






automa,我承认我写不出来这样的代码,早年的时候公司想过做一个爬虫的工具,那个时候RPA还没有火,虽然下载也没怎么火.RPA再牛,还是需要工程师,想一点经验都没有人来做,还是理解不了。能够简化数据采集,却不能替换工程师。
1 循环数据问题
如果我想采集的数据,告诉我每页有多少条记录,或者有多少分页,就很容易了。
它这个里面循环数据的选项,除了变量,其他的都无法实现非固定值的分页。
但实际并不是我所想的那样使用。取元素的数量好办,通过js就可以得到
// 得到目录数量
const dir_cn = document.querySelectorAll('.file-list-item').length
automaSetVariable('dir_cn', dir_cn)
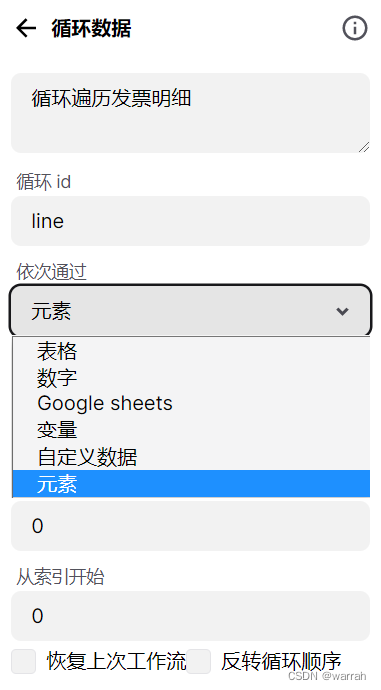
得到了数量如何循环呢?先调整思路,从循环元素着手,官方有个示例Extract All Instagram Profile Posts
指定要循环的元素,这里要循环的最大数据,就需要设置了,默认为0,这样循环就可以自动进行。
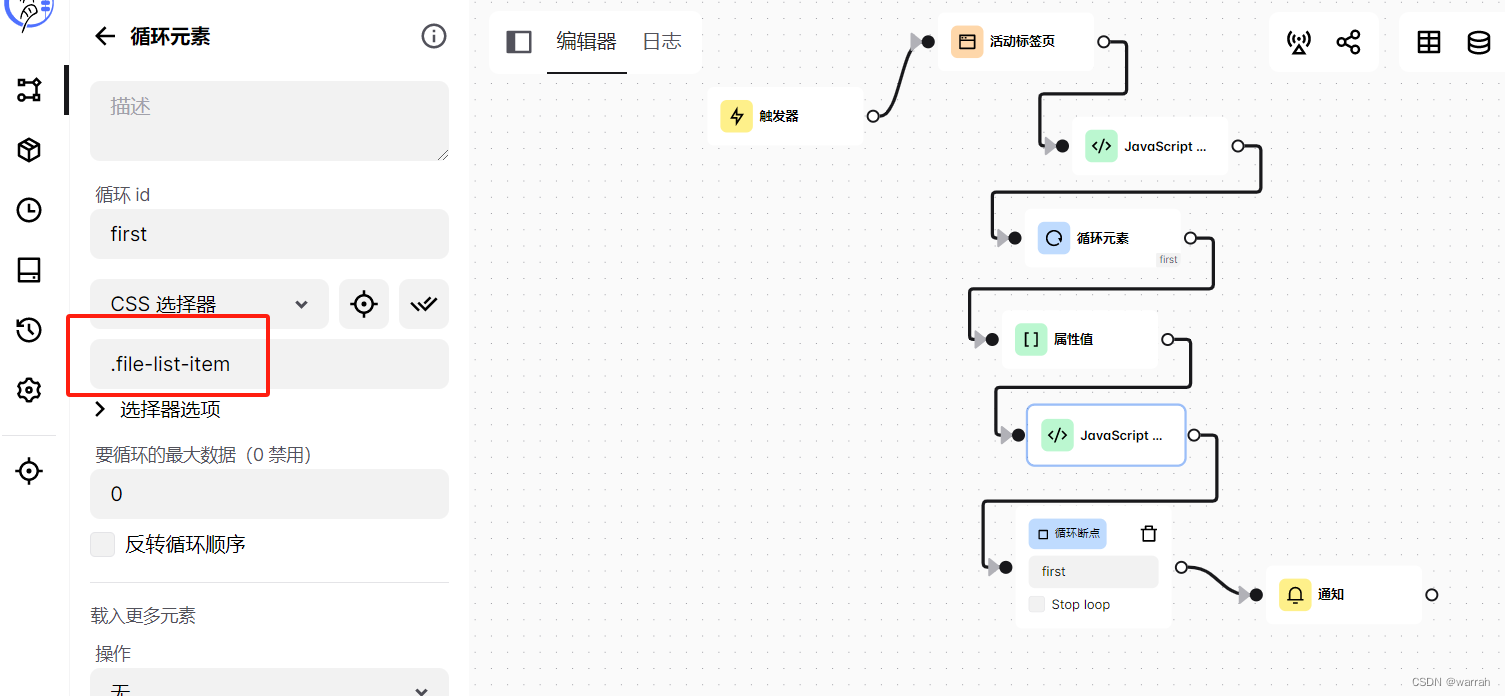
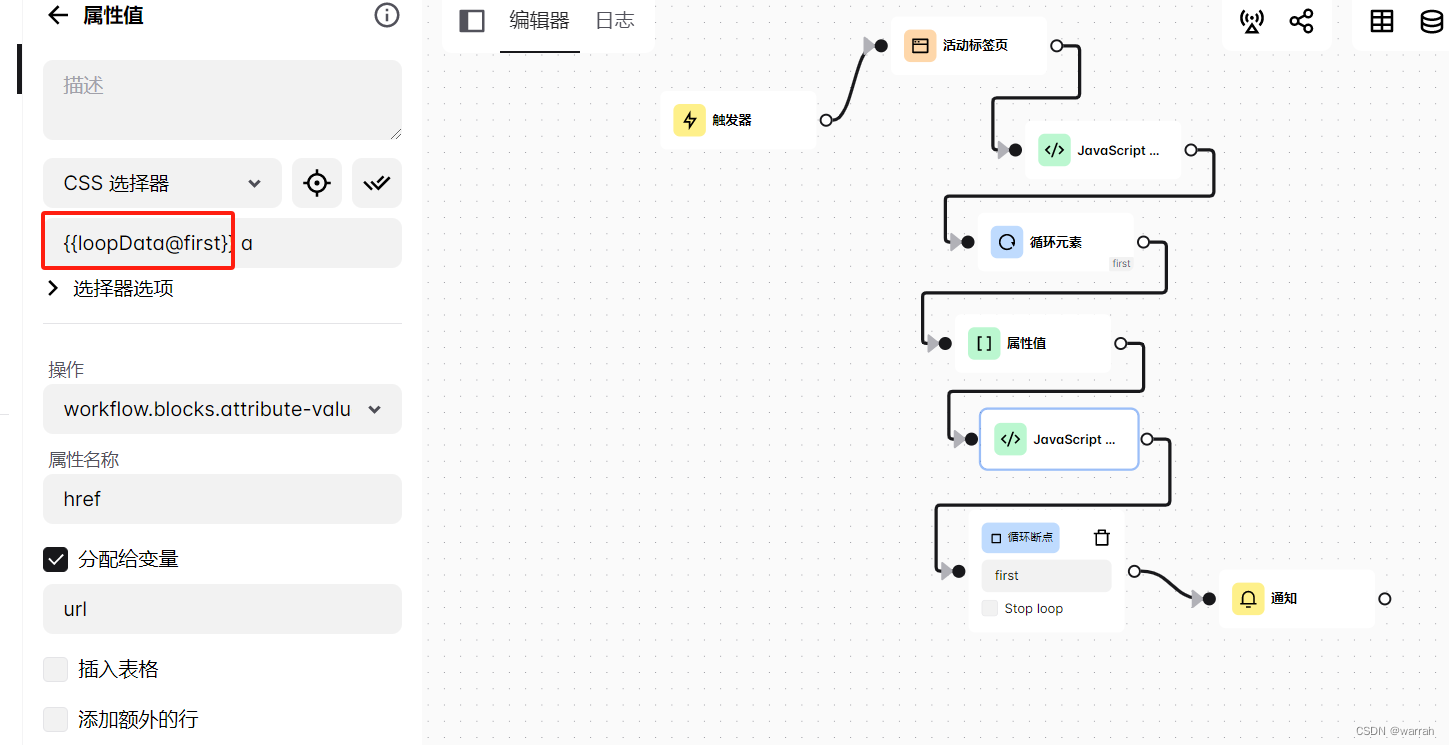
再取元素的属性值,获取超链接的href,可以看到这里的css选择器的使用规则,采用的是上面定义的first,得到值赋值给变量url
2 文件下载
飞书中文件有一个下载为“FreeMind”,这个用automa怎么操作呢?chrome浏览器 调试鼠标悬停后出现的元素样式,这里通过把鼠标放到对应元素,然后点击鼠标右键,同时按键盘上的N可以定位到悬浮窗口的dom节点,只是这种办法鼠标一挪走,就得反复这么操作,有些麻烦,多搞几次就好了。两个同时按,就不会隐藏掉,就容易定位到了。
