






 本文探讨了AIAgent的不同架构,如React的环境反馈机制、ChainofThought的推理过程和TreeofThought的树状结构,以及Reflexion如何增强强化学习。还介绍了Self-Ask和Plan-and-executeagents的特点及局限性。
本文探讨了AIAgent的不同架构,如React的环境反馈机制、ChainofThought的推理过程和TreeofThought的树状结构,以及Reflexion如何增强强化学习。还介绍了Self-Ask和Plan-and-executeagents的特点及局限性。
目录
如何理解一个 agent?
目前与AI的交互形式基本上都是你输入指令,AI模型会根据你的指令内容做出响应,这样就是导致你每次在进行提供有效的提示词才能达到你想要的效果。
而AI Agent则不同,它被设计为具有独立思考和行动能力的AI程序。你只需要提供一个目标,比如写一个游戏、开发一个网页,他就会根据环境的反应和独白的形式生成一个任务序列开始工作。就好像是人工智能可以自我提示反馈,不断发展和适应,以尽可能最好的方式来实现你给出的目标。
Agent架构
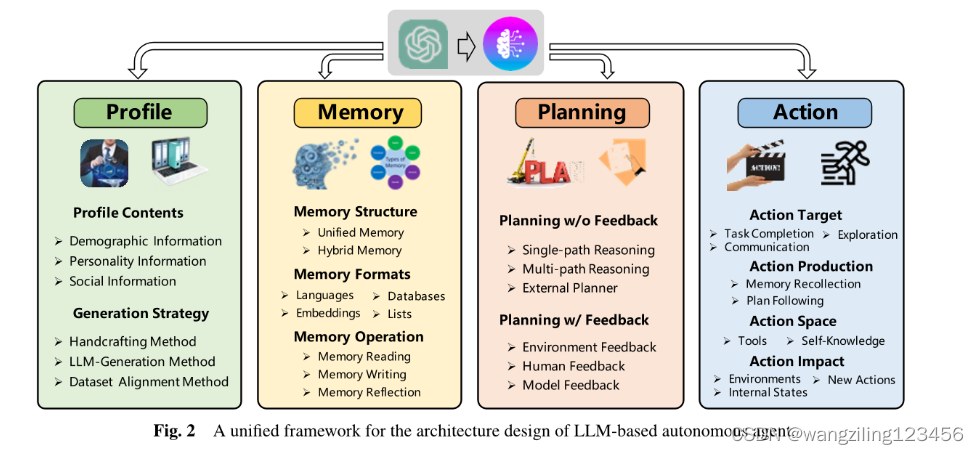
配置模块
内存模块
规划模块
1.无反馈规划
1)单路径规划 2) 多路径规划
Chain Of Thought Tree Of Thought
2.有反馈规划
1)环境反馈
来自客观世界或虚拟环境。例如,它可能是游戏的任务完成信号或代理采取行动后的观察结果
React
2) 人类反馈
除了从环境中获取反馈外,与人直接互动也是增强代理规划能力的一种直观策略
3) 模型反馈
来自代理自身的内部反馈的利用
提出了一种自我改进机制。该机制由三个关键组件组成:输出、反馈和改进。首先,代理人生成一个输出。然后,它使用 LLM 对输出进行反馈,并提供如何改进输出的指导。最后,输出通过反馈和改进得到改善。这个输出-反馈-改进过程会迭代直到达到某些期望条件。
动作模块
什么是React?
环境反馈
ReAct 实际上是一种通过多次调用 LLM 以交错的方式生成推理轨迹和特定于任务的动作,从而实现两者之间更大的协同作用
推理轨迹帮助模型归纳、跟踪和更新行动计划以及处理异常,而操作允许它与外部源(例如知识库或外部环境、API)交互,以收集附加信息。
由此上面的定义可知,ReAct需要迭代的使用 3 类元素:
Thought (思考)。LLM基于用户提出的问题进行推理(Reasoning),并根据推理的结果采取某种行为,类似人类大脑的思考、决策过程。
Action (行为)。LLM将决策行为动作的指令发送给外部源(比如调用知识库、外部的API),这就是行为。在上面的例子中,LLM告诉你可能的原因列表,示意你去检查这些原因。
Observation(观察)。行为会产生结果,这个结果是可以被LLM观察的。
LLM汇总用户的问题、这一次(每一次)产生的Thought、Action和Observation,进行Reasoning后,会产生新的的Thought、Action和Observation。以此类推,直到LLM的action代表结束。
上面例子的迭代示例如下:
Step 1 中,LLM基于 Question 先think(reasoning),然后再决定采取什么行动。这样LLM就会生成 Thought 1 和 Action 1 。执行 Action 1 获得 Observation 1。
Step 2 中,LLM基于 Question,Thought 1 ,Action 1 和 Observation 1,汇总所有信息先think(reasoning),然后再决定采取什么行动。这样LLM就会生成 Thought 2 和 Action 2 。执行 Action 2 获得 Observation 2。
Step 3 中,LLM基于 Question,Thought 1 ,Action 1 ,Observation 1,Thought 2 ,Action 2 和 Observation 2,汇总所有信息先think(reasoning),然后再决定采取什么行动。这样LLM就会生成 Thought 3 和 Action 3 。执行 Action 3 获得 Observation 3。
以此类推直到 Action 表示结束。
简述
ReAct [59] 提出使用Thought、Action和Observation三元组构建提示。thought部分旨在促进推理和规划,以引导agent的行为。action代表代理执行的具体操作。执行action操作结果获得observation。下一个想法受到先前观察的影响,这使得生成的计划更能适应环境。
什么是 Chain of Thought?
