






目录
为什么要对大模型进行微调
2018年BERT问世后,NLP任务的主流范式已经变为预训练语言模型+微调。从大多数模型的自我对比来说,尺寸越大,效果越好。预训练语言模型的趋势为:大 → 更大 → 再大。BERT-Base只有0.1B,而现在意义上的大模型,起步就要6、7B,更大的模型带来了更好的性能,但是也带来了一些问题。
1.以传统微调的方式对模型进行全量参数更新会消耗巨大的计算与存储资源。
2.个人层面,很难拥有充足的资源进行训练
参数高效微调
在上述的情况下,参数高效微调(Parameter-efficient fine-tuning,PEFT)应运而生。
参数高效微调方法仅对模型的一小部分参数(这一小部分可能是模型自身的,也可能是外部引入的)进行训,便可以为模型带来显著的性能变化,一些场景下甚至不输于全量微调,颇有一种四两拨千斤的感觉。
由于训练一小部分参数,极大程度降低了训练大模型的算力需求,不需要多机多卡,单卡即可完成对一些大模型的训练,不仅如此,少量的训练参数对存储的要求同样降低了很多,大多数的参数高效微调方法只需要保存训练部分的参数,与动辄几十GB的原始大模型相比,几乎可以忽略。
参见的高效微调方法
高效微调技术可以粗略分为以下三大类:增加额外参数(A)、选取一部分参数更新(S)、引入重参数化(R)。而在增加额外参数这类方法中,又主要分为类适配器(Adapter-like)方法和软提示(Soft prompts)两个小类。
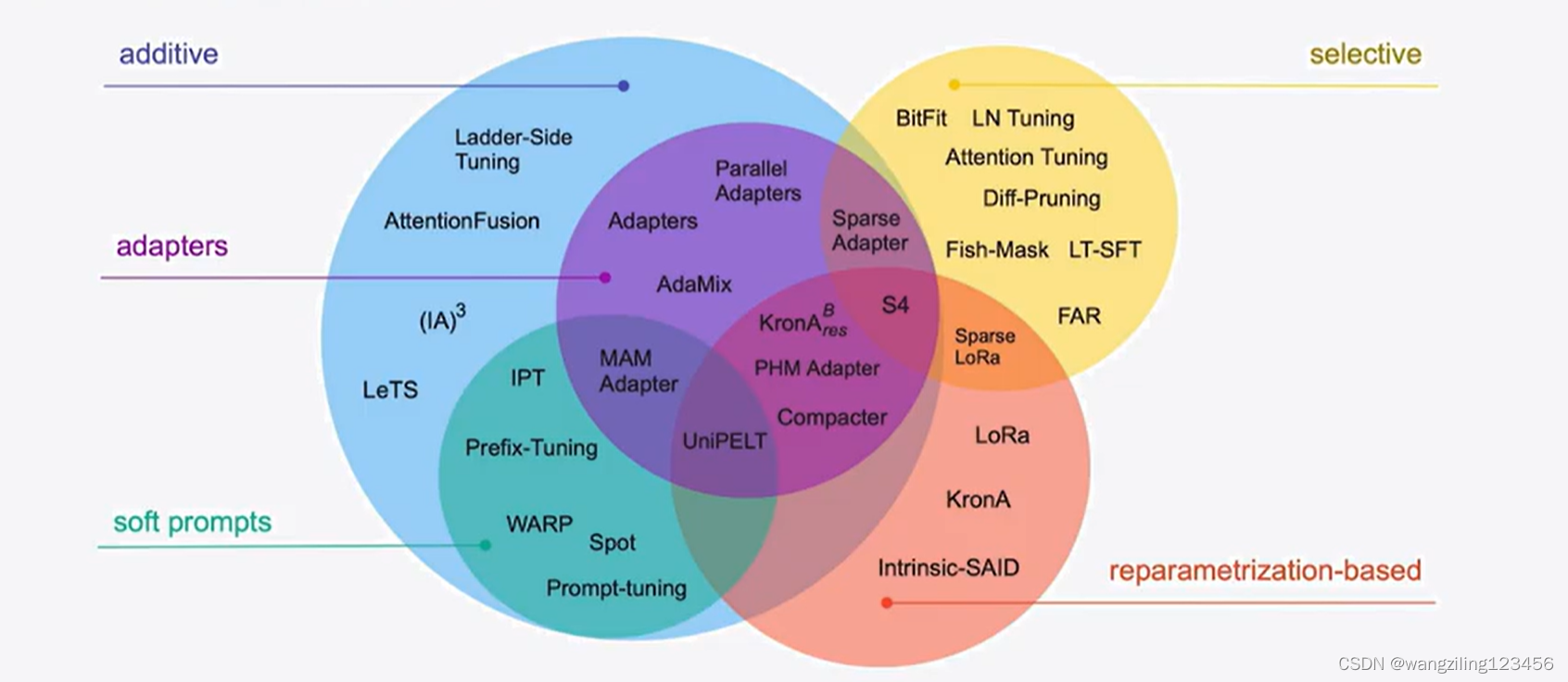
PEFT是什么
