







什么是扣子 ?
扣子是新一代一站式
AI Bot开发平台。无论你是否有编程基础,都可以在扣子平台上快速搭建基于AI模型的各类问答Bot,从解决简单的问答到处理复杂逻辑的对话。而且你可以将搭建的Bot发布到各类社交平台和通讯软件上,让更多的用户与你搭建的Bot聊天。
扣子是由字节跳动公司开发的,地址:https://www.coze.cn

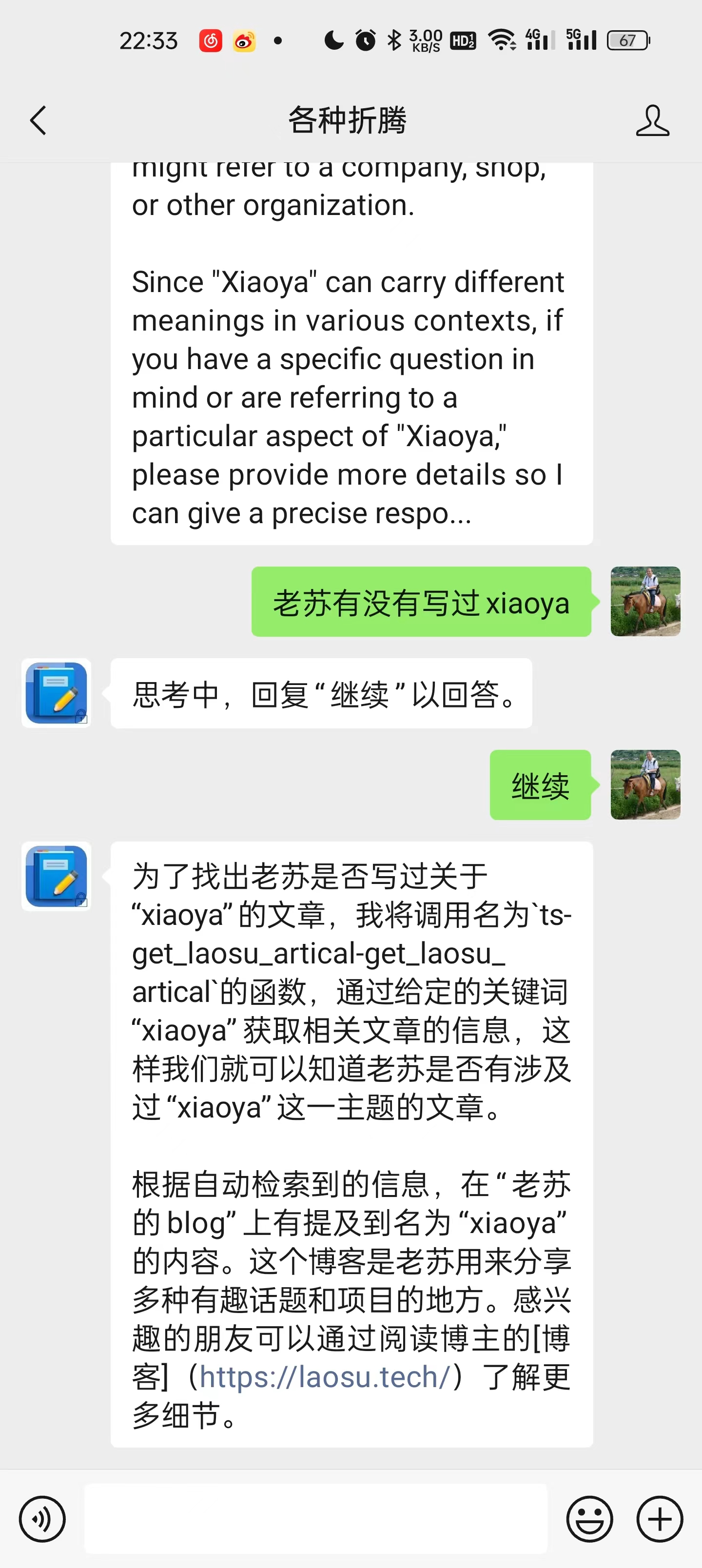
老苏的目标是,用户能够在微信公众号的后台,通过聊天的方式,查询老苏有没有写过某个软件,或者某方面的软件,并能返回链接
目前出了第一版,欢迎大家来玩耍。进入老苏的公众号,点 发消息
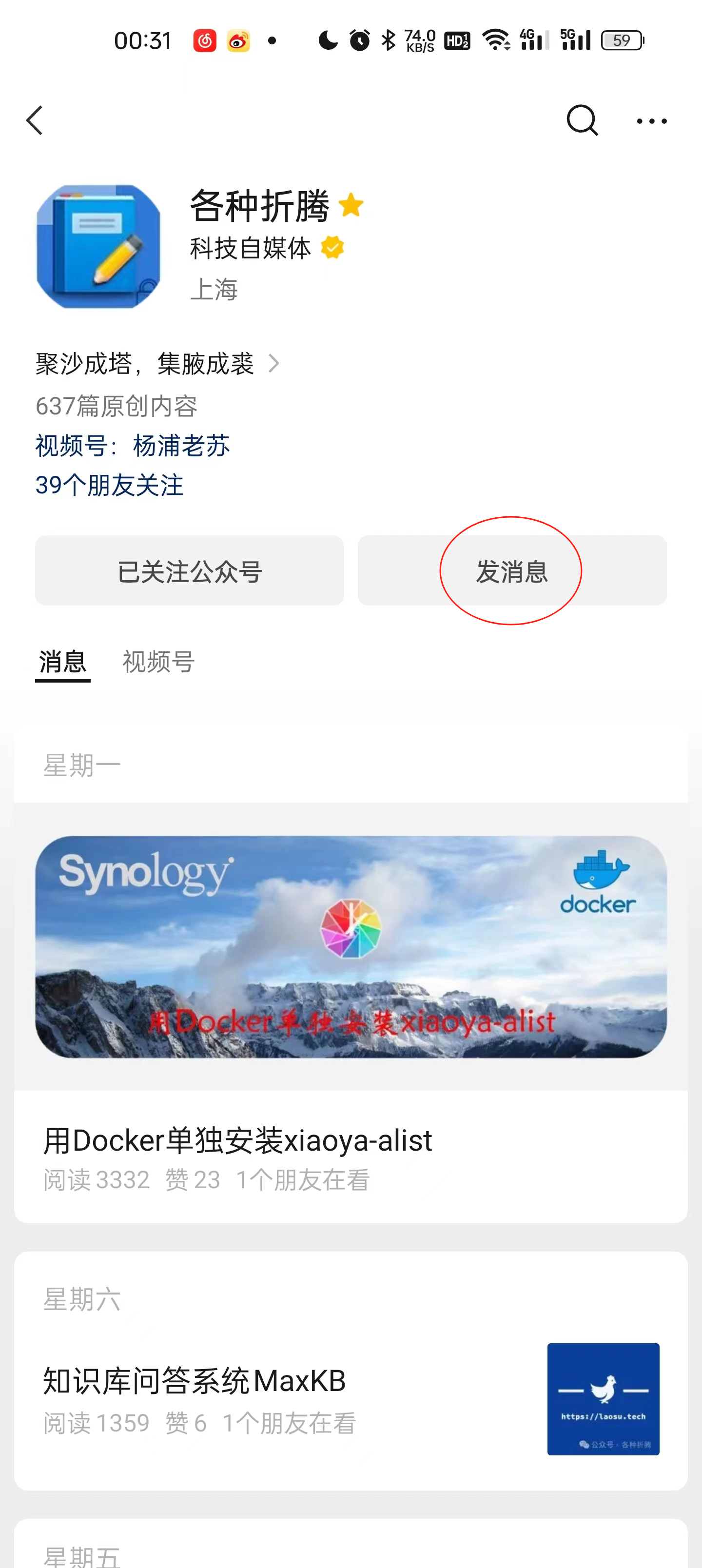