在Agent规划模块中处理推理任务时,给出答案之前产生的一系列连贯的中间推理步骤。
特点
在问LLM问题前,手工在prompt里面加入一些包含思维过程(Chain of thought)的问答示例,就可以让LLM在推理任务上大幅提升。
1、COT在原则上能够让模型把一个多步问题可以分解出多个中间步骤,就可以使那些需要更多推理步骤的问题,就有机会分配到更多的计算量。
这个怎么理解呢?因为语言模型在生成下一句的时候是token by token,假设你的问题越难,COT又使得你生成的中间步骤够多,那么总体上生成的token就会越多,自然在解决更难问题时,就可以用到更多的计算量。
类比我们人脑,在解决更难问题时会消耗更多的脑力,COT也可以让LLM在解决更难的问题时,消耗更多的计算资源。
2、COT提供了可解释性,也就是通过COT,可以不仅仅知道答案,也可以知道答案是怎么来的。
3、COT在原则上适用于任何人类能用语言所解的问题,不只是数学、逻辑、推理问题。
4、当一个语言模型训练好后,就可以像比如few-shot prompting这种范式,在每个样例中写入中间推理步骤,再跟上要解的问题,丢给语言模型,就能够引发语言模型帮你续写出中间的推理步骤。
结论
1、 CoT Prompting对于小模型的效果并不明显,只在大于100B参数的模型中才产生了优于 Standard Prompting的效果。
2、 CoT Prompting对于复杂问题的效果更明显,实验中用了三个数据集,其中GSM8K是最复杂的,从实验结果上也是它相对于Standard Prompting提升的效果大于1倍。
局限性
1、虽然CoT模拟了人类推理的思维过程,但是仍然不能确认神经网络是否真的在“推理”,这仍是个尚未解决的问题。
2、手动生成CoT样例的成本问题。
3、无法保证正确的推理路径。
4、CoT仅仅能在大模型上出现。
Zero-shot CoT
大模型可能不需要写一堆CoT来作为prompt,它自己可能就会推理了,秘诀就是加上一句咒语:“Let’s think step by step.”
通过实验发现,Zero-shot CoT还是可以显著提升LLM的数学推理能力的。虽然Zero-shot CoT和Few-shot CoT都会犯错,但是犯错误时的特点很不一样:Zero-shot方法在推出正确答案后,可能会继续“画蛇添足”,导致最终错误;另外,Zero-shot有时候干脆不推理,直接重复题目。Few-shot方法则是在生成的推理过程中包含三元运算的时候很容易出错,例如(3+2)*4。另外Zero-shot CoT在常识推理问题上的提升不大。
总体上,Few-shot CoT的效果还是比Zero-shot CoT更好的。
Auto-CoT
Zero-shot CoT没有使用 In-Context-Learning,Few-shot CoT使用了 In-Context-Learning。ICL 提供了LLM更多的示范信息,可能能让LLM在输出的时候更加规范。
那是不是可以先通过 Zero-shot CoT 来让 LLM 产生很多带有推理的QA pair,然后把这些QA pair加入到prompt中,构成ICL的上文,再让LLM进行推理。
1、给定待测试的问题,从无标注问题集合中,采样一批问题;
2、使用 GPT-3 作为产生推理过程的工具,即直接使用 “Let’s think step by step.” 咒语,来对这一批采样的问题产生推理过程;
3、把产生的这些问题和推理过程,构成In-Context-Learning的上文加入到prompt中,再让LLM对问题进行回答。
什么是 Tree of Thought?
在这种策略中,生成最终计划的推理步骤被组织成树状结构。每个中间步骤可以有多个后续步骤。这种方法与人类思维相似,因为个人在每个推理步骤中可能有多种选择。具体来说,Self-consistent CoT( CoT-SC)[49] 认为每个复杂问题都可以通过多种思维方式来推导出最终答案。因此,它首先使用 CoT 生成各种推理路径及其相应的答案。随后,选择具有最高频率的答案作为最终输出。
Tot旨在使用类似树形的推理结构来生成计划。在此方法中,树中的每个节点表示一个“想法”,这对应于在推理步骤中。选择这些中间步骤基于对 LLM 的评估。最后,使用广度优先搜索(BFS)或深度优先搜索(DFS)策略生成最终计划。
什么是 Reflexion?
