"gx":"父亲"
}
PUT /test_sort_2/shgx/2?parent=1
{
"id":2,
"name":"张二",
"age":22,
"gx":"哥哥"
}
PUT /test_sort_2/shgx/3?parent=2
{
"id":3,
"name":"李五",
"age":23,
"gx":"弟弟"
}
然后,再根据age小于50岁的亲属排序,正序排序的话张三应该是第一位,
POST /test_sort_3/zf_parent/_search
{
"query": {
"has_child": {
"type": "shgx",
"query": {
"range": {
"age": {
"lt": 50
}
}
},
"inner_hits": {
"name": "ZfShgx",
"sort": [
{
"age": {
"order": "asc"
}
}
]
}
}
}
}
排查结果:
{
"_index": "test_sort_3",
"_type": "zf_parent",
"_id": "2",
"_score": 1,
"_source": {
"id": 2,
"name": "李四",
"age": 25
},
"inner_hits": {
"ZfShgx": {
"hits": {
"total": 1,
"max_score": null,
"hits": [
{
"_type": "shgx",
"_id": "3",
"_score": null,
"_routing": "2",
"_parent": "2",
"_source": {
"id": 3,
"name": "李五",
"age": 23,
"gx": "弟弟"
},
"sort": [
23
]
}
]
}
}
}
},
{
"_index": "test_sort_3",
"_type": "zf_parent",
"_id": "1",
"_score": 1,
"_source": {
"id": 1,
"name": "张三",
"age": 18
},
"inner_hits": {
"ZfShgx": {
"hits": {
"total": 1,
"max_score": null,
"hits": [
{
"_type": "shgx",
"_id": "2",
"_score": null,
"_routing": "1",
"_parent": "1",
"_source": {
"id": 2,
"name": "张二",
"age": 22,
"gx": "哥哥"
},
"sort": [
22
]
}
]
}
}
}
}
结果是错误的,李四在前,查看官方文档的父子文档时不能直接用子文档排序父文档,或者用父文档排序子文档。那有没有解决办法呢?有一个曲线救国的方案,使用function_score通过子文档的评分来影响父文档的顺序,但是评分算法很难做到精准控制顺序。
中文字符排序
在项目中发现,中文字符在ES中的顺序和在关系型数据库中的顺序不一致。经查原因是因为ES是用的unicode的字节码做排序的。即先对字符(包括汉字)转换成byte[]数组,然后对数组进行排序。这种排序规则对ASIC码(英文)是有效的,但对于中文等亚洲国家的字符不适用,怎么办呢?有两种办法:
- 第一种,做拼音冗余。即在向ES同步数据时候,同步程序将汉字字段同时转换成拼音,在ES里专用用于汉字排序。如:
#插入信息
POST /test/star/1
{
"xm": "刘德华",
"xm_pinyin": "liudehua"
}
POST /test/star/2
{
"xm": "张惠妹",
"xm_pinyin": "zhanghuimei"
}
# 查询排序
POST /test/star/_search
{
"query": {
"match_all": {}
},
"sort": [
{
"xm_pinyin": {
"order": "desc"
}
}
]
}
- 第二种,使用ICU分词插件。使用插件提供的icu_collation_keyword 过滤器,实现中文排序。
PUT test2
{
"mappings": {
"user": {
"properties": {
"xm": {
"type": "text",
"fields": {
"sort": {
"type": "icu_collation_keyword",
"index": false,
"language": "zh",
"country": "CN"
}
}
}
}
}
}
}
POST /test/star/_search
{
"query": {
"match_all": { }
},
"sort": "xm.sort"
}
结论
- 嵌套文档-根据主文档字段排序时,可以使用sort语句直接排序,无限制。
- 嵌套文档-根据嵌套文档字段排序时,必须在sort子句里把所有有关的查询条件,重新写一边,排序才正确。
- 父子文档-查父文档-根据子文档排序不能根据子文档排序父文档,反之亦然。
- 数据模型的复杂程度决定了排序的复杂程度,排序的复杂程度随着模型的复杂程度成指数级增加。
- 中文字符可以通过做拼音冗余和使用ICU插件来实现排序。















 580
580











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