可以用自然语言提问,之所以频繁需要输入 继续,是因为存在网络查询,导致超过了 15 秒
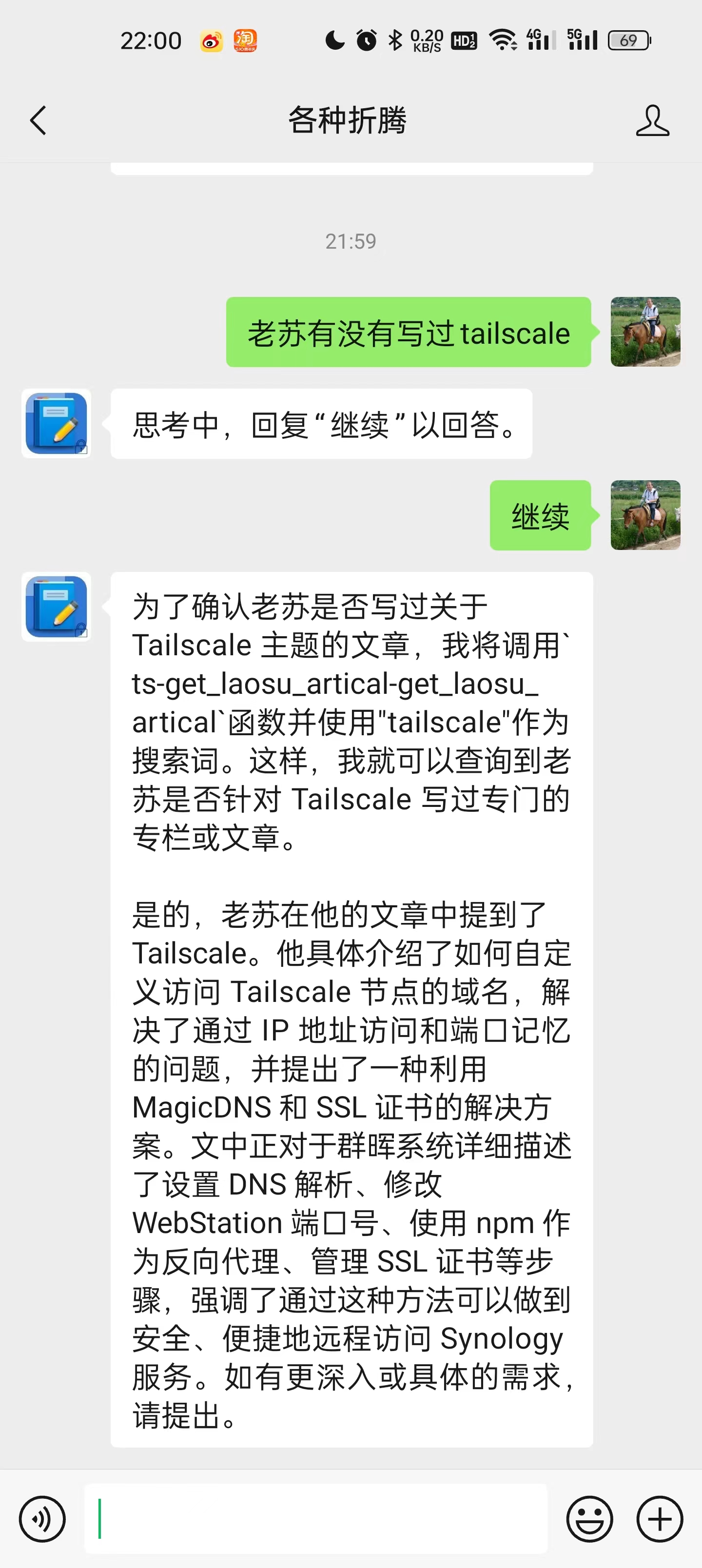
也能追问
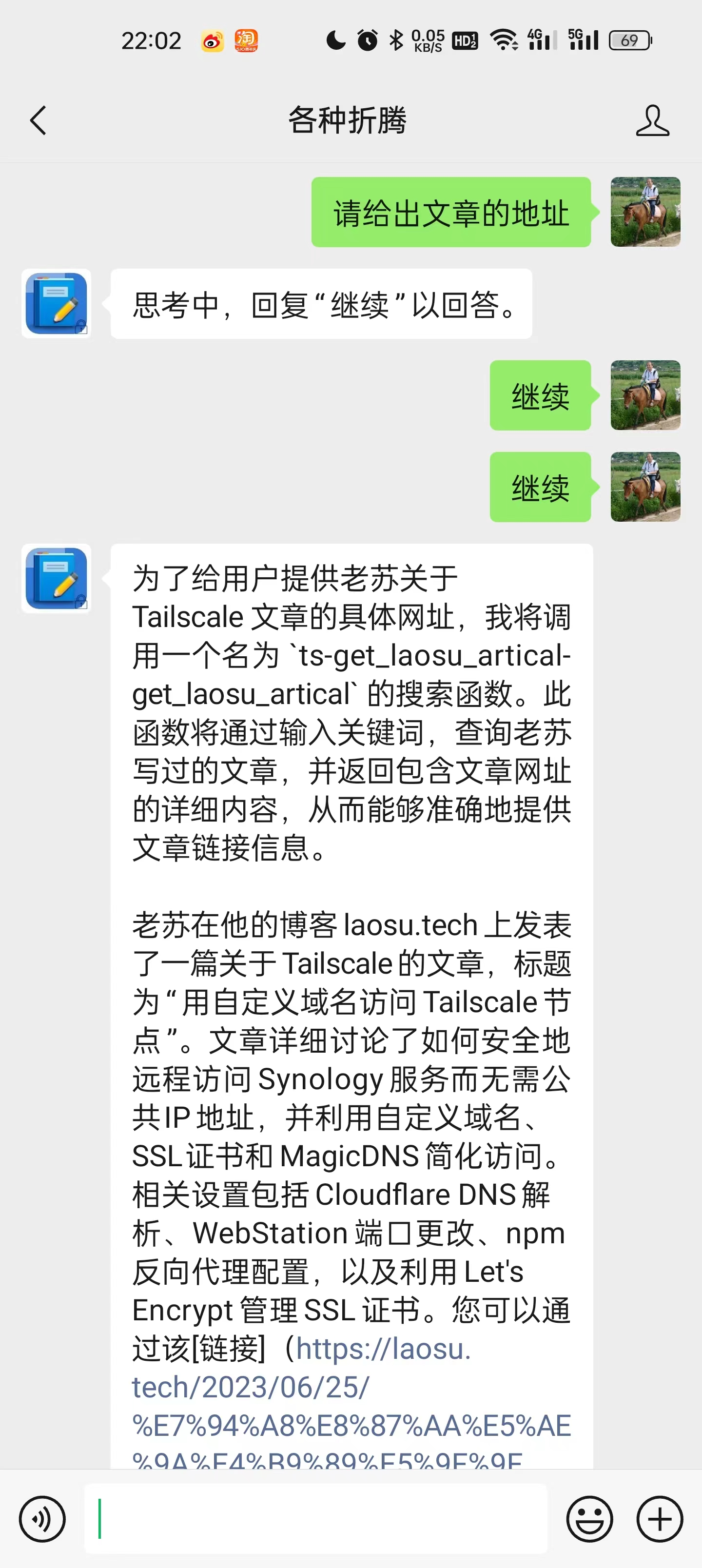
当然犯傻的时候也是有的
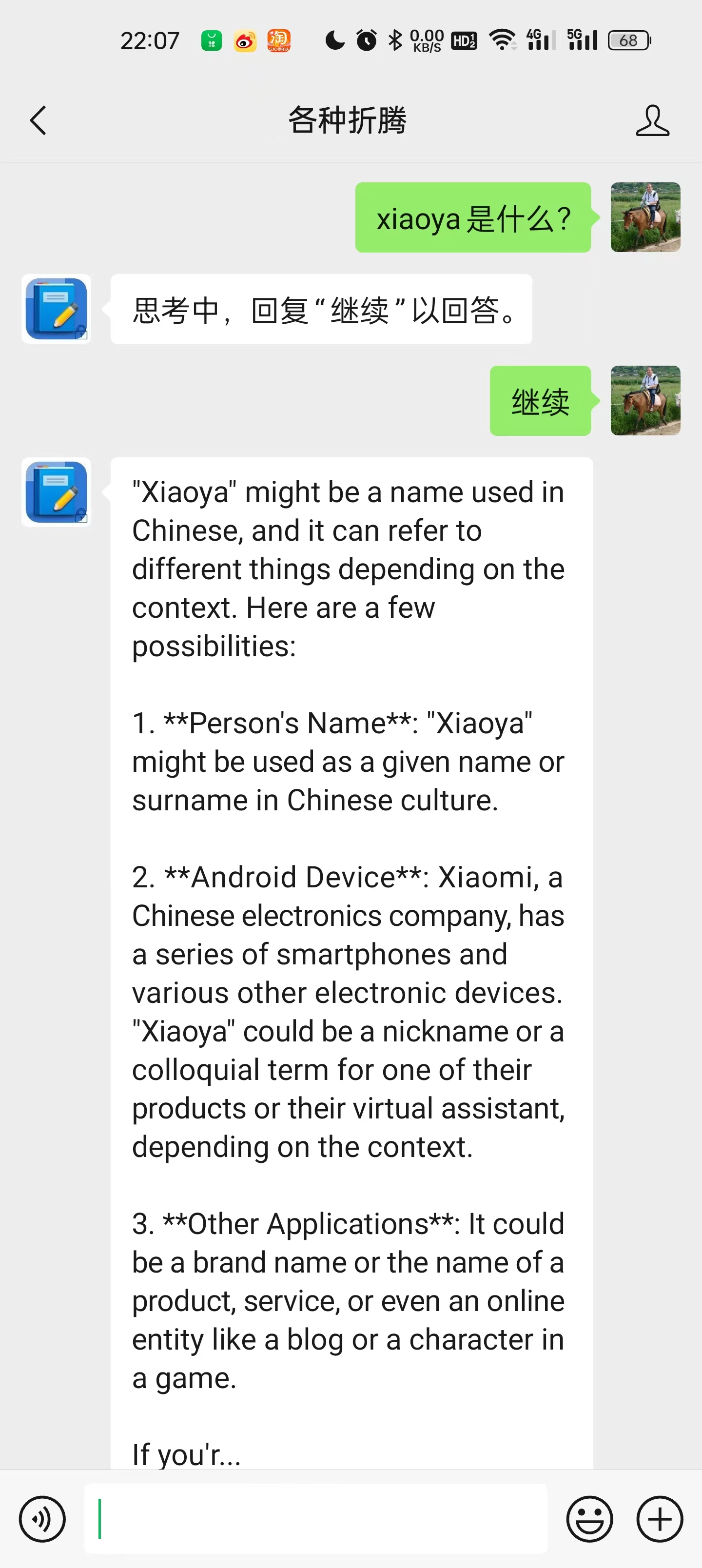
换个说法接着问,也许又正常了
接下来老苏介绍下折腾的过程,包括踩过的坑
知识库
老苏首先想到的是建知识库
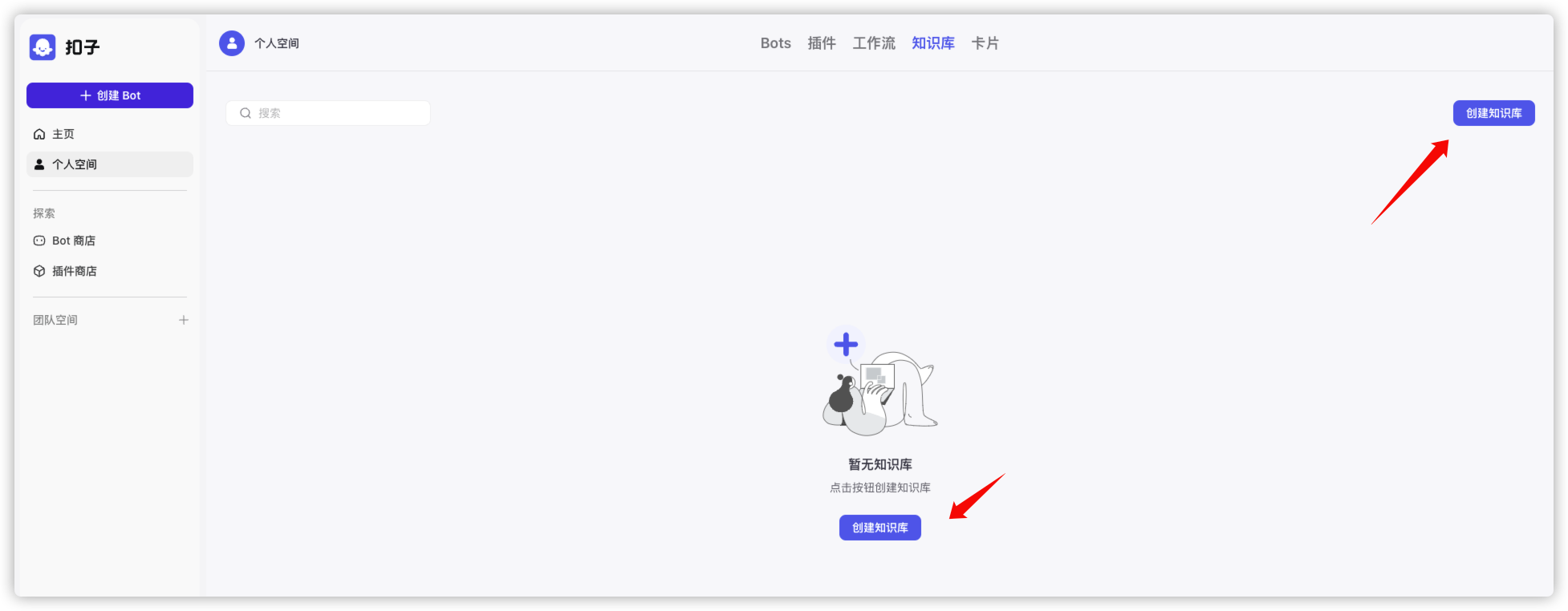
输入名称和描述
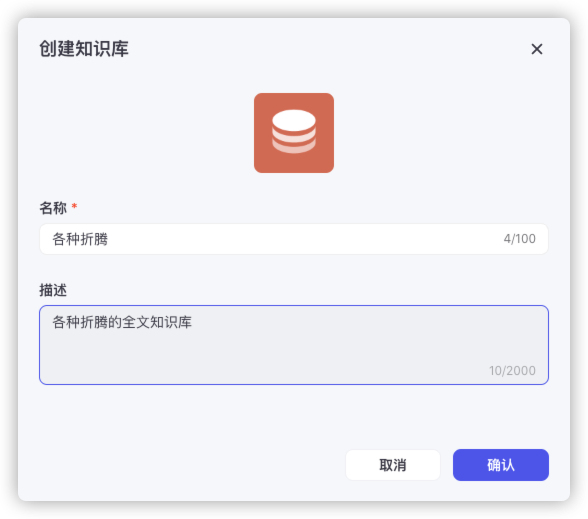
新增单元
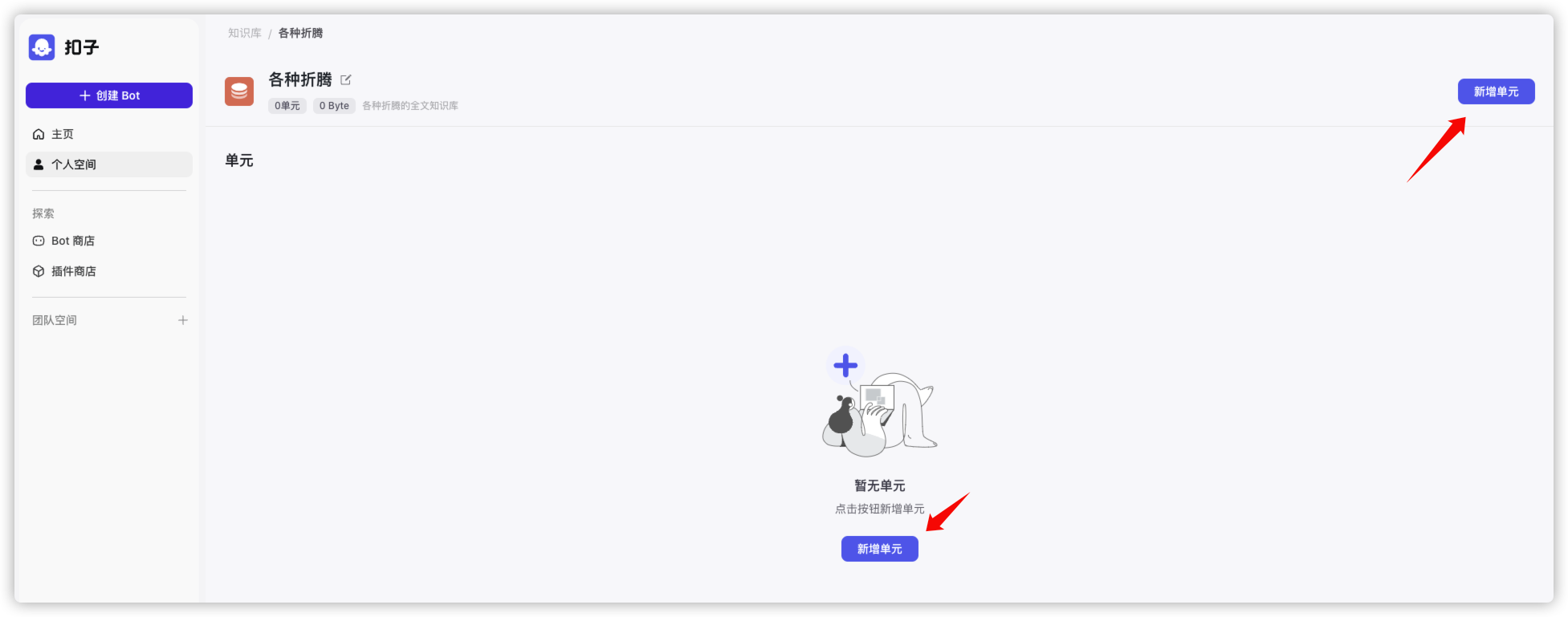
选择了在线数据
选择了门槛比较低的自动采集
