






1.概述
接到了一个数据清理的任务,这里就写一个简单的总结,并且把学习过程和代码记录下来以便复习,也希望能给其他人作为一个简单的参考。
2.文本数据清理
数据清理(Data Cleaning)是数据预处理的一部分,它涉及识别和纠正(或删除)数据集中的错误和不一致性,以提高数据的质量和准确性。
而针对我手头的实际任务更重要的是文本数据的清理。
文本清理(Text Cleaning)是自然语言处理(NLP)和文本分析中的一个重要步骤,它涉及从文本数据中去除或修正不需要的信息,以便进行更有效的分析。文本清理的目标是提高文本数据的质量,使其更适合于后续的文本挖掘、机器学习或其他处理任务。
3.具体任务
我拿到的文件格式为xlsx,所以优先选择用Excel打开观察一下数据。
3.1铁矿石文档
3.1.1短信
内容示例:
4月15日市场消息:滦州A矿山于12:00-12:30进行招标,66%酸粉拦标价1042,招标量为10000吨,后期Mysteel国产矿团队将持续跟踪。(干基含税现汇出厂价;单位:元/吨)
4月15日 矿山调价:安徽金日晟矿业铁精粉价格涨64,65%造球精粉1002。(干基含税出厂价;单位:元/吨) 
4月7日可门港进口铁矿价格全天累计跌6。市场交投情绪较为冷清,成交几无。现PB粉783跌6,巴混(BRBF)797跌6。(对比前一工作日晚间价格;单位:元/湿吨)
2月9日青岛港进口铁矿盘中价格持跌运行,累计下跌20-30。现PB粉925-930,卡粉1140-1150,超特粉590-600。(对比前一工作日晚间价格;单位:元/湿吨 )
26日邯邢铁精粉市场价暂稳。现邯邢局66%碱668,武安64%碱540;沙河64%碱540。
数据分析:
共119999条数据,长度都很短。标签绝大多数为铁矿石
整体来看数据很干净,符合要求,但是出现了“ ”这样的字符。
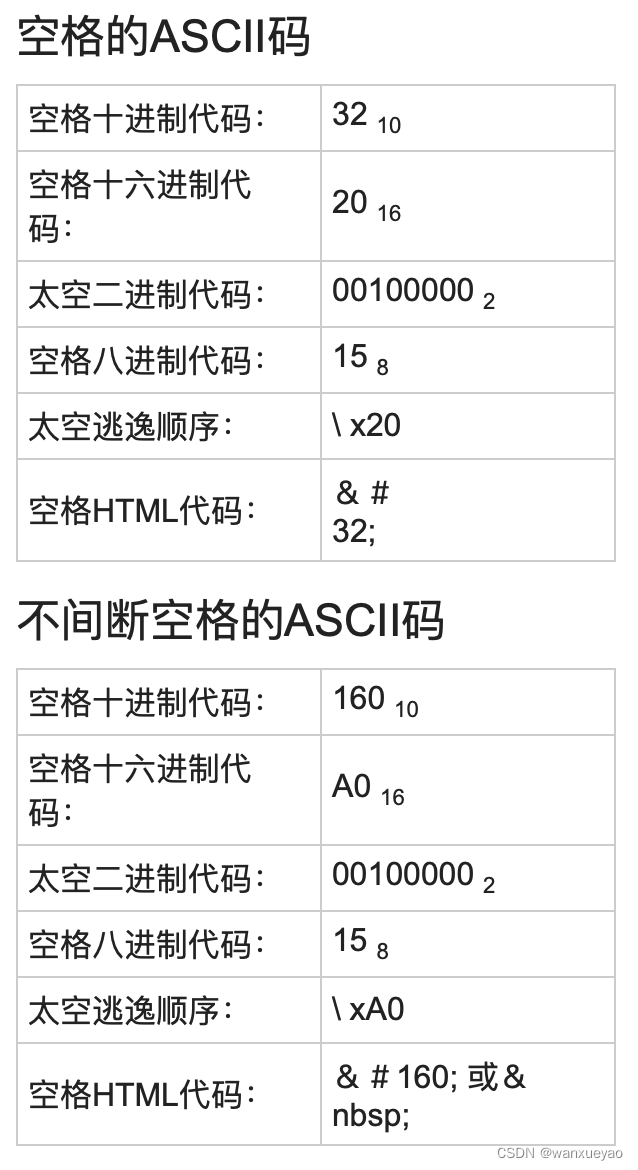
“不换行空格(Non-Breaking Space,又称硬空格,ASCII 160)和(普通空格,ASCII 32)都是用于表示空白的字符”。
在网上找到了这样的资料。
处理方法:
可以直接在Excel中使用查找替换工具消除。
处理结果:
检索时还找到了 ;。
1日15:00曹妃甸港进口铁矿午后价格涨5-20。现PB粉1495-1500,纽曼筛后块1880-1885,卡粉1750-1760,超特粉1045-1050,混合粉1238-1243。(对比前一工作日17:30价格;单位:元/湿吨 )
替换后没有发现问题。
3.1.2快讯
内容示例:
【黑色持仓日报:铁矿石涨2.18%,乾坤期货增持超3千手多单】截至4月15日收盘,螺纹钢2410收3616元/吨,跌0.03%;热卷2410收3780元/吨,涨0.32%;铁矿石2409收845.5元/吨,涨2.18%。
3月17日岚山港进口铁矿价格全天累计上涨9-14。市场交投情绪较为冷清,成交寥寥。现PB粉922涨9,超特粉794涨14,麦克粉912涨9,扬迪粉884涨9。(对比前一工作日晚间价格;单位:元/湿吨)
29日唐山国产矿市场弱势运行,66%酸粉价格:迁安大矿报价860-870,选厂参考价820-830,小幅趋弱5-10;遵化参考价830-840;迁西参考价830-840;69%酸粉参考价:遵化930-940(湿基不含税现汇出厂价;单位:元/吨 )。
部分地区受政策影响,矿选企业有停产现象,市场资源略显紧张,但由于近期精粉价格持续下滑,导致部分精选厂对后市持悲观心态,对粗粉需求偏弱,市场交投清淡;钢厂维持按需采购,对市场持观望心态,采货谨慎,供需两弱状态下,成交显僵持。
26日河北部分区域铁精粉价格暂稳。66%迁安1244;66%遵化1234;65%承德1100;64%武安1151;66%五矿邯邢1263;64%沙河1159.
数据分析:
总计51266条数据,标签较为复杂。完全符合要求,无须处理。
3.1.3文章
内容示例:
<p style="margin: 0cm 0cm 6pt; text-align: justify;">德国最大的钢铁制造商Thyssenkrupp计划每年削减其位于<span style="color: #444444; background: white;">North Rhine-Westphalia</span>州<span style="color: #444444; background: white;"> Duisbu</span><span style="color: #444444; background: white;">rg</span><span style="color: #444444; background: white;">工厂约</span><span style="color: #444444; background: white;">20%</span><span style="color: #444444; background: white;">的钢铁产量(约</span>150—200万吨),以应对欧洲市场需求疲软以及产能过剩问题。</p>
<p style="margin: 0cm 0cm 6pt; text-align: justify;">目前,<span style="color: #444444; background: white;">Duisbu</span><span style="color: #444444; background: white;">rg</span>工厂的四座高炉的生铁年产能约为1170万吨,粗钢年产能约为1100万吨。</p>
