







Paper Reading Note
相关链接:
论文URL
论文Github
作者项目介绍
full resolution pdf
TL;DR
人类往往在认知一件事物时,由于生物功能信息上的局限性,我们往往只能够看到局部信息。人类会根据自己的经验结合这些信息形成对这个物体的整体上认知。
本文介绍的COnditional COordinate GAN从这点上得到启发,将真实图像进行切分,对每一小块坐标对应的图像进行训练,并将位置信息作为条件作为Conditional辅助GAN的训练,最终能够通过拼接生成比训练数据更大的假图像,并且在生成质量上也做到了SOTA。
Model
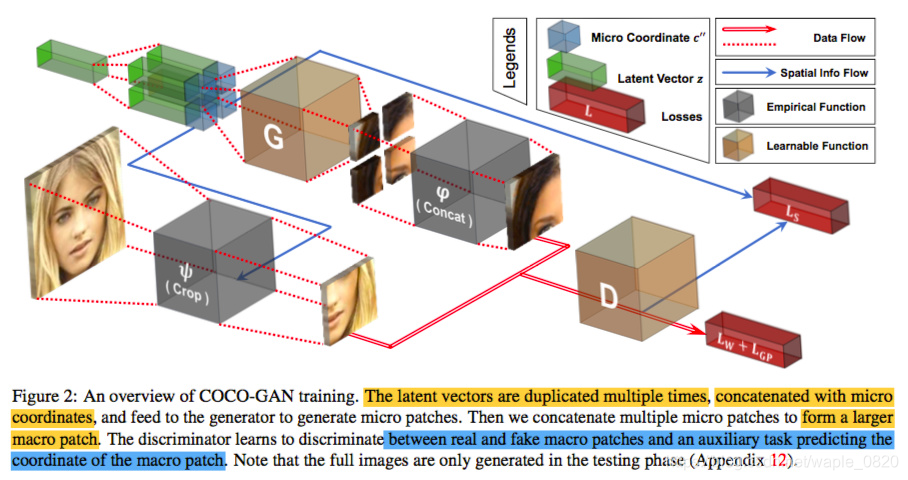
采用的是conditionalGAN作为模型框架:
- 将位置信息作为condition加入到latent distribution中。
- 将生成的小块图像与经过crop的图像训练判别器的true/fake分类。
- 位置信息训练判别器的位置分类器。
- 为了能轻连续小块之间缝隙的问题,作者将生成器生成的小块图像进行对应位置的拼接,使判别器能够学习到位置之间的相关性。
最后的损失函数也很好理解:
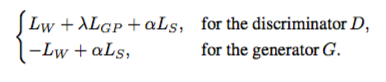
L_w是对抗损失,这里用的是WGAN-gp,所以在判别器中还有梯度惩罚:L_GP,L_s是位置信息的准确性损失。
L_s采用了Conditional GAN的损失。与一般的CGAN不同的是,一般的CGAN都是分类问题,最后的损失函数都是交叉熵等。这里由于位置信息的连续性关系,作者采用了L2损失:
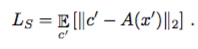
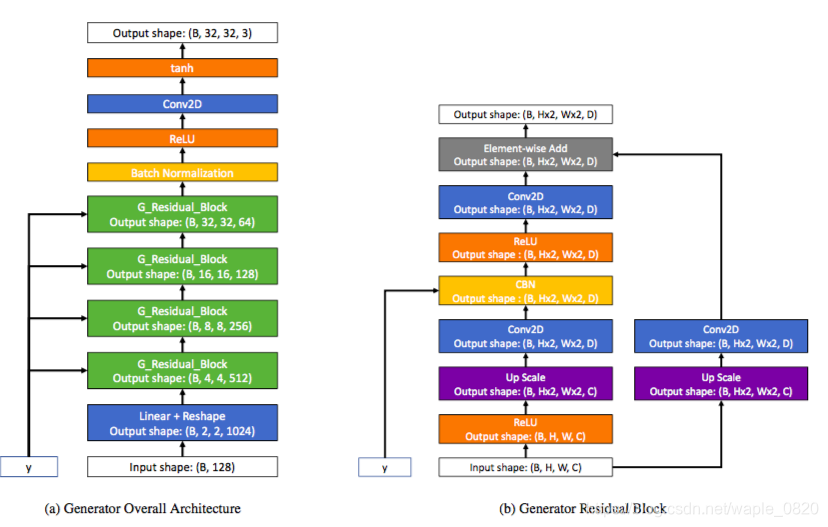
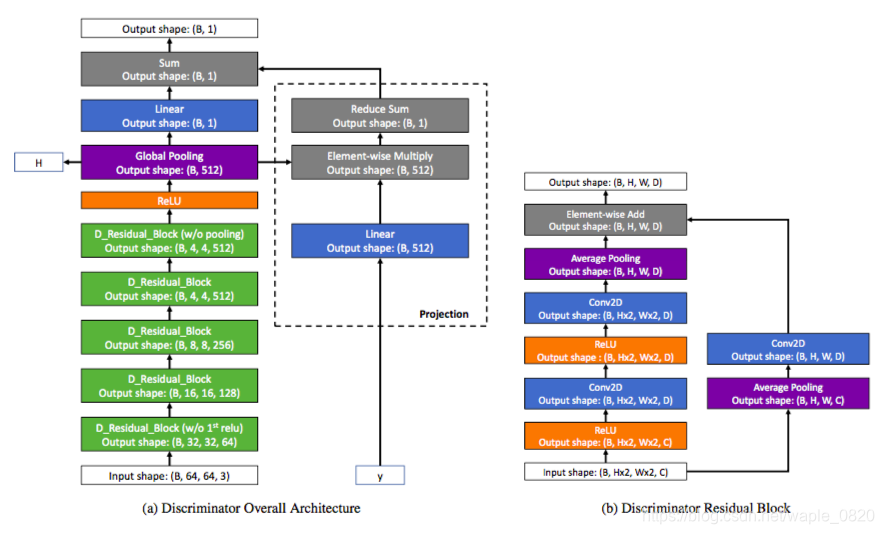
生成器网络
判别器网络
Experiment
生成图像过程
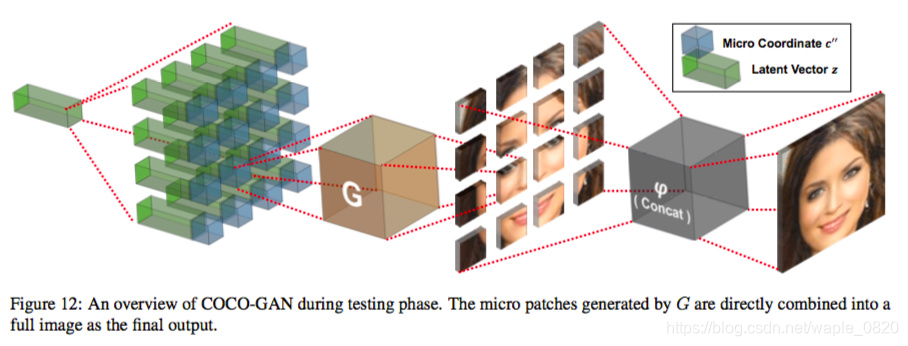
使用一个latent distribution能够在训好的生成器上通过位置信息生成每一个小块的图像,然后通过简单的基于位置的拼接操作即可得到整个图像。
模型结果
选取不同的full-macro-micro比例图像得到的实验结果

