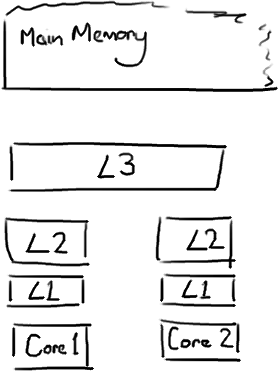
CPU是你机器的心脏,最终由它来执行所有运算和程序。主内存(RAM)是你的数据(包括代码行)存放的地方。CPU和主内存之间有好几层缓存,因为即使直接访问主内存也是非常慢的。如果你正在多次对一块数据做相同的运算,那么在执行运算的时候把它加载到离CPU很近的地方就有意义了(比如一个循环计数-你不想每次循环都跑到主内存去取这个数据来增长它吧)。
越靠近CPU的缓存越快也越小。所以L1缓存很小但很快(译注:L1表示一级缓存),并且紧靠着在使用它的CPU内核。L2大一些,也慢一些,并且仍然只能被一个单独的 CPU 核使用。L3在现代多核机器中更普遍,仍然更大,更慢,并且被单个插槽上的所有 CPU 核共享。最后,你拥有一块主存,由全部插槽上的所有 CPU 核共享。
当CPU执行运算的时候,它先去L1查找所需的数据,再去L2,然后是L3,最后如果这些缓存中都没有,所需的数据就要去主内存拿。走得越远,运算耗费的时间就越长。所以如果你在做一些很频繁的事,你要确保数据在L1缓存中。
|
从CPU到
| 大约需要的 CPU 周期 | 大约需要的时间 |
| 主存 | | 约60-80纳秒 |
| QPI 总线传输 | | 约20ns |
| (between sockets, not drawn) |
| L3 cache | 约40-45 cycles, | 约15ns |
| L2 cache | 约10 cycles, | 约3ns |
| L1 cache | 约3-4 cycles, | 约1ns |
| 寄存器 | 1 cycle |
|
如果你的目标是让端到端的延迟只有 10毫秒,而其中花80纳秒去主存拿一些未命中数据的过程将占很重的一块。
缓存行
现在需要注意一件有趣的事情,数据在缓存中不是以独立的项来存储的,如不是一个单独的变量,也不是一个单独的指针。缓存是由缓存行组成的,通常是64字节,并且它有效地引用主内存中的一块地址。一个Java的long类型是8字节,因此在一个缓存行中可以存8个long类型的变量。
非常奇妙的是如果你访问一个long数组,当数组中的一个值被加载到缓存中,它会额外加载另外7个。因此你能非常快地遍历这个数组。事实上,你可以非常快速的遍历在连续的内存块中分配的任意数据结构。
因此如果你数据结构中的项在内存中不是彼此相邻的,你将得不到免费缓存加载所带来的优势。并且在这些数据结构中的每一个项都可能会出现缓存未命中。
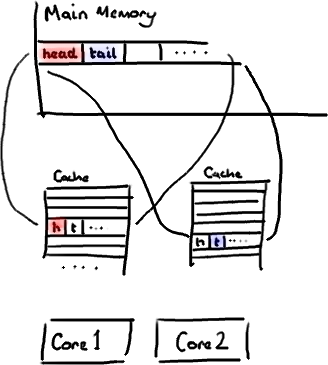
不过,所有这种免费加载有一个弊端。设想你的long类型的数据不是数组的一部分。设想它只是一个单独的变量。让我们称它为head,这么称呼它其实没有什么原因。然后再设想在你的类中有另一个变量紧挨着它。让我们直接称它为tail。现在,当你加载head到缓存的时候,你也免费加载了tail。

听想来不错。直到你意识到tail正在被你的生产者写入,而head正在被你的消费者写入。这两个变量实际上并不是密切相关的,而事实上却要被两个不同内核中运行的线程所使用。

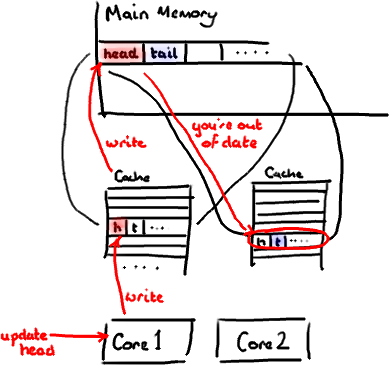
设想你的消费者更新了head的值。缓存中的值和内存中的值都被更新了,而其他所有存储head的缓存行都会都会失效,因为其它缓存中head不是最新值了。请记住我们必须以整个缓存行作为单位来处理,不能只把head标记为无效。

