







20240202在Ubuntu20.04.6下使用whisper.cpp的CPU模式
2024/2/2 14:15
rootroot@rootroot-X99-Turbo:~/whisper.cpp$ ./main -l zh -osrt -m models/ggml-medium.bin chs.wav
在纯CPU模式下,使用medium中等模型,7分钟的中文视频需要851829.69 ms,也就是852s,大概14分钟+。
https://github.com/ggerganov/whisper.cpp/tree/master/models
https://github.com/ggerganov/whisper.cpp
ggerganov/whisper.cpp
https://blog.csdn.net/aiyolo/article/details/129674728?share_token=2c48b804-37f6-43a8-9159-08b28147ad67
Whisper.cpp 编译使用
whisper.cpp 是牛人 ggerganov 对 openai 的 whisper 语音识别模型用 C++ 重新实现的项目,开源在 github 上,具有轻量、性能高,实用性强等特点。这篇文章主要记录在 windows 平台,如何使用该模型在本地端进行语音识别。
whisper.cpp 的开源地址在 ggerganov/whisper.cpp: Port of OpenAI’s Whisper model in C/C++ (github.com),首先将项目下载在本地。
git clone https://github.com/ggerganov/whisper.cpp
whisper.cpp 项目里提供了几个现成的模型。建议下载 small 以上的模型,不然识别效果完全无法使用。
https://huggingface.co/ggerganov/whisper.cpp
ggerganov/whisper.cpp
OpenAI's Whisper models converted to ggml format
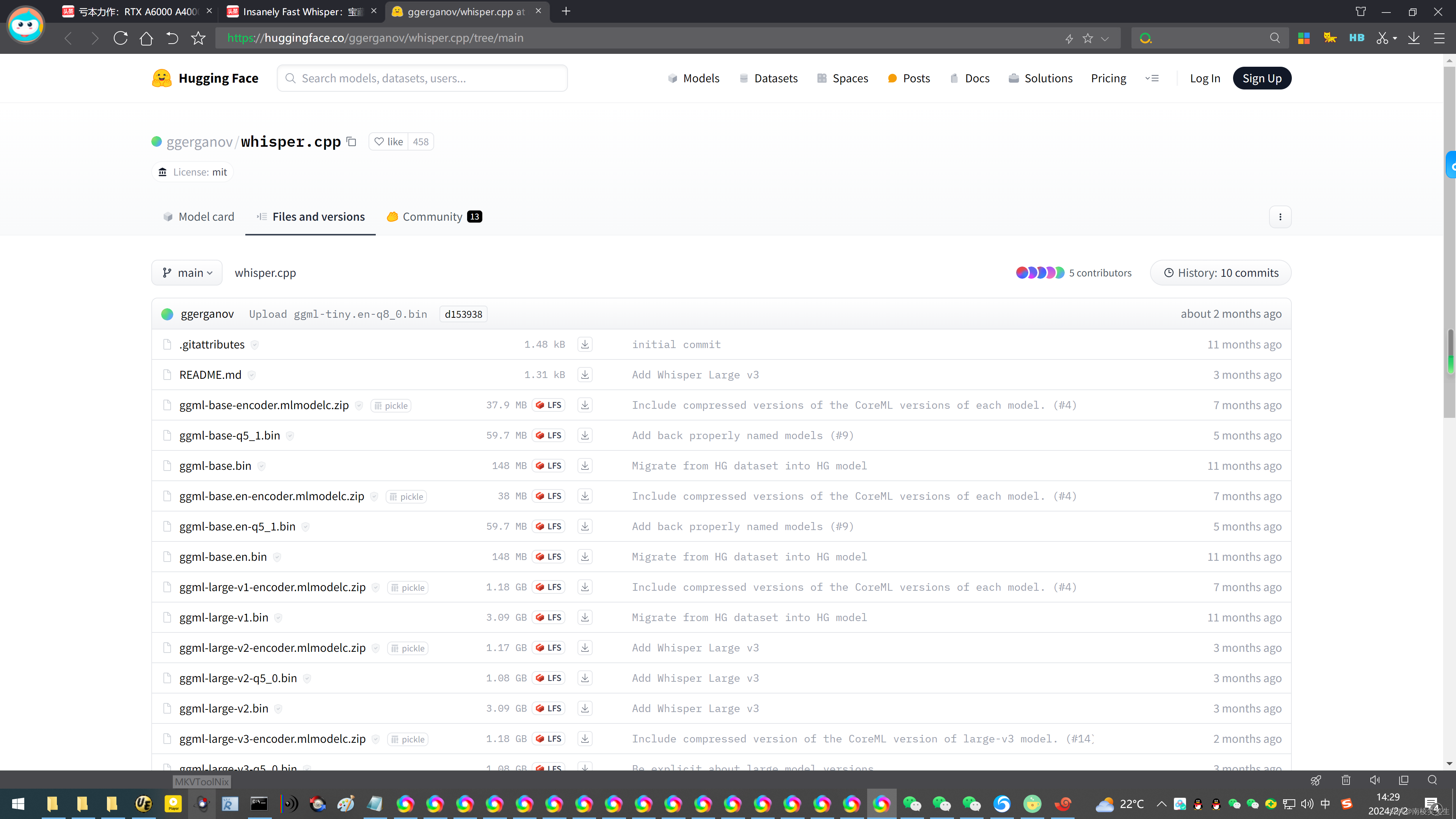
Available models
Model Disk Mem SHA
tiny 75 MB ~390 MB bd577a113a864445d4c299885e0cb97d4ba92b5f
tiny.en 75 MB ~390 MB c78c86eb1a8faa21b369bcd33207cc90d64ae9df
base 142 MB ~500 MB 465707469ff3a37a2b9b8d8f89f2f99de7299dac
base.en 142 MB ~500 MB 137c40403d78fd54d454da0f9bd998f78703390c
small 466 MB ~1.0 GB 55356645c2b361a969dfd0ef2c5a50d530afd8d5
small.en 466 MB ~1.0 GB db8a495a91d927739e50b3fc1cc4c6b8f6c2d022
medium 1.5 GB ~2.6 GB fd9727b6e1217c2f614f9b698455c4ffd82463b4
medium.en 1.5 GB ~2.6 GB 8c30f0e44ce9560643ebd10bbe50cd20eafd3723
large-v1 2.9 GB ~4.7 GB b1caaf735c4cc1429223d5a74f0f4d0b9b59a299
large-v2 2.9 GB ~4.7 GB 0f4c8e34f21cf1a914c59d8b3ce882345ad349d6
large 2.9 GB ~4.7 GB ad82bf6a9043ceed055076d0fd39f5f186ff8062
note: large corresponds to the latest Large v3 model
For more information, visit:
https://github.com/ggerganov/whisper.cpp/tree/master/models
https://huggingface.co/ggerganov/whisper.cpp/tree/main
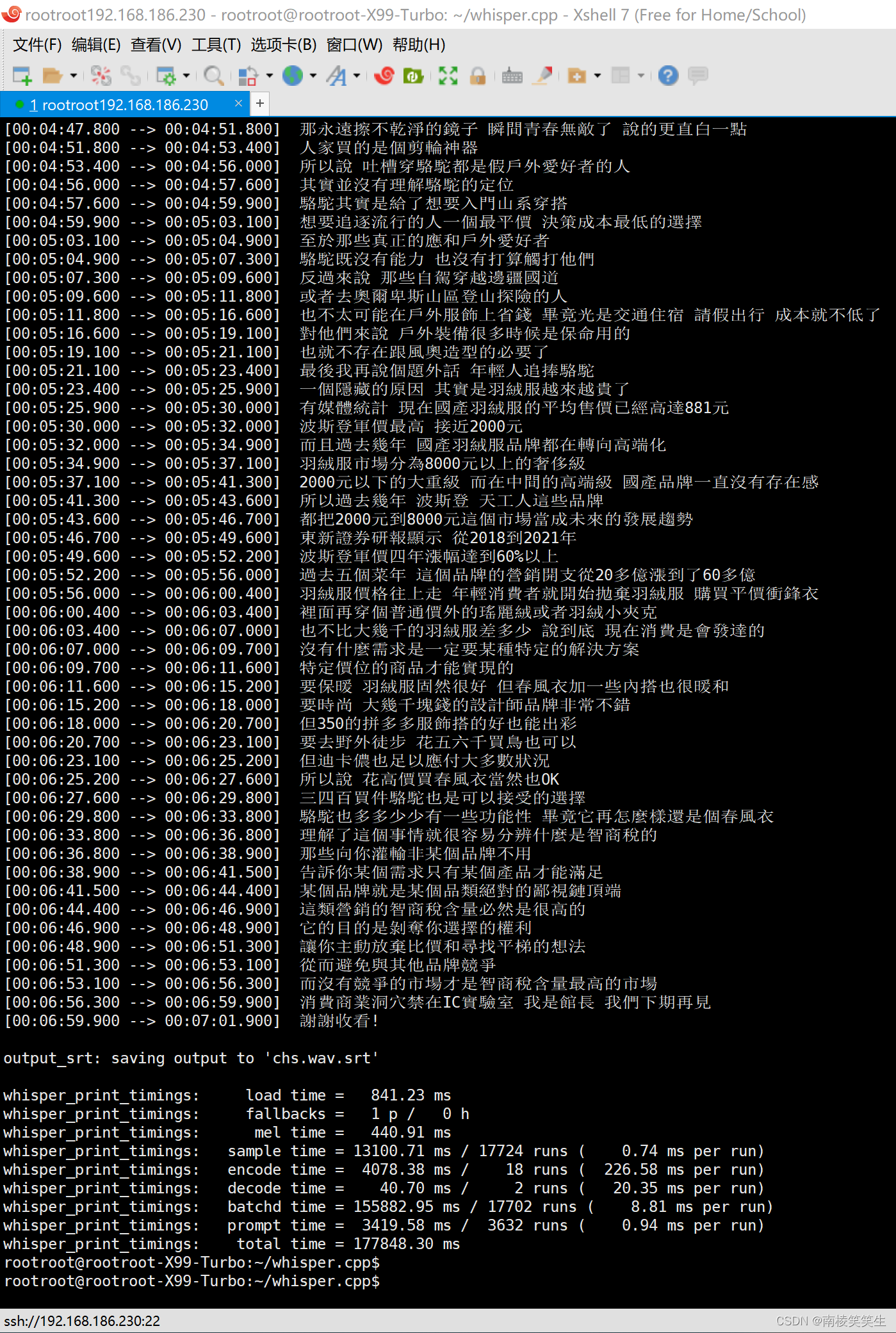
【结论:在Ubuntu20.04.6下,确认large模式识别7分钟中文视频,需要356447.78 ms,也就是356.5秒,需要大概5分钟!效率太差!】
前提条件,可以通过技术手段上外网!^_
首先你要有一张NVIDIA的显卡,比如我用的PDD拼多多的二手GTX1080显卡。【并且极其可能是矿卡!】800¥
2、请正确安装好NVIDIA最新的545版本的驱动程序和CUDA、cuDNN。
2、安装Torch
3、配置whisper
https://github.com/ggerganov/whisper.cpp
https://www.toutiao.com/article/7276732434920653312/?app=news_article×tamp=1706802934&use_new_style=1&req_id=2024020123553463D3509B1706BC79D479&group_id=7276732434920653312&tt_from=mobile_qq&utm_source=mobile_qq&utm_medium=toutiao_android&utm_campaign=client_share&share_token=7bcb7488-a03d-4291-96fb-d0835ac76cca&source=m_redirect