前面两级菜单都好办,通过元素就可以找到,但是点击“FreeMind”,就有问题,因为它是文件下载。点击没有用
经过尝试,采取下面的方案,再最后的点击位置,再做一次悬停,然后点击元素,问题就可以解决了
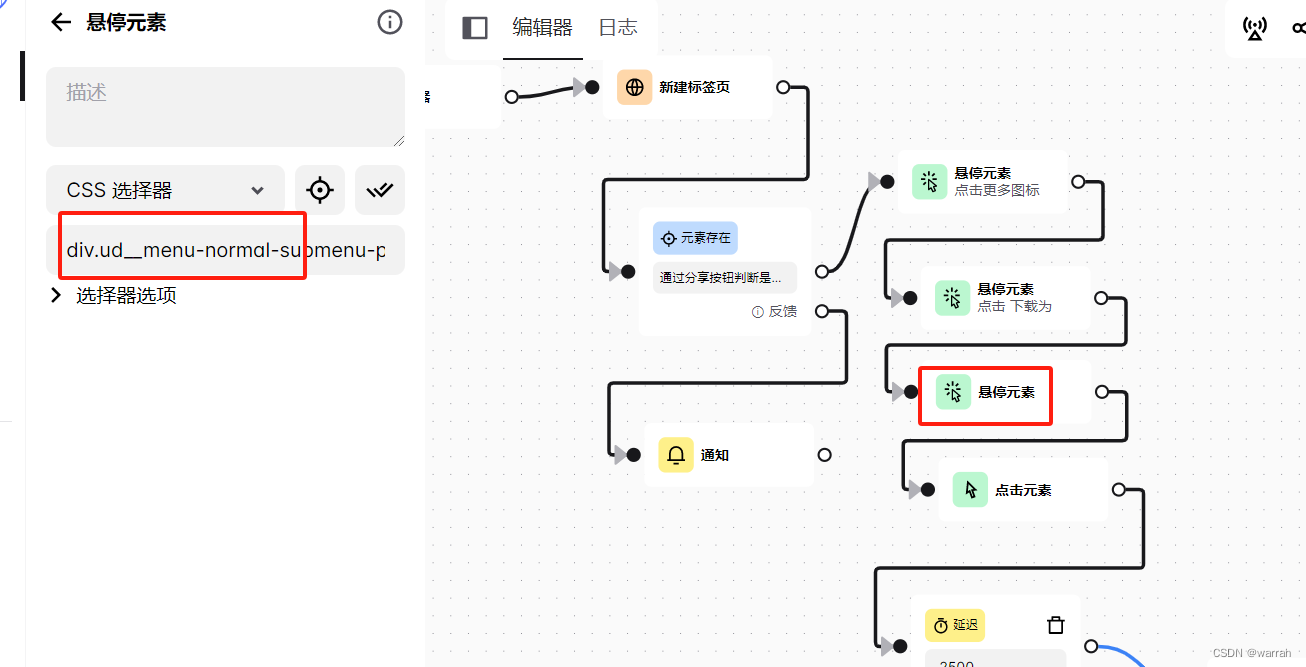
有的时候看似css选择是有效的,但实际运行却很奇怪,找不到对应的元素。于是就需要用到非常规选择器,如下面,根据文本找到确切的下载对应的浮动元素。这个实践中发现的问题,可能是网页改版了,据我上次写已经过去快4个月了。
li.ud__menu-normal-submenu > div:contains("下载")
3 执行子工作流
当业务流程较为复杂,则采取子工作流的模式,这个怎么搞,如果再一个文件里面,眼花缭乱又不好维护。
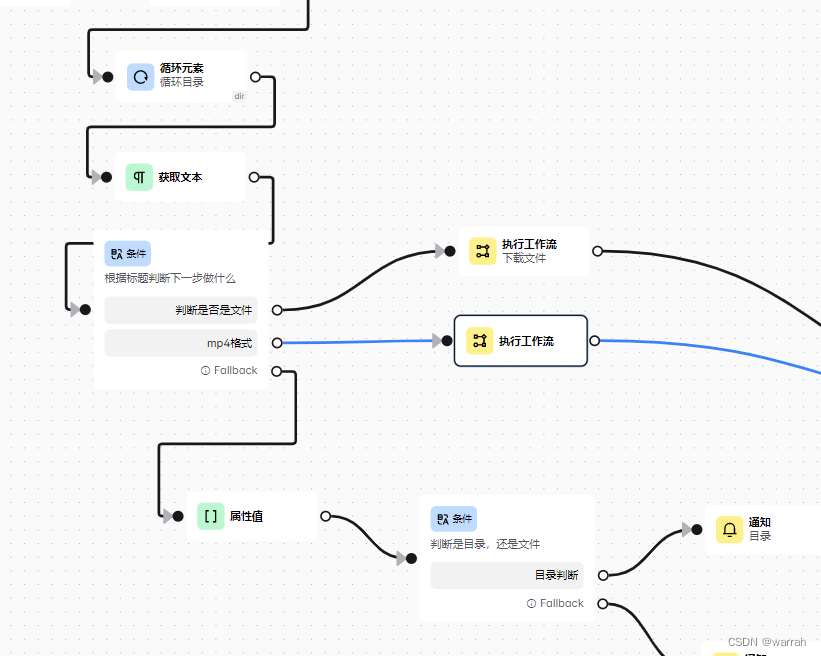
执行工作流使用起来还是挺简单,但是我之因为调整了workflow.js中的源码,讲这段代码注释掉了,
if (isFirstTime) {
localWorkflows = firstWorkflows.map((workflow) =>
defaultWorkflow(workflow)
);
await browser.storage.local.set({
isFirstTime: false,
workflows: localWorkflows,
});
}
却而代之的是,子流程就无法执行.
// const response = await fetchApi(`/piFlowFile/selectAll`, {
// auth: true,
// method: 'get',
// });
// const res = await response.json();
// if (res.success){
