







分布式系统原理系列目录

图片上的人叫Leslie Lamport(莱斯利·兰波特),这老爷子看发型就很资深,就是它提出了分布式共识算法Paxos,还有拜占庭将军问题,我们前面说过分布式系统的麻烦,严格来说,拜占庭将军问题也应该算在其中,为啥没讲呢,因为拜占庭将军问题是假设分布式系统中某些节点可以不遵守协议,比如撒谎、或者恶意扰乱,我们绝大多数系统都是按照既定协议运行的,所以可以不用考虑这个问题。只有在一些特定的场景下才会需要考虑拜占庭将军问题。比如在航空航天环境中,计算机内存或CPU寄存器中的数据可能被辐射破坏,导致它以任何不可预知的⽅式响应其他节点;再比如区块链场景,它就是要让互不信任的各⽅达成共识
好,说回paxos本身。关于Paxos 在分布式领域的地位,有这么一种说法:世界上只有一种共识协议,就是 Paxos,其他所有共识算法都是 Paxos 的退化版本。这句话有点夸张的成分,但是如果没有 Paxos,那后续的 Raft、ZAB 等算法,ZooKeeper、etcd 这些分布式协调框架,Hadoop、Consul 这些在此基础上的各类分布式应用,都很可能会延后好几年面世
Paxos的故事
Paxos从被提出到广为人知这个过程并不是一帆风顺的,可以说是很曲折了,大家就当故事听一下哦:
兰伯特在 1990 年首次发表了 Paxos 算法。由于这个算法本身就非常复杂,然后为了展示自己的幽默感呢,老爷子还特地用了一个希腊城邦的比喻,这就让论文显得更难理解了。然后这篇论文的三个审稿人,一致要求他删掉希腊城邦的故事。这就让老爷子非常不爽,认为这些人不懂他的幽默,然后干脆就撤稿不发了
之后过了8年,也就是 1998 年,Lamport 把这篇论文重新整理后又发出来了。这次论文是审核通过了,但是并没有多少人能看懂他到底在说什么
又过了3年,到了 2001 年,Lamport 认为前两次没有引起什么反响,是因为同行们无法理解他以“希腊城邦”来讲故事的幽默感。然后这次发表的时候,它终于放弃了“希腊城邦”的比喻,尽可能用(他认为)简单直接、可读性较强的方式去介绍 Paxos 算法。这次的情况虽然比前两次要好一些,但是相对于它本应该受到的重视程度来说,这次也没好到哪里去,为什么?还是因为太难懂了
后来这段经历被 Lamport 以自嘲的形式放到了他的个人网站上,如果你打开“Paxos Made Simple”这篇论文(我也没打开过。这句话是别人说的哦。),你就会看到它的摘要部分只有一句话:“Paxos算法,如果用英文来解释,非常简单.” ,就很让人怀疑他是在嘲讽审稿人和读者,“你们这些愚蠢的人类!”
到这里Paxos的知名度依然不太高,直到了2006 年,Google 发表了Chubby、Megastore 和 Spanner 等分布式系统的论文,文中提到这些系统都使用 Paxos 解决了分布式共识的问题,Google 的行业影响力很大,Paxos 算法一夜间成为分布式领域的网红概念。随后,才有了 Paxos 在分布式系统、云计算、区块链等多个领域大放异彩的故事。这事也充分说明了,在技术圈里,即使再有本事,也还是要好好包装一下啊
paxos要解决的问题
paxos算法的细节我这里就不说了,一来篇幅很长,二来估计我也很难讲的清楚。接下来我就大概说下paxos要解决的问题
Paxos要干的事情就是让多个节点就某件事情达成共识,这个事情看起来好像不难,但实际非常困难,困难主要来源于两方面:
1、我们前面说过,分布式系统中有各种异常问题(机器宕机、网络异常等等),解决这些问题的办法是法定人数机制,每次都投票,少数服从多数,这样可以容忍少数节点故障。具体来说就是每次收到客户端请求时,只要超过半数的节点同意执行这个请求,那就算请求成功