https://www.toutiao.com/article/7276732434920653312/
OpenAI的whisper的c/c++ 版本体验
首先下载代码,注:我的OS环境是Ubuntu20.04.6。
git clone https://github.com/ggerganov/whisper.cpp
下载成功后进入项目目录:
cd whisper.cpp
执行如下脚本命令下载模型,这里选择的base 版本,我们先来测试英语识别:
bash ./models/download-ggml-model.sh base.en
但是尝试了几次都无法下载成功,报错消息如下:
网上search 了一下,找到可提供下载的链接:
https://github.com/ggerganov/whisper.cpp/tree/master/models
https://huggingface.co/ggerganov/whisper.cpp/tree/main
我选择下载全部35个文件!
下载成功后将模型文件copy 到项目中的models目录:
cp ~/Downloads/ggml-base.en.gin /home/havelet/ai/whisper.cpp/models
接下来执行如下编译命令:
rootroot@rootroot-X99-Turbo:~/whisper.cpp$ make
rootroot@rootroot-X99-Turbo:~/whisper.cpp$
执行结果如下:
rootroot@rootroot-X99-Turbo:~/whisper.cpp$ make
I whisper.cpp build info:
I UNAME_S: Linux
I UNAME_P: x86_64
I UNAME_M: x86_64
I CFLAGS: -I. -O3 -DNDEBUG -std=c11 -fPIC -D_XOPEN_SOURCE=600 -D_GNU_SOURCE -pthread -mavx -mavx2 -mfma -mf16c -msse3 -mssse3
I CXXFLAGS: -I. -I./examples -O3 -DNDEBUG -std=c++11 -fPIC -D_XOPEN_SOURCE=600 -D_GNU_SOURCE -pthread -mavx -mavx2 -mfma -mf16c -msse3 -mssse3
I LDFLAGS:
I CC: cc (Ubuntu 9.4.0-1ubuntu1~20.04.2) 9.4.0
I CXX: g++ (Ubuntu 9.4.0-1ubuntu1~20.04.2) 9.4.0
cc -I. -O3 -DNDEBUG -std=c11 -fPIC -D_XOPEN_SOURCE=600 -D_GNU_SOURCE -pthread -mavx -mavx2 -mfma -mf16c -msse3 -mssse3 -c ggml.c -o ggml.o
cc -I. -O3 -DNDEBUG -std=c11 -fPIC -D_XOPEN_SOURCE=600 -D_GNU_SOURCE -pthread -mavx -mavx2 -mfma -mf16c -msse3 -mssse3 -c ggml-alloc.c -o ggml-alloc.o
cc -I. -O3 -DNDEBUG -std=c11 -fPIC -D_XOPEN_SOURCE=600 -D_GNU_SOURCE -pthread -mavx -mavx2 -mfma -mf16c -msse3 -mssse3 -c ggml-backend.c -o ggml-backend.o
cc -I. -O3 -DNDEBUG -std=c11 -fPIC -D_XOPEN_SOURCE=600 -D_GNU_SOURCE -pthread -mavx -mavx2 -mfma -mf16c -msse3 -mssse3 -c ggml-quants.c -o ggml-quants.o
g++ -I. -I./examples -O3 -DNDEBUG -std=c++11 -fPIC -D_XOPEN_SOURCE=600 -D_GNU_SOURCE -pthread -mavx -mavx2 -mfma -mf16c -msse3 -mssse3 -c whisper.cpp -o whisper.o
g++ -I. -I./examples -O3 -DNDEBUG -std=c++11 -fPIC -D_XOPEN_SOURCE=600 -D_GNU_SOURCE -pthread -mavx -mavx2 -mfma -mf16c -msse3 -mssse3 examples/main/main.cpp examples/common.cpp examples/common-ggml.cpp ggml.o ggml-alloc.o ggml-backend.o ggml-quants.o whisper.o -o main
./main -h
usage: ./main [options] file0.wav file1.wav ...