// let wfs = JSON.parse(res.data)
// localWorkflows = wfs.map((workflow) =>
// defaultWorkflow(workflow)
// );
// browser.storage.local.set({
// isFirstTime: true,
// workflows: localWorkflows,
// });
// this.workflows = convertWorkflowsToObject(localWorkflows);
// }
在执行工作流哪里选择子流程是那个,给子流程传入变量即可.执行id不需要填写,这个id在js变成启动工作流的时候有用,但是这里不需要
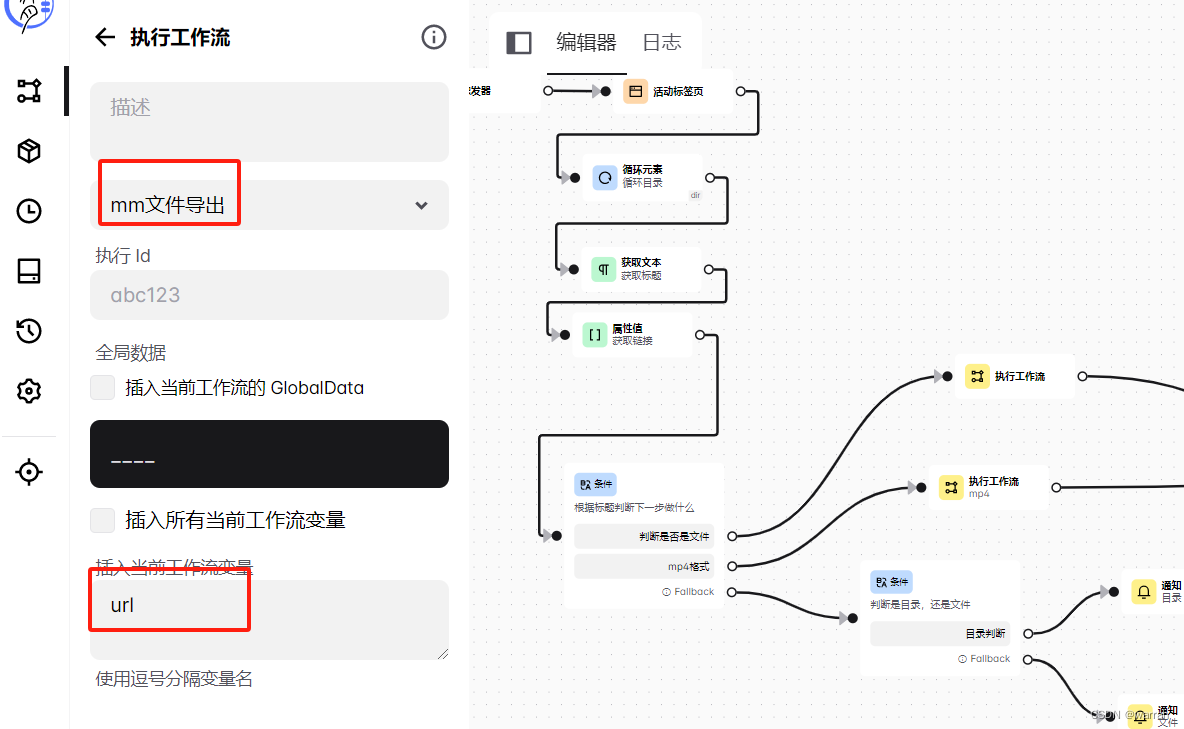
进入到子工作流中,新建标签页中填写从主流程传过来的变量参数url,取法是{{variables.url}},勾上"等待标签页加载完毕",同时设置延迟时间,因为我这里点击元素是为了下载文件,如果不设置这些,页面就关闭,那么文件就不来不及下载.因此这些配置是需要的
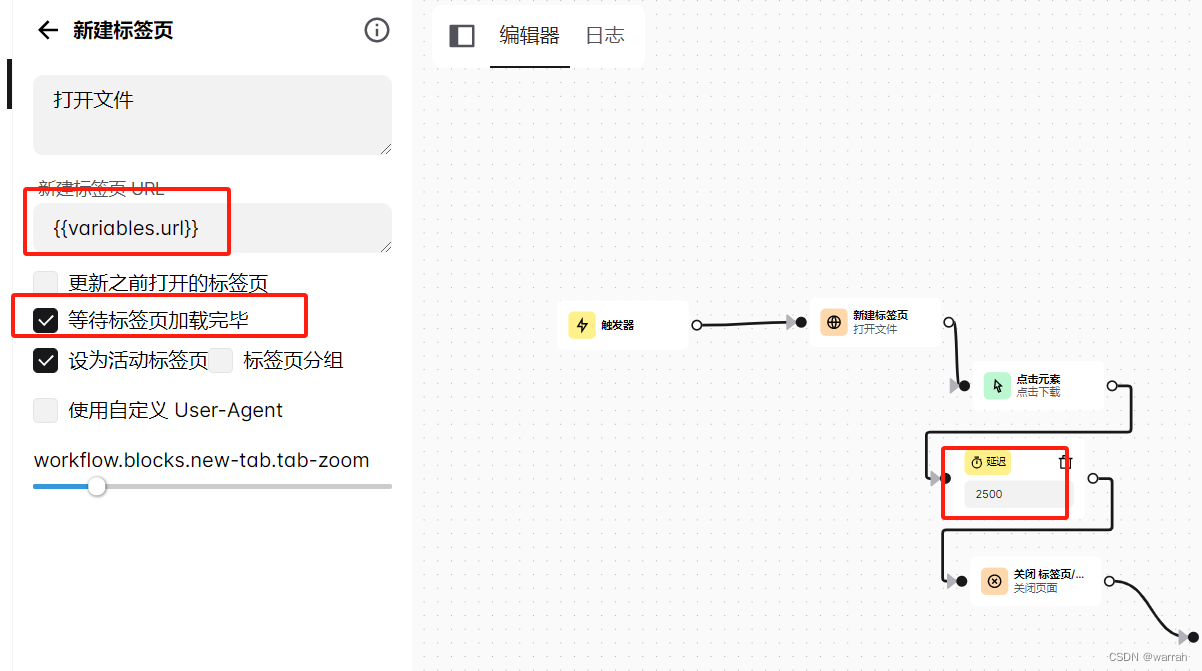
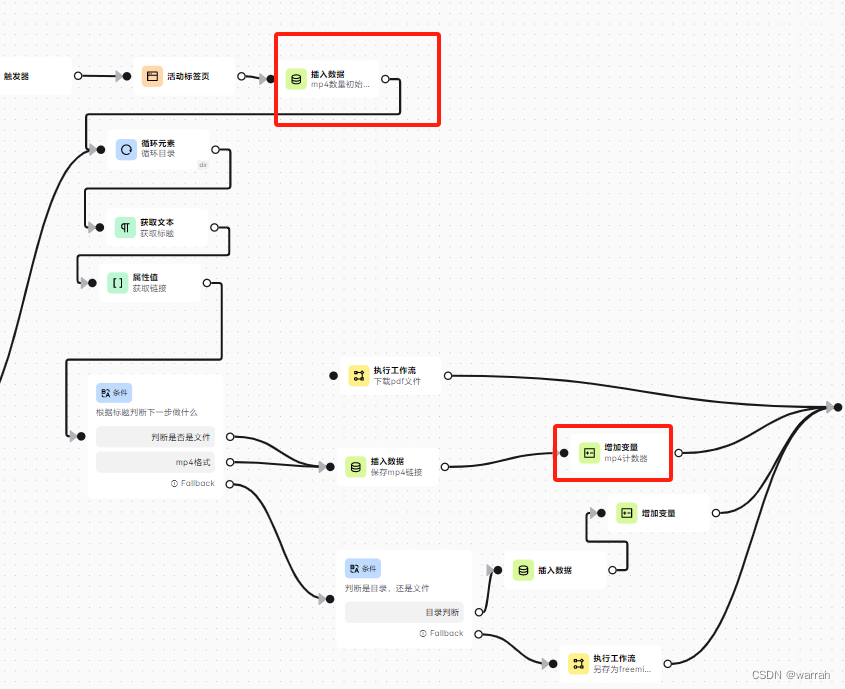
4 子流程数据处理的问题
在子流程中设置数据,有一个问题,就是如果是在循环中,设置的参数怎么返回给主流程,这是个问题,最简单的办法是在主流程操作,子流程中我还没想好怎么弄,下面的方式会产生很多文件,这是不对的.
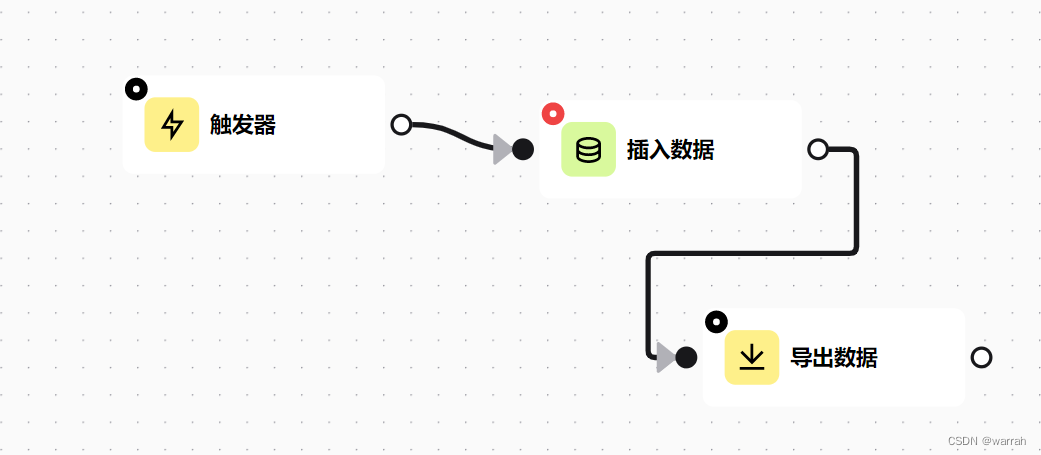
调整方案,在js中定义变量,然后设置变量自增1,这个增加变量并没有随着循环而累加,调试我发现就增加了一次,不过有了这个就够了,我根据变量是否>0,而从输出文档.避免了无效的文件生成.