<p><img style="width: 600px; height: 1000px;" src="/wz/uploaded/steel/2024/04/15/031ec5ac6ed94cdda23d592207248862.jpg" width="600" height="1000" /></p>
数据分析:
总计30540条数据,标签较为复杂,但也有相当数量单纯只是“铁矿石”。
看起来像是网页爬取,文本质量很差。
处理方法:
从网页得到的数据通常包含了大量html实体比如< >: &,嵌入在原始数据中。必须去掉这些实体。一种方法是用具体的正则表达式直接删除。
import re
pattern = re.compile(r'<[^>]+>',re.S)
result = pattern.sub('', html)
print(result)另一种方法是用适当的包和模块(比如Python的htmlparser),可以将这些实体转换成标准的html标签。
from bs4 import BeautifulSoup
soup = BeautifulSoup(html,'html.parser')
print(soup.get_text())或者
from lxml import etree
response = etree.HTML(text=html)
print(response.xpath('string(.)'))处理结果:
正则化
德国最大的钢铁制造商Thyssenkrupp计划每年削减其位于North Rhine-Westphalia州 Duisburg工厂约20%的钢铁产量(约150—200万吨),以应对欧洲市场需求疲软以及产能过剩问题。 目前,Duisburg工厂的四座高炉的生铁年产能约为1170万吨,粗钢年产能约为1100万吨。
转换html标签
德国最大的钢铁制造商Thyssenkrupp计划每年削减其位于North Rhine-Westphalia州 Duisburg工厂约20%的钢铁产量(约150—200万吨),以应对欧洲市场需求疲软以及产能过剩问题。 目前,Duisburg工厂的四座高炉的生铁年产能约为1170万吨,粗钢年产能约为1100万吨。
显然后者的效果要好一些。
3.2原油
3.2.1短信
内容示例:
31日WTI 原油期货涨1.48,报68.21美元/桶;布伦特原油期货涨2.11,报77.5美元/桶。
美元汇率下降提振原油市场,国际油价反弹。27日,WTI:46.23,涨1.08;布伦特:49.60涨1.44
数据分析:
共计936条数据,标签均为原油。文本数据很干净,无须清理,不过数量确实相当少。
3.2.2快讯
内容示例:
国内商品期货多数收跌,沪锡、郑棉、橡胶、棉纱、液化天然气跌逾3%,尿素、沥青、玉米、原油、花生跌逾2%;生猪、纯碱、硅铁、线材涨逾2%,螺纹、郑煤、热卷涨逾1%。
【陕西省工业领域碳达峰实施方案】到2025年,短流程炼钢占比稳步提高;“减油增化”取得积极进展,新建炼化一体化项目成品油产量占原油加工量比例下降至40%以下;水泥熟料单位产品综合能耗水平下降3%以上。到2030年,短流程炼钢占比达20%以上,在水泥、玻璃、陶瓷等行业建设一批减污降碳绿色低碳生产线。
中交一航局第二工程有限公司现就茂名港博贺新港区30万吨级原油码头工程项目木方、竹胶板的采购事宜进行公开招标,预计木方总用量约为:101方,竹胶板总用量约为:3926平方米,截止时间为2024年3月12日17时。(百年建筑)
数据分析:
数据总共440条,标签较为复杂。数据很干净,同上。
3.2.3文章
内容示例:
<p style="text-align: center;"><span style="font-size: 16px">4月11日山东市场进口原油价格行情</span></p><p><span style="font-size: 16px"></span></p><table width="100%" width="99%"><tbody><tr style=";height:37px" class="firstRow"><td width="13" style="border-top: none; border-left: 1px solid white; border-bottom: 2px solid white; border-right: 1px solid white; background: rgb(2, 57, 133); padding: 0px 7px;"><p style="text-align:center"><span style="font-size: 16px;font-family: 宋体, SimSun;color:white">原油品种</span></p></td><td width="22" style="border-top: none; border-left: none; border-bottom: 2px solid white; border-right: 1px solid white; background: rgb(2, 57, 133); padding: 0px 7px;"><p