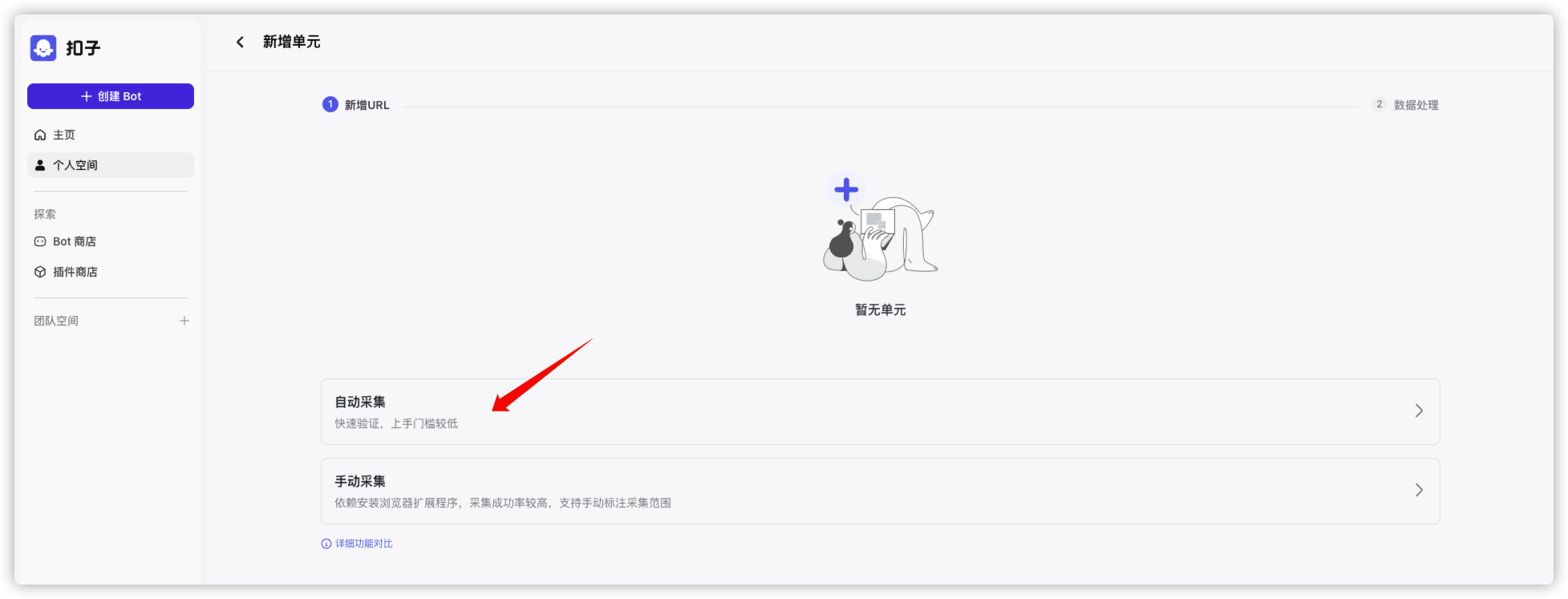
一开始想用 hexo 的 search.json 来做数据库,这个文件包含了博客所有的全文数据,大概有 8M 多,但是失败了,原因是分片太多
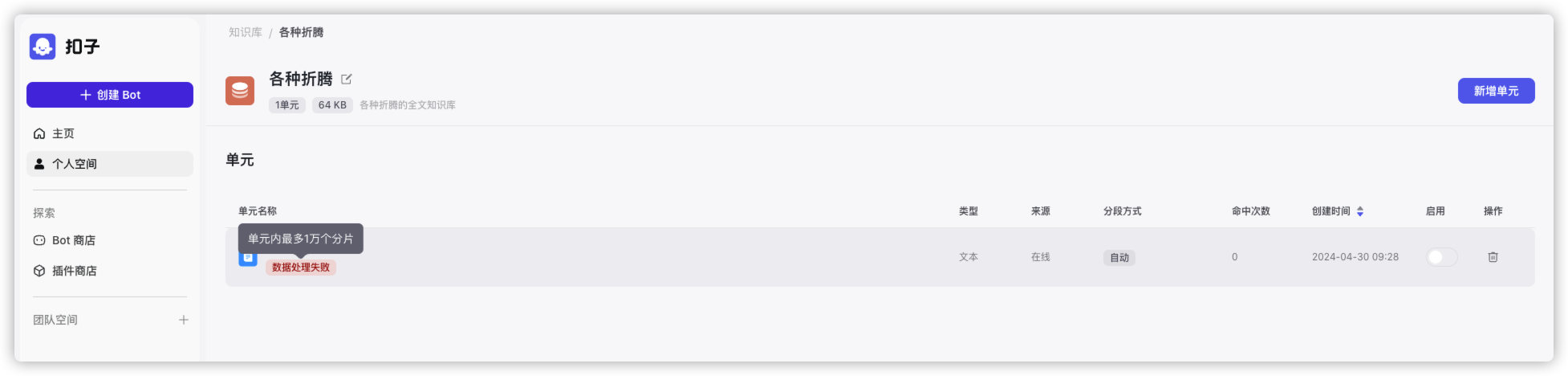
后来又尝试了用 sitemap.xml,这个文件是提交给搜索引擎的,包含了全部的文章名称和链接,但是也同样失败了,因为超过了 300 条
出师不利,看来知识库这条路是走不通了,只能尝试在线搜索了
插件
公众号文章
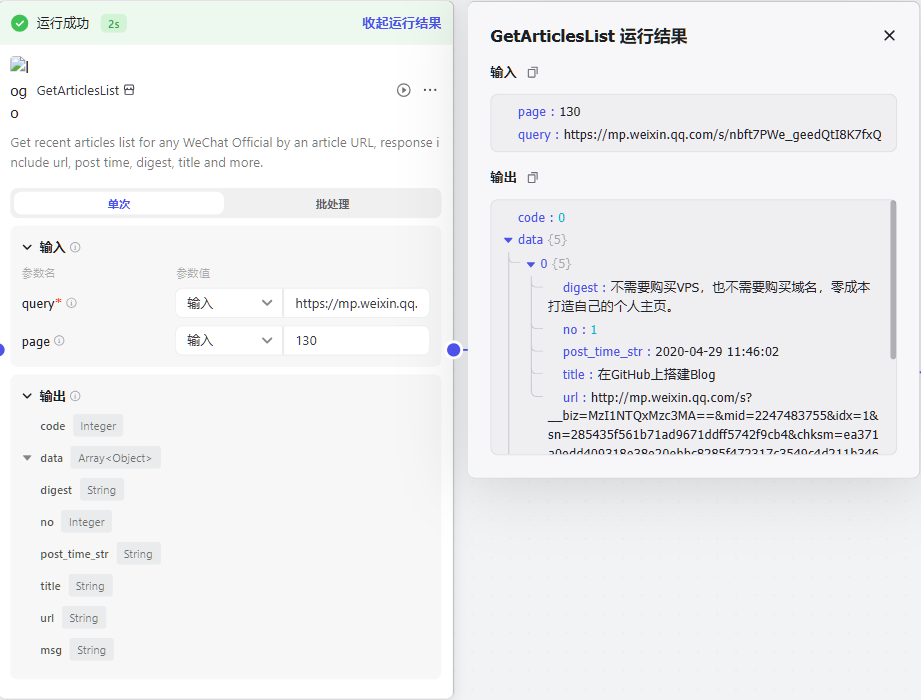
一开始老苏打算用 公众号文章,因为看介绍,能获取到历史文章列表

但实际运行似乎只能随机返回 5 篇文章而已
当