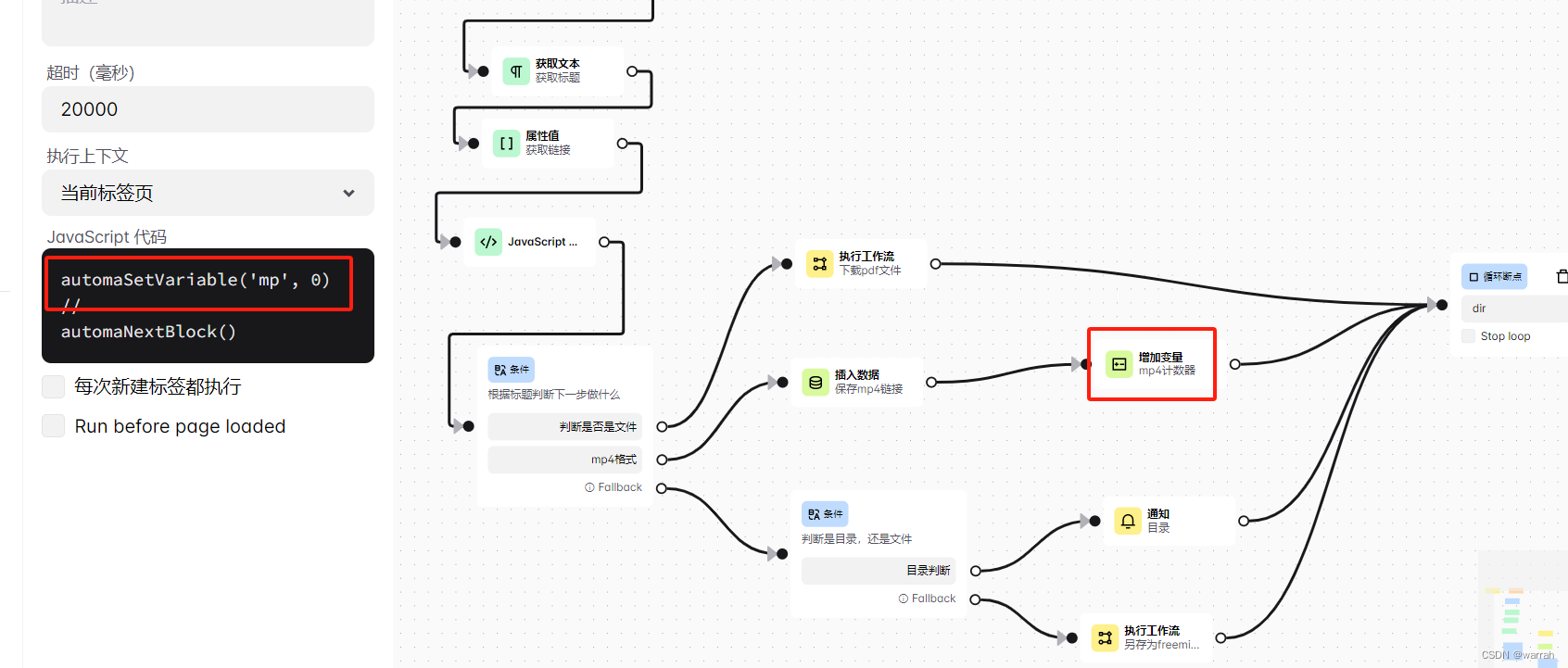
还有一种办法并不是通过js来变成定义变量,而是采用如下图,使用插入数据模块定义变量,注意变量的定义应该在循环体外。
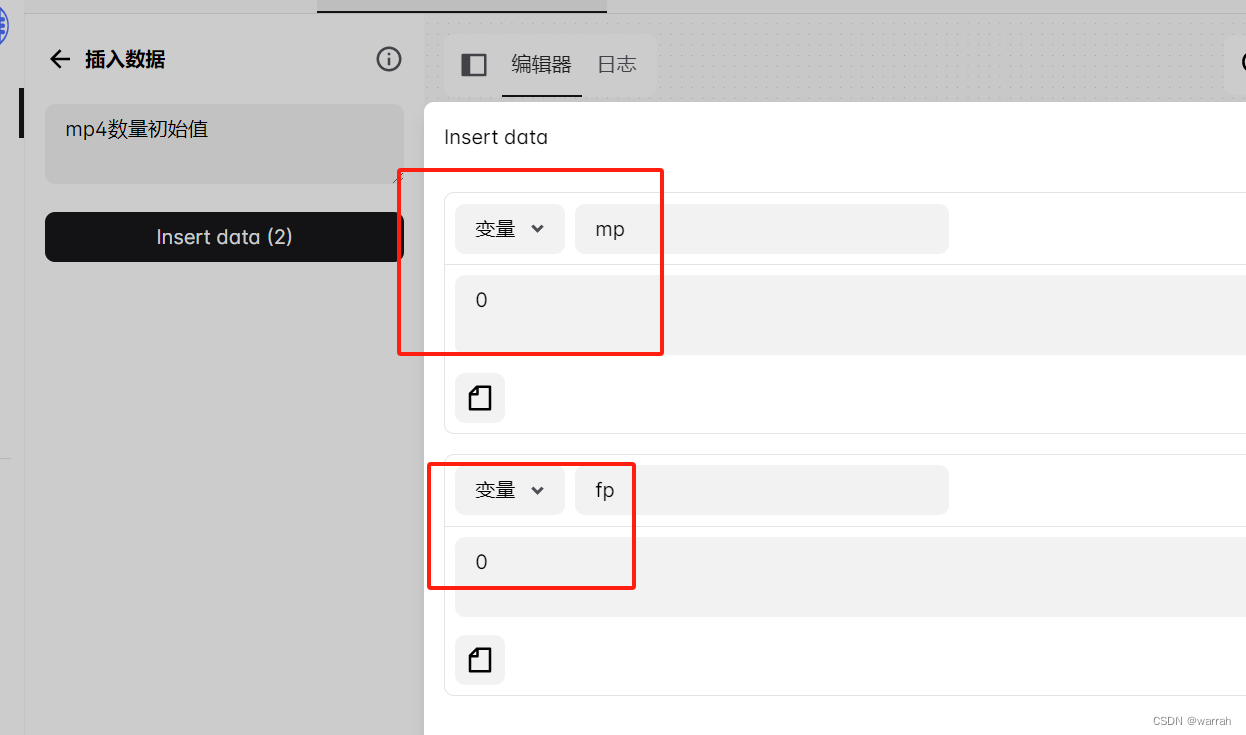
如下图在循环体外定义,这个学过变成的人都懂
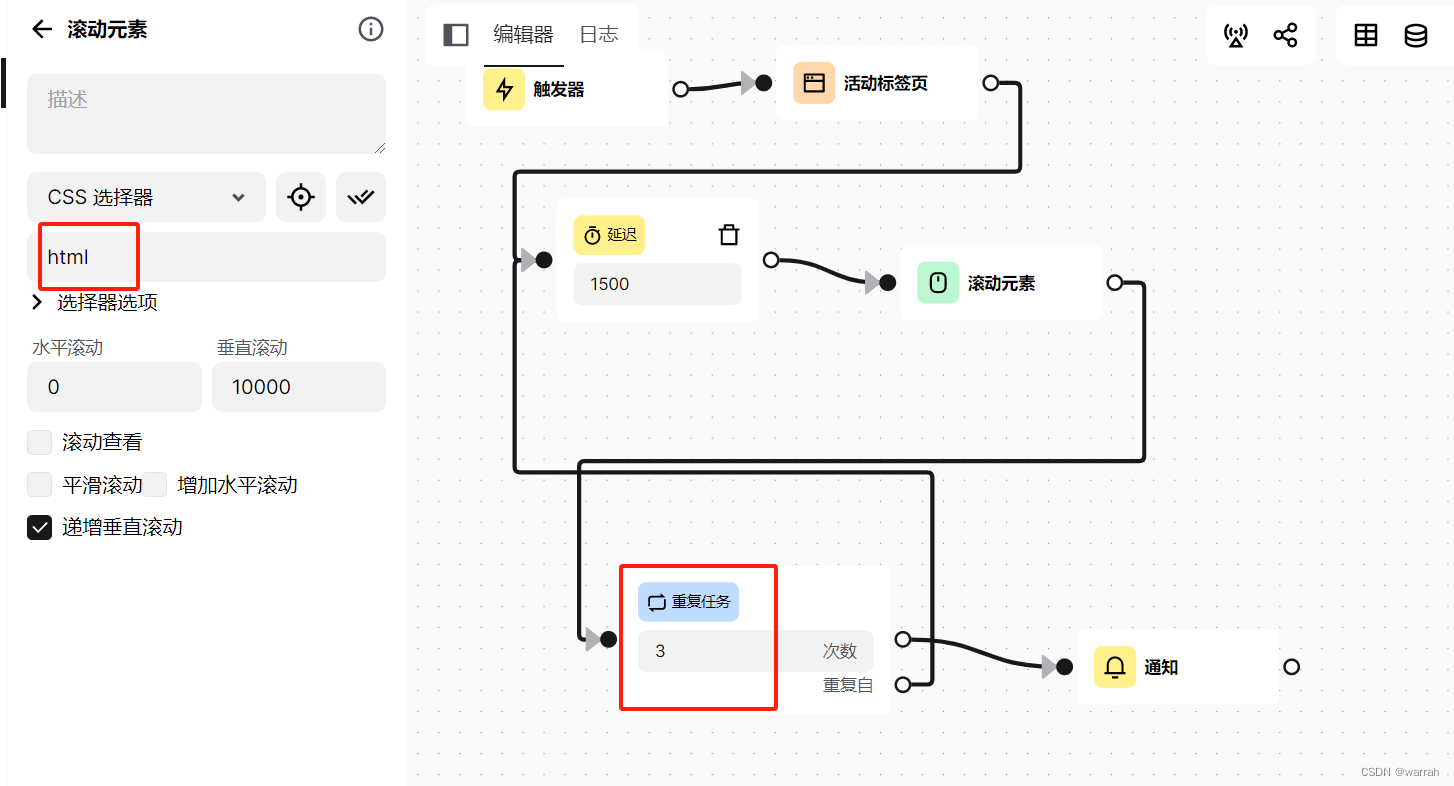
5 滚动元素使用
飞书上我的空间里面的文章并不是表格,而是采用了下拉分页,因此需要采用滚动元素来操作,
如果采取默认的css选择器,在实际应用是不行的,因为是表格下拉,而不是整页下拉.重复次数并不能解决问题,因为谁说重置任务次数就是为3的.
