







https://www.eriksmistad.no/getting-started-with-opencl-and-gpu-computing/
一、读取稀疏矩阵。先以一个简单的稀疏矩阵为例,读进这个稀疏矩阵
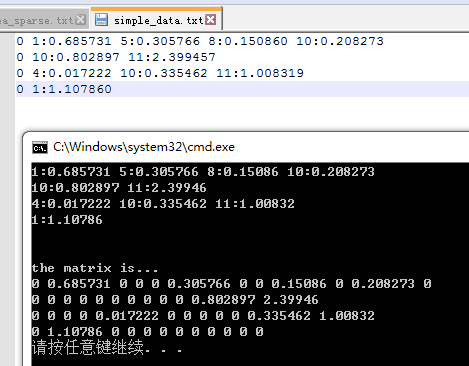
#include <stdio.h>
//#include <iostream>
#include <fstream>
#include <opencv2/highgui/highgui.hpp>
#include <opencv2/opencv.hpp>
using namespace std;
using namespace cv;
void main(){
int width = 12, height = 4;
float *matrix = new float[width*height];
memset(matrix, 0,width*height * sizeof(float));
ifstream infile("simple_data.txt");
vector<string> vec_str;
string line;
size_t curpos, pos_maohao, pos_kongge, pos_enter, prepos,lineLength;
//char *end;
int lineID=0;
while (getline(infile, line))
{
if (line.size() == 0)
{
continue;
}
for (size_t maohao1 = 0; maohao1 < line.size(); maohao1 = pos_maohao+7)
{
pos_maohao = line.find_first_of(":");
pos_kongge = line.find_first_of(" ");
if (pos_maohao == string::npos || pos_kongge == string::npos)
{
continue;
}
string tempIndex = line.substr(pos_kongge + 1, pos_maohao - pos_kongge-1);
string tempData = line.substr(pos_maohao+1, 8);
line = line.substr(pos_maohao + 9);
//int ind = static_cast<int>(strtol(tempIndex.c_str(), &end, 10));
int ind = atoi(tempIndex.c_str());
float data = atof(tempData.c_str());
cout << ind << ":"<< data << " ";
matrix[lineID*width + ind] = data;
}
lineID += 1;
cout << endl;
}
cout << endl << endl;
cout << "the matrix is..." << endl;
for (int i = 0; i < height;i++)
{
for (int j = 0; j < width;j++)
{
cout << matrix[i*width + j] << " ";
}
cout << endl;
}
infile.close();
delete[] matrix;
}一、写好的第一个KNN版本(先只拿前k个距离 而不是前k个最小距离 因为只是先测试一下是否写错):
在算一个200(高height)X931(宽width)的矩阵matrix,对于每一行去算它与另199行的距离,(它与自己这一行的距离为0 不用算),对于每一行可以得到一个200维的向量,取向量的前k个结果作为最终的距离矩阵instanceMatrix的结果(应该是200Xk的矩阵),这k个结果的位置矩阵positionMatrix(附带的,其实这个不用算) localsize是[1][512] globalsize是[100][1024]即有200个工作组 我是让每个工作组去算一行与另199行的距离。结果距离矩阵instanceMatrix中只有第1列是正确的 另k-1列是无意义的值 位置矩阵positionMatrix中k-1列无意义的值。
cl部分:
__kernel void knnForRobin(__global float *matrix,int width,int height,int k,__global int *positionMatrix,__global float *instanceMatrix,__local float *localSizeInstance,__local float *localInstanceNoSort)
{
uint currentGroupID=get_group_id(1)*get_num_groups(0)+get_group_id(0); //0--199
__global float *row=matrix+width*currentGroupID;
for(uint anotherID=0;anotherID<height;anotherID++)
{
if(anotherID==currentGroupID)
{
localInstanceNoSort[anotherID]=0;
continue;
}
float sum=0;
const __global float *rowAnother=matrix+width*anotherID;
for(uint j=get_local_id(0);j<width;j+=get_local_size(0))
{
sum+=(row[j]-rowAnother[j])*(row[j]-rowAnother[j]);
}
barrier(CLK_LOCAL_MEM_FENCE);
localSizeInstance[get_local_id(0)]=sum;
for (uint stride = get_local_size(0) / 2; stride > 0; stride /= 2)
{
barrier(CLK_LOCAL_MEM_FENCE);
if (get_local_id(0) < stride)
{
localSizeInstance[get_local_id(0)] += localSizeInstance[get_local_id(0) + stride];
}
}
if (get_local_id(0) == 0)
{
localInstanceNoSort[anotherID] = localSizeInstance[0];
}
barrier(CLK_LOCAL_MEM_FENCE);
}
// no sort
if(get_local_id(0)<k)
{
instanceMatrix[currentGroupID*k+get_local_id(0)]=localInstanceNoSort[get_local_id(0)];
positionMatrix[currentGroupID*k+get_local_id(0)]=get_local_id(0);
}
barrier(CLK_LOCAL_MEM_FENCE);
}#include <stdio.h>
#include <stdlib.h>
#include <CL/cl.h>
#include <fstream>
#include <vector>
#include "oclUtils.h"
#include "shrQATest.h"
using namespace std;