style="text-align:center"><span style="font-size: 16px;font-family: 宋体, SimSun;color:white">美金到价</span></p></td><td width="8" style="border-top: none; border-left: none; border-bottom: 2px solid white; border-right: 1px solid white; background: rgb(2, 57, 133); padding: 0px 7px;"><p style="text-align:center"><span style="font-size: 16px;font-family: 宋体, SimSun;color:white">涨跌</span></p></td><td width="22" style="border-top: none; border-left: none; border-bottom: 2px solid white; border-right: 1px solid white; background: rgb(2, 57, 133); padding: 0px 7px;"><p style="text-align:center"><span style="font-size: 16px;font-family: 宋体, SimSun;color:white">人民币到岸价</span></p></td><td width="15" style="border-top: none; border-left: none; border-bottom: 2px solid white; border-right: 1px solid white; background: rgb(2, 57, 133); padding: 0px 7px;"><p style="text-align:center"><span style="font-size: 16px;font-family: 宋体, SimSun;color:white">涨跌</span></p></td><td width="17" style="border-top: none; border-left: none; border-bottom: 2px solid white; border-right: 1px solid white; background: rgb(2, 57, 133); padding: 0px 7px;"><p style="text-align:center"><span style="font-size: 16px;font-family: 宋体, SimSun;color:white">备注</span></p></td></tr><tr style=";height:21px"><td width="13" style="border-right: 1px solid white; border-bottom: 1px solid white; border-left: 1px solid white; border-image: initial; border-top: none; padding: 0px 7px;"><p style="text-align:center"><span style="font-size: 16px;">ESPO</span></p></td><td width="22" style="border-top: none; border-left: none; border-bottom: 1px solid white; border-right: 1px solid white; padding: 0px 7px;"><p style="text-align:center">89.64</p></td><td width="8" style="border-top: none; border-left: none; border-bottom: 1px solid white; border-right: 1px solid white; padding: 0px 7px;"><p style="text-align:center">-0.64</p></td><td width="22" style="border-top: none; border-left: none; border-bottom: 1px solid white; border-right: 1px solid white; padding: 0px 7px;"><p style="text-align:center">5424.94</p></td><td width="15" style="border-top: none; border-left: none; border-bottom: 1px solid white; border-right: 1px solid white; padding: 0px 7px;"><p style="text-align:center">-36.39</p></td><td width="17" style="border-top: none; border-left: none; border-bottom: 1px solid white; border-right: 1px solid white; padding: 0px 7px;"><br/></td></tr></tbody></table><p>备注:</p><p>1、此列表中美金到岸价及升贴水单位为美元/桶,人民币到岸价单位为元/吨;<br/></p><p>2、发布时间为工作日10:00前。</p><p><br/></p>