PEFT(Parameter-Efficient Fine-Tuning)是hugging face开源的一个参数高效微调大模型的工具,里面集成了4种微调大模型的方法,可以通过微调少量参数就达到接近微调全量参数的效果,使得在GPU资源不足的情况下也可以微调大模型。
常见的高效微调方法
1.BitFit
BitFit是一种稀疏的微调方法,它训练时只更新bias的参数或者部分bias参数。
对于Transformer模型而言,冻结大部分 transformer-encoder 参数,只更新bias参数跟特定任务的分类层参数。涉及到的bias参数有attention模块中计算query,key,value跟合并多个attention结果时涉及到的bias,MLP层中的bias,Layernormalization层的bias参数。
在Bert-Base/Bert-Large这种模型里,bias参数仅占模型全部参数量的0.08%~0.09%。但是通过在Bert-Large模型上基于GLUE数据集进行了 BitFit、Adapter和Diff-Pruning的效果对比发现,BitFit在参数量远小于Adapter、Diff-Pruning的情况下,效果与Adapter、Diff-Pruning想当,甚至在某些任务上略优于Adapter、Diff-Pruning。
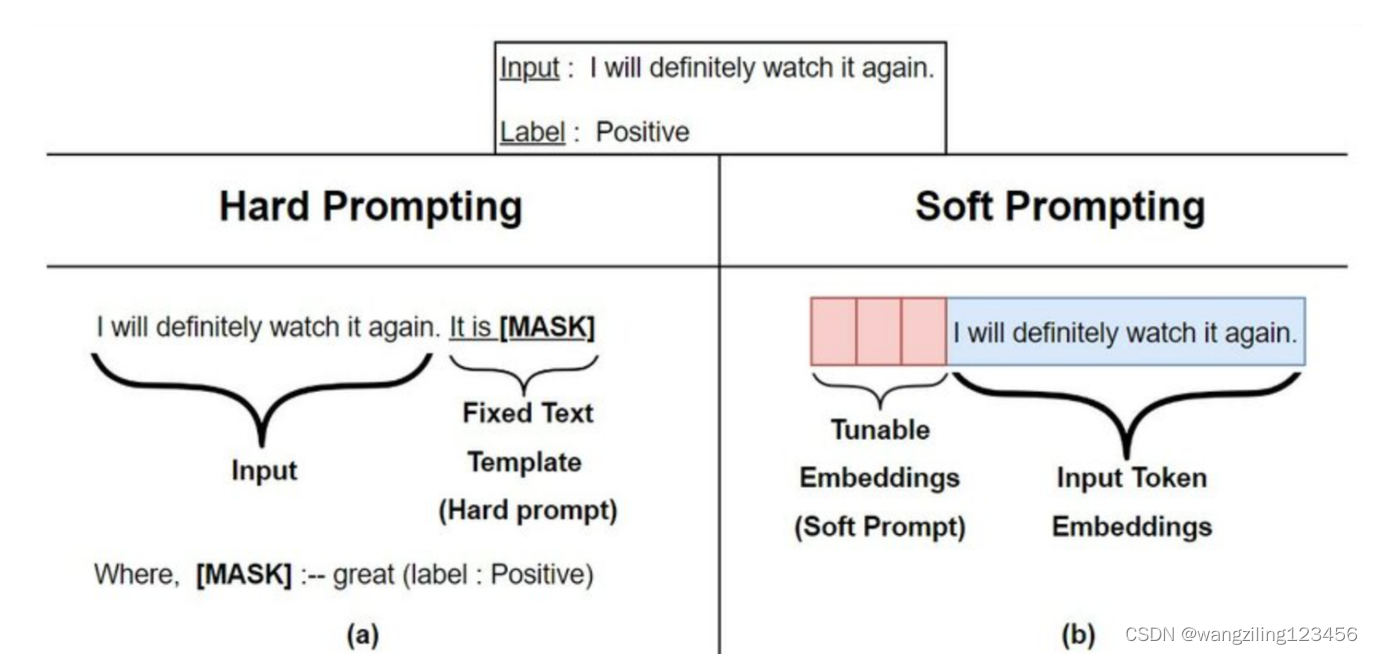
2.Prompt Tuning
Prompt Tuning给每个任务定义了自己的Prompt,然后拼接到数据上作为输入,但只在输入层加入prompt tokens,并且不需要加入 MLP 进行调整来解决难训练的问题。