const int width=931;
const int height=200;
const int k=5;
void readTxt(const char *txtname,float *matrix)
{
//int width = 931, height = 200;
//float *matrix = new float[width*height];
//memset(matrix, 0,width*height * sizeof(float));
//ifstream infile("fea_sparse.txt");
ifstream infile(txtname);
vector<string> vec_str;
string line;
size_t curpos, pos_maohao, pos_kongge, pos_enter, prepos,lineLength;
//char *end;
int lineID=0;
while (getline(infile, line))
{
if (line.size() == 0)
{
continue;
}
for (size_t maohao1 = 0; maohao1 < line.size(); maohao1 = pos_maohao+7)
{
pos_maohao = line.find_first_of(":");
pos_kongge = line.find_first_of(" ");
if (pos_maohao == string::npos || pos_kongge == string::npos)
{
continue;
}
string tempIndex = line.substr(pos_kongge + 1, pos_maohao - pos_kongge-1);
string tempData = line.substr(pos_maohao+1, 8);
line = line.substr(pos_maohao + 9);
//int ind = static_cast<int>(strtol(tempIndex.c_str(), &end, 10));
int ind = atoi(tempIndex.c_str());
float data = atof(tempData.c_str());
//cout << ind << ":"<< data << " ";
matrix[lineID*width + ind] = data;
}
lineID += 1;
//cout << endl;
}
infile.close();
//delete[] matrix;
}
int main( int argc, const char** argv)
{
shrQAStart(argc, (char **)argv);
// set logfile name and start logs
shrSetLogFileName ("oclKnn4Robin.txt");
shrLog("%s Starting...\n\n", argv[0]);
//Get the NVIDIA platform
cl_platform_id cpPlatform;
cl_int ciErrNum = oclGetPlatformID(&cpPlatform);
oclCheckError(ciErrNum, CL_SUCCESS);
//Get the devices
cl_uint uiNumDevices;
ciErrNum = clGetDeviceIDs(cpPlatform, CL_DEVICE_TYPE_GPU, 0, NULL, &uiNumDevices);
oclCheckError(ciErrNum, CL_SUCCESS);
cl_device_id *cdDevices = (cl_device_id *)malloc(uiNumDevices * sizeof(cl_device_id) );
ciErrNum = clGetDeviceIDs(cpPlatform, CL_DEVICE_TYPE_GPU, uiNumDevices, cdDevices, NULL);
oclCheckError(ciErrNum, CL_SUCCESS);
//Create the context
cl_context cxGPUContext = clCreateContext(0, uiNumDevices, cdDevices, NULL, NULL, &ciErrNum);
oclCheckError(ciErrNum, CL_SUCCESS);
cl_device_id device ;
clGetDeviceIDs(cpPlatform,CL_DEVICE_TYPE_GPU,1,&device,NULL);
cl_command_queue commandQueue = clCreateCommandQueue(cxGPUContext, device, CL_QUEUE_PROFILING_ENABLE, &ciErrNum);
if (ciErrNum != CL_SUCCESS)
{
shrLog(" Error %i in clCreateCommandQueue call !!!\n\n", ciErrNum);
return ciErrNum;
}
//read kernel file and build it
size_t program_length;
char* source_path = shrFindFilePath("knn.cl", argv[0]);
oclCheckError(source_path != NULL, shrTRUE);
char *source = oclLoadProgSource(source_path, "", &program_length);
oclCheckError(source != NULL, shrTRUE);
// create the program
cl_program cpProgram = clCreateProgramWithSource(cxGPUContext, 1,(const char **)&source, &program_length, &ciErrNum);
oclCheckError(ciErrNum, CL_SUCCESS);
// build the program
ciErrNum = clBuildProgram(cpProgram, 0, NULL, "-cl-fast-relaxed-math", NULL, NULL);
if (ciErrNum != CL_SUCCESS)
{
// write out standard error, Build Log and PTX, then return error
shrLogEx(LOGBOTH | ERRORMSG, ciErrNum, STDERROR);
oclLogBuildInfo(cpProgram, oclGetFirstDev(cxGPUContext));
oclLogPtx(cpProgram, oclGetFirstDev(cxGPUContext), "oclknn.ptx");
return(EXIT_FAILURE);
}
cl_kernel ckKernel = clCreateKernel(cpProgram, "knnForRobin", &ciErrNum);
oclCheckError(ciErrNum, CL_SUCCESS);
//host data
float *matrix = new float[width*height];