options:
-h, --help [default] show this help message and exit
-t N, --threads N [4 ] number of threads to use during computation
-p N, --processors N [1 ] number of processors to use during computation
-ot N, --offset-t N [0 ] time offset in milliseconds
-on N, --offset-n N [0 ] segment index offset
-d N, --duration N [0 ] duration of audio to process in milliseconds
-mc N, --max-context N [-1 ] maximum number of text context tokens to store
-ml N, --max-len N [0 ] maximum segment length in characters
-sow, --split-on-word [false ] split on word rather than on token
-bo N, --best-of N [5 ] number of best candidates to keep
-bs N, --beam-size N [5 ] beam size for beam search
-wt N, --word-thold N [0.01 ] word timestamp probability threshold
-et N, --entropy-thold N [2.40 ] entropy threshold for decoder fail
-lpt N, --logprob-thold N [-1.00 ] log probability threshold for decoder fail
-debug, --debug-mode [false ] enable debug mode (eg. dump log_mel)
-tr, --translate [false ] translate from source language to english
-di, --diarize [false ] stereo audio diarization
-tdrz, --tinydiarize [false ] enable tinydiarize (requires a tdrz model)
-nf, --no-fallback [false ] do not use temperature fallback while decoding
-otxt, --output-txt [false ] output result in a text file
-ovtt, --output-vtt [false ] output result in a vtt file
-osrt, --output-srt [false ] output result in a srt file
-olrc, --output-lrc [false ] output result in a lrc file
-owts, --output-words [false ] output script for generating karaoke video
-fp, --font-path [/System/Library/Fonts/Supplemental/Courier New Bold.ttf] path to a monospace font for karaoke video
-ocsv, --output-csv [false ] output result in a CSV file
-oj, --output-json [false ] output result in a JSON file
-ojf, --output-json-full [false ] include more information in the JSON file
-of FNAME, --output-file FNAME [ ] output file path (without file extension)
-np, --no-prints [false ] do not print anything other than the results
-ps, --print-special [false ] print special tokens
-pc, --print-colors [false ] print colors
-pp, --print-progress [false ] print progress
-nt, --no-timestamps [false ] do not print timestamps
-l LANG, --language LANG [en ] spoken language ('auto' for auto-detect)
-dl, --detect-language [false ] exit after automatically detecting language
--prompt PROMPT [ ] initial prompt
-m FNAME, --model FNAME [models/ggml-base.en.bin] model path
-f FNAME, --file FNAME [ ] input WAV file path
-oved D, --ov-e-device DNAME [CPU ] the OpenVINO device used for encode inference
-ls, --log-score [false ] log best decoder scores of tokens
-ng, --no-gpu [false ] disable GPU
g++ -I. -I./examples -O3 -DNDEBUG -std=c++11 -fPIC -D_XOPEN_SOURCE=600 -D_GNU_SOURCE -pthread -mavx -mavx2 -mfma -mf16c -msse3 -mssse3 examples/bench/bench.cpp ggml.o ggml-alloc.o ggml-backend.o ggml-quants.o whisper.o -o bench
g++ -I. -I./examples -O3 -DNDEBUG -std=c++11 -fPIC -D_XOPEN_SOURCE=600 -D_GNU_SOURCE -pthread -mavx -mavx2 -mfma -mf16c -msse3 -mssse3 examples/quantize/quantize.cpp examples/common.cpp examples/common-ggml.cpp ggml.o ggml-alloc.o ggml-backend.o ggml-quants.o whisper.o -o quantize