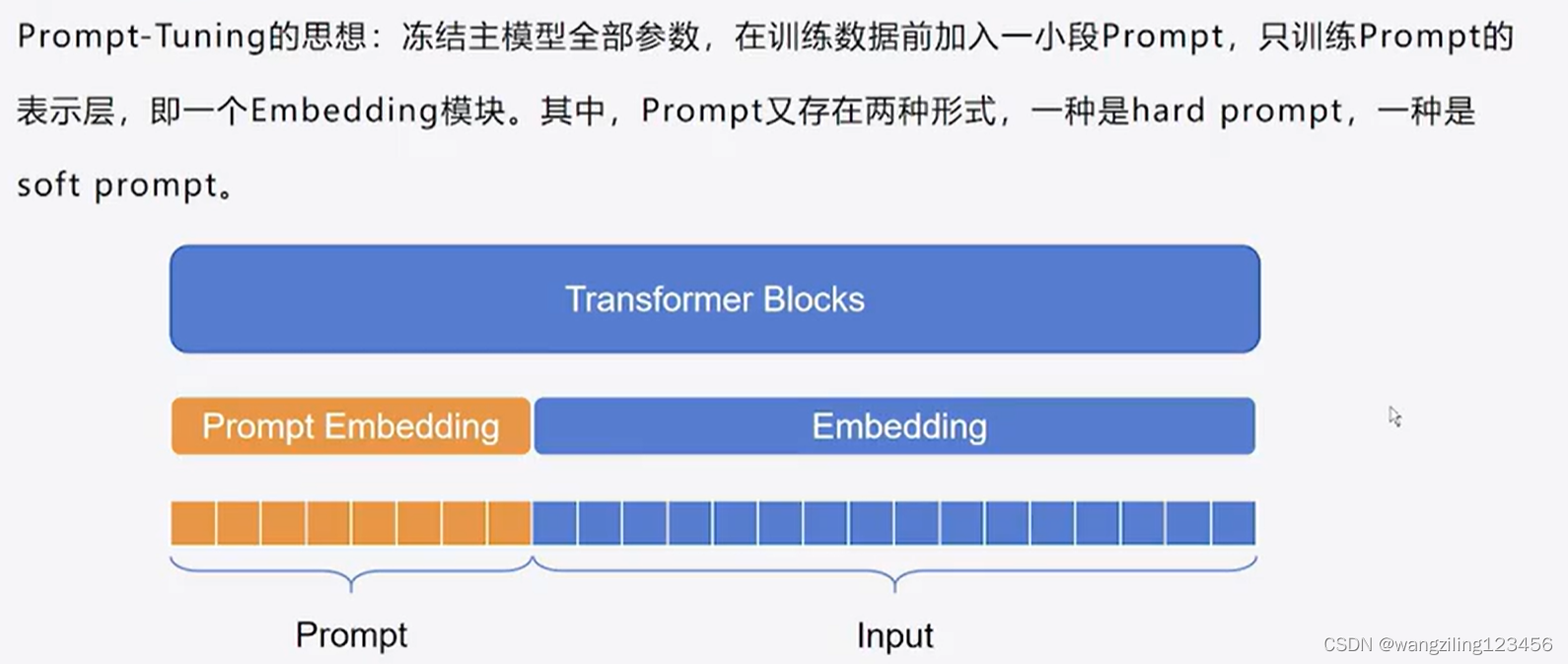
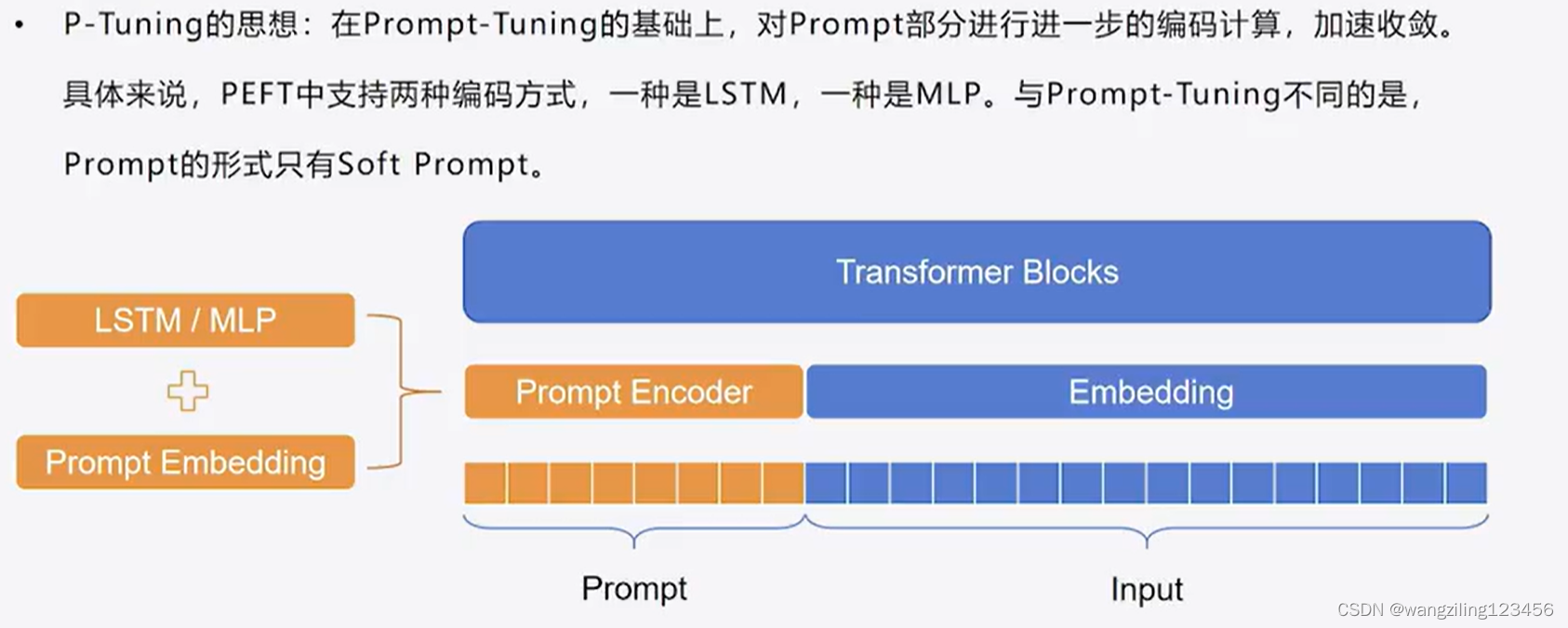
3.P Tuning
4.Prefix Tuning
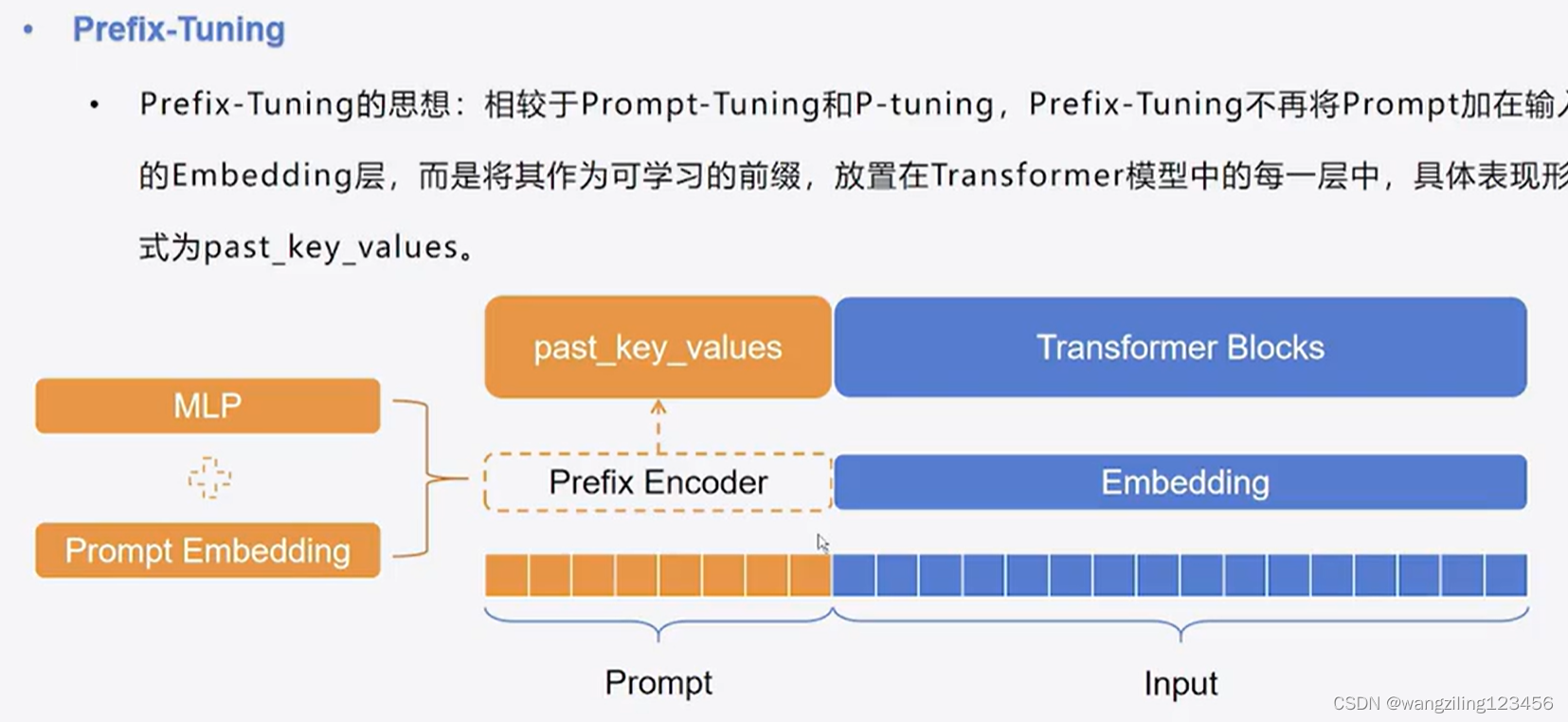
Prefix Tuning 在输入token之前构造一段任务相关的virtual tokens作为Prefix,然后训练的时候只更新Prefix部分的参数,而PLM中的其他部分参数固定。
针对不同的模型结构,需要构造不同的Prefix。
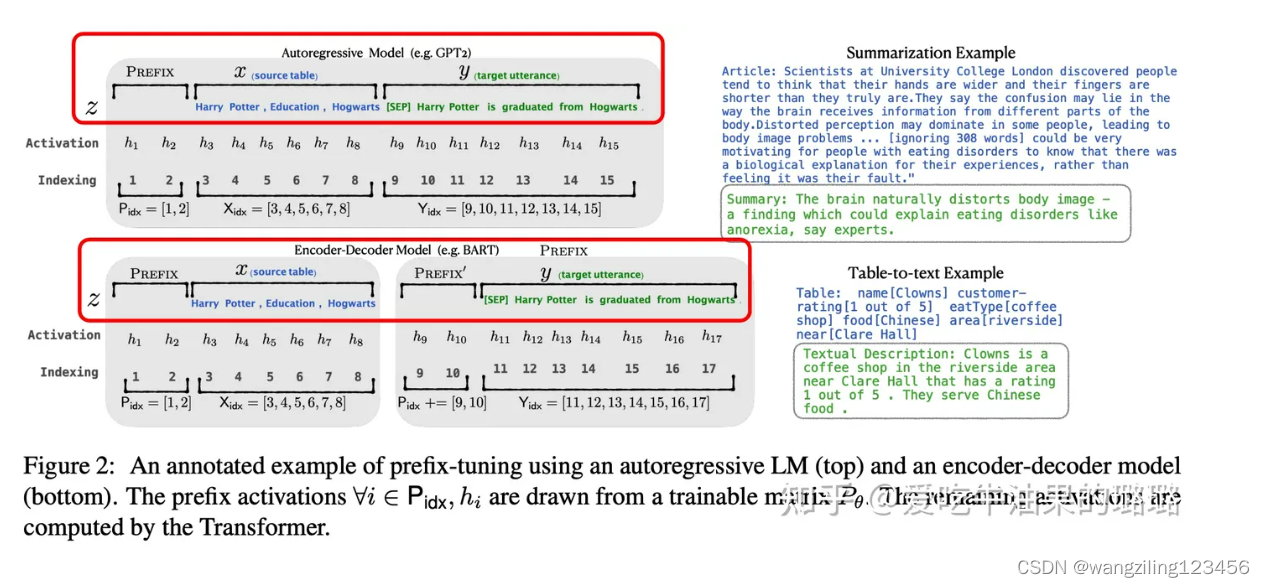
- 针对自回归架构模型:在句子前面添加前缀,得到