const size_t matrixSize=width*height*sizeof(float);
memset(matrix, 0,matrixSize);
const char *txtfile="fea_sparse.txt";
readTxt(txtfile,matrix);
int *resultPosMatrix=new int[height*k];
size_t resultPosSize=height*k*sizeof(int);
memset(resultPosMatrix,0,resultPosSize);
float *resultInstanceMatrix=new float[height*k];
size_t resultInstanceSize=height*k*sizeof(float);
memset(resultInstanceMatrix,0,resultInstanceSize);
//send arguments to kernel file | CL_MEM_COPY_HOST_PTR
cl_mem matrix_buffer=clCreateBuffer(cxGPUContext, CL_MEM_READ_ONLY ,matrixSize, matrix, &ciErrNum);
cl_mem result_pos_buffer=clCreateBuffer(cxGPUContext,CL_MEM_WRITE_ONLY,resultPosSize,resultPosMatrix,&ciErrNum);
cl_mem result_ins_buffer=clCreateBuffer(cxGPUContext,CL_MEM_WRITE_ONLY,resultInstanceSize,resultInstanceMatrix,&ciErrNum);
ciErrNum = clEnqueueWriteBuffer(commandQueue, matrix_buffer, CL_FALSE, 0, matrixSize, matrix, 0, NULL, NULL);
oclCheckError(ciErrNum, CL_SUCCESS);
ciErrNum = clSetKernelArg(ckKernel, 0, sizeof(cl_mem), (void*)&matrix_buffer);
ciErrNum |= clSetKernelArg(ckKernel, 1, sizeof(int), &width);
ciErrNum |= clSetKernelArg(ckKernel, 2, sizeof(int), &height);
ciErrNum |= clSetKernelArg(ckKernel, 3, sizeof(int), &k);
ciErrNum |= clSetKernelArg(ckKernel, 4, sizeof(cl_mem), (void*)&result_pos_buffer);
ciErrNum |= clSetKernelArg(ckKernel, 5, sizeof(cl_mem), (void*)&result_ins_buffer);
//ciErrNum |= clSetKernelArg(ckKernel, 6, k * sizeof(float), 0);
ciErrNum |= clSetKernelArg(ckKernel, 6, 512*sizeof(float), 0);
ciErrNum |= clSetKernelArg(ckKernel, 7, height*sizeof(float), 0);
oclCheckError(ciErrNum, CL_SUCCESS);
size_t localsize[2]={1,512};
size_t globalsize[2]={100,1024};
clEnqueueNDRangeKernel(commandQueue, ckKernel, 2, NULL, globalsize, localsize,0, NULL, NULL);
int *positionHost=(int*)alloca(resultPosSize);
memset(positionHost,0,resultPosSize);
float *instanceHost=(float*)alloca(resultInstanceSize);
memset(instanceHost,0,resultInstanceSize);
ciErrNum = clEnqueueReadBuffer(commandQueue, result_pos_buffer, CL_TRUE, 0,resultPosSize, positionHost,0, NULL, NULL);
ciErrNum = clEnqueueReadBuffer(commandQueue, result_ins_buffer, CL_TRUE, 0,resultInstanceSize, instanceHost,0, NULL, NULL);
oclCheckError(ciErrNum, CL_SUCCESS);
//save as txt to check.
ofstream posOutfile("position.txt",ios::out);
ofstream instanceOutfile("instance.txt",ios::out);
for(size_t r=0;r<height;r++)
{
for(size_t c=0;c<k;c++)
{
int data=positionHost[r*k+c];
float instanceData=instanceHost[r*k+c];
posOutfile<<data<<"\t";
instanceOutfile<<instanceData<<"\t";
}
posOutfile<<endl;
instanceOutfile<<endl;
}
posOutfile.close();
instanceOutfile.close();
delete [] matrix;
delete [] resultPosMatrix;
delete [] resultInstanceMatrix;
clReleaseCommandQueue(commandQueue);
clReleaseContext(cxGPUContext);
clReleaseProgram(cpProgram);
clReleaseKernel(ckKernel);
shrLog("%s Successfully end.\n\n", argv[0]);
return 0;
}if(get_local_id(0)<k)
{
instanceMatrix[currentGroupID*k+get_local_id(0)]=localInstanceNoSort[get_local_id(0)];
positionMatrix[currentGroupID*k+get_local_id(0)]=get_local_id(0);
}ps:原来这个localsize[2]={M,N}实际是NXM 记住了。
ps:CL_DEVICE_MAX_WORK_ITEM_SIZES:1024X1024X64是对localsize每个维度的限制,即[0]<1024,[1]<1024,[2]<64, globalsize基本上是无限的,不用担心。 我之前以为那个就是globalsize的限制。太傻。
ps:CL_DEVICE_MAX_WORK_GROUP_SIZE: 1024 是说每个CU上三个维度总共最多1024个工作组。就是说localsize[0]*[1]*[2]<=1024!!!
另外大神夸了我,这个kernel写得很清晰,有进步。好开心!!!