g++ -I. -I./examples -O3 -DNDEBUG -std=c++11 -fPIC -D_XOPEN_SOURCE=600 -D_GNU_SOURCE -pthread -mavx -mavx2 -mfma -mf16c -msse3 -mssse3 examples/server/server.cpp examples/common.cpp examples/common-ggml.cpp ggml.o ggml-alloc.o ggml-backend.o ggml-quants.o whisper.o -o server
rootroot@rootroot-X99-Turbo:~/whisper.cpp$
编译成功后,则可以执行测试程序,首先执行自带测试音频:【英文】
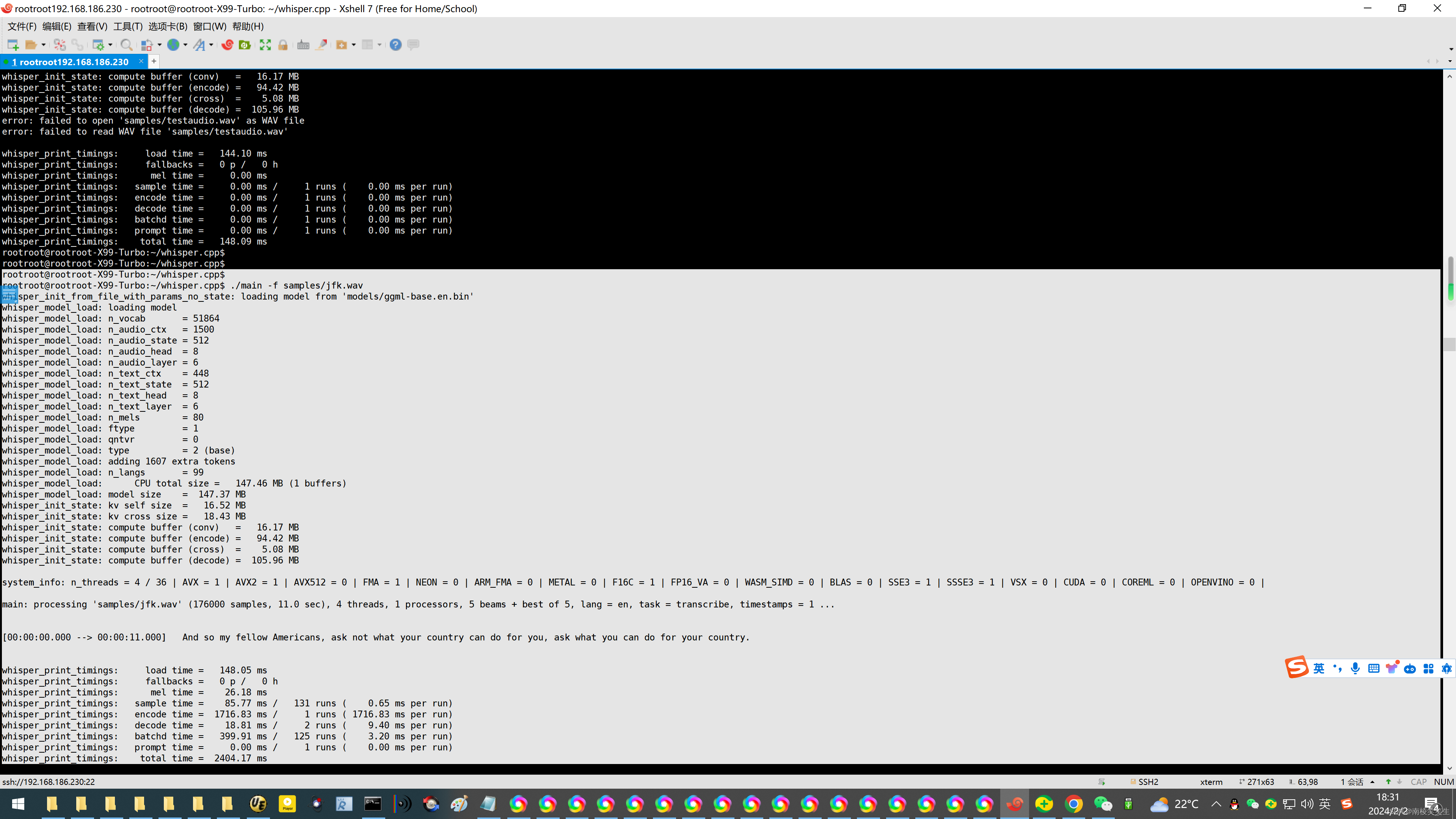
./main -f samples/jfk.wav
执行结果如下,我们可看到识别结果正确:
rootroot@rootroot-X99-Turbo:~/whisper.cpp$
rootroot@rootroot-X99-Turbo:~/whisper.cpp$ ./main -f samples/jfk.wav
whisper_init_from_file_with_params_no_state: loading model from 'models/ggml-base.en.bin'
whisper_model_load: loading model
whisper_model_load: n_vocab = 51864
whisper_model_load: n_audio_ctx = 1500
whisper_model_load: n_audio_state = 512
whisper_model_load: n_audio_head = 8
whisper_model_load: n_audio_layer = 6
whisper_model_load: n_text_ctx = 448
whisper_model_load: n_text_state = 512
whisper_model_load: n_text_head = 8
whisper_model_load: n_text_layer = 6
whisper_model_load: n_mels = 80
whisper_model_load: ftype = 1
whisper_model_load: qntvr = 0
whisper_model_load: type = 2 (base)
whisper_model_load: adding 1607 extra tokens
whisper_model_load: n_langs = 99
whisper_model_load: CPU total size = 147.46 MB (1 buffers)
whisper_model_load: model size = 147.37 MB
whisper_init_state: kv self size = 16.52 MB
whisper_init_state: kv cross size = 18.43 MB
whisper_init_state: compute buffer (conv) = 16.17 MB
whisper_init_state: compute buffer (encode) = 94.42 MB
whisper_init_state: compute buffer (cross) = 5.08 MB
whisper_init_state: compute buffer (decode) = 105.96 MB
system_info: n_threads = 4 / 36 | AVX = 1 | AVX2 = 1 | AVX512 = 0 | FMA = 1 | NEON = 0 | ARM_FMA = 0 | METAL = 0 | F16C = 1 | FP16_VA = 0 | WASM_SIMD = 0 | BLAS = 0 | SSE3 = 1 | SSSE3 = 1 | VSX = 0 | CUDA = 0 | COREML = 0 | OPENVINO = 0 |
main: processing 'samples/jfk.wav' (176000 samples, 11.0 sec), 4 threads, 1 processors, 5 beams + best of 5, lang = en, task = transcribe, timestamps = 1 ...
[00:00:00.000 --> 00:00:11.000] And so my fellow Americans, ask not what your country can do for you, ask what you can do for your country.
whisper_print_timings: load time = 148.05 ms
whisper_print_timings: fallbacks = 0 p / 0 h
whisper_print_timings: mel time = 26.18 ms
whisper_print_timings: sample time = 85.77 ms / 131 runs ( 0.65 ms per run)
whisper_print_timings: encode time = 1716.83 ms / 1 runs ( 1716.83 ms per run)
whisper_print_timings: decode time = 18.81 ms / 2 runs ( 9.40 ms per run)
whisper_print_timings: batchd time = 399.91 ms / 125 runs ( 3.20 ms per run)
whisper_print_timings: prompt time = 0.00 ms / 1 runs ( 0.00 ms per run)
whisper_print_timings: total time = 2404.17 ms
rootroot@rootroot-X99-Turbo:~/whisper.cpp$
rootroot@rootroot-X99-Turbo:~/whisper.cpp$
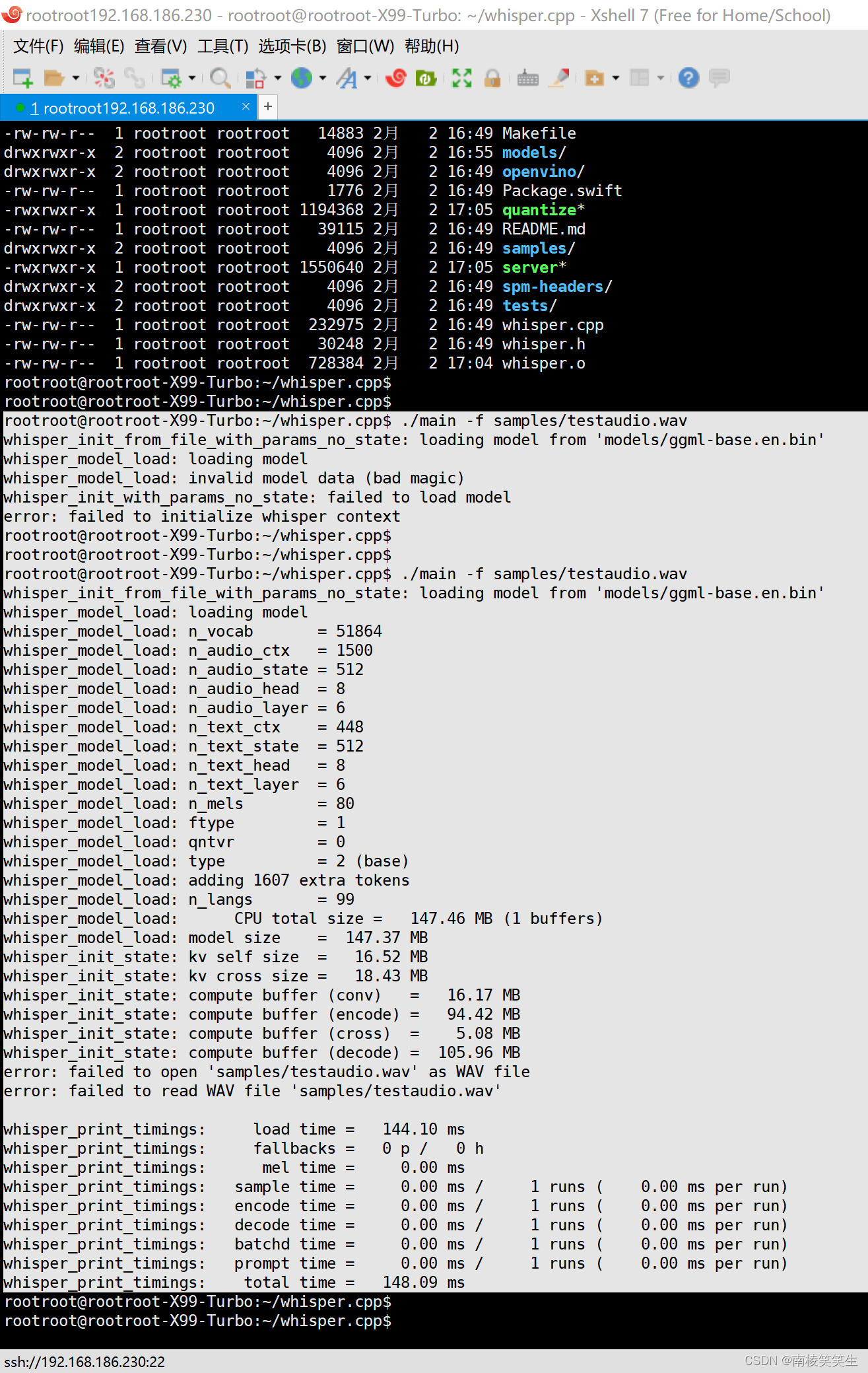
rootroot@rootroot-X99-Turbo:~/whisper.cpp$ ./main -m ./models/ggml-base.en.bin -f ./samples/jfk.wav -ml 16