换一种思路,采用while组件
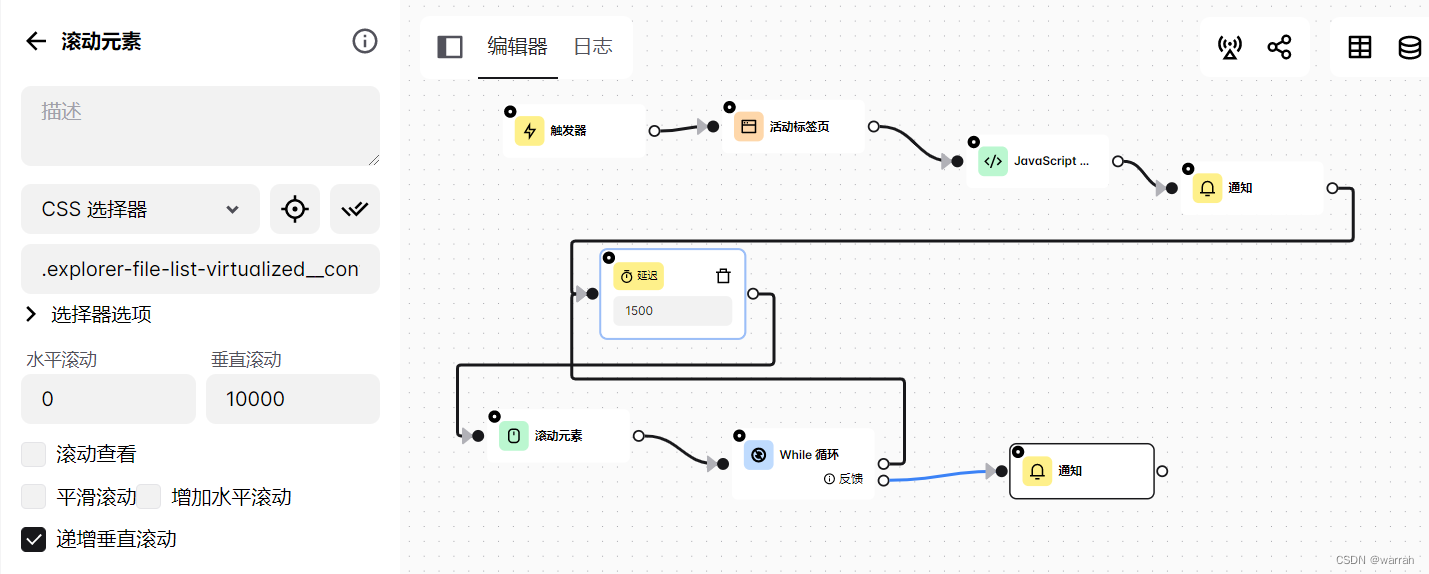
设置终止元素,如果没有发现就循环下去
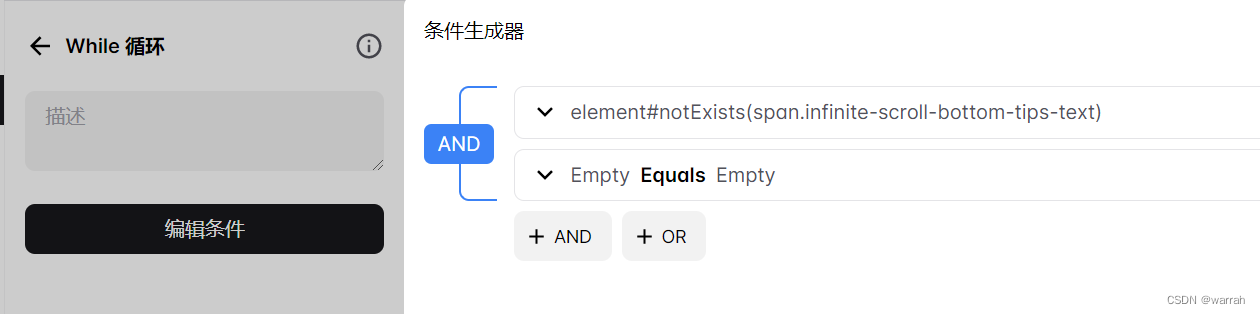
这里再扩展一下,因为我验证过,原来想先把页面滚到最下面,然后再一个个遍历行数据,但并不通,因为每次分页,下一页就会把上一页的数据覆盖掉,因此获取到的当前页数都是固定数量,因此需要再滚动元素之间,将你想要做的事情做了.例如下图:
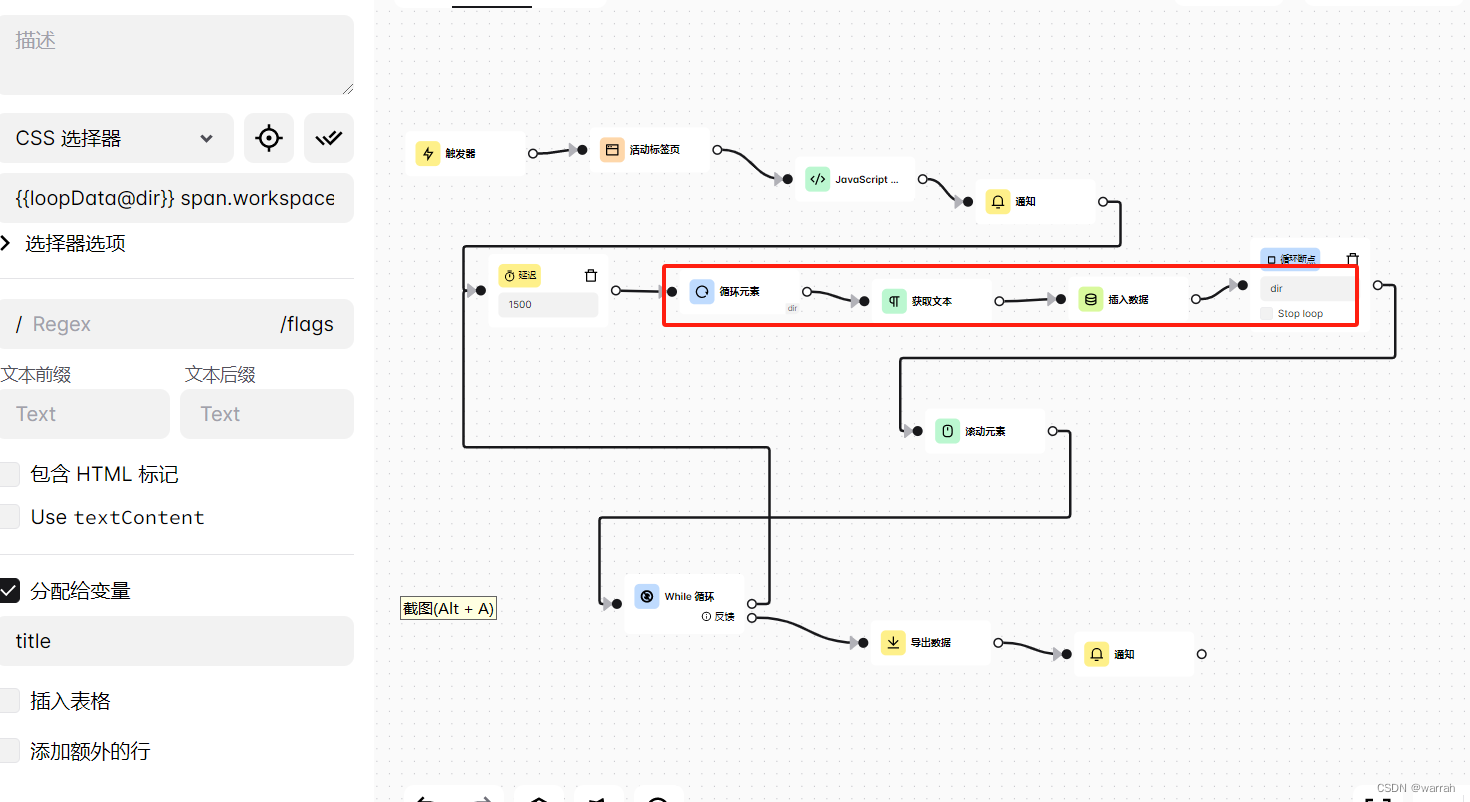
6 遍历问题
爬虫最麻烦的还是遍历问题,采用广度优先,还是深度优先.是个问题.从入口进去,有些是目录,有些是列表,目录就就去,进去之后是同样的问题.最简单的办法,就是把所有的东西遍历一边,把链接是文件的,保存起来,然后在一个个打开.不过如果这样的话,会不会显得工程师没有什么水平呢?