这个版本与knn的区别就是取前k个最小的,而我取的直接就是前k个,这个后续再改就好了。
另外大神说,我这个忘记考虑一点了 不然可以节省一半的时间,除了我自己想到的“对每个group的511个线程拿当前行的地址是重复的511次 还有自己组的groupID也重复去拿了 还有别的行的地址也是重复拿了”这里外,还有更重要的一点,我这个版本,第1行去算它与第8行的距离,第8行还会算一次它与第1行的距离,所以重复了一倍的计算!我目前想的改进就是“让每个group代表行 只访问后续的group代表行即可解决你说的那个重复一半的问题 不让它向前追溯 ”当然这个是后话(等我把取前k个最小写完 编译运行都正确的情况下 再来对这个部分提高性能)。
另外大神还说了一个要注意事项:
二、第二个KNN版本(即仍旧是200X931的稀疏矩阵,取前k个最小距离及其相应位置,先不要求这k个最小距离一定要按从小到大排列)
我本来用的是CUDA里有的thrust下的sort.h,我想用sort_by_key()这个函数,于是在main.cpp前加入了#include <thrust/sort.h> 然后在cl文件中直接用sort_by_key(),这样距离和距离对应的位置可以跟着自动排序,但结果在编译kernel时报错:ptxas application ptx input, line16; fatal error :Parsing error near '[]': syntax error
ptxas: fatal error :Ptx assembly aborted due to errors
我检查了下,并不关第16行或者附近的[]的问题,我想应该是与网上比较多的“ptx, line 150; fatal error :Parsing error near '-': syntax error”这个报错就是因为路径中文,与什么150行的- 根本没关系。我感觉我这个也与[]没关系。但具体什么原因 谷歌不到?!!!!!!
这个kernel:
__kernel void knnForRobin(__global float *matrix,int width,int height,int k,__global int *positionMatrix,__global float *instanceMatrix,__local float *localSizeInstance,__local float *localInstanceNoSort,
__local float *localTempInst199,__local int *localTempPos199)
{
///the first step : calculate the distances!!!!
uint currentGroupID=get_group_id(1)*get_num_groups(0)+get_group_id(0); //0--199
__global float *row=matrix+width*currentGroupID;
for(uint anotherID=0;anotherID<height;anotherID++)
{
if(anotherID==currentGroupID)
{
localInstanceNoSort[anotherID]=0;
continue;
}
float sum=0;
const __global float *rowAnother=matrix+width*anotherID;
for(uint j=get_local_id(0);j<width;j+=get_local_size(0))
{
sum+=(row[j]-rowAnother[j])*(row[j]-rowAnother[j]);
}
barrier(CLK_LOCAL_MEM_FENCE);
localSizeInstance[get_local_id(0)]=sum;
for (uint stride = get_local_size(0) / 2; stride > 0; stride /= 2)
{
barrier(CLK_LOCAL_MEM_FENCE);
if (get_local_id(0) < stride)
{
localSizeInstance[get_local_id(0)] += localSizeInstance[get_local_id(0) + stride];
}
}
if (get_local_id(0) == 0)
{
localInstanceNoSort[anotherID] = localSizeInstance[0];
}
barrier(CLK_LOCAL_MEM_FENCE);
}
///erase the 0 instance (the instance from the current row to iteself).
if(get_local_id(0)<height)
{
if(get_local_id(0)<currentGroupID)
{
localTempInst199[get_local_id(0)]=localInstanceNoSort[get_local_id(0)];
localTempPos199[get_local_id(0)]=get_local_id(0);
}
else if(get_local_id(0)>currentGroupID)
{
localTempInst199[get_local_id(0)+1]=localInstanceNoSort[get_local_id(0)];
localTempPos199[get_local_id(0)]=get_local_id(0)+1;
}
else
{
;
}
}
barrier(CLK_LOCAL_MEM_FENCE);
extract the first k datas!!!
//solution1:
//sort()! but it cannot work!!!
if(get_local_id(0)==0)
{
//thrust::sort(localTempInst199,localTempInst199+199);
//thrust::sort_by_key(localTempInst199,localTempInst199+199,localTempPos199);
sort_by_key(localTempInst199,localTempInst199+199,localTempPos199);
}
barrier(CLK_LOCAL_MEM_FENCE);
if(get_local_id(0)<k)
{
instanceMatrix[currentGroupID*k+get_local_id(0)]=localTempInst199[get_local_id(0)];
positionMatrix[currentGroupID*k+get_local_id(0)]=localTempPos199[get_local_id(0)];
}
barrier(CLK_LOCAL_MEM_FENCE);
}所以我想 如果这个函数sort_by_key()不报错 那么这个版本的knn是可以用的。
三、第三个KNN版本
思路(我们公司的大神提供的思路,比我自己想的另一个好很多):在想一个从N(非常非常大)个数里拿出前k个最小值和对应位置(k<<N)。先用小一点的数实验:N=199,k=5,thread_num=10,每个线程负责20个数(thread9其实只负责19个数)。对于某个thread,比如负责的数是:2,1,7,3,9,5,10,2,7,3,6,5.9,9,3.5,7.2,8,8.8,17,1,12。这20个数对应的位置分别是8,1,3,7,6,24,48,15,0,12,41,26,59,33,14,57,89,57,31,55. 先把前k个数放进一个data数组里[2,1,7,3,9] 同时将对应位置前k个放进pos数组[8,1,3,7,6]。先算data的最大值max为9.然后这个线程将第6个数(第6个数为5)与max比较,如果小于max,则替换。(pos中对应地方也要替换)。结果data为[2,1,7,3,5],pos为[8,1,3,7,24]然后又计算这个data的最大值max=7,将第7个数(为10)与此max比较,大于max不用替换。继续将第8个数2与max=7比较,小于它,又替换掉7,此时data变成[2,1,2,3,5] pos变成[8,1,15,7,24]....此线程遍历到第20个数结束时,此线程将负责的20个数变成了只有k=5个。。。共10个线程,所以199个数变成了50个数。然后进行第2轮,需要三个线程,每个线程负责20个数。。。
按照这个思路,我开始写cl文件,写完了但结果不正确:
__kernel void knnForRobin(__global float *matrix,int width,int height,int k,__global int *positionMatrix,__global float *instanceMatrix,__local float *localSizeInstance,__local float *localInstanceNoSort,
__local float *localTempInst199,__local int *localTempPos199,
__local float *localTempInst50,__local int *localTempPos50,
__local float *localTempInst15,__local int *localTempPos15,
__local float *data,__local int *pos )
{
///the first step : calculate the distances!!!!