whisper_init_from_file_with_params_no_state: loading model from './models/ggml-base.en.bin'
whisper_model_load: loading model
whisper_model_load: n_vocab = 51864
whisper_model_load: n_audio_ctx = 1500
whisper_model_load: n_audio_state = 512
whisper_model_load: n_audio_head = 8
whisper_model_load: n_audio_layer = 6
whisper_model_load: n_text_ctx = 448
whisper_model_load: n_text_state = 512
whisper_model_load: n_text_head = 8
whisper_model_load: n_text_layer = 6
whisper_model_load: n_mels = 80
whisper_model_load: ftype = 1
whisper_model_load: qntvr = 0
whisper_model_load: type = 2 (base)
whisper_model_load: adding 1607 extra tokens
whisper_model_load: n_langs = 99
whisper_model_load: CPU total size = 147.46 MB (1 buffers)
whisper_model_load: model size = 147.37 MB
whisper_init_state: kv self size = 16.52 MB
whisper_init_state: kv cross size = 18.43 MB
whisper_init_state: compute buffer (conv) = 16.17 MB
whisper_init_state: compute buffer (encode) = 94.42 MB
whisper_init_state: compute buffer (cross) = 5.08 MB
whisper_init_state: compute buffer (decode) = 105.96 MB
system_info: n_threads = 4 / 36 | AVX = 1 | AVX2 = 1 | AVX512 = 0 | FMA = 1 | NEON = 0 | ARM_FMA = 0 | METAL = 0 | F16C = 1 | FP16_VA = 0 | WASM_SIMD = 0 | BLAS = 0 | SSE3 = 1 | SSSE3 = 1 | VSX = 0 | CUDA = 0 | COREML = 0 | OPENVINO = 0 |
main: processing './samples/jfk.wav' (176000 samples, 11.0 sec), 4 threads, 1 processors, 5 beams + best of 5, lang = en, task = transcribe, timestamps = 1 ...
[00:00:00.000 --> 00:00:00.850] And so my
[00:00:00.850 --> 00:00:01.590] fellow
[00:00:01.590 --> 00:00:04.140] Americans, ask
[00:00:04.140 --> 00:00:05.740] not what your
[00:00:05.740 --> 00:00:07.000] country can do
[00:00:07.000 --> 00:00:08.370] for you, ask
[00:00:08.370 --> 00:00:09.440] what you can do
[00:00:09.440 --> 00:00:10.020] for your
[00:00:10.020 --> 00:00:11.000] country.
whisper_print_timings: load time = 146.52 ms
whisper_print_timings: fallbacks = 0 p / 0 h
whisper_print_timings: mel time = 27.35 ms
whisper_print_timings: sample time = 87.86 ms / 131 runs ( 0.67 ms per run)
whisper_print_timings: encode time = 1829.62 ms / 1 runs ( 1829.62 ms per run)
whisper_print_timings: decode time = 20.76 ms / 2 runs ( 10.38 ms per run)
whisper_print_timings: batchd time = 401.02 ms / 125 runs ( 3.21 ms per run)
whisper_print_timings: prompt time = 0.00 ms / 1 runs ( 0.00 ms per run)
whisper_print_timings: total time = 2550.71 ms
rootroot@rootroot-X99-Turbo:~/whisper.cpp$
rootroot@rootroot-X99-Turbo:~/whisper.cpp$
rootroot@rootroot-X99-Turbo:~/whisper.cpp$ ffmpeg -i chs.mp4 -ar 16000 -ac 1 -c:a pcm_s16le chs.wav
ffmpeg version 4.2.7-0ubuntu0.1 Copyright (c) 2000-2022 the FFmpeg developers
built with gcc 9 (Ubuntu 9.4.0-1ubuntu1~20.04.1)