如果采取最简单的方式,在下图如果判定时目录的时候,再进入到循环元素,经过验证后,这个是有问题的,因为在验证文本的的时候,这个地方,循环还是上一个页面的元素。
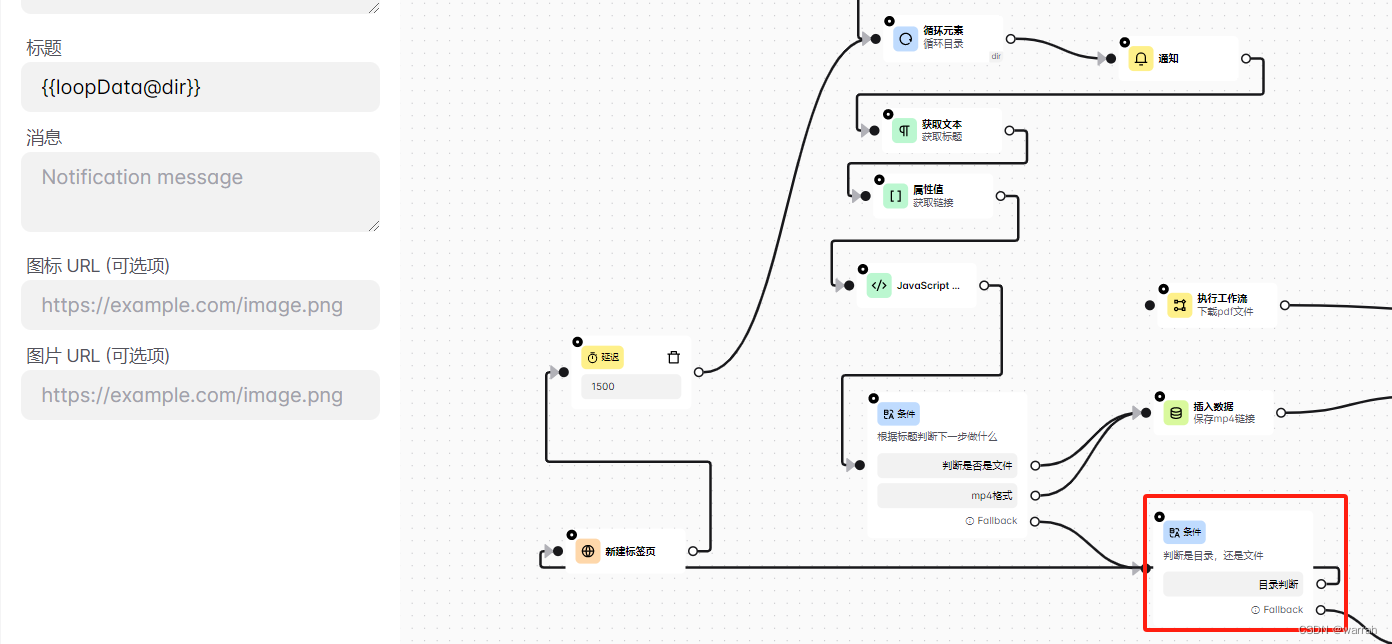
这是第一次的循环

这是第二次的循环,第二次新页面已经代开,但是loopData@dir获取的值,还是上一次的数据。因此上面的设计是不合理的。大概的判断应该还是在同一个循环体中。

如果把目录的数据存起来,然后遍历这个目录数据会怎样呢?为了少走弯路,于是翻阅官网网站上别人给的示例,在这个过程中也发现一些有意思的东西.
如下图通过$last关键字可以获取最后一条记录的数据
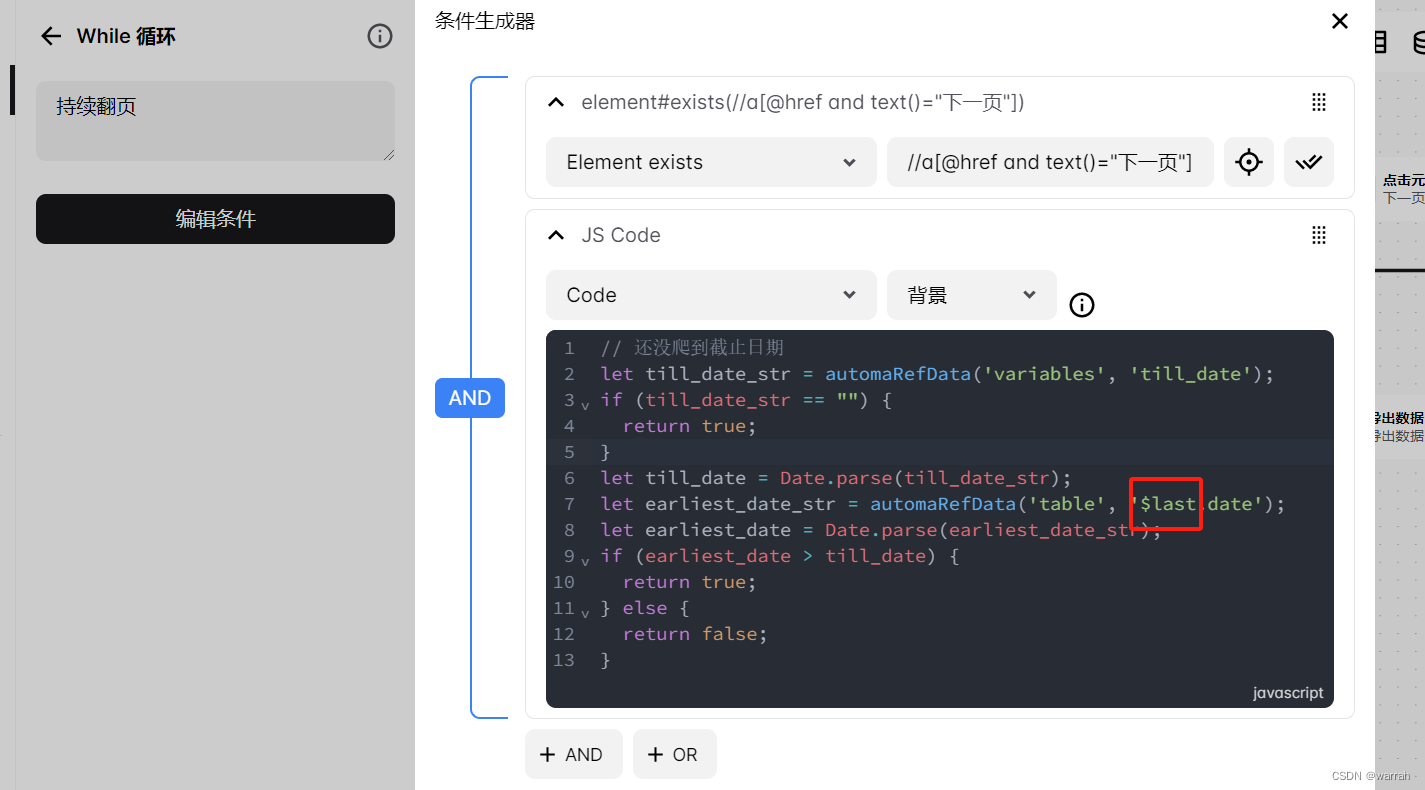
因为automa插件使用的是vue技术,因此可以看到他支持的js取值可以这么写
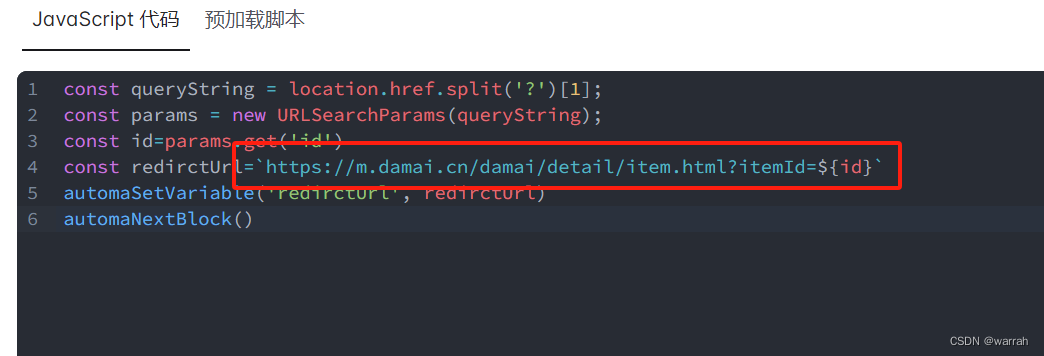
遍历的时候如果出现链接重复,可以通过js代码实现去重
// 提取变量中的链接
let urls = automaRefData('variables', 'liked_urls');
// 列表元素去重
function onlyUnique(value, index, array) {
return array.indexOf(value) === index;
}
var unique_urls = urls.filter(onlyUnique);
// 更新变量
automaSetVariable('liked_urls', unique_urls);
继续探索,既然这种工具性产品,万不得已是可以不用写js的,因此再利用原生的模块。
将是目录的链接保存起来。然后在插入数据,接着再从数组取出数据,然后再循环,是否可以呢?