uint currentGroupID=get_group_id(1)*get_num_groups(0)+get_group_id(0); //0--199
__global float *row=matrix+width*currentGroupID;
for(uint anotherID=0;anotherID<height;anotherID++)
{
if(anotherID==currentGroupID)
{
localInstanceNoSort[anotherID]=0;
continue;
}
float sum=0;
const __global float *rowAnother=matrix+width*anotherID;
for(uint j=get_local_id(0);j<width;j+=get_local_size(0))
{
sum+=(row[j]-rowAnother[j])*(row[j]-rowAnother[j]);
}
barrier(CLK_LOCAL_MEM_FENCE);
localSizeInstance[get_local_id(0)]=sum;
for (uint stride = get_local_size(0) / 2; stride > 0; stride /= 2)
{
barrier(CLK_LOCAL_MEM_FENCE);
if (get_local_id(0) < stride)
{
localSizeInstance[get_local_id(0)] += localSizeInstance[get_local_id(0) + stride];
}
}
if (get_local_id(0) == 0)
{
localInstanceNoSort[anotherID] = localSizeInstance[0];
}
barrier(CLK_LOCAL_MEM_FENCE);
}
///erase the 0 instance (the instance from the current row to iteself).
if(get_local_id(0)<height)
{
if(get_local_id(0)<currentGroupID)
{
localTempInst199[get_local_id(0)]=localInstanceNoSort[get_local_id(0)];
localTempPos199[get_local_id(0)]=get_local_id(0);
}
else if(get_local_id(0)>currentGroupID)
{
localTempInst199[get_local_id(0)+1]=localInstanceNoSort[get_local_id(0)];
localTempPos199[get_local_id(0)]=get_local_id(0)+1;
}
else
{
;
}
}
barrier(CLK_LOCAL_MEM_FENCE);
extract the first k datas!!!
/* //solution1:
//sort()! but it cannot work!!!
if(get_local_id(0)==0)
{
//thrust::sort(localTempInst199,localTempInst199+199);
//thrust::sort_by_key(localTempInst199,localTempInst199+199,localTempPos199);
sort_by_key(localTempInst199,localTempInst199+199,localTempPos199);
}
barrier(CLK_LOCAL_MEM_FENCE);
if(get_local_id(0)<k)
{
instanceMatrix[currentGroupID*k+get_local_id(0)]=localTempInst199[get_local_id(0)];
}
barrier(CLK_LOCAL_MEM_FENCE);
*/
//solution2:use these instead!
//use the 10 threads of a group ,every thread include 20 datas,k=5
//circle0 ,handle with 199 datas!
