






本节知识点:
1.数据之间的逻辑结构:
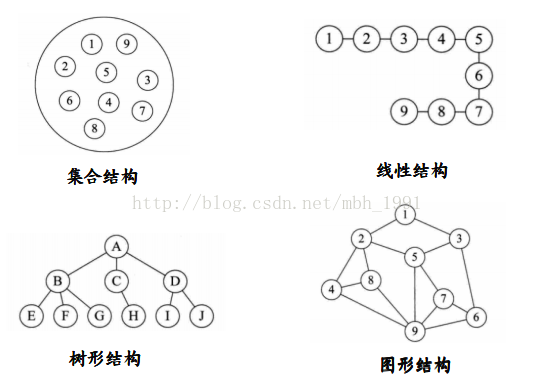
集合结构:数据元素之间没有特别的关系,仅同属相同集合
线性结构:数据元素之间是一对一的关系
树形结构:数据元素之间存在一对多的层次关系
图形结构:数据元素之间是多对多的关系
2.数据之间的物理结构
顺序存储结构:将数据存储在地址连续的存储单元里
链式存储结构:将数据存储在任意的存储单元里,通过保存地址的方式找到相关的数据元素
3.数据结构是相互之间存在一种或多种特定关系的数据元素的集合
4.程序 = 数据结构 + 算法
5.大O表示法:算法效率严重依赖于操作数量,首先关注操作数的最高次项,操作数的估计可以作为时间和空间复杂度的估算,在没有特殊说明的时候,我们应该分析复杂度的最坏情况
6.常见的复杂度类型:
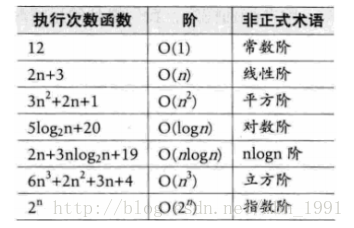
大小关系:
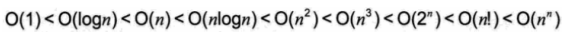
7.线性表是零个或多个数据元素的集合,之间的元素是有顺序的,个数是有限的,数据类型必须相同。线性表包含两种存储方式,一种是顺序表,另一种链表。
8.对于线性表的使用是这样的:应该是在设计算法的时候,考虑算法中使用的数据,这些数据之间是什么关系的,如果是符合线性表特质的,就选择线性表作为数据结构。
9.顺序表与数组的关系:其实顺序表就是在数组的基础上构建的,本质跟数组是一样的,只是在数组的基础上增加了length长度,capacity容量等特性,然后补充了一些列,增、删、改、查的功能。
10. 我觉得链表比顺序表最大的优势,就在于链表的删除和插入要比顺序表简单的多,而且当线性表长度很大的时候很难开辟出整段的连续空间!!!最重要的是顺序表在创建的时候长度就固定了,再也改变不了了,而链表则可以根据情况动态增加,这一点是顺序表无论怎么样都不可能实现的!!!
顺序表的优点是:无需为线性表中的逻辑增加额外的空间,可以快速的通过下标的方式找到表中的合法位置。
11.线性表的常用操作:创建线性表、销毁线性表、清空线性表、将元素插入线性表、将元素从线性表中删除、获取线性表中某个位置的元素、获取线性表的长度
本节代码:
1.本节的代码是一个可以适合各种类型的顺序表,之所以能够适合各种类型,是因为它在顺序表中保存的是元素的地址(其实就是一个指针数组)。
2.代码中的描述顺序表的结构体中的元素介绍:length是顺序表中有元素的个数、capacity是顺序表的容量、node是顺序表的头地址(也是这个指针数组的头地址)、还有一个就是pos,pos是在删除和插入的时候使用的一个参数,它代表的是插入到顺序表位置的下标(数组的下标 是从0开始的 这个很要注意)。顺序表中有length个元素 下标是从0到length-1的。要注意的是 操作顺序表不同功能函数的pos的允许范围是不一样的。
3.本节代码对于函数参数的合法性判断是极其重视的,这个规范是值得学习的。
4.本节代码中对于顺序表的操作函数,凡是外界输入的,和输出到外界的,都是void *类型的,这样就保证了只有在这些操作函数中才能去改变 描述顺序表的结构体里面的值,在其他文件的函数中接受到的都是void *类型,无法直接给这个结构体中的值进行改变,这样的封装,保证了代码的安全性。
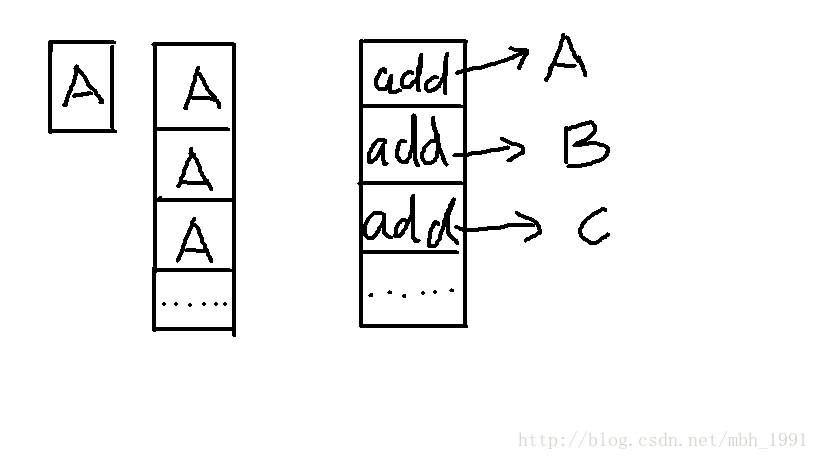
5.对于本节代码最值得思考的地方,常见的顺序表是typedef一个A类型,然后在顺序表中定义一个这个A类型的数组和length顺序表元素个数,这个顺序表中是好多个A类型的顺序集合,占用空间的大小是sizeof(A)*capacity。而本节的顺序表中是好多个unsigned int *地址类型的顺序集合,表中只有地址,第一节省了顺序表的空间,第二这样可以变相的保存不同类型的数据,第三它实现了 顺序表(即数据结构) 和 我们打算利用的数据(即元素)的分离。例如:linux内核链表(一个双向循环链表)就是一套单独的链表体制,这个链表用在很多机制上面,它就是变相的存储了好多类型的数据,并且实现了链表和数据的分离。
所以在main.c中 数据要想保存在这个顺序表中 就应该先给这些数据开辟内存 因为顺序表中没有他们呆的地方 顺序表中只能保存他们的地址。
如图:















 3844
3844











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