比如客户端请求写入x=1,收到请求的那个节点先只记录日志,不直接写入这个值,然后广播到其他节点请求投票,如果收到半数以上节点的投票(包括他自己),那这个写请求就算成功了,然后他自己真正写入这个值,并再广播一条提交消息让其他节点提交。如果只有这一个问题,法定人数机制就解决了,每次请求过来发起一轮投票,少数服从多数,完事儿
但还有个并发问题要解决
2、并发有什么问题呢,举个例子客户1、2同时向系统请求占座,谁能成功?我们立马会想到加锁,谁加成功谁占座。如下图,如果是在主从架构的集群中,master加锁就完事儿了,不管咋样,两个请求到master是一定有一个先后顺序的,先来先加锁就行了。问题是非中心化集群怎么加锁呢?并发请求可能会发到多个节点上,而这多个节点是完全平等的、node1会提出让client1占座,node2会提出让client2占座,那让谁占?所以就需要协调多个节点去完成加锁,这个问题是非常复杂的
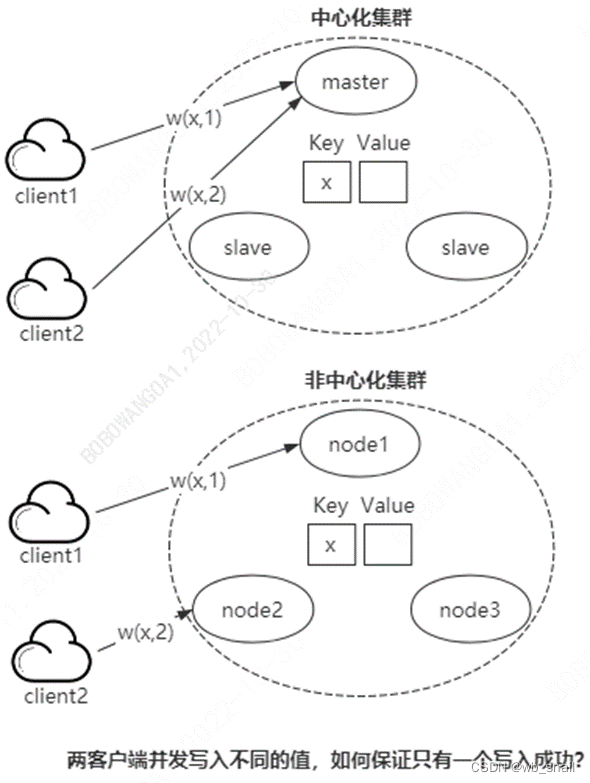
paxos中的很大一部分复杂度都是为了要解决这个问题带来的,而且这个过程还会导致比较多的性能消耗。本质原因是每个节点完全平等,写请求可能会被同时发送到多个节点,那多个节点就可能同时提出提案,这些提案是有竞争关系的(只有一个能成功),为了解决这个竞争问题,比较费劲
Basic Paxos与Multi Paxos
为此lamport老爷子还专门设计了一个改进版的算法,叫做Multi Paxos,对应的哦,前面说的paxos就叫做Basic Paxos,大家在其他资料看到的Paxos如果没有特殊说明,都是指Paxos。
(ps:“专门设计”的意思是,它在 Paxos 的论文里随意提了几句可以这么做)
他说希望能够找到一种两全其美的办法:既不破坏 Paxos 中“众节点平等”的原则,又能限制下,不是每个节点都可以提案,这样子性能就可以好很多。没错,就是类似选村长的方案,首先各节点基于basic paxos选出一个leader,之后正常情况下就只有leader可以提案,那就 不需要多个节点去协调解决竞争问题了。如果发生前面我们说的两个客户端同时请求占座的情况,因为请求只会发到leader,它直接加锁控制并发就完事儿了
这样就是一开始有一群平等的节点,然后他们自己投票选出个Leader,以后都让这个Leader来做决策,如果Leader宕机了,就再投票选一个新的Leader
Multi Paxos的派生算法
后来就有人根据multi paxos的思想,提出了raft算法,发布了一篇叫做《raft-一种可以让人理解的共识算法》的论文(这再一次从侧面说明了这个paxos的难度)。这篇论文获得了USENIX ATC 2014 大会的 Best Paper,更是成为了日后 etcd、LogCabin、Consul 等重要分布式程序的实现基础。ZooKeeper 的 ZAB 算法和 Raft 的思路也非常类似,这些算法都被认为是与 Multi Paxos 的等价实现
再补充一点,很多中文资料把 共识Consensus翻译为一致性,也就是"分布式一致性算法",听起来就很像是保证数据一致性的算法,就很让人迷惑。共识(Consensus)与一致性(Consistency)是有区别的:
分布式一致性我们之前说过,指的是协调数据在不同副本之间的差异。而共识的重点是让多个节点达成一致,这和多副本数据差异完全不是一回事,大家以后看到分布式一致性算法就要知道它的重点是达成共识















 7035
7035











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