在混合记忆中,Reflection 利用短期滑动窗口捕获最近的反馈,并使用持久的长期存储来保留凝练的见解。这种结合使我们可以利用详细的即时体验和高层次的抽象。
Reflexion通过自我反思来增强语言模型的强化学习能力,使用口头强化来帮助agent从之前的失败中学习。 Reflexion将环境中的二进制或标量反馈转换为文本摘要形式的口头反馈,然后将其作为下一个episode中LLM agent的附加上下文添加。这种自我反思的反馈通过提供具体的改进方向来充当“语义”梯度信号,帮助它从以前的错误中学习以更好地完成任务。
Reflexion具有以下优点:
- 轻量化,不需要微调语言模型。
- 支持细致的反馈形式,不仅有标量奖励。
- 具有明确的记忆机制,可以积累经验episode,为后续episode提供更明确的行动提示。
- 引入自我反思步骤,可以识别错误并自我推理如何改进。
有哪些 agent 框架,他们各自的特点是什么?可能有的优点和缺点是什么?
Agent类型
React
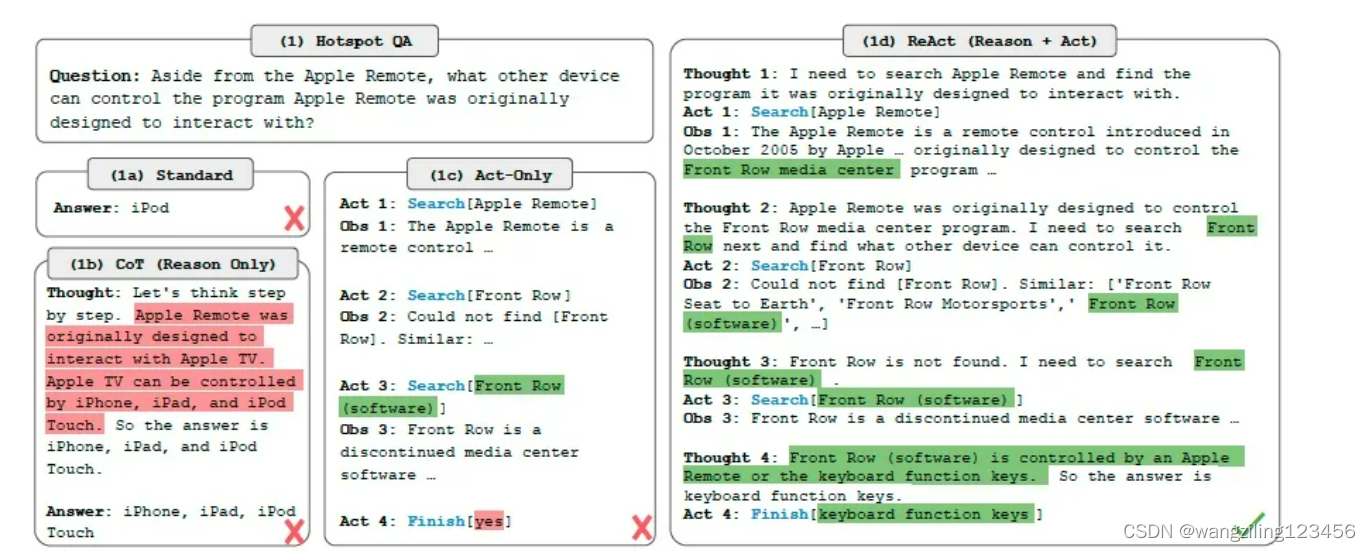
ReAct本质上就是把融合了Reasoning和Acting的一种范式,推理过程是浅显易懂,仅仅包含thought-action-observation步骤,很容易判断推理的过程的正确性,使用ReAct做决策甚至超过了强化学习
Self-ask
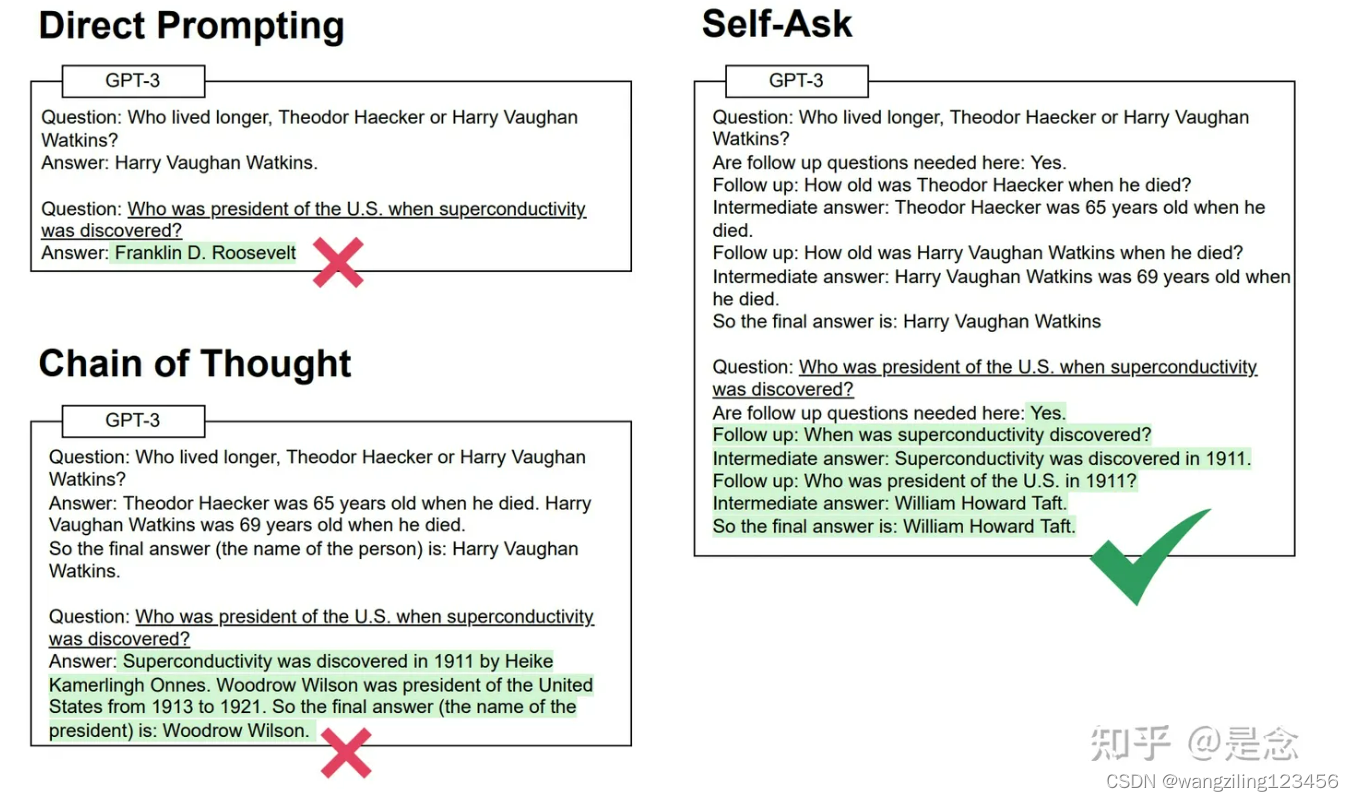
Self Ask提出了一种把问题拆解成子问题的Prompt范式,每一步模型都会自我提问是否可以把问题改写/拆解成一个简单的子问题,并进行回答,回答时可以调佣搜索工具来获得答案,然后根据工具返回结果,继续进行自我提问,直到获得最终答案。其实自我提问的推理形式并不是核心,核心是引导模型来进行问题拆解,也就是开头提到的规划能力。
Self-ask需要一个或者少量的prompt来演示如何回答的提示问题。