数据分析:
总计19680条数据,标签较为复杂。下同“3.1.3文章”一小节。
3.2.4报告
内容示例:
//mfs.***cdn.com/group1/M00/B2/F0/rBL64GYc1SuAXtfUAOokzOGF5ec901.pdf
<p>PVC周评:</p>
<p>本周期货市场主力09合约表现为反弹态势,周一开盘价为5905元/吨,周五收盘价为5967元/吨,周涨幅为1.05%。</p>
<p>供应端来看,4月PVC生产企业新增检修产能274万吨左右,占国内产能的10%左右,同比下降,将对供给减压有所贡献。本周样本企业产能利用率为74.10%,环比减少3.75百分点;电石法企业产量32.40万吨,环比减少4.34%;乙烯法企业产量9.71万吨,环比减少6.86%;本周检修规模持续扩大,产量输出持续下降,下周预计降幅将有所收敛。</p>
<p>需求端来看,型管材开工率较清明节前难有提升,持续低迷;出口绝对量小幅提升,预计5月台塑报价将有所下调。</p>
<p>成本上来看,电石成本支撑受供给高位持续影响走弱;乙烯法成本跟随原油震荡走强,继续亏损;双吨价差低位震荡,未来排产继续承压。总体成本支撑持稳。</p>
<p>库存上来看,企业库存为39.73万吨,环比减少3.37%;电石法厂库为29.00万吨,环比减少4.62%;乙烯法厂库为10.73万吨,环比增加0.19%;社会库存为60.25万吨,环比增加0.02%;生产厂家库存可用天数为6.50天,环比减少5.11%。生产端持续加速去库,社会库存微幅增加,总体库存水平小幅降。</p>
<p>预计下周成本支撑走稳,供给持续减弱,需求未有明显起色,仍将偏多震荡调整为主。</p>
<p><br></p>
数据分析:
总计18101条数据,标签较为复杂。内容格式也并不统一,大部分为网址,网址内是一个pdf文件。还有少量样本为网页爬取文字,处理方法同“3.1.3文章”一小节。
处理方法:
先将数据分成两类。
对于url格式的样本。批量从url下载pdf并按顺序命名,将pdf转成txt,根据txt文件建立csv文件。
首先安装pdfplumber库
pip install pdfplumber然后使用下述脚本
import os
import pdfplumber
# 源文件夹路径
source_folder = "/Users/xueyaowan/Documents/HIT-AI小组/数据清洗/pdf"
# 目标文件夹路径,用于保存TXT文件
target_folder = "/Users/xueyaowan/Documents/HIT-AI小组/数据清洗/txt_exports"
# 如果目标文件夹不存在,则创建它
if not os.path.exists(target_folder):
os.makedirs(target_folder)
# 遍历源文件夹中的所有文件
for filename in os.listdir(source_folder):
if filename.endswith(".pdf"):
# 构建完整的文件路径
file_path = os.path.join(source_folder, filename)
# 使用pdfplumber打开PDF文件
with pdfplumber.open(file_path) as pdf:
# 初始化一个空字符串来保存文本内容
text = ""
# 遍历PDF中的每一页
for page in pdf.pages:
# 提取页面的文本并添加到text变量中
text += page.extract_text()
text += "\n\n" # 添加换行符以分隔不同页面的内容
# 构建目标TXT文件的路径,文件名保持不变,只是扩展名改为.txt
txt_file_path = os.path.join(target_folder, filename.replace(".pdf", ".txt"))
# 将文本内容写入TXT文件
with open(txt_file_path, "w", encoding="utf-8") as txt_file:
txt_file.write(text)
print(f"已转换文件: {filename} -> {txt_file_path}")处理结果:
【中钢期货】黑色产业链周报
中钢期货
2024.4.15
目录
01 周度行情回顾
02 本周黑色行情预判
03 品种数据(成材、铁矿石、煤焦、废钢、铁合金)
01 周度行情回顾
02 本周黑色行情预判
成材:库存降需求升 成材重心在整理中上移
Ø 逻辑:上周,247家钢厂高炉开工率78.41%,环比增加0.60个百分点,同比减少6.33个百分点;高炉炼铁产能利用率
84.05%,环比增加0.44个百分点,同比减少7.75个百分点;钢厂盈利率38.1,环比增加4.77个百分点,同比减少9.52个