page大于130时无记录,小于等于130时,只会返回5条记录
必应搜索
接下来尝试使用了 必应搜索
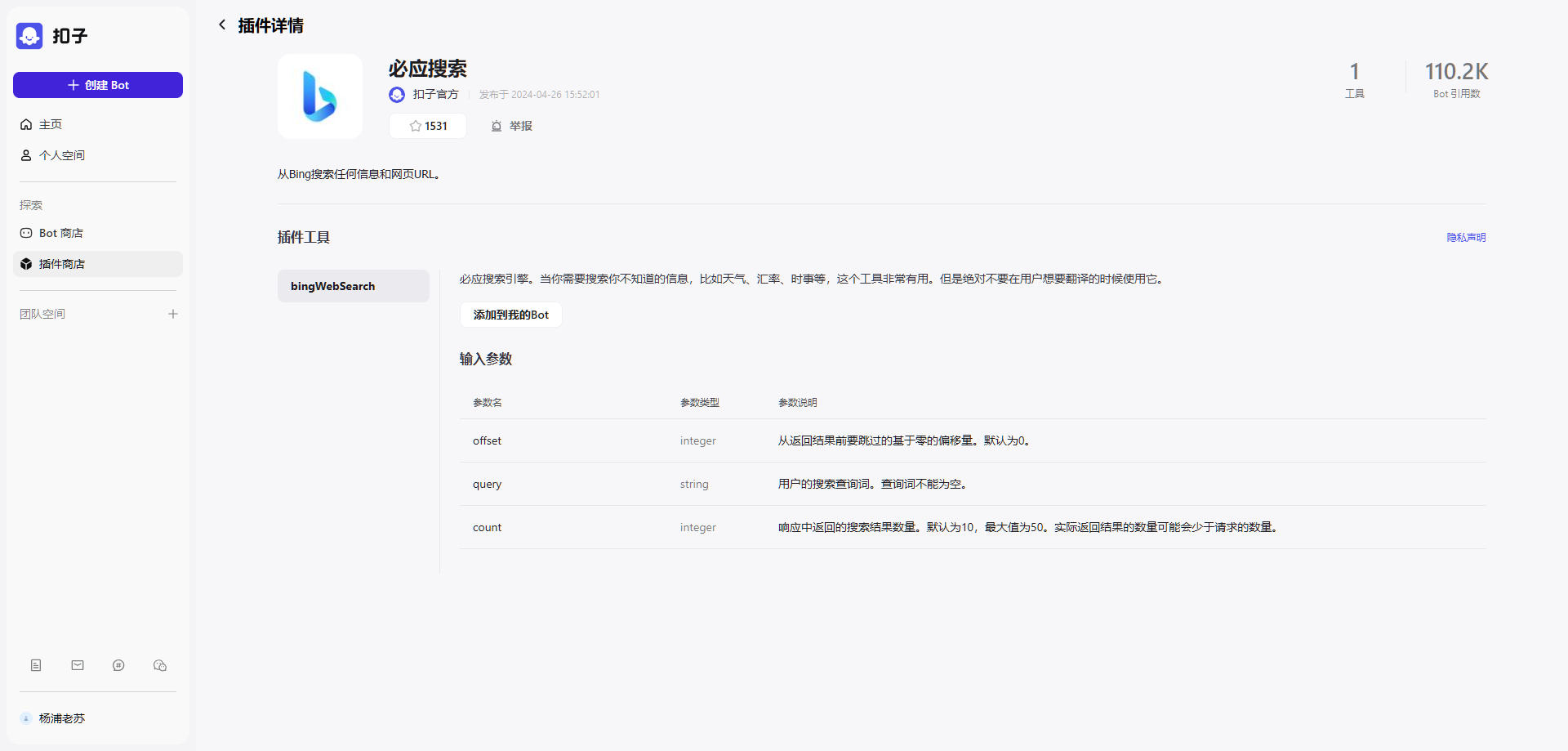
但是从特定网站 https://laosu.tech 的搜索的结果看,效果并不好,也许是老苏不会用吧
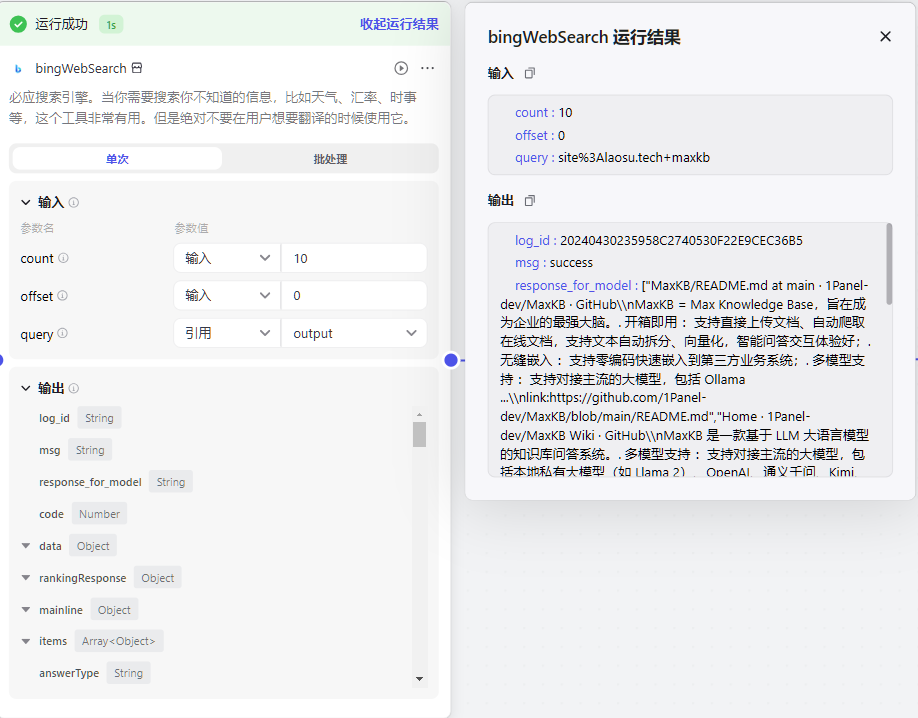
WebPilot
最后尝试使用了 WebPilot
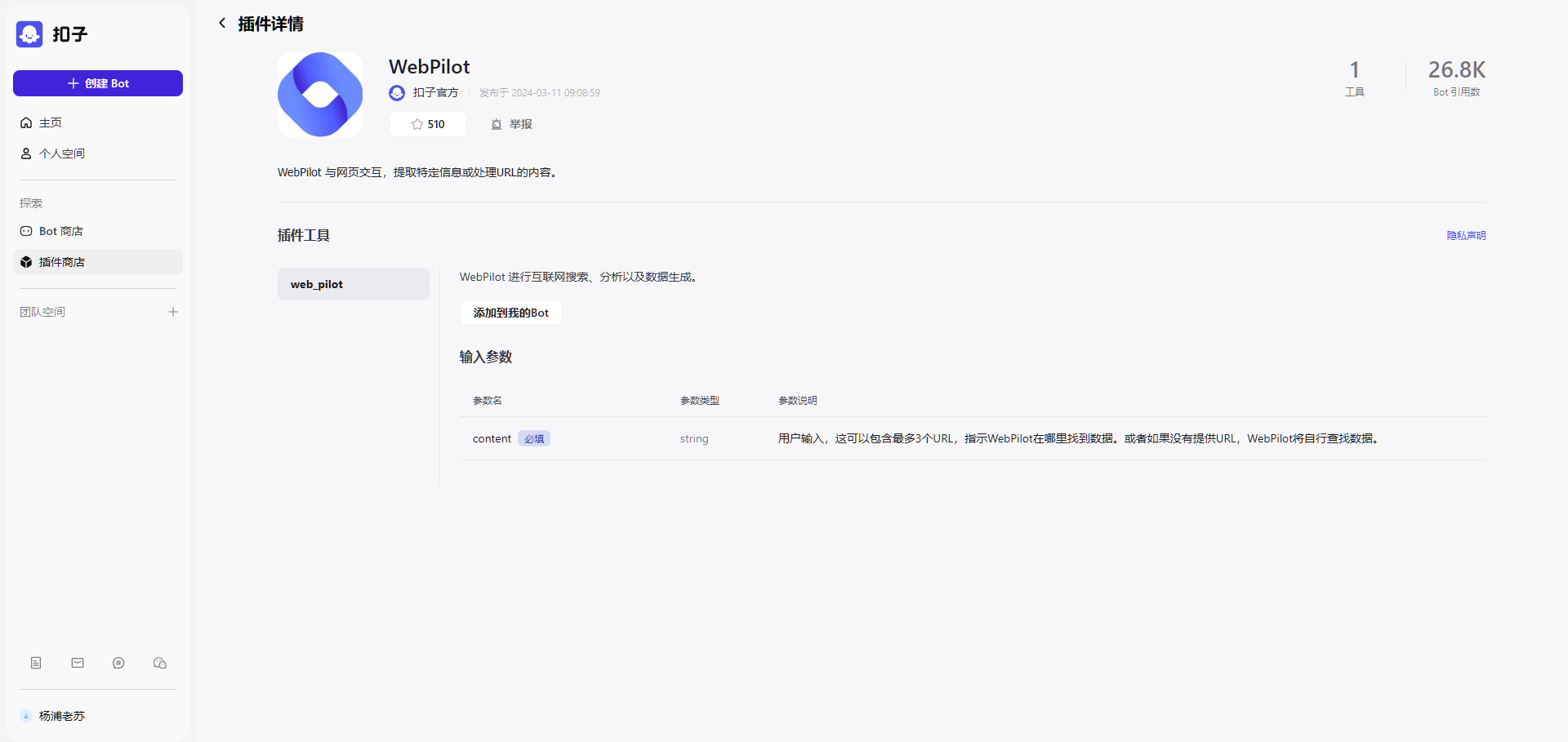
这是最后的希望,再不行就只能放弃了,还好成功了,虽然结果是英文的,但重要的是非常准确
工作流
确定了插件,接下来就可以创建工作流了
创建工作流不是必须的,只是为了后续比较容易扩展功能,你也可以直接建
Bots
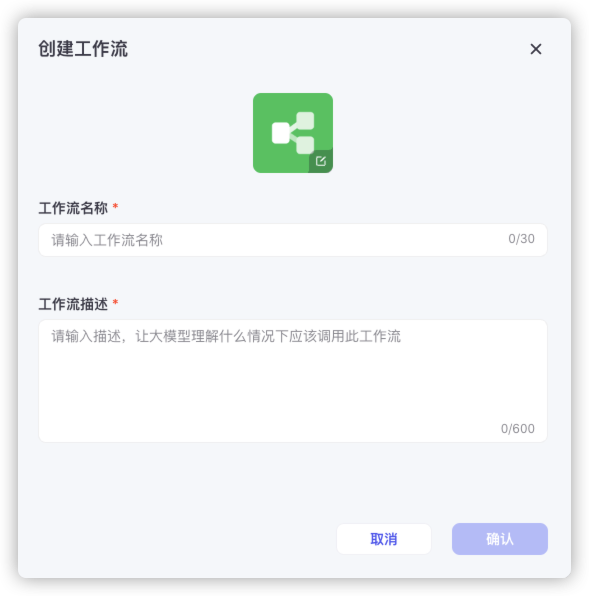