if(get_local_id(0)<10)
{
//copy the forward k data and position
size_t ind=0;
for(size_t k0=get_local_id(0)*20;k0<get_local_id(0)*20+k;k0++,ind++)
{
data[ind]=localTempInst199[k0];
pos[ind]=localTempPos199[k0];
}
int the1st=get_local_id(0)*20+k;
int thelast=get_local_id(0)*20+20;
while(the1st<thelast)
{
if(get_local_id(0)==9 && the1st==199)
{
break;
}
//max from k
float kmaxdata=data[0];
int kmaxPos=pos[0];
int tempMaxPos=0;
for(size_t first=1;first<k;first++)
{
if(data[first]>kmaxdata)
{
kmaxdata=data[first];
kmaxPos=pos[first];
tempMaxPos=first;
}
}
if(localTempInst199[the1st]<kmaxdata)
{
data[tempMaxPos]=localTempInst199[the1st];
pos[tempMaxPos]=localTempPos199[the1st];
}
the1st+=1;
}
//result of circle0
for(size_t finalk0=0;finalk0<k;finalk0++)
{
localTempInst50[get_local_id(0)*k+finalk0]=data[finalk0];
localTempPos50[get_local_id(0)*k+finalk0]=pos[finalk0];
}
}
barrier(CLK_LOCAL_MEM_FENCE);
if(get_local_id(0)<3)
{
//copy the forward k data and position
size_t ind=0;
for(size_t k0=get_local_id(0)*20;k0<get_local_id(0)*20+k;k0++,ind++)
{
data[ind]=localTempInst50[k0];
pos[ind]=localTempPos50[k0];
}
int the1st=get_local_id(0)*20+k;
int thelast=get_local_id(0)*20+20;
while(the1st<thelast)
{
if(get_local_id(0)==2 && the1st==49)
{
break;
}
//max from k
float kmaxdata=data[0];
int kmaxPos=pos[0];
int tempMaxPos=0;
for(size_t first=1;first<k;first++)
{
if(data[first]>kmaxdata)
{
kmaxdata=data[first];
kmaxPos=pos[first];
tempMaxPos=first;
}
}
if(localTempInst50[the1st]<kmaxdata)
{
data[tempMaxPos]=localTempInst50[the1st];
pos[tempMaxPos]=localTempPos50[the1st];
}
the1st+=1;
}
//result of circle1
for(size_t finalk0=0;finalk0<k;finalk0++)
{
localTempInst15[get_local_id(0)*k+finalk0]=data[finalk0];
localTempPos15[get_local_id(0)*k+finalk0]=pos[finalk0];
}
}
barrier(CLK_LOCAL_MEM_FENCE);
if(get_local_id(0)<1)
{
//copy the forward k data and position
size_t ind=0;
for(size_t k0=get_local_id(0)*20;k0<get_local_id(0)*20+k;k0++,ind++)
{
data[ind]=localTempInst15[k0];
pos[ind]=localTempPos15[k0];
}
int the1st=get_local_id(0)*20+k;
int thelast=get_local_id(0)*20+20;
while(the1st<thelast)
{
if(the1st==15)
{
break;
}
//max from k
float kmaxdata=data[0];
int kmaxPos=pos[0];
int tempMaxPos=0;
for(size_t first=1;first<k;first++)
{
if(data[first]>kmaxdata)
{
kmaxdata=data[first];
kmaxPos=pos[first];
tempMaxPos=first;
}
}
if(localTempInst15[the1st]<kmaxdata)
{
data[tempMaxPos]=localTempInst15[the1st];
pos[tempMaxPos]=localTempPos15[the1st];
}
the1st+=1;
}
//result of circle2
for(size_t finalk0=0;finalk0<k;finalk0++)
{
instanceMatrix[currentGroupID*k+finalk0]=data[finalk0];
positionMatrix[currentGroupID*k+finalk0]=pos[finalk0];
}
}
barrier(CLK_LOCAL_MEM_FENCE);
}main.cpp文件:
/*
* main.cpp
*breaf:knn algorithm with OpenCL accelaration
* Created on: 2017年6月13日
* Author: root
*/
//#define __CL_ENABLE_EXCEPTIONS
#include <stdio.h>
#include <stdlib.h>
//#include <CL/cl.hpp>
#include <CL/cl.h>
#include <thrust/sort.h>
#include <fstream>
#include <vector>
#include "oclUtils.h"
#include "shrQATest.h"
using namespace std;
const int width=931;
const int height=200;
const int k=5;
void readTxt(const char *txtname,float *matrix)
{
//int width = 931, height = 200;
//float *matrix = new float[width*height];
//memset(matrix, 0,width*height * sizeof(float));
//ifstream infile("fea_sparse.txt");
ifstream infile(txtname);
vector<string> vec_str;
string line;
size_t curpos, pos_maohao, pos_kongge, pos_enter, prepos;//lineLength;
//char *end;
int lineID=0;
while (getline(infile, line))
{
if (line.size() == 0)
{
continue;
}
for (size_t maohao1 = 0; maohao1 < line.size(); maohao1 = pos_maohao+7)
{
pos_maohao = line.find_first_of(":");
pos_kongge = line.find_first_of(" ");
if (pos_maohao == string::npos || pos_kongge == string::npos)
{
continue;
}
string tempIndex = line.substr(pos_kongge + 1, pos_maohao - pos_kongge-1);