我们的提示从这些例子开始,之后我们附加inference-time question,然后在prompt的末尾插入短语“Are follow up questions needed here:",因为我们发现这样做会略微改善结果。然后模型输出一个响应。在大多数情况下,它首先输出“Yes”,这意味着后续行动问题是必要的。然后LM输出第一个follow-up问题,回答它,然后继续询问并回答follow-up问题,直到它决定有足够的信息为止。最终会输出:"So the final answer is:",这使得最终答案可以很容易根据":"解析出来。
Plan-and-execute agents
Plan-and-execute agents这个方法本质上是先计划再执行,即先把用户的问题分解成一个个的子任务,然后再执行各个子任务,最后合并输出得到结果。做法也比较简单,prompt的形式需要改变一下,前面的论文使用的是“Let’s think step by step”,在这里使用新的prompt,“Let’s first understand the problem and devise a plan to solve the problem. Then, let’s carry out the plan and solve the problem step by step”
参考文章
https://blog.csdn.net/hjingfeng/article/details/136419072
AI Agents系列—— 探究大模型的推理能力,关于Chain-of-Thought的那些事儿_chain of thought存在什么问题-CSDN博客
LLM As Agents(4)——Reflexion - 知乎 (zhihu.com)
2023年新生代大模型Agents技术,ReAct,Self-Ask,Plan-and-execute,以及AutoGPT, HuggingGPT等应用 - 知乎 (zhihu.com)


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