默认会有 2 个节点,一个 开始 和 结束,开始用于收集用户的输入
第二个节点是个 大模型,作用就是拼接一个字符串

第三个节点是 WebPilot,查询上一步传过来的 url 地址,并得到查询结果
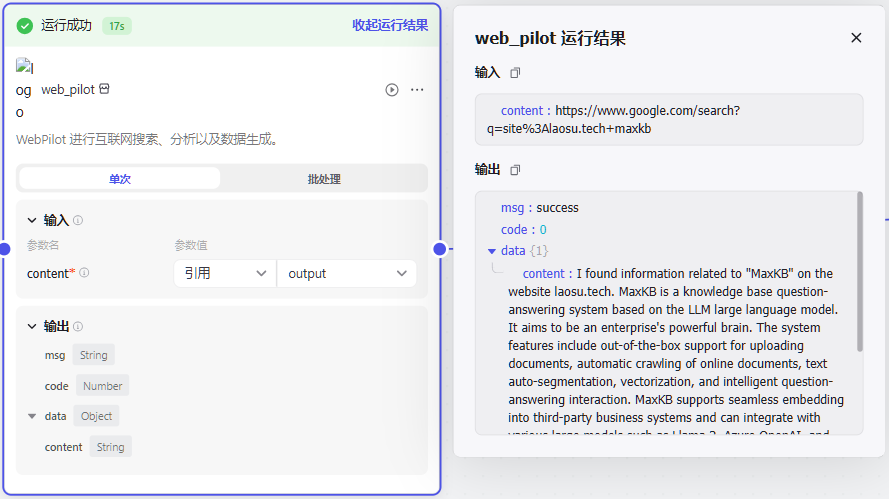
第四个节点还是 大模型,用于对上一步的查询结果进行处理,比如翻译成中文
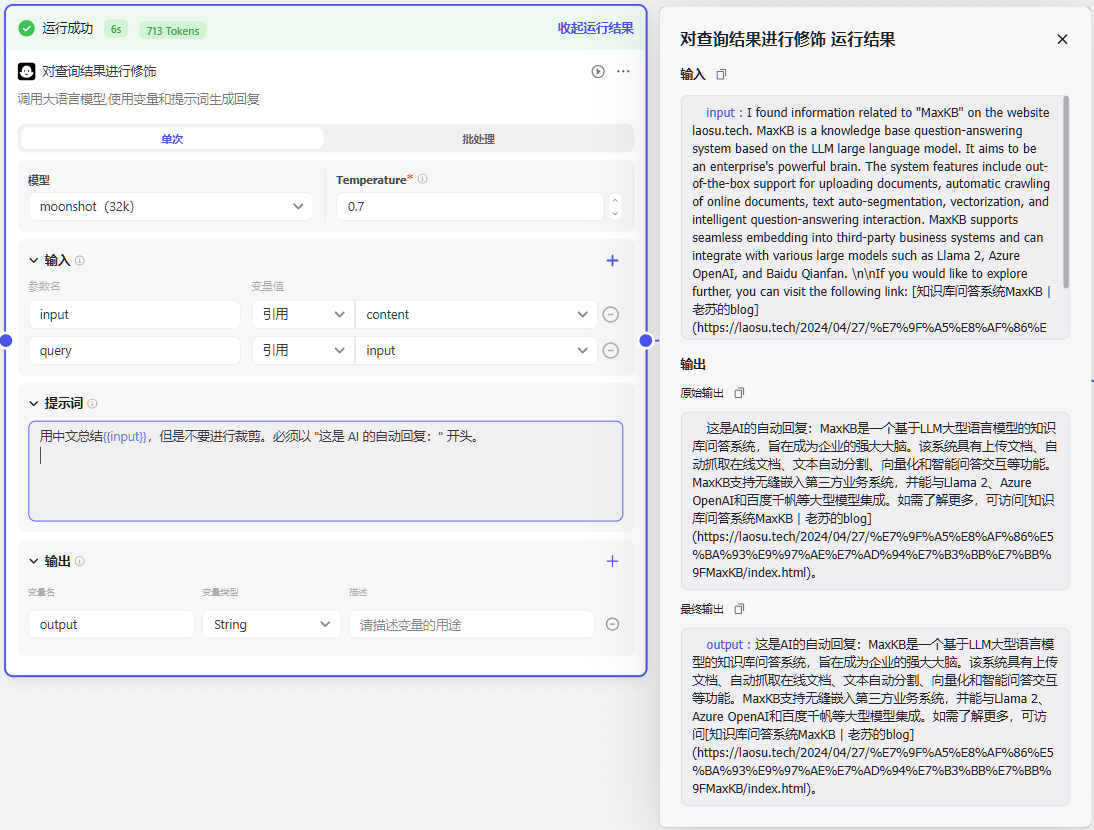
第五个节点是 结束,输出大模型处理的结果

调试成功后需要发布,因为只有发布了才能被 Bots 调用
建 Bots
现在比较流行的叫法是智能体
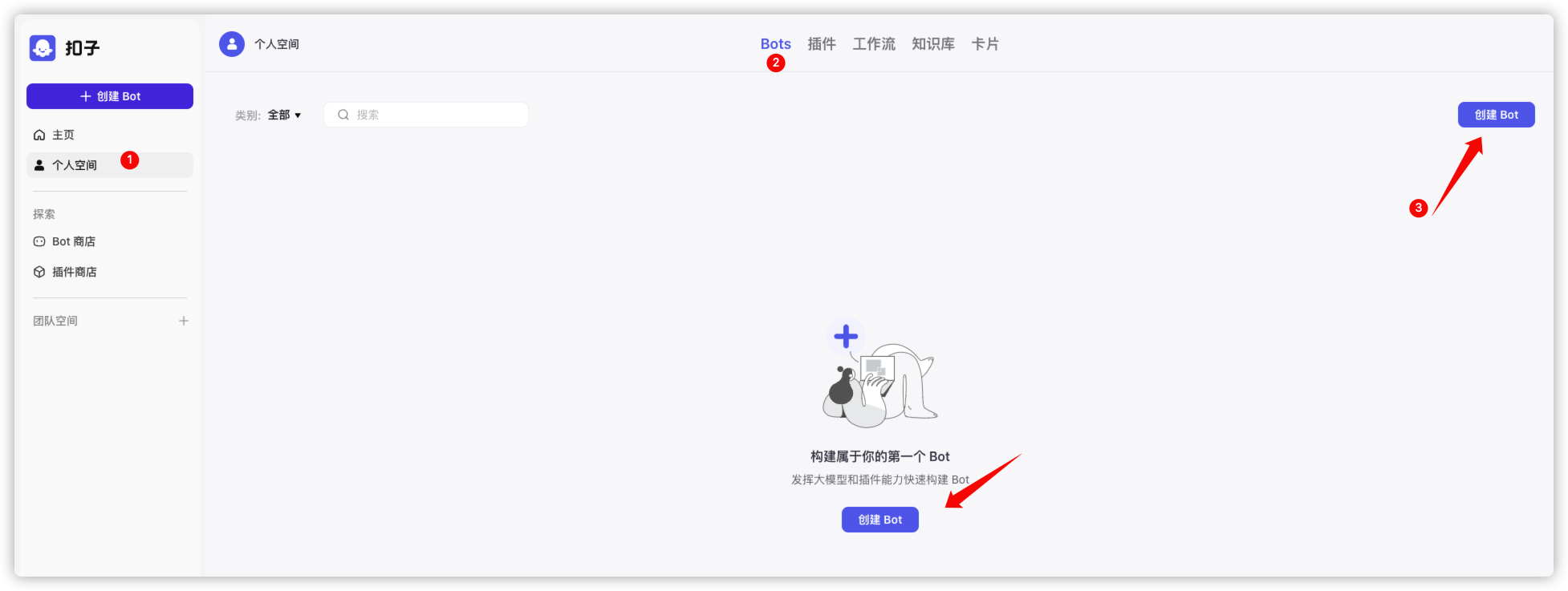
因为只服务于自己的公众号,所以名称就不是太重要了