z = [PREFIX; x; y],合适的上文能够在固定 LM 的情况下去引导生成下文(比如:GPT3的上下文学习)。 - 针对编码器-解码器架构模型:Encoder和Decoder都增加了前缀,得到
z = [PREFIX; x; PREFIX0; y]。Encoder端增加前缀是为了引导输入部分的编码,Decoder 端增加前缀是为了引导后续token的生成。
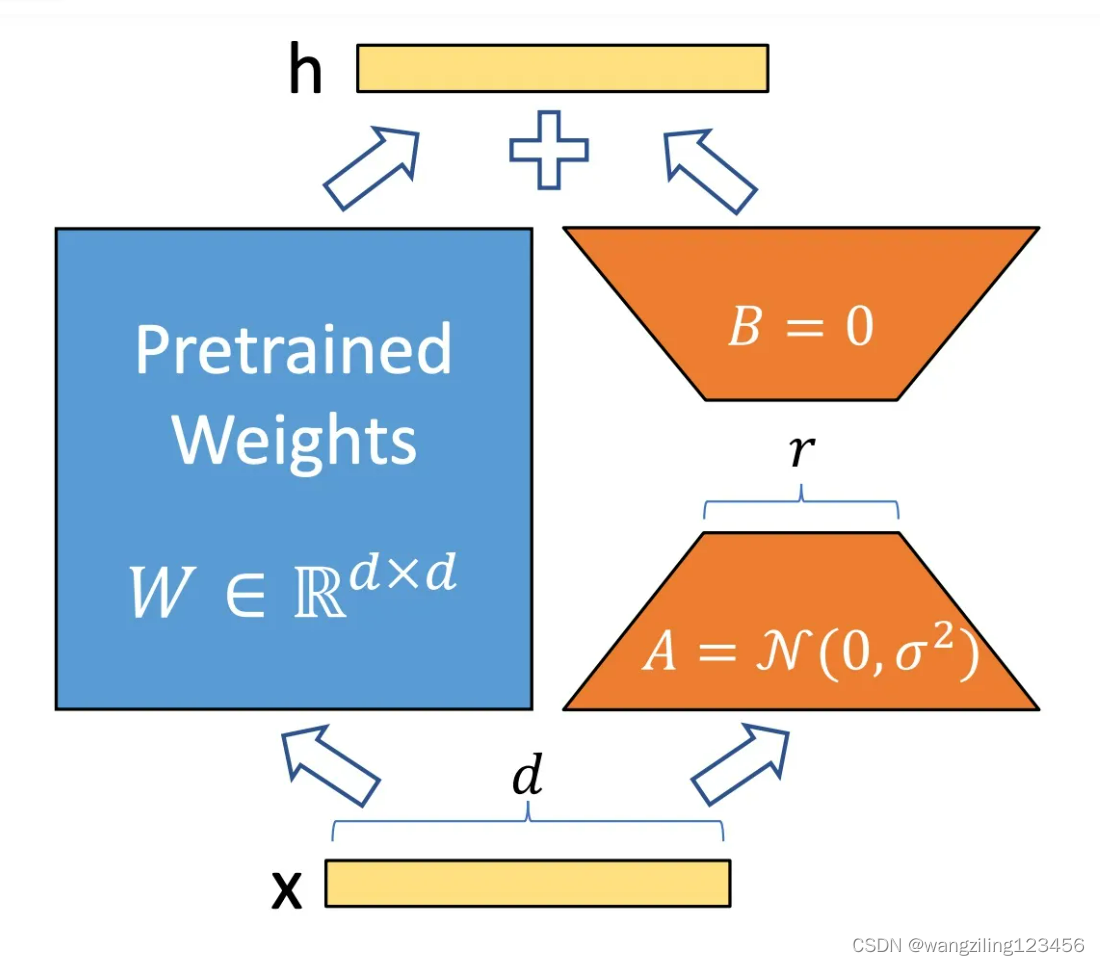
5.LoRA

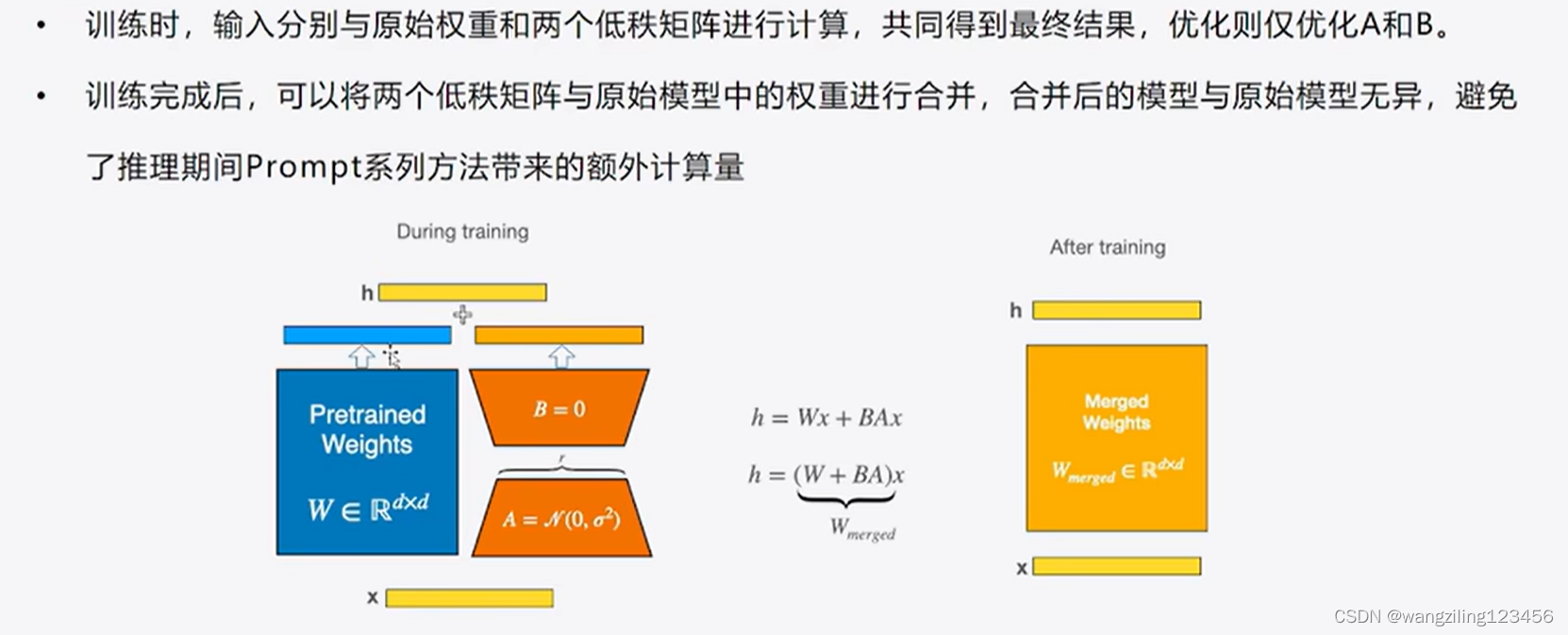
LoRA的核心思想就是通过低秩分解来模拟参数的改变量,从而以极小的参数量来实现大模型的间接训练。