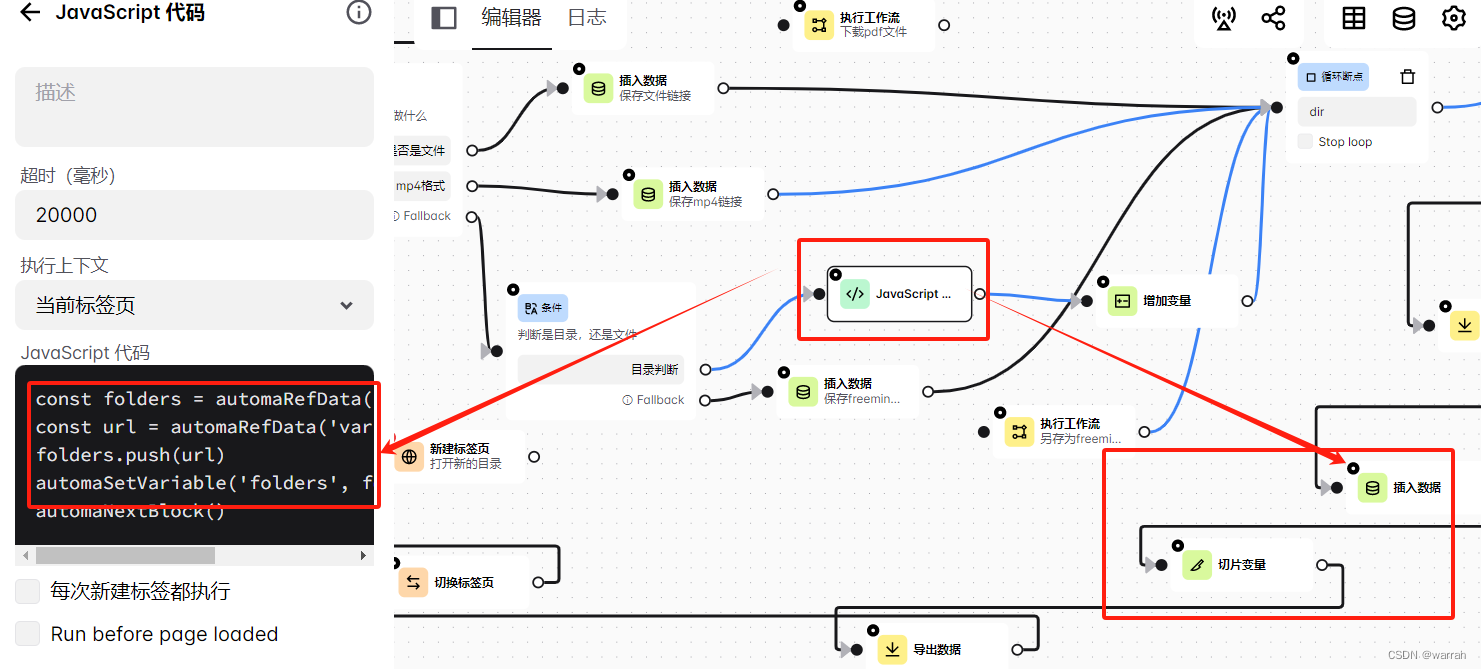
插入数据模块,采用是下面的写法,取文件链接变量folders的第一个值
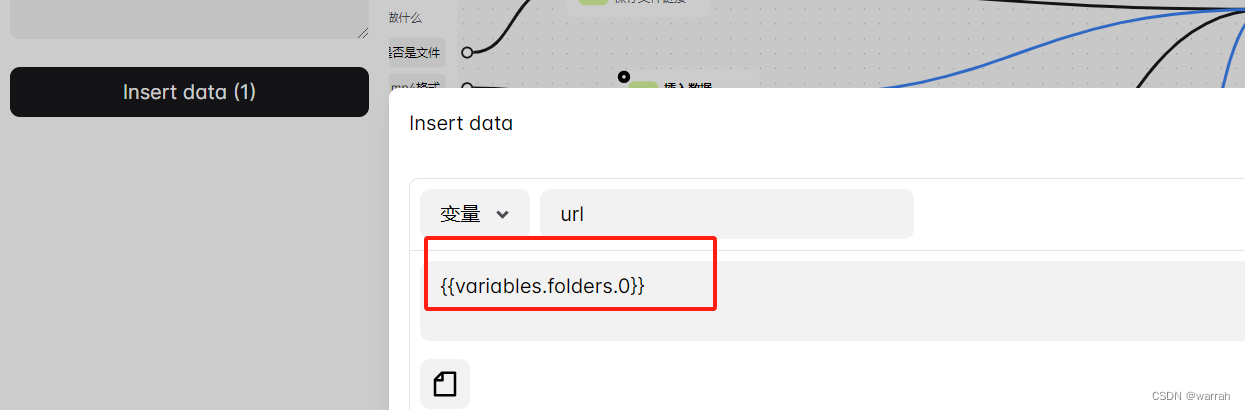
接着利用切片变量,将使用过的链接从数组中删掉。注意开始序列是1。
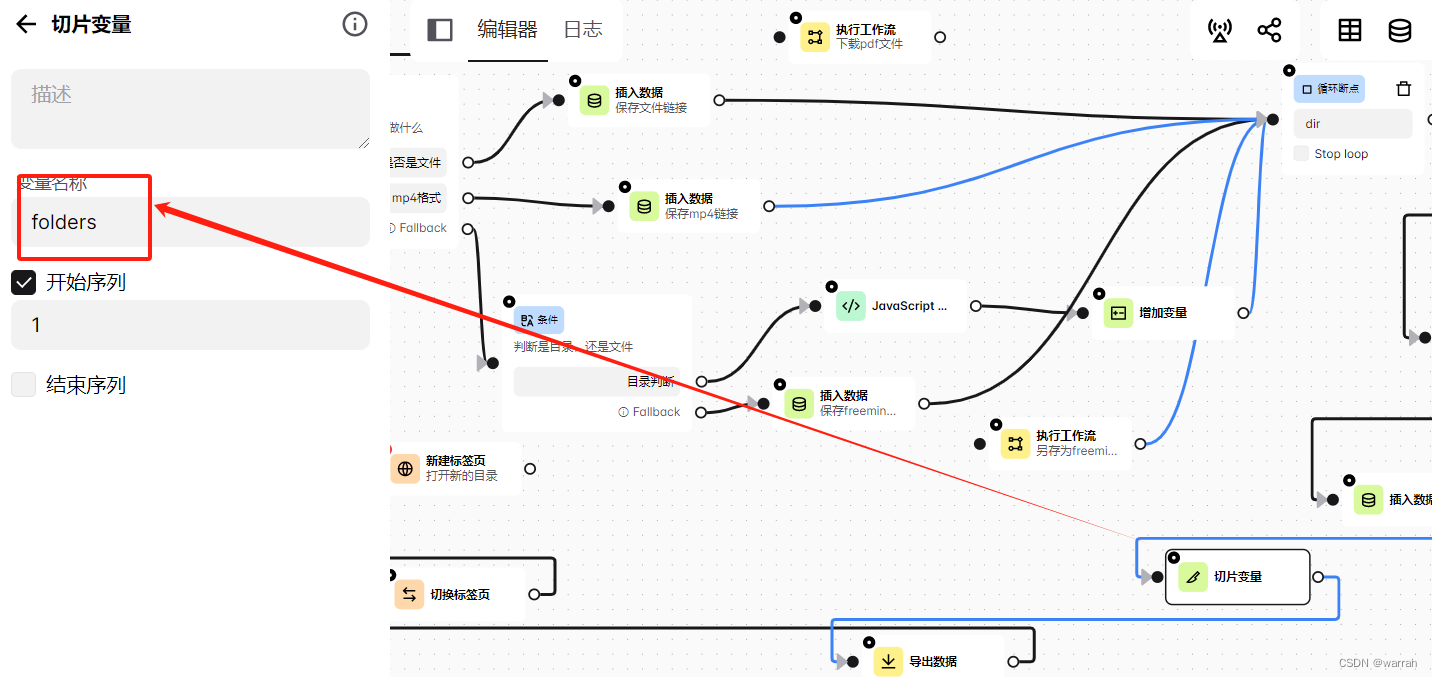
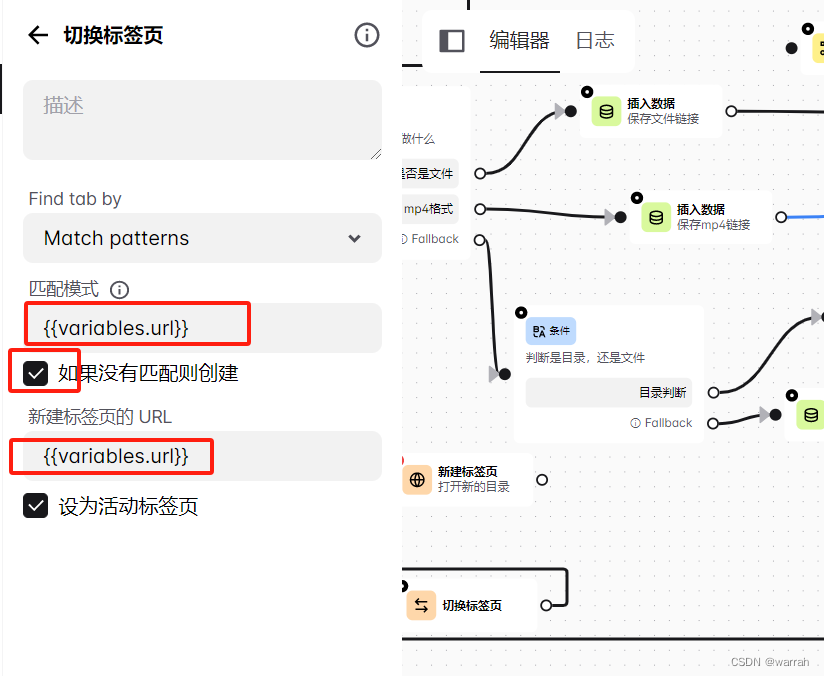
接下来通过链接打开的是切换标签页,不是新建标签页,验证过新建标签页是不能达到想要的效果。
切换标签页的配置项如下红色方框设置。经过几个页面居然成功了。
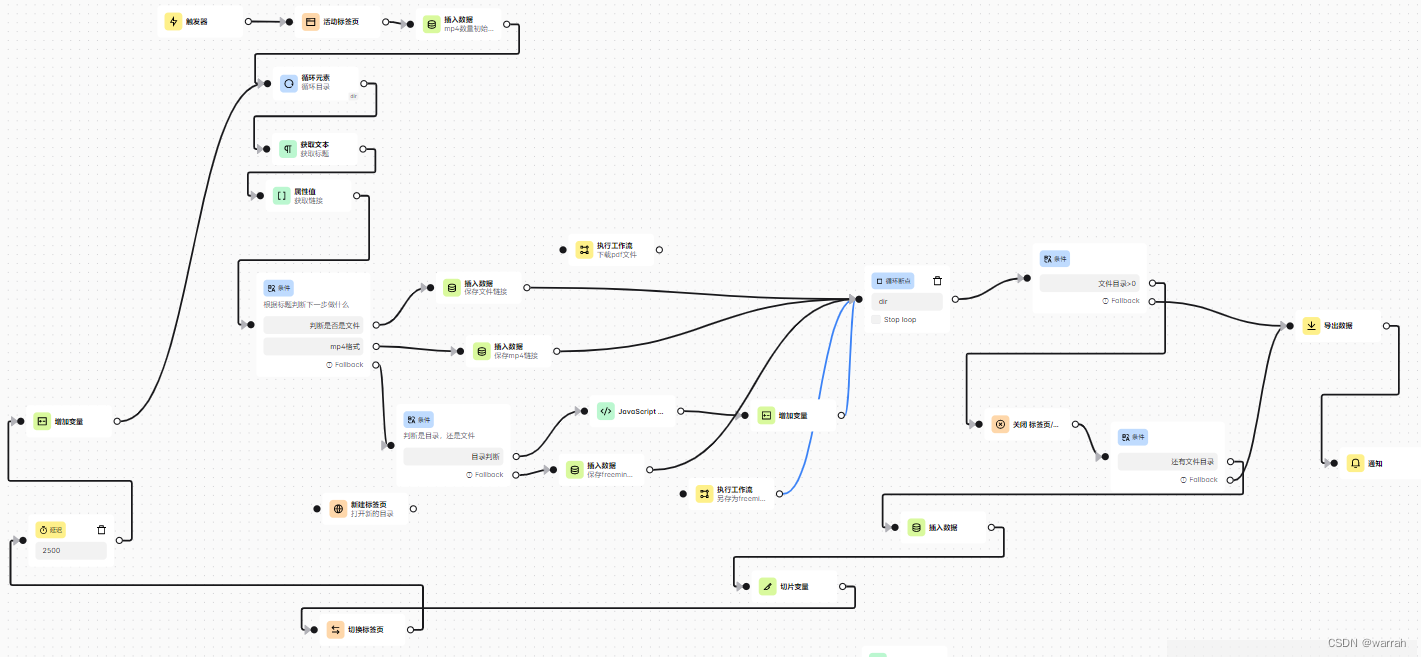