configuration: --prefix=/usr --extra-version=0ubuntu0.1 --toolchain=hardened --libdir=/usr/lib/x86_64-linux-gnu --incdir=/usr/include/x86_64-linux-gnu --arch=amd64 --enable-gpl --disable-stripping --enable-avresample --disable-filter=resample --enable-avisynth --enable-gnutls --enable-ladspa --enable-libaom --enable-libass --enable-libbluray --enable-libbs2b --enable-libcaca --enable-libcdio --enable-libcodec2 --enable-libflite --enable-libfontconfig --enable-libfreetype --enable-libfribidi --enable-libgme --enable-libgsm --enable-libjack --enable-libmp3lame --enable-libmysofa --enable-libopenjpeg --enable-libopenmpt --enable-libopus --enable-libpulse --enable-librsvg --enable-librubberband --enable-libshine --enable-libsnappy --enable-libsoxr --enable-libspeex --enable-libssh --enable-libtheora --enable-libtwolame --enable-libvidstab --enable-libvorbis --enable-libvpx --enable-libwavpack --enable-libwebp --enable-libx265 --enable-libxml2 --enable-libxvid --enable-libzmq --enable-libzvbi --enable-lv2 --enable-omx --enable-openal --enable-opencl --enable-opengl --enable-sdl2 --enable-libdc1394 --enable-libdrm --enable-libiec61883 --enable-nvenc --enable-chromaprint --enable-frei0r --enable-libx264 --enable-shared
libavutil 56. 31.100 / 56. 31.100
libavcodec 58. 54.100 / 58. 54.100
libavformat 58. 29.100 / 58. 29.100
libavdevice 58. 8.100 / 58. 8.100
libavfilter 7. 57.100 / 7. 57.100
libavresample 4. 0. 0 / 4. 0. 0
libswscale 5. 5.100 / 5. 5.100
libswresample 3. 5.100 / 3. 5.100
libpostproc 55. 5.100 / 55. 5.100
Input #0, mov,mp4,m4a,3gp,3g2,mj2, from 'chs.mp4':
Metadata:
major_brand : isom
minor_version : 512
compatible_brands: isomiso2avc1mp41iso5
comment : vid:v0d004g10000cmbmsrjc77ubc8r79ssg
encoder : Lavf58.76.100
Duration: 00:07:01.78, start: -0.042667, bitrate: 65 kb/s
Stream #0:0(und): Audio: aac (LC) (mp4a / 0x6134706D), 48000 Hz, stereo, fltp, 64 kb/s (default)
Metadata:
handler_name : Bento4 Sound Handler
Stream mapping:
Stream #0:0 -> #0:0 (aac (native) -> pcm_s16le (native))
Press [q] to stop, [?] for help
Output #0, wav, to 'chs.wav':
Metadata:
major_brand : isom
minor_version : 512
compatible_brands: isomiso2avc1mp41iso5
ICMT : vid:v0d004g10000cmbmsrjc77ubc8r79ssg
ISFT : Lavf58.29.100
Stream #0:0(und): Audio: pcm_s16le ([1][0][0][0] / 0x0001), 16000 Hz, mono, s16, 256 kb/s (default)
Metadata:
handler_name : Bento4 Sound Handler
encoder : Lavc58.54.100 pcm_s16le
size= 13181kB time=00:07:01.78 bitrate= 256.0kbits/s speed= 645x
video:0kB audio:13181kB subtitle:0kB other streams:0kB global headers:0kB muxing overhead: 0.000919%
rootroot@rootroot-X99-Turbo:~/whisper.cpp$
rootroot@rootroot-X99-Turbo:~/whisper.cpp$ ll *.wav
-rw-rw-r-- 1 rootroot rootroot 13497126 2月 2 17:26 chs.wav
rootroot@rootroot-X99-Turbo:~/whisper.cpp$
rootroot@rootroot-X99-Turbo:~/whisper.cpp$
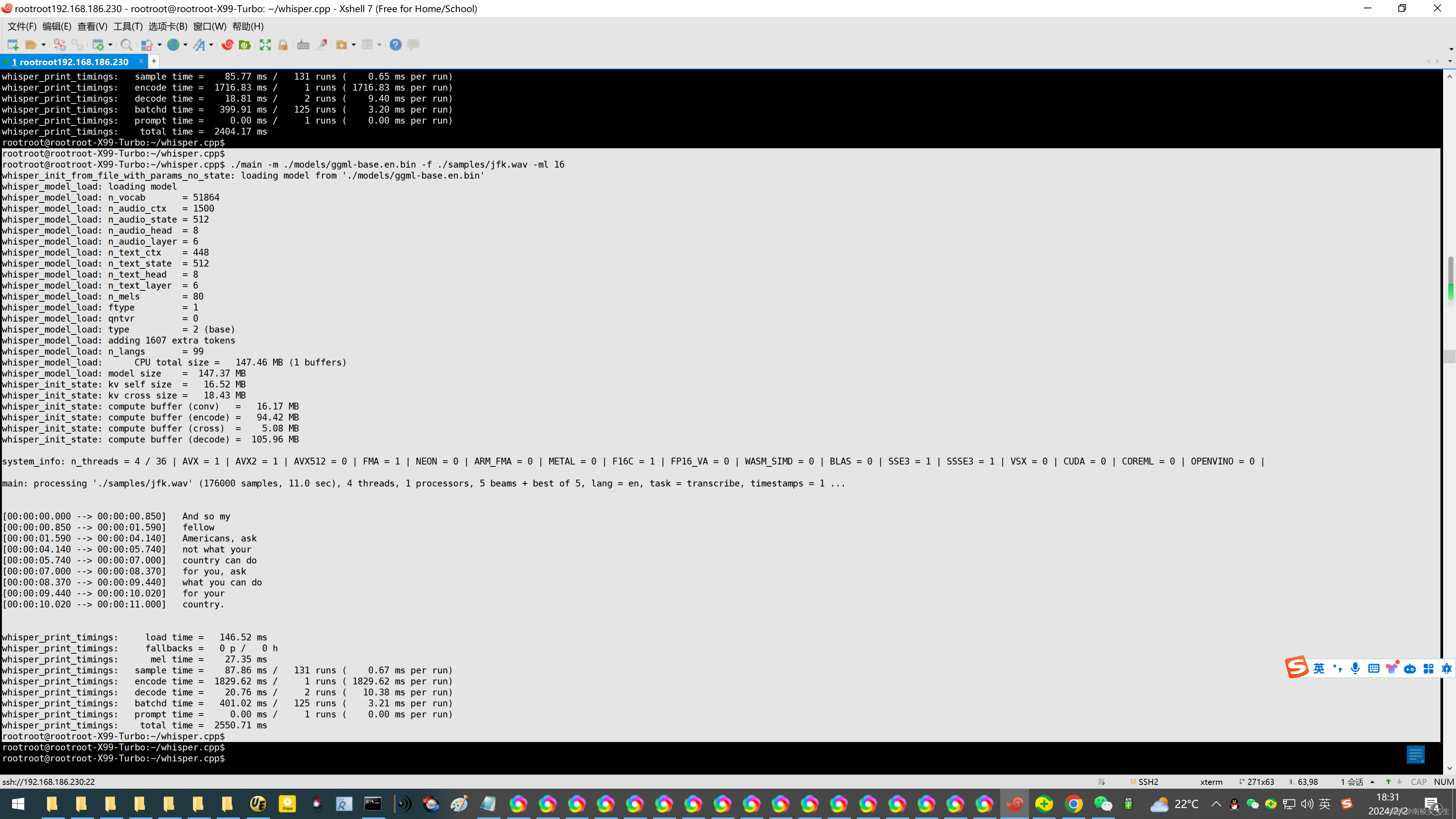
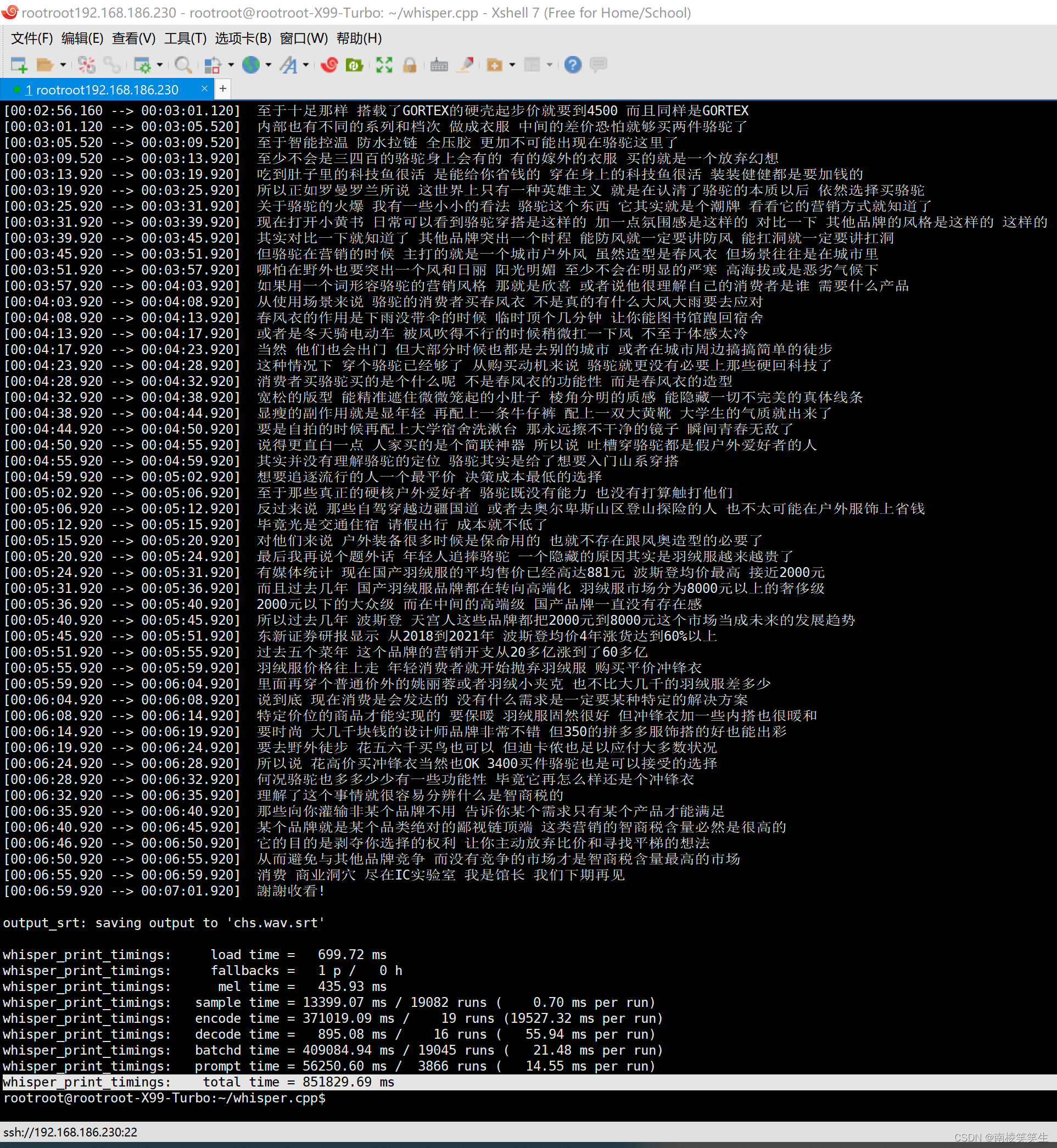
rootroot@rootroot-X99-Turbo:~/whisper.cpp$ ./main -l zh -osrt -m models/ggml-medium.bin chs.wav
whisper_init_from_file_with_params_no_state: loading model from 'models/ggml-medium.bin'
whisper_model_load: loading model
whisper_model_load: n_vocab = 51865
whisper_model_load: n_audio_ctx = 1500
whisper_model_load: n_audio_state = 1024
whisper_model_load: n_audio_head = 16
whisper_model_load: n_audio_layer = 24
whisper_model_load: n_text_ctx = 448
whisper_model_load: n_text_state = 1024