在涉及到矩阵相乘的模块,在原始的PLM旁边增加一个新的通路,通过前后两个矩阵A,B相乘,第一个矩阵A负责降维,第二个矩阵B负责升维,中间层维度为r,从而来模拟所谓的本征秩(intrinsic rank)。
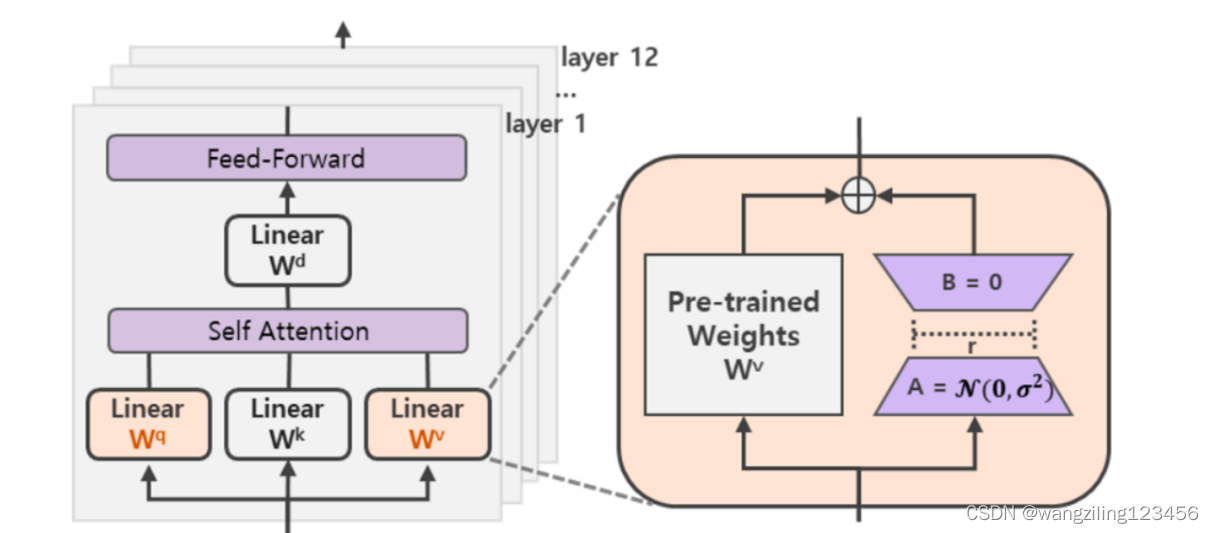
可训练层维度和预训练模型层维度一致为d,先将维度d通过全连接层降维至r,再从r通过全连接层映射回d维度,其中,r<<d,r是矩阵的秩,这样矩阵计算就从d x d变为d x r + r x d,参数量减少很多。



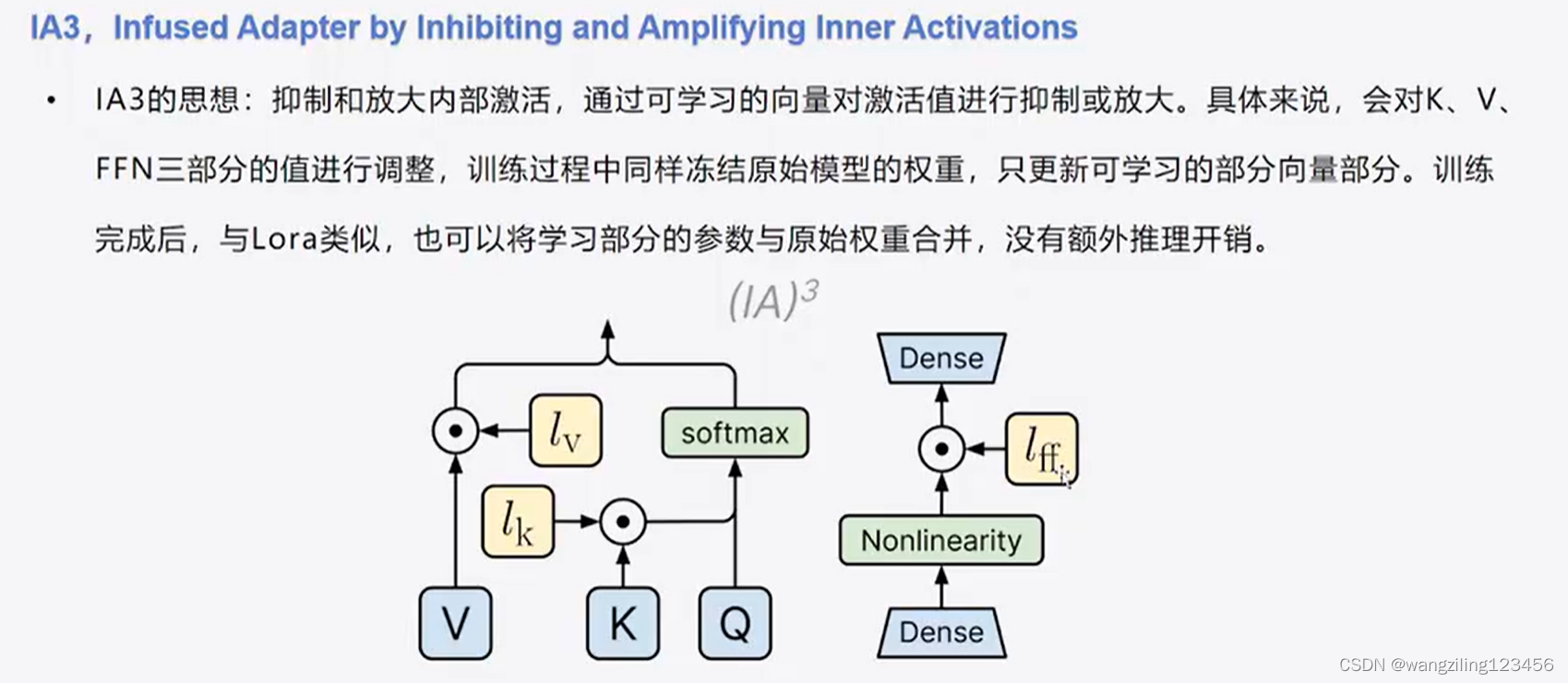
6.IA3
7.Adapter
Adapter方法的思路是用一个较小的神经网络模块插入到模型的不同层, 如下图右侧的Adapter Layer 由两个线性映射层和一个非线性变换层组成,先降维再升维,两个线性映射的可学习参数量比原模型的attention和feed-forward 中的参数少的多。
模型迁移微调的时候,只训练Adapter Layer的相关参数和原始模型中的norm层和最后的分类层。

参考视频
【手把手带你实战HuggingFace Transformers-高效微调篇】参数高效微调与BitFit实战_哔哩哔哩_bilibili
参考文章
大模型炼丹术:大模型微调总结及实现 - 知乎 (zhihu.com)
大模型参数高效微调技术原理综述(一)-背景、参数高效微调简介 - 知乎 (zhihu.com)















 1845
1845

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