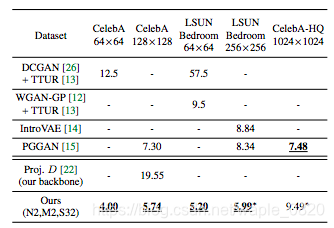
在FID评价指标上也超过了部分SOTA方法。
特征表示向量的选取
作者首先分析了latent distribution不同取值的影响。这里的latent distribution的取法是通过随机取两个vector,然后用弧插值的方法计算出一个中间值,不同取值得到的结果:

小块引导的图像生成 (※)
本文最有意思的一个工作:通过另一个网络预测该patch对应大图的latent vector(有点粗暴),然后通过同样的网络生成整个图像:
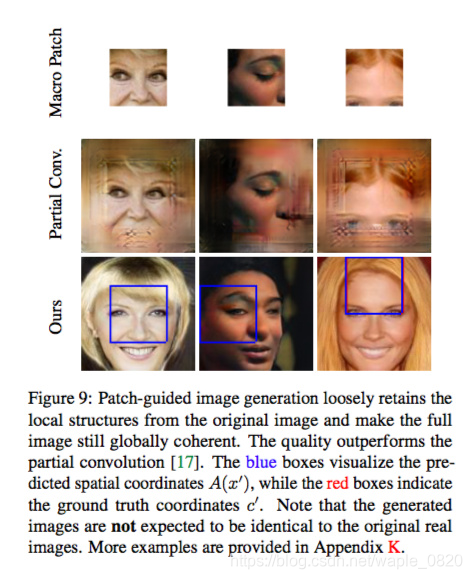
这种方法相对于其他任务的一个比较好的点在于不依赖于生成部分周围的信息,单纯依靠位置预测latent distribution,如果这个模型训得很好,那么相同的网络就可以还原出一整幅逼真的图像。
更多使用该方法的结果:

Thoughts
这篇文章的核心模型十分简单容易理解。但脑洞开的很大,能够从patch图像去生成整体的图像这点不太好想到,作者提供的这套解决方法很有说服力,最关键的是提供了分小块去做GAN这种方法。这种思路这篇文章让我觉得GAN不仅能够做简单的数据增强,在super resolution,image inpainting等任务上也可以用类似的想法去做。















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