string tempData = line.substr(pos_maohao+1, 8);
line = line.substr(pos_maohao + 9);
//int ind = static_cast<int>(strtol(tempIndex.c_str(), &end, 10));
int ind = atoi(tempIndex.c_str());
float data = atof(tempData.c_str());
//cout << ind << ":"<< data << " ";
matrix[lineID*width + ind] = data;
}
lineID += 1;
//cout << endl;
}
infile.close();
//delete[] matrix;
}
int main( int argc, const char** argv)
{
shrQAStart(argc, (char **)argv);
// set logfile name and start logs
shrSetLogFileName ("oclKnn4Robin.txt");
shrLog("%s Starting...\n\n", argv[0]);
//Get the NVIDIA platform
cl_platform_id cpPlatform;
cl_int ciErrNum = oclGetPlatformID(&cpPlatform);
oclCheckError(ciErrNum, CL_SUCCESS);
//Get the devices
cl_uint uiNumDevices;
ciErrNum = clGetDeviceIDs(cpPlatform, CL_DEVICE_TYPE_GPU, 0, NULL, &uiNumDevices);
oclCheckError(ciErrNum, CL_SUCCESS);
cl_device_id *cdDevices = (cl_device_id *)malloc(uiNumDevices * sizeof(cl_device_id) );
ciErrNum = clGetDeviceIDs(cpPlatform, CL_DEVICE_TYPE_GPU, uiNumDevices, cdDevices, NULL);
oclCheckError(ciErrNum, CL_SUCCESS);
//Create the context
cl_context cxGPUContext = clCreateContext(0, uiNumDevices, cdDevices, NULL, NULL, &ciErrNum);
oclCheckError(ciErrNum, CL_SUCCESS);
cl_device_id device ;
clGetDeviceIDs(cpPlatform,CL_DEVICE_TYPE_GPU,1,&device,NULL);
cl_command_queue commandQueue = clCreateCommandQueue(cxGPUContext, device, CL_QUEUE_PROFILING_ENABLE, &ciErrNum);
if (ciErrNum != CL_SUCCESS)
{
shrLog(" Error %i in clCreateCommandQueue call !!!\n\n", ciErrNum);
return ciErrNum;
}
//read kernel file and build it
size_t program_length;
char* source_path = shrFindFilePath("knn.cl", argv[0]);
oclCheckError(source_path != NULL, shrTRUE);
char *source = oclLoadProgSource(source_path, "", &program_length);
oclCheckError(source != NULL, shrTRUE);
// create the program
cl_program cpProgram = clCreateProgramWithSource(cxGPUContext, 1,(const char **)&source, &program_length, &ciErrNum);
oclCheckError(ciErrNum, CL_SUCCESS);
// build the program
ciErrNum = clBuildProgram(cpProgram, 0, NULL, "-cl-fast-relaxed-math", NULL, NULL);
if (ciErrNum != CL_SUCCESS)
{
// write out standard error, Build Log and PTX, then return error
shrLogEx(LOGBOTH | ERRORMSG, ciErrNum, STDERROR);
oclLogBuildInfo(cpProgram, oclGetFirstDev(cxGPUContext));
oclLogPtx(cpProgram, oclGetFirstDev(cxGPUContext), "oclknn.ptx");
return(EXIT_FAILURE);
}
cl_kernel ckKernel = clCreateKernel(cpProgram, "knnForRobin", &ciErrNum);
oclCheckError(ciErrNum, CL_SUCCESS);
//host data
float *matrix = new float[width*height];
const size_t matrixSize=width*height*sizeof(float);
memset(matrix, 0,matrixSize);
const char *txtfile="fea_sparse.txt";
readTxt(txtfile,matrix);
int *resultPosMatrix=new int[height*k];
size_t resultPosSize=height*k*sizeof(int);
memset(resultPosMatrix,0,resultPosSize);
float *resultInstanceMatrix=new float[height*k];
size_t resultInstanceSize=height*k*sizeof(float);
memset(resultInstanceMatrix,0,resultInstanceSize);
//send arguments to kernel file | CL_MEM_COPY_HOST_PTR
cl_mem matrix_buffer=clCreateBuffer(cxGPUContext, CL_MEM_READ_ONLY ,matrixSize, matrix, &ciErrNum);
cl_mem result_pos_buffer=clCreateBuffer(cxGPUContext,CL_MEM_WRITE_ONLY,resultPosSize,resultPosMatrix,&ciErrNum);
cl_mem result_ins_buffer=clCreateBuffer(cxGPUContext,CL_MEM_WRITE_ONLY,resultInstanceSize,resultInstanceMatrix,&ciErrNum);
ciErrNum = clEnqueueWriteBuffer(commandQueue, matrix_buffer, CL_FALSE, 0, matrixSize, matrix, 0, NULL, NULL);
oclCheckError(ciErrNum, CL_SUCCESS);
ciErrNum = clSetKernelArg(ckKernel, 0, sizeof(cl_mem), (void*)&matrix_buffer);
ciErrNum |= clSetKernelArg(ckKernel, 1, sizeof(int), &width);
ciErrNum |= clSetKernelArg(ckKernel, 2, sizeof(int), &height);
ciErrNum |= clSetKernelArg(ckKernel, 3, sizeof(int), &k);
ciErrNum |= clSetKernelArg(ckKernel, 4, sizeof(cl_mem), (void*)&result_pos_buffer);
