










笔记内容都是记录对我有意义的方面,供我以后个人复习参考,打扰大家,还望海涵。
第二周任务一笔记:
np.linalg.norm()函数:
官方解释网址:https://numpy.org/doc/1.18/reference/generated/numpy.linalg.norm.html
np.linalg.norm(x, ord=None, axis=None, keepdims=False)
参数解释:
x:输入矩阵
如果参数axis为None,x必须为一维或者二维,除了ord为None时。如果ord和axis都为None,则返回的是norm of x.ravel。
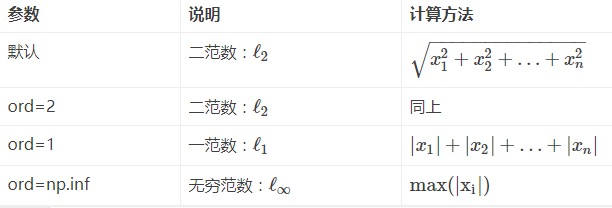
ord:可选输入
范数类型
图片来自:https://blog.csdn.net/hqh131360239/article/details/79061535
axis:可选输入
值为1时,求各行的范数;值为0时,求各列的范数;值为None时,求矩阵的范数。
keepding:输出矩阵的特性
值为True时,表示保持输入矩阵的维度特性;值为False时,不保持矩阵的维度特性。
第二周任务二笔记:
预处理数据需要记住的一般步骤:
**What you need to remember:**
Common steps for pre-processing a new dataset are:
- Figure out the dimensions and shapes of the problem (m_train, m_test, num_px, ...)
- Reshape the datasets such that each example is now a vector of size (num_px * num_px * 3, 1)
- "Standardize" the data
np.dot() 函数:
官方网址: https://numpy.org/doc/1.18/reference/generated/numpy.dot.html
numpy.dot(a, b, out=None)
参数解释:
1. 当a和b是一维时,得到的是向量的内积;
2. 当a和b是二维时,得到的是矩阵乘积,但是建议使用matmul或者a @ b进行计算;
3. 当a或者b是0维时,作用相当于multiply,并且建议使用multiply(a,b) 或者 a*b;
4. 当a和b是多维时,就是矩阵和矩阵相乘。
总结步骤:
1. 预处理数据:preprocess()
2. 初始化参数:initialize()
3. 梯度下降(Gradient descent):前向传播和后向传播
propagate()->optimize()
4. predict()
5. Merge all functions into a model















 207
207











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