whisper_model_load: n_text_head = 16
whisper_model_load: n_text_layer = 24
whisper_model_load: n_mels = 80
whisper_model_load: ftype = 1
whisper_model_load: qntvr = 0
whisper_model_load: type = 4 (medium)
whisper_model_load: adding 1608 extra tokens
whisper_model_load: n_langs = 99
whisper_model_load: CPU total size = 1533.52 MB (2 buffers)
whisper_model_load: model size = 1533.14 MB
whisper_init_state: kv self size = 132.12 MB
whisper_init_state: kv cross size = 147.46 MB
whisper_init_state: compute buffer (conv) = 28.00 MB
whisper_init_state: compute buffer (encode) = 187.14 MB
whisper_init_state: compute buffer (cross) = 8.46 MB
whisper_init_state: compute buffer (decode) = 107.98 MB
system_info: n_threads = 4 / 36 | AVX = 1 | AVX2 = 1 | AVX512 = 0 | FMA = 1 | NEON = 0 | ARM_FMA = 0 | METAL = 0 | F16C = 1 | FP16_VA = 0 | WASM_SIMD = 0 | BLAS = 0 | SSE3 = 1 | SSSE3 = 1 | VSX = 0 | CUDA = 0 | COREML = 0 | OPENVINO = 0 |
main: processing 'chs.wav' (6748501 samples, 421.8 sec), 4 threads, 1 processors, 5 beams + best of 5, lang = zh, task = transcribe, timestamps = 1 ...
[00:00:00.000 --> 00:00:01.520] 前段时间有个巨石横虎
[00:00:01.520 --> 00:00:03.040] 某某是男人最好的义妹
[00:00:03.040 --> 00:00:04.800] 这里的某某可以替换为减肥
[00:00:04.800 --> 00:00:07.760] 长发 西装 考研 书唱 永洁无间等等等等
[00:00:07.760 --> 00:00:09.280] 我听到最新的一个说法是
[00:00:09.280 --> 00:00:12.000] 微分碎盖加口罩加半框眼镜加春风衣
[00:00:12.000 --> 00:00:13.360] 等于男人最好的义妹
[00:06:28.920 --> 00:06:32.920] 何况骆驼也多多少少有一些功能性 毕竟它再怎么样还是个冲锋衣
[00:06:32.920 --> 00:06:35.920] 理解了这个事情就很容易分辨什么是智商税的
[00:06:35.920 --> 00:06:40.920] 那些向你灌输非某个品牌不用 告诉你某个需求只有某个产品才能满足
[00:06:40.920 --> 00:06:45.920] 某个品牌就是某个品类绝对的鄙视链顶端 这类营销的智商税含量必然是很高的
[00:06:46.920 --> 00:06:50.920] 它的目的是剥夺你选择的权利 让你主动放弃比价和寻找平梯的想法
[00:06:50.920 --> 00:06:55.920] 从而避免与其他品牌竞争 而没有竞争的市场才是智商税含量最高的市场
[00:06:55.920 --> 00:06:59.920] 消费 商业洞穴 尽在IC实验室 我是馆长 我们下期再见
[00:06:59.920 --> 00:07:01.920] 謝謝收看!
output_srt: saving output to 'chs.wav.srt'
whisper_print_timings: load time = 699.72 ms
whisper_print_timings: fallbacks = 1 p / 0 h
whisper_print_timings: mel time = 435.93 ms
whisper_print_timings: sample time = 13399.07 ms / 19082 runs ( 0.70 ms per run)
whisper_print_timings: encode time = 371019.09 ms / 19 runs (19527.32 ms per run)
whisper_print_timings: decode time = 895.08 ms / 16 runs ( 55.94 ms per run)
whisper_print_timings: batchd time = 409084.94 ms / 19045 runs ( 21.48 ms per run)
whisper_print_timings: prompt time = 56250.60 ms / 3866 runs ( 14.55 ms per run)
whisper_print_timings: total time = 851829.69 ms
rootroot@rootroot-X99-Turbo:~/whisper.cpp$
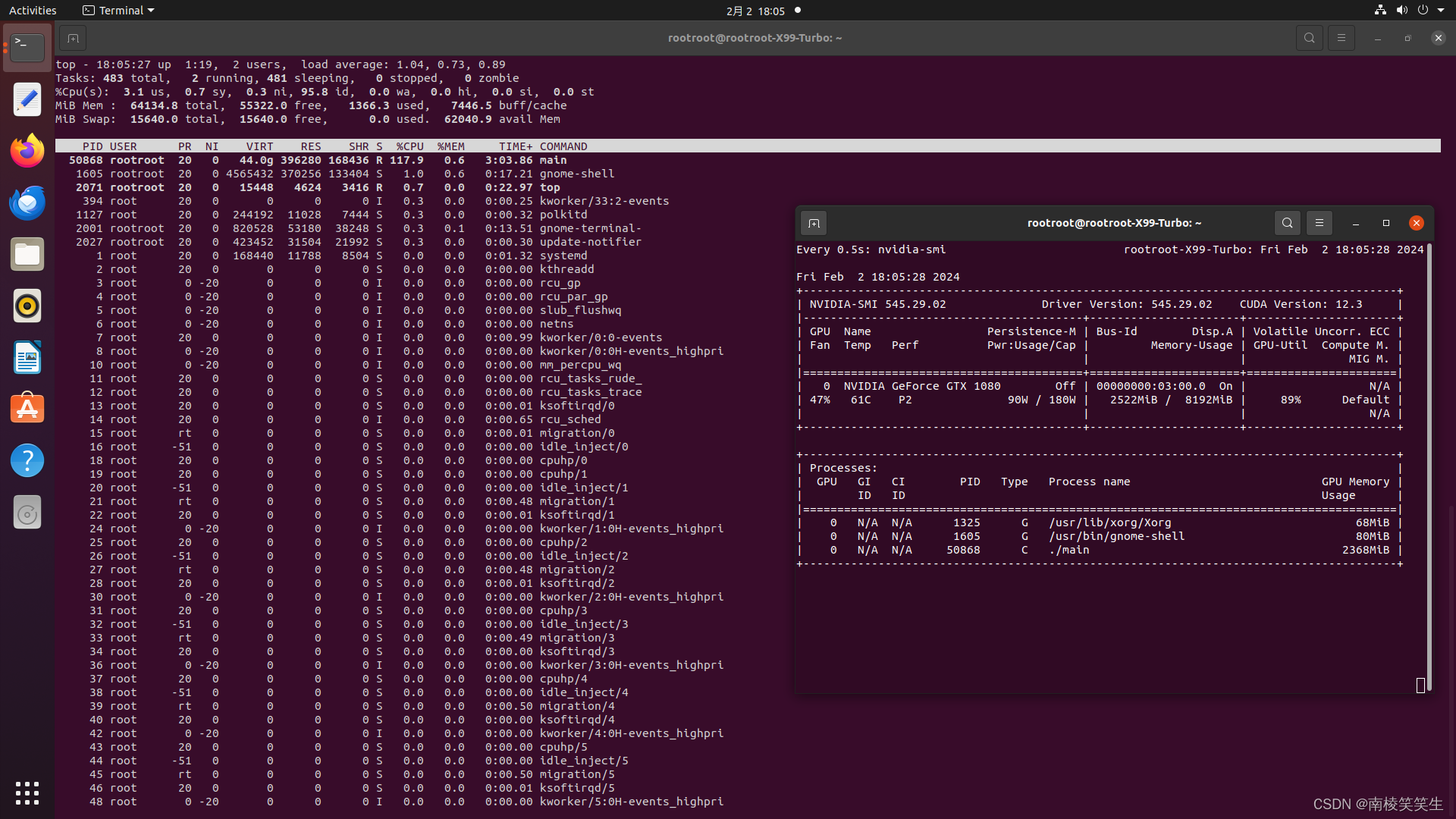
中等模式下的显存占用:
参考资料:
https://www.toutiao.com/article/7225218604160418338/?app=news_article×tamp=1706803458&use_new_style=1&req_id=2024020200041726E9258609E554857D25&group_id=7225218604160418338&tt_from=mobile_qq&utm_source=mobile_qq&utm_medium=toutiao_android&utm_campaign=client_share&share_token=37e094d5-29b8-4d14-87bb-241cdc28b0ea&source=m_redirect
AI浪潮下的12大开源神器介绍
原创2023-04-23 20:33·IT小熊实验室丶