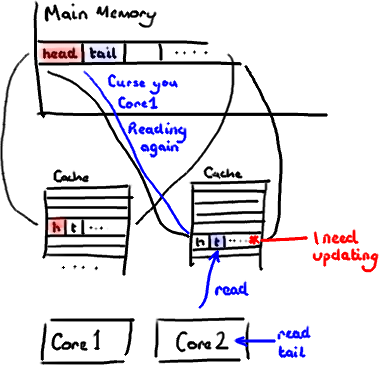
现在如果一些正在其他内核中运行的进程只是想读tail的值,整个缓存行需要从主内存重新读取。那么一个和你的消费者无关的线程读一个和head无关的值,它被缓存未命中给拖慢了。
当然如果两个独立的线程同时写两个不同的值会更糟。因为每次线程对缓存行进行写操作时,每个内核都要把另一个内核上的缓存块无效掉并重新读取里面的数据。你基本上是遇到两个线程之间的写冲突了,尽管它们写入的是不同的变量。
这叫作“伪共享”(可以理解为错误的共享),因为每次你访问head你也会得到tail,而且每次你访问tail,你也会得到head。这一切都在后台发生,并且没有任何编译警告会告诉你,你正在写一个并发访问效率很低的代码。
伪共享(False Sharing)
缓存系统中是以缓存行(cache line)为单位存储的。缓存行是2的整数幂个连续字节,一般为32-256个字节。最常见的缓存行大小是64个字节。当多线程修改互相独立的变量时,如果这些变量共享同一个缓存行,就会无意中影响彼此的性能,这就是伪共享。缓存行上的写竞争是运行在SMP系统中并行线程实现可伸缩性最重要的限制因素。有人将伪共享描述成无声的性能杀手,因为从代码中很难看清楚是否会出现伪共享。
为了让可伸缩性与线程数呈线性关系,就必须确保不会有两个线程往同一个变量或缓存行中写。两个线程写同一个变量可以在代码中发现。为了确定互相独立的变量是否共享了同一个缓存行,就需要了解内存布局,或找个工具告诉我们。Intel VTune就是这样一个分析工具。

上图说明了伪共享的问题。在核心1上运行的线程想更新变量X,同时核心2上的线程想要更新变量Y。不幸的是,这两个变量在同一个缓存行中。每个线程都要去竞争缓存行的所有权来更新变量。如果核心1获得了所有权,缓存子系统将会使核心2中对应的缓存行失效。当核心2获得了所有权然后执行更新操作,核心1就要使自己对应的缓存行失效。这会来来回回的经过L3缓存,大大影响了性能。如果互相竞争的核心位于不同的插槽,就要额外横跨插槽连接,问题可能更加严重。
Volatile的官方定义
Java语言规范第三版中对volatile的定义如下: java编程语言允许线程访问共享变量,为了确保共享变量能被准确和一致的更新,线程应该确保通过排他锁单独获得这个变量。Java语言提供了volatile,在某些情况下比锁更加方便。如果一个字段被声明成volatile,java线程内存模型确保所有线程看到这个变量的值是一致的。
为什么要使用Volatile
Volatile变量修饰符如果使用恰当的话,它比synchronized的使用和执行成本会更低,因为它不会引起线程上下文的切换和调度。
Volatile的实现原理
那么Volatile是如何来保证可见性的呢?在x86处理器下通过工具获取JIT编译器生成的汇编指令来看看对Volatile进行写操作CPU会做什么事情。
| Java代码: | instance = new Singleton();//instance是volatile变量 |
| 汇编代码: | 0x01a3de1d: movb $0×0,0×1104800(%esi);0x01a3de24: lock addl $0×0,(%esp); |
有volatile变量修饰的共享变量进行写操作的时候会多第二行汇编代码,通过查IA-32架构软件开发者手册可知,lock前缀的指令在多核处理器下会引发了两件事情。
- 将当前处理器缓存行的数据会写回到系统内存。
- 这个写回内存的操作会引起在其他CPU里缓存了该内存地址的数据无效。
处理器为了提高处理速度,不直接和内存进行通讯,而是先将系统内存的数据读到内部缓存(L1,L2或其他)后再进行操作,但操作完之后不知道何时会写到内存,如果对声明了Volatile变量进行写操作,JVM就会向处理器发送一条Lock前缀的指令,将这个变量所在缓存行的数据写回到系统内存。但是就算写回到内存,如果其他处理器缓存的值还是旧的,再执行计算操作就会有问题,所以在多处理器下,为了保证各个处理器的缓存是一致的,就会实现缓存一致性协议,每个处理器通过嗅探在总线上传播的数据来检查自己缓存的值是不是过期了,当处理器发现自己缓存行对应的内存地址被修改,就会将当前处理器的缓存行设置成无效状态,当处理器要对这个数据进行修改操作的时候,会强制重新从系统内存里把数据读到处理器缓存里。

























 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










{kind=link}
{kind=link}
{kind=link}
{kind=link}