百分点。上周,全国87家独立电弧炉钢厂平均开工率66.84%,环比减少2.09个百分点,同比减少9.76个百分点;平均
产能利用率50.55%,环比减少1.53个百分点,同比减少13.40个百分点。成材上周上涨,对之前一周的跌幅进行修复。
成材走势出现一定变化,一是宏观面和市场环境偏暖,受外围经济数据良好推动,有色和原油板块近期上涨,对黑色板
块有带动;二是成材库存持续下降,需求较3月份有回升,供需结构有好转。我们认为成材4月初的底就是阶段性底部,
后面走势或有反复,但大幅下跌空间不大,后期以震荡中重心上移为主。
Ø 观点:关注下游需求变化,逢低偏多对待。
Ø 后期关注/市场风险:关注宏观政策、下游需求变化。
4.实现方法
上面针对各种不同的数据都分别进行了处理,下面是具体如何批量化完成各部分文本数据清理的代码。
4.1任务分解
希望输出3+5共8个csv文件,包括铁矿石-短信;快讯;文章;原油-短信;快讯;文章;报告1(pdf/csv),报告2(文本)
铁矿石-文章:需要列合并以及去html
原油-文章:需要去html
原油-报告:需要拆分,报告1为pdf的url链接,报告2需要去html
首先需要一个批量下载pdf的程序,并且对pdf文件重命名。
然后,对于pdf文件有两种处理方式——直接输入大模型;转成文本再输入大模型
因为pdf文件的特殊性(多种格式,甚至可能是单纯的图像文件),转成文本后的格式并不工整,不过对于分类任务也应该够用
4.2测试
主要需要实现两个功能——批量去除html和批量下载pdf
4.2.1去除html
from bs4 import BeautifulSoup
import pandas as pd
test1 = pd.read_excel(io='/Users/xueyaowan/Desktop/test1.xlsx')
print(test1.text)
for i in range(test1.text.shape[0]):
trash = test1.text[i]
soup = BeautifulSoup(trash,'html.parser')
test1.text[i] = soup.get_text(strip=True)
print(test1.text)执行以后发现会出现空数据,于是还要加一步抹除缺省值。但是直接用dropna()并不奏效,检测一下发现是空白的str类型。于是使用替换将空白的str变成NaN。
data.text.replace('', np.nan, inplace=True)4.2.2下载pdf
因为pdf转文字已经在“3.2.4报告”小节解决了,这里还要解决pdf下载以及组合成一个完整的csv文件。因为数量过大,没法在电脑上直接进行,所以最后只给出可实现的程序。
import urllib.request
import re
import os
import pandas as pd
def getHtml(url):
page = urllib.request.urlopen(url)
html = page.read()
page.close()
return html
def getFile(url):
file_name = url.split('/')[-1]
try:
u = urllib.request.urlopen(url)
except urllib.error.HTTPError:
print(url, "url file not found")
return
block_sz = 8192
with open(file_name, 'wb') as f:
while True:
buffer = u.read(block_sz)
if buffer:
f.write(buffer)
else:
break
print("Sucessful to download" + " " + file_name)
root_url = 'https:'
if not os.path.exists('pdf_download'):
os.mkdir('pdf_download')
os.chdir(os.path.join(os.getcwd(), 'pdf_download'))
data = pd.read_csv(r'/Users/xueyaowan/Desktop/test2.csv')
for i in range(data.url.shape[0]):
dl = data.url[i]
dl = root_url + str(dl)
getFile(dl)
print("下载完啦!")4.3整体实现
4.3.1程序1
import pandas as pd
import numpy as np
from bs4 import BeautifulSoup
data = pd.read_csv(r'/Users/xueyaowan/Desktop/原油-报告text.csv')
for i in range(data.text.shape[0]):
trash = data.text[i]
soup = BeautifulSoup(trash,'html.parser')
data.text[i] = soup.get_text(strip=True)
data.text.replace('', np.nan, inplace=True)
data.dropna(inplace=True)
print(data)
