







50070###1. 拓扑结构图
4台机器,搭建图如下
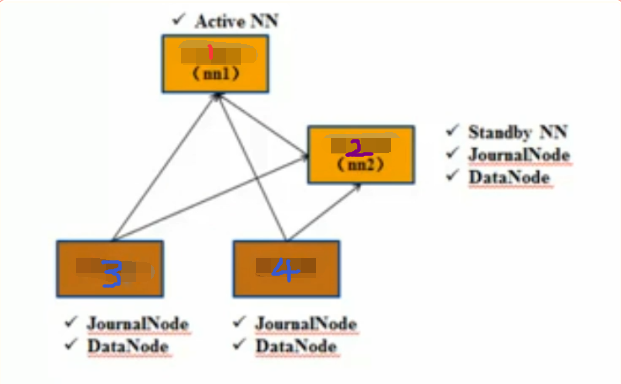
1,2,3,4 分别记做 Hagrid01,Hagrid02,Hagrid03,Hagrid04
NN指的是 Namenode
JN指的是JournalNode
DN指的是DataNode
生产环境下,Active NN 和 Standby NN 都应该单独占用一台机器,这里为了节省资源,StandbyNN上也做了 JN 和 DN
2. 对每台机器创建普通用户
我们一般不在root用户下跑hadoop,因此每台机器都需要创建普通用户
注意,为了方便ssh免密码登录,每台机器的用户名要一样,都为Hagrid01
使得每个机器的存放hadoop解压包的路径一样,
同时配置java的安装目录也要一样!
for 01,02,03,04
useradd -d /Hagrid/ Hagrid01
passwd Hagrid013 对每台机器添加每个机器的hosts 并设置ssh免密码登录
注意!同一个IP只能配置一个域名,不然后面运行命运时会出错!
设置hosts可以方便各个机器访问,后面的配置文件也写些
注意,hosts中本机的host的名字应该和hostname一致 不然后边会报错
注意要永久修改hostname:
要永久修改RedHat的hostname,就修改/etc/sysconfig/network文件,将里面的HOSTNAME这一行修改成HOSTNAME=NEWNAME
然后service network restart10.174.xxx.xxx Hagrid01
10.174.xxx.xxx Hagrid02
10.174.xxx.xxx Hagrid03
10.174..xxx.xxx Hagrid04ssh免密码登录,在启动和关闭服务时极大的提升效率
本地Linux用ssh-keygen创建密钥对。
然后使用ssh-copy-id -i /xxx/.ssh/id_rsa.pub xxx@
ssh-keygen
ssh-copy-id -i /xxx/.ssh/id_rsa.pub xxx@<aliyun机器ip>对于本机可以同样设置,但是要注意本机对 /xxx/.ssh的权限需要是700,如果是777则不会成功。
这样在Hagrid01@Hagrid01 上 通过
SSH Hagrid01
SSH Hagrid02
SSH Hagrid03
SSH Hagrid04就可以切换到其他机器,原因是我设置的其他机器的用户名还是Hagrid01,因此ssh默认的用户名是登录登录用户的用户名,所以直接ssh + 域名 即可登录其他机器!
4 将安装包分别放到各个用户的家目录,并解压
测试版本:2.6.2
http://hadoop.apache.org/releases.html
wget http://apache.fayea.com/hadoop/common/hadoop-2.6.2/hadoop-2.6.2.tar.gz
tar -zxf hadoop-2.6.2.tar.gz5 配置
所有的配置文件都在etc/hadoop 下,我们只需在一个节点上配置,然后将配置文件分发到各个机器就行了
5.1 首先修改:
./etc/hadoop/hadoop-env.sh
默认:
export JAVA_HOME=${JAVA_HOME}
修改为绝对路径:
# The java implementation to use.
export JAVA_HOME=/usr/java/jdk1.7.0_45-cloudera5.2 修改core-site.xml
这里的Active NN ,需要手动指定,因为我们没有搭建zookeeper
<property>
<name>fs.defaultFS</name>
<value>hdfs://Hagird01:8020</value>
</property>5.3 修改mapred-site.xml,如果没有则直接创建!
<?xml version="1.0" encoding="UTF-8"?>
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>Hagrid02:10020</value>
</property>
<property>
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 275
275











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