https://blog.csdn.net/sinat_18131557/article/details/130950719?share_token=25ca6bb5-8450-472c-9228-abc8c6ce74d8
whisper.cpp在Windows VS的编译
sinat_18131557 于 2023-05-30 16:03:53 发布
https://www.toutiao.com/article/7283079784329052726/?app=news_article×tamp=1706803297&use_new_style=1&req_id=20240202000137411974769524167990E0&group_id=7283079784329052726&tt_from=mobile_qq&utm_source=mobile_qq&utm_medium=toutiao_android&utm_campaign=client_share&share_token=b7961b29-d87a-4b6c-bb8e-c7c213388390&source=m_redirect
【往期回顾】Github开源项目月刊精选-2023年8月
原创2023-09-27 08:30·Github推荐官
https://blog.csdn.net/weixin_45533131/article/details/132817683?share_token=72d8a161-4d49-4795-ad21-2ce5e2e4b197
在Linux(Centos7)上编译whisper.cpp的详细教程
https://github.com/Const-me/Whisper/releases
https://www.cnblogs.com/jike9527/p/17545484.html?share_token=5af4092d-5b67-4e52-8231-0ae220fd2185
使用whisper批量生成字幕(whisper.cpp)
https://blog.csdn.net/u012234115/article/details/134668510?share_token=e3835a0d-ac3b-4c86-9e32-e79ec85cddbe
开源C++智能语音识别库whisper.cpp开发使用入门
https://www.toutiao.com/article/7276732434920653312/?app=news_article×tamp=1706802934&use_new_style=1&req_id=2024020123553463D3509B1706BC79D479&group_id=7276732434920653312&tt_from=mobile_qq&utm_source=mobile_qq&utm_medium=toutiao_android&utm_campaign=client_share&share_token=7bcb7488-a03d-4291-96fb-d0835ac76cca&source=m_redirect
OpenAI的whisper的c/c++ 版本体验
首先下载代码,注:我的OS环境是ubuntu 18.04。
https://post.smzdm.com/p/a3052kz7/?share_token=d4057cba-adb0-4c91-8a8b-d8a7adcf4087
显卡怎么玩 篇三:音频转字幕神器whisper升级版,whisper-webui使用教程
https://www.toutiao.com/article/7311876528407921162/?app=news_article×tamp=1706801102&use_new_style=1&req_id=20240201232501647517150775FC7AD89A&group_id=7311876528407921162&tt_from=mobile_qq&utm_source=mobile_qq&utm_medium=toutiao_android&utm_campaign=client_share&share_token=dfa1976e-9422-49d2-a73b-6453becea90c&source=m_redirect
2023 AI 界7个最火的 Text-to-Video 模型
动画
https://www.toutiao.com/article/7312473532829745700/?app=news_article×tamp=1706801052&use_new_style=1&req_id=2024020123241265D9BE3F954EB979A010&group_id=7312473532829745700&tt_from=mobile_qq&utm_source=mobile_qq&utm_medium=toutiao_android&utm_campaign=client_share&share_token=ca5d0d2a-2d9b-4959-b5c0-3dd869555240&source=m_redirect
推荐5款本周 超火 的开源AI项目
原创2023-12-15 07:32·程序员梓羽同学
https://blog.csdn.net/chenlu5201314/article/details/131156770?share_token=b8796ff0-44f8-471a-af6d-c1bc7ca57002
【开源工具】使用Whisper提取视频、语音的字幕
1、下载安装包Assets\WhisperDesktop.zip
https://www.toutiao.com/article/7222852915286016544/?app=news_article×tamp=1706460752&use_new_style=1&req_id=2024012900523164164830D4E1ECF3CCE2&group_id=7222852915286016544&tt_from=mobile_qq&utm_source=mobile_qq&utm_medium=toutiao_android&utm_campaign=client_share&share_token=9bc8621f-b3b1-4f49-ae20-5214c1254515&source=m_redirect
从零开始,手把手教本地部署Stable Diffusion AI绘画 V3版 (Win最新)
原创2023-04-17 11:23·觉悟之坡
https://blog.csdn.net/S_eashell/article/details/135258411?share_token=f998e896-6dff-4fd4-8df2-c6aae132e95c
98秒转录2.5小时音频,最强音频转文字软件insanely-fast-whisper下载部署
老艾的AI世界 已于 2024-01-05 20:20:51 修改


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