data.to_csv('cleandata.csv',index=False)但是在对“铁矿石-文章”进行这样处理时遇到了诸多问题。
输入到trash里的并不全是str类型,有float,这就导致BeautifulSoup报错。
TypeError: object of type 'NoneType' has no len()于是用str()强制转变类型,就找到了罪魁祸首。是如下样式的数据。
<p>1</p>
另外还有处理后依旧无法理解的文本。
日期BDIBaltic Dry IndexBCIBaltic Capesize IndexBPIBaltic Panamax IndeBSIBaltic Supramax Index2010年7月14日17091653198017172010年7月13日17901839194617602010年7月12日18401949194117892010年7月9日19022102194418172010年7月8日1940215919851843<tr style="FONT-SIZE: 12px" removechild="function MyRC(arg1){var self = this;if (self.removeAttribute)self.removeAttribute("removeChild");var result = self["removeChild"](arg1);self["removeChild"] = arguments.callee; /*Finally restore the Over
经过观察发现这应该是一个表格。
于是尝试用另一种方式。
import pandas as pd
import numpy as np
from lxml import etree
data = pd.read_csv(r'/Users/xueyaowan/Desktop/铁矿石-文章.csv')
for i in range(data.text.shape[0]):
trash = str(data.text[i])
response = etree.HTML(text=trash)
data.text[i] = response.xpath('string(.)')
data.text.replace('', np.nan, inplace=True)
data.dropna(inplace=True)
print(data)
data.to_csv('cleandata.csv',index=False)得到的结果还需要再进行一次处理,包含空数据,一行只有1,以及\n。

依旧使用替换
cleandata.text.replace('1', np.nan, inplace=True)
cleandata.dropna(inplace=True)
cleandata.text.apply(lambda x:x.replace('\n', ''))
print(cleandata)
cleandata.to_csv('puredata.csv',index=False)4.3.2程序2
在完成“3.2.4报告”小节和“4.2.2下载pdf”两小节后,终于可以编写一个能完成任务的程序了。
首先回顾任务目标,最后生成一个csv文件,替换带标签的url为其对应的文字。
import pdfplumber
import os
import pandas as pd
data = pd.read_csv(r'/Users/xueyaowan/Desktop/test2.csv')
source_folder = "/Users/xueyaowan/Documents/AIGC/workspace/pdf_download"
num = 0
for filename in os.listdir(source_folder):
if filename.endswith(".pdf"):
num += 1
for i in range(num):
file_path = os.path.join(source_folder, str(i)+'.pdf')
with pdfplumber.open(file_path) as pdf:
content = ""
for page in pdf.pages:
content += page.extract_text()
content += "\n\n"
data.url[i] = str(content)
print("Sucessful to transfer" + " " + str(i)+'.pdf')
textdata = data.rename(columns={"url":"text"})
print(textdata)
textdata.to_csv('textdata.csv',index=False)最后使用test2.csv(包含前10条数据)测试结果如下

5.结果
最后获得2个干净的xlsx文件——训练语料-铁矿石,训练语料-原油
6个csv文件
铁矿石-短信;快讯;文章;
原油-短信;快讯;文章;报告text
一个包含所有pdf下载源url及其标签的csv文件
一个可批量下载pdf以及批量转换成文字,并生成csv文件的python程序


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









