






使用 torchtext.datasets 下载数据的时候,
import torchtext.datasets as datasets
# downloaded to C:\Users\Administrator\.cache\torch\text\datasets\Multi30k automactically.
train_iter, valid_iter, test_iter = datasets.Multi30k(
language_pair=("de", "en")
)
遇到错误:
File "C:\devel\Python\Python311\Lib\site-packages\torchdata\datapipes\iter\util\plain_text_reader.py", line 62, in decode
yield from stream
File "C:\devel\Python\Python311\Lib\site-packages\torchdata\datapipes\iter\util\plain_text_reader.py", line 54, in strip_newline
for line in stream:
File "C:\devel\Python\Python311\Lib\site-packages\torchdata\datapipes\iter\util\plain_text_reader.py", line 45, in skip_lines
yield from file
File "C:\devel\Python\Python311\Lib\site-packages\torch\utils\data\datapipes\utils\common.py", line 368, in __iter__
yield from self.file_obj
File "<frozen codecs>", line 322, in decode
UnicodeDecodeError: 'utf-8' codec can't decode byte 0x80 in position 37: invalid start byte
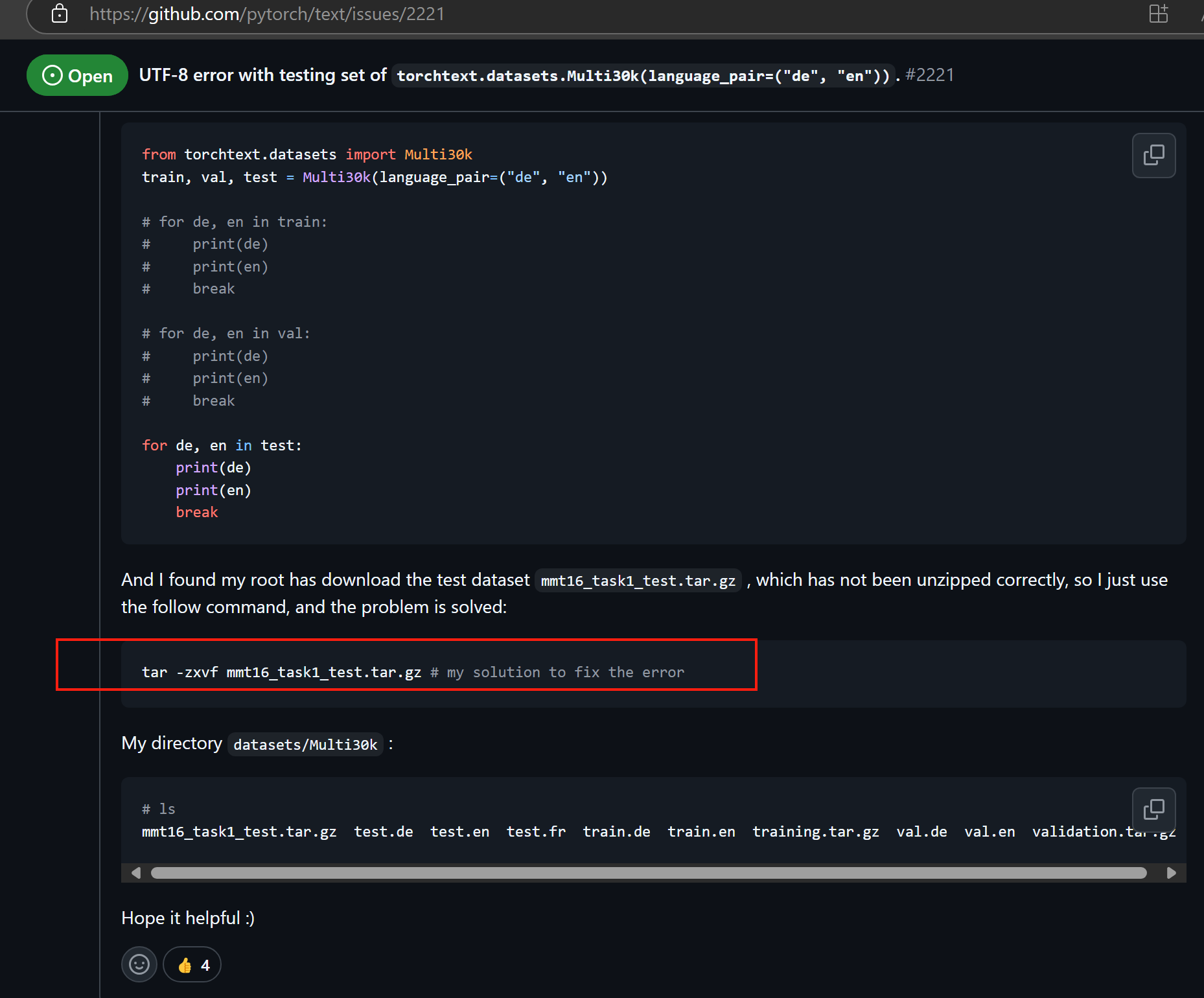
解决方案:
cd C:\Users\Administrator\.cache\torch\text\datasets\Multi30k
tar -zxvf mmt16_task1_test.tar.gz # my solution to fix the error
参考:


















 2413
2413

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









