消息流是storm里面的最关键的抽象。一个消息流是一个没有边界的tuple序列, 而这些tuples会被以一种
分布式的方式并行地创建和处理。 对消息流的定义主要是对消息流里面的tuple的定义, 我们会给tuple里的每个字段一个名字。 并且不同tuple的对应字段的类型必须一样。 也就是说: 两个tuple的第一个字段的类型必须一样, 第二个字段的类型必须一样, 但是第一个字段和第二个字段可以有不同的类型。 在默认的情况下, tuple的字段类型可以是: integer, long, short, byte, string, double, float, boolean和byte array。 你还可以自定义类型 — 只要你实现对应的序列化器。
更多概念可以参考:
导读:
1.Storm对流数据进行实时处理时,如何处理tuple?
2.ConcurrentLinkedQueue是否可存储tuple?
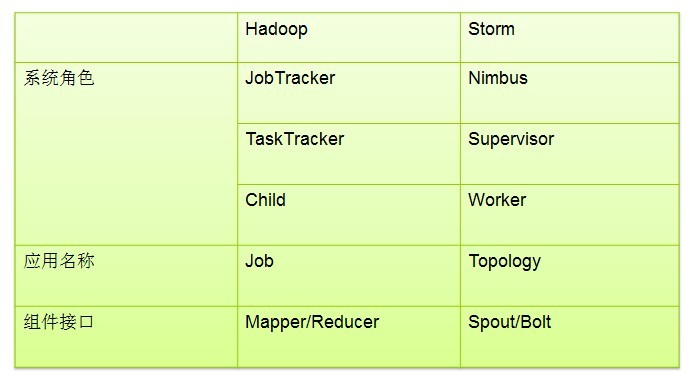
在读文章内容的时候,经常会忘掉里面的术语是什么,这里在strom中都补充一张图:
Storm对流数据进行实时处理时,一种常见场景是批量一起处理一定数量的tuple元组,而不是每接收一个tuple就立刻处理一个tuple,这样可能是性能的考虑,或者是具体业务的需要。
例如,批量查询或者更新数据库,如果每一条tuple生成一条sql执行一次数据库操作,数据量大的时候,效率会比批量处理的低很多,影响系统吞吐量。
当然,如果要使用Storm的可靠数据处理机制的话,应该使用容器将这些tuple的引用缓存到内存中,直到批量处理的时候,ack这些tuple。
下面给出一个简单的代码示例:
现在,假设我们已经有了一个DBManager数据库操作接口类,它至少有两个接口:
(1)getConnection(): 返回一个
java.sql.Connection对象;
(2)getSQL(Tuple tuple): 根据tuple元组生成
数据库操作语句。
为了在Bolt中缓存一定数量的tuple,构造Bolt时传递int n参数赋给Bolt的成员变量int count,指定每个n条tuple批量处理一次。
同时,为了在内存中缓存缓存Tuple,使用java concurrent中的ConcurrentLinkedQueue来
存储tuple,每当攒够count条tuple,就触发批量处理。
另外,考虑到数据量小(如很长时间内都没有攒够count条tuple)或者count条数设置过大时,因此,Bolt中加入了一个定时器,保证最多每个1秒钟进行一次批量处理tuple。
下面是Bolt的完整代码(仅供参考):
- import java.util.Map;
- import java.util.Queue;
- import java.util.concurrent.ConcurrentLinkedQueue;
- import java.sql.Connection;
- import java.sql.SQLException;
- import java.sql.Statement;
-
- import backtype.storm.task.OutputCollector;
- import backtype.storm.task.TopologyContext;
- import backtype.storm.topology.IRichBolt;
- import backtype.storm.topology.OutputFieldsDeclarer;
- import backtype.storm.tuple.Tuple;
-
- public class BatchingBolt implements IRichBolt {
- private static final long serialVersionUID = 1L;
- private OutputCollector collector;
- private Queue<Tuple> tupleQueue = new ConcurrentLinkedQueue<Tuple>();
- private int count;
- private long lastTime;
- private Connection conn;
-
- public BatchingBolt(int n) {
- count = n; //批量处理的Tuple记录条数
- conn = DBManger.getConnection(); //通过DBManager获取数据库连接
- lastTime = System.currentTimeMillis(); //上次批量处理的时间戳
- }
-
- @Override
- public void prepare(Map stormConf, TopologyContext context,
- OutputCollector collector) {
- this.collector = collector;
- }
-
- @Override
- public void execute(Tuple tuple) {
- tupleQueue.add(tuple);
- long currentTime = System.currentTimeMillis();
- // 每count条tuple批量提交一次,或者每个1秒钟提交一次
- if (tupleQueue.size() >= count || currentTime >= lastTime + 1000) {
- Statement stmt = conn.createStatement();
- conn.setAutoCommit(false);
- for (int i = 0; i < count; i++) {
- Tuple tup = (Tuple) tupleQueue.poll();
- String sql = DBManager.getSQL(tup); //生成sql语句
- stmt.addBatch(sql); //加入sql
- collector.ack(tup); //进行ack
- }
- stmt.executeBatch(); //批量提交sql
- conn.commit();
- conn.setAutoCommit(true);
- System.out.println("batch insert data into database, total records: " + count);
- lastTime = currentTime;
- }
- }
-
- @Override
- public void cleanup() {
- }
-
- @Override
- public void declareOutputFields(OutputFieldsDeclarer declarer) {
- }
-
- @Override
- public Map<String, Object> getComponentConfiguration() {
- // TODO Auto-generated method stub
- return null;
- }
- }
复制代码
























 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











