







Step 1. 准备安装环境
在虚拟机中有三台服务器, 采用的是CentOS6 64位系统, 三台机的命名分别为
yun1,yun2,yun3, 现已在三台机子上建了相同的用户名clwang/123456
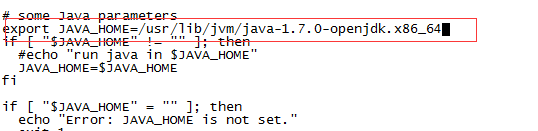
已安装jdk1.7并配置好环境变量
export JAVA_HOME=/usr/lib/jvm/java-1.7.0-openjdk.x86_64
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=.:${JAVA_HOME}/lib
export PATH=${JAVA_HOME}/bin:$PATH
用java,javac测试成功, 同时把jdk复制到yun2,yun3相同位置,并对/etc/profile文件作相同修改
因为准备把yun1作为主节点, 所以从网上下载了 hadoop-2.6.0.tar.gz并解压到
/home/clwang位置
Step 2. 禁用iptables, selinux
Chkconfig iptables off # 停止iptables, 这条命令在重启后生效
Service iptables stop #禁用iptables
编辑 “/etc/selinux/config"文件,设置"SELINUX=disabled”
同时要对三台机进行相同配置
Step 3. 配置ssh免密码连入
首先以root分别登陆到三台服务中, 修改/etc/hosts文件,把三台机子的IP以及主机名添加到hosts文件名, 注意, 所有的hosts都要同时添加三台机的IP,主机名.
然后以wclluck用户分别登陆到三台服务器中, 执行ssh-keygen –t rsa后 ,
执行ls –a 可以看到多了一个.ssh文件夹
进入到.ssh文件夹, 分别在三台机子中执行cp id_rsa.pub authorized_keys 命令,将会看到.ssh文件夹中多一个authorized_keys文件, 把三台机子的authorized_keys的内容互相拷贝到对方的此文件中, 就可以互相免密码连入了, 如下图为authorized_keys的最终内容.测试 ssh 192.168.124.151, 如下图, 不用密码即能连入,配置成功.
Step4. 配置hadoop 相关文件
所有需配置文件都在/home/wclluck/hadoop-2.6.2/etc/hadoop文件夹中,
共包括hadoop-env.sh,yarn-env.sh,slaves, core-site.xml, hdfs-site.xml, mapred-site.xml,
yarn-site.xml 七个文件, 修改内容如下:

Slaves:
yun2,
yun3
mapred-site.xml(注:该文件并不存在,需要自己创建)
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
</configuration>
#在配置core-site.xml前要先在hadoop根目录下建tmp文件夹
core-site.xml
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://yun1:8020</value>
</property>
<property>
<name>io.file.buffer.size</name>
<value>131072</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/home/clwang/hadoop-2.6.2/tmp</value>
</configuration>
yarn-site.xml
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>yun1:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value> yun1:8030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value> yun1:8031</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value> yun1:8033</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value> yun1:8088</value>
</property>
</configuration>
#在配置hdfs-site.xml前要先在hadoop根目录下建name和 data文件夹.
Hdfs-site.xml
<configuration>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>yun1:9001</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/home/ wclluck /hadoop-2.6.2/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/home/wclluck/hadoop-2.6.2/data</value>
</property>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
</configuration>
Step 5. 用scp命令向slave从机上复制hadoop,
scp –r ./hadoop-2.6.2 clwang@192.168.124.151:/home/clwang/ (这里r表示包括子目录)
Step6. 格式化namenode, 用bin/hdfs namenode –format 命令
Step 7. 启动hdfs, 用./sbin/start-dfs.sh命令
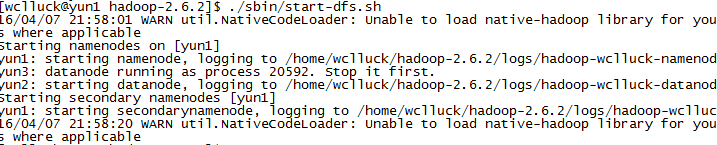
Step 8. 启动yarn: ./sbin/start-yarn.sh

Step 9. 用jps检验各后台是否启动成功.
在yun1上运行的进程有:namenode, secondarynamenode,resourcemanager
在yun2,yun3上面运行的进程有: datanode, nodemanager
经检验, 启动成功, hadoop集群配置完成.
验证: namenode页面

Resourcemanager页面

集群安装成功














 113
113











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