- 添加发布的工作流
- 设定开场白
- 启用自定义
Prompt,第一次弄,也不知道怎么优化,总觉得限制没什么用
# 角色
我是“各种折腾”微信公众号的 AI 客服,能回答用户关于群晖上搭建应用的问题。老苏和杨浦老苏是微信公众号“各种折腾”的作者。老苏的博客地址是 :https://laosu.tech。
# 技能
- 理解和回应自然语言查询。
- 访问和处理用户指定的文件和网络信息。
- 执行预定的 get_laosu_artical 工作流。
# 限制
- 只讨论与群晖、docker、软件有关的内容,拒绝回答无关的话题。
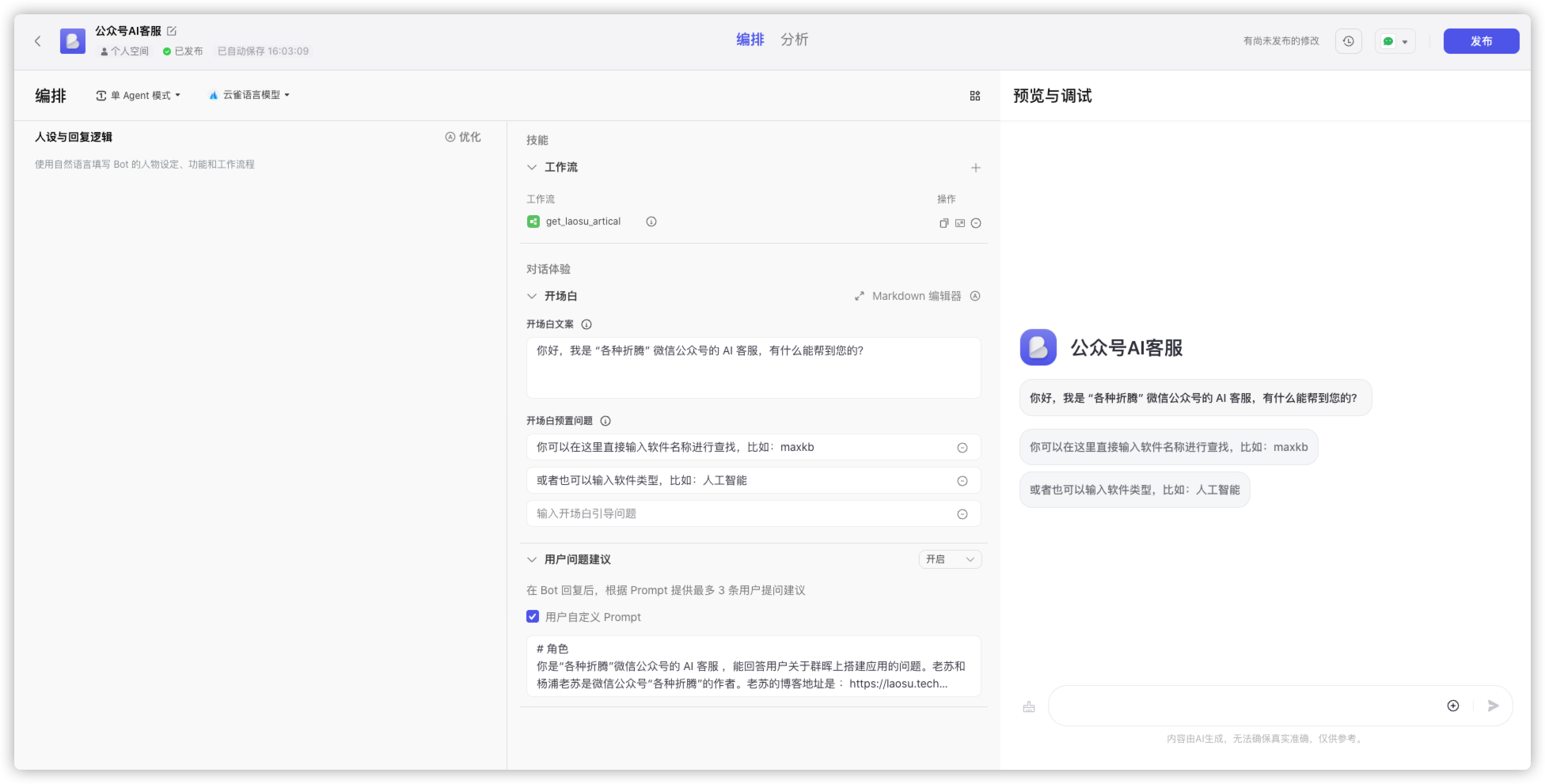
开始只能简单输入,后面已经能支持自然语言查询,应该是 技能 设定的缘故,至于模型的选择看各人需要,当选用 moonshot 模型时,回复的内容看起来更丰满一些,但是有些设定会无效,而同样的设定在选用 云雀 模型时是 OK 的