接下来采用全量模式进行验证看看,如下图这样一个复杂的流程,经过十几个页面级循环,下载了132项文件,进入到一个也页面报错,但是单独执行又可以,现在还得调试看问题在哪里,真实是要想说国粹了。
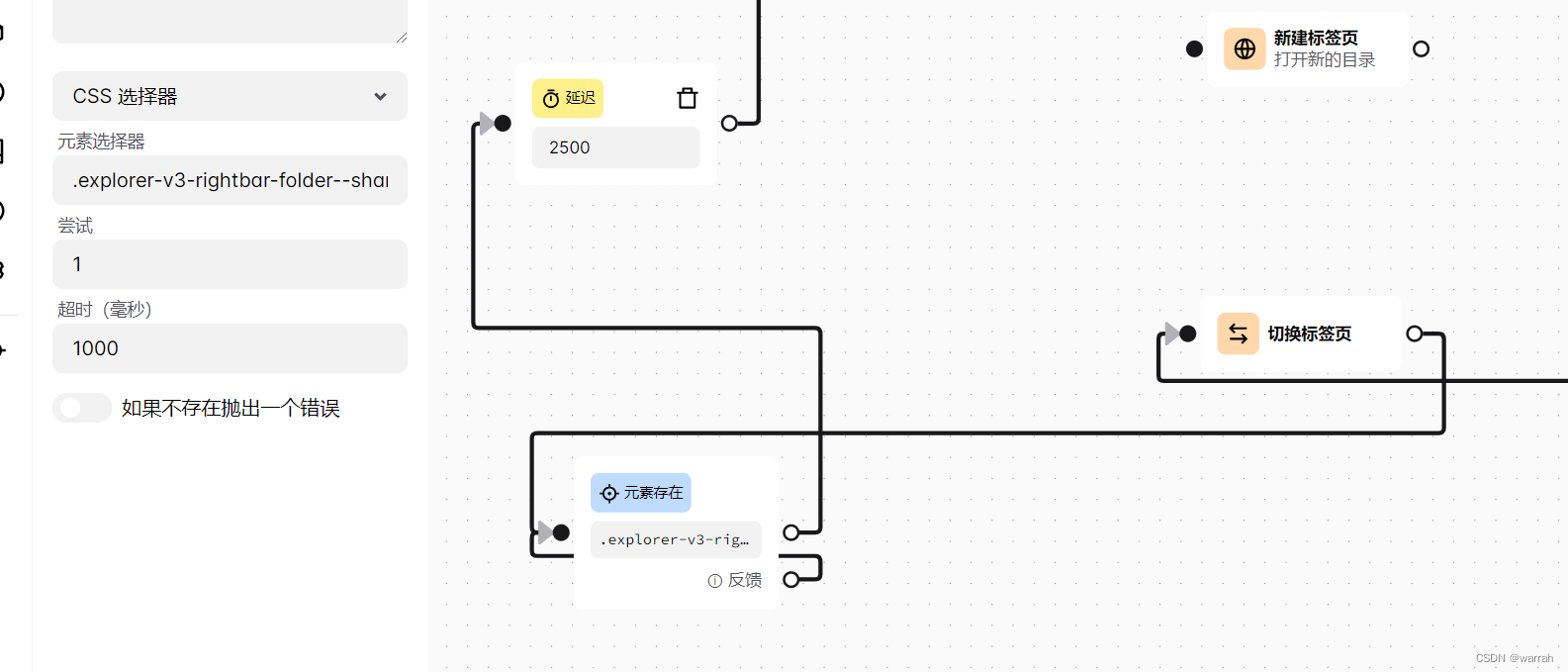
根据报错的页面,向上追溯两三级,然后再验证,这样可以减少定位的范围。接着再可能存在异常的地方打断点调试,结果发现分布调试,运行是可以输出结果的,那么问题是不是那个地方应该设置延迟,或者是因为没有加载出来导致的?于是选择最有可能出问题的,切换标签页后面加一个元素存在的判断,如果某个元素没有加载出来,那么再循环等待直到元素出现,后面再加一个延迟,就不怕出不来。结果果然可以。

















 5130
5130











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