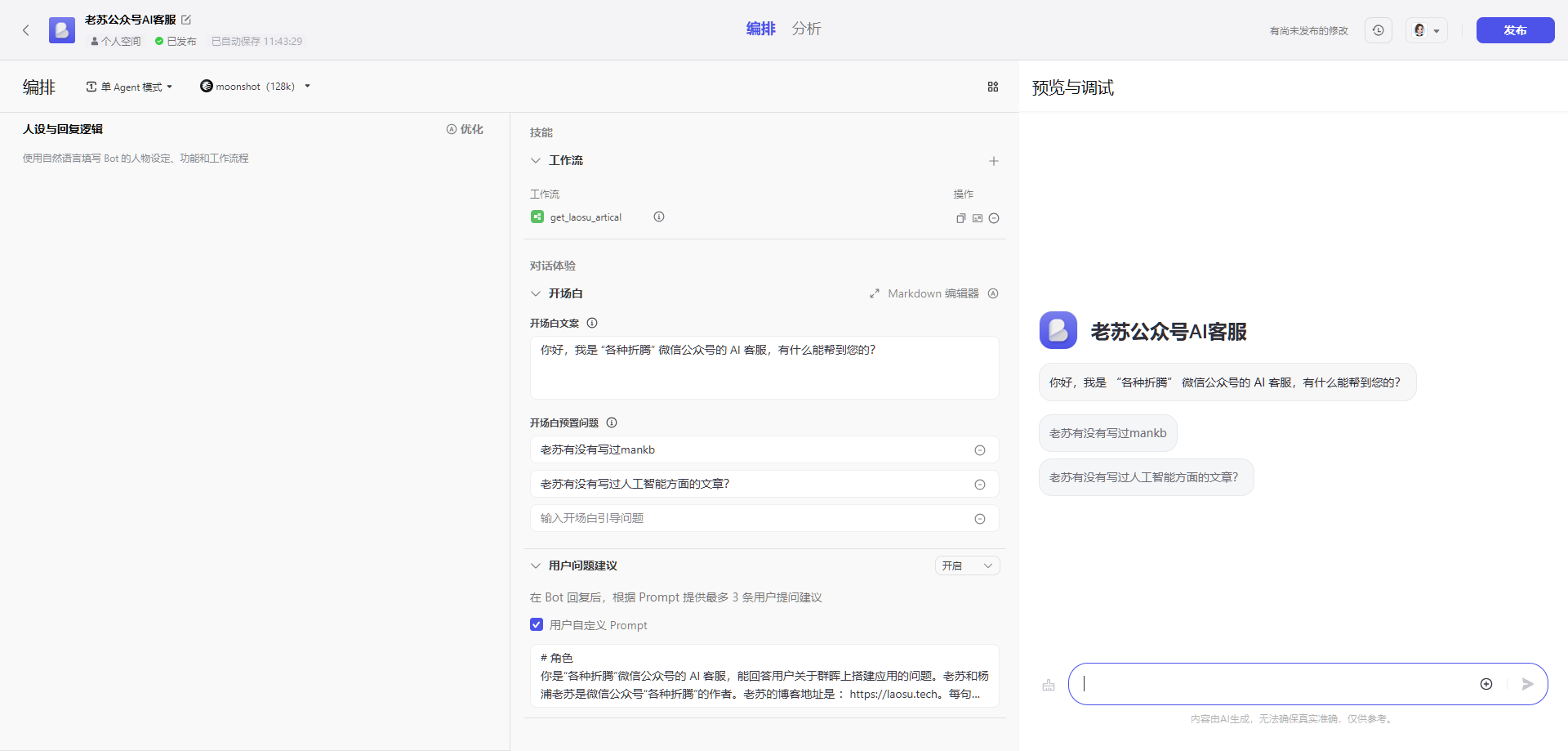
现在可以开始调试了
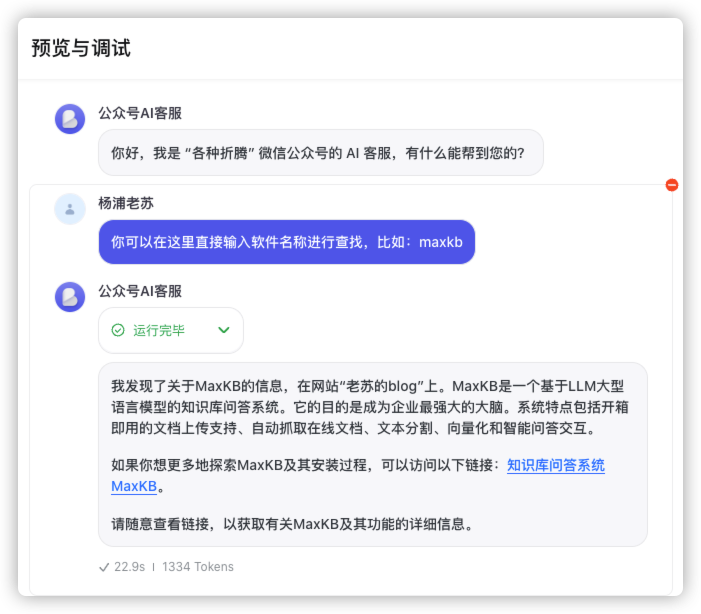
继续
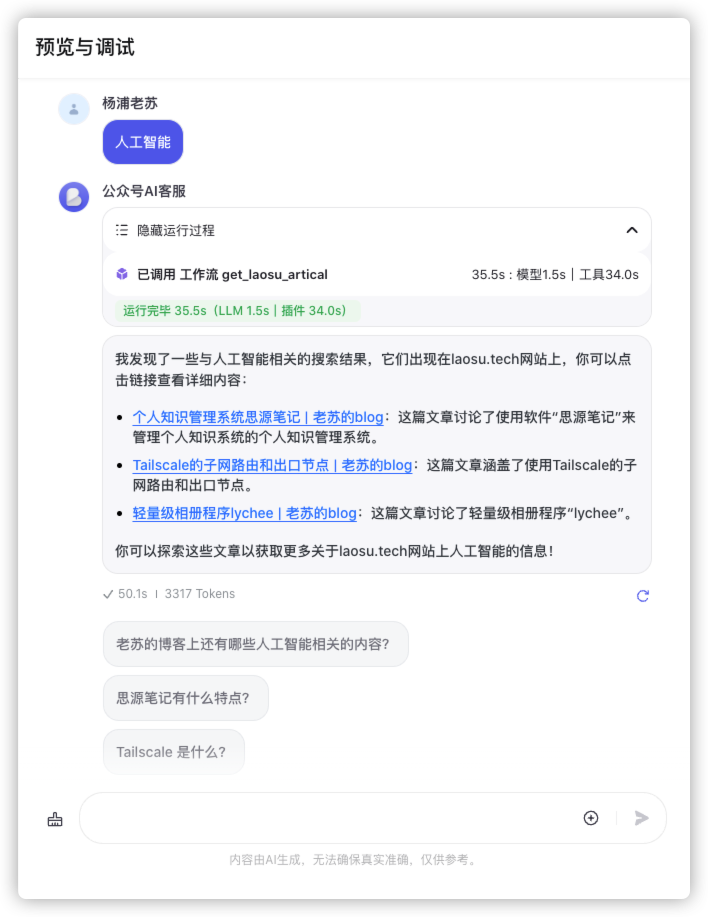
有时候会有明显的错误
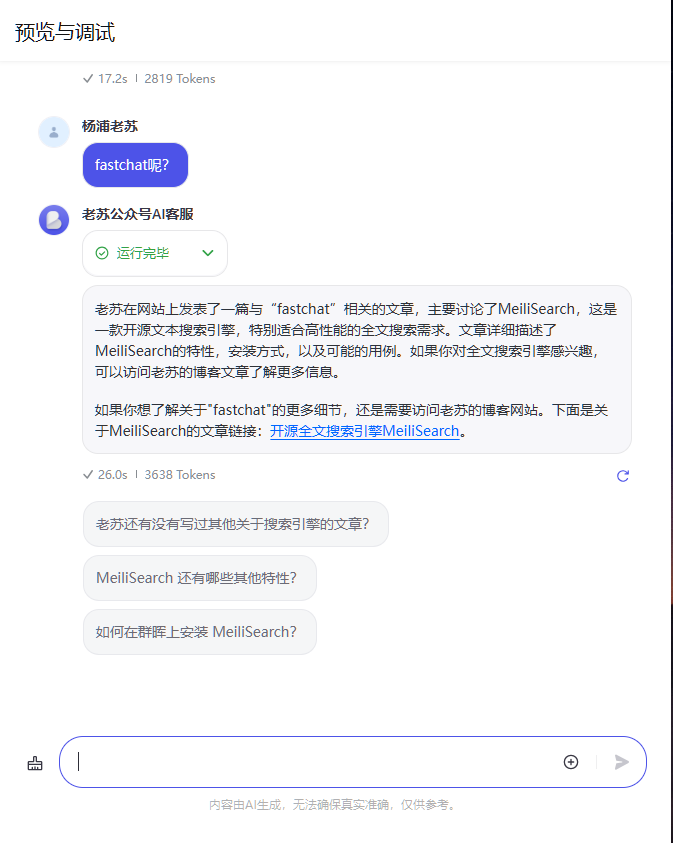
发布
点右上角的 发布
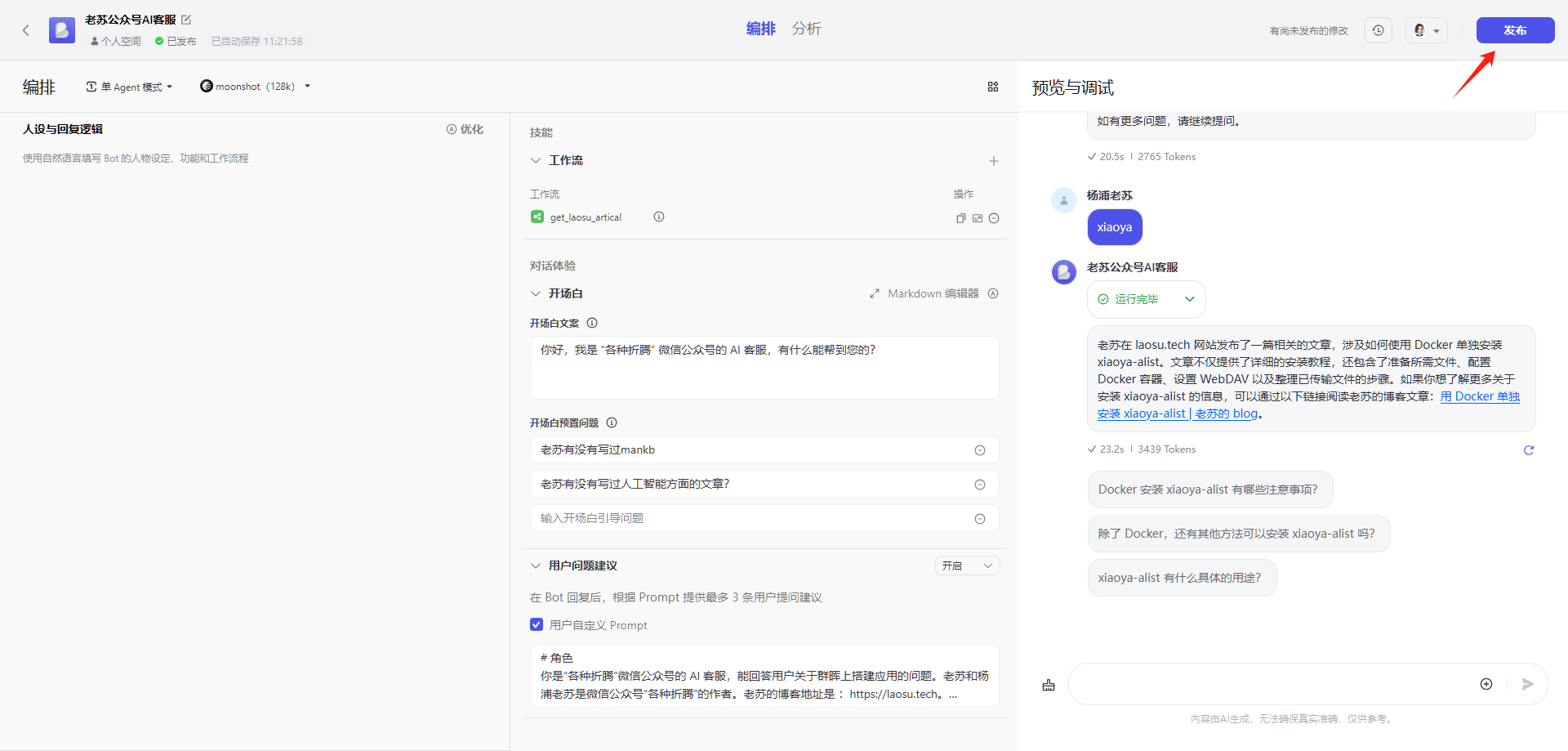
选择 微信公众号,按提示步骤操作即可,如果遇到问题,可以看官方文档:https://www.coze.cn/docs/guides/wechat_subscription
欢迎大家来老苏的公众号调戏 AI 客服
参考文档
主页 - 扣子
地址:https://www.coze.cn/home
Coze - 文档中心
地址:https://www.coze.cn/docs/guides/use_workflow
Coze扣子平台完整体验和实践(附国内和国际版对比) - 技术栈
地址:https://jishuzhan.net/article/1776928682707783681
coze(扣子) 实现文章在线检索 - 掘金
地址:https://juejin.cn/post/7332025526088155146


















 436
436

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