ciErrNum |= clSetKernelArg(ckKernel, 5, sizeof(cl_mem), (void*)&result_ins_buffer);
//ciErrNum |= clSetKernelArg(ckKernel, 6, k * sizeof(float), 0);
ciErrNum |= clSetKernelArg(ckKernel, 6, 512*sizeof(float), 0);
ciErrNum |= clSetKernelArg(ckKernel, 7, height*sizeof(float), 0);
ciErrNum |= clSetKernelArg(ckKernel, 8, 199*sizeof(float), 0);
ciErrNum |= clSetKernelArg(ckKernel, 9, 199*sizeof(int), 0);
ciErrNum |= clSetKernelArg(ckKernel, 10, 50*sizeof(float), 0);
ciErrNum |= clSetKernelArg(ckKernel, 11, 50*sizeof(int), 0);
ciErrNum |= clSetKernelArg(ckKernel, 12, 15*sizeof(float), 0);
ciErrNum |= clSetKernelArg(ckKernel, 13, 15*sizeof(int), 0);
ciErrNum |= clSetKernelArg(ckKernel, 14, k*sizeof(float), 0);
ciErrNum |= clSetKernelArg(ckKernel, 15, k*sizeof(int), 0);
oclCheckError(ciErrNum, CL_SUCCESS);
size_t localsize[2]={512,1};
size_t globalsize[2]={1024,200};
clEnqueueNDRangeKernel(commandQueue, ckKernel, 2, NULL, globalsize, localsize,0, NULL, NULL);
int *positionHost=(int*)alloca(resultPosSize);
memset(positionHost,0,resultPosSize);
float *instanceHost=(float*)alloca(resultInstanceSize);
memset(instanceHost,0,resultInstanceSize);
ciErrNum = clEnqueueReadBuffer(commandQueue, result_pos_buffer, CL_TRUE, 0,resultPosSize, positionHost,0, NULL, NULL);
ciErrNum = clEnqueueReadBuffer(commandQueue, result_ins_buffer, CL_TRUE, 0,resultInstanceSize, instanceHost,0, NULL, NULL);
oclCheckError(ciErrNum, CL_SUCCESS);
//save as txt to check.
ofstream posOutfile("position.txt",ios::out);
ofstream instanceOutfile("instance.txt",ios::out);
for(size_t r=0;r<height;r++)
{
for(size_t c=0;c<k;c++)
{
int data=positionHost[r*k+c];
float instanceData=instanceHost[r*k+c];
posOutfile<<data<<"\t";
instanceOutfile<<instanceData<<"\t";
}
posOutfile<<endl;
instanceOutfile<<endl;
}
posOutfile.close();
instanceOutfile.close();
delete [] matrix;
delete [] resultPosMatrix;
delete [] resultInstanceMatrix;
clReleaseCommandQueue(commandQueue);
clReleaseContext(cxGPUContext);
clReleaseProgram(cpProgram);
clReleaseKernel(ckKernel);
shrLog("%s Successfully end.\n\n", argv[0]);
return 0;
}因为总共存在5处bug:host上1处,cl上4处(大神帮我看到4处 自己只检查出1处)
1:host上的bug:
size_t globalsize[2]={1024,200};我要的是200个,在纸上规划好了结果这里心急写了200,实际是100,100*2=200。
2:cl上4处bug:
a:从200个距离中去掉与自己这一行的距离0时,我以为越过了那个空位,实际没有,大神帮我点出此处,然后自己修改正确。
b:本来10个线程处理199个数,最后一个线程是处理19个数,我就写的19而不是199!相应的后面我写的9而不是49.后来才改过来。
c:第2个for中 break的条件应该是==50就break!
d:对于每个线程data和pos我设置的是__local型,每个线程都可以操作这个,导致data race!应该设置成每个线程独享的而不是local。
修改好后全部正确并稳定:
修改后的cl文件:
__kernel void knnForRobin(__global float *matrix,int width,int height,int k,__global int *positionMatrix,__global float *instanceMatrix,
__local float *localSizeInstance,__local float *localInstanceNoSort,
__local float *localTempInst199,__local int *localTempPos199,
__local float *localTempInst50,__local int *localTempPos50,
__local float *localTempInst15,__local int *localTempPos15)
{
///the first step : calculate the distances!!!!
uint currentGroupID=get_group_id(1)*get_num_groups(0)+get_group_id(0); //0--199
__global float *row=matrix+width*currentGroupID;
for(uint anotherID=0;anotherID<height;anotherID++)
{
if(anotherID==currentGroupID)
{
localInstanceNoSort[anotherID]=0;
continue;
}
float sum=0;
const __global float *rowAnother=matrix+width*anotherID;
for(uint j=get_local_id(0);j<width;j+=get_local_size(0))
{
sum+=(row[j]-rowAnother[j])*(row[j]-rowAnother[j]);
}
barrier(CLK_LOCAL_MEM_FENCE);
localSizeInstance[get_local_id(0)]=sum;
for (uint stride = get_local_size(0) / 2; stride > 0; stride /= 2)
{
barrier(CLK_LOCAL_MEM_FENCE);
if (get_local_id(0) < stride)
{
localSizeInstance[get_local_id(0)] += localSizeInstance[get_local_id(0) + stride];
}
}
if (get_local_id(0) == 0)
{
localInstanceNoSort[anotherID] = localSizeInstance[0];
}
barrier(CLK_LOCAL_MEM_FENCE);
}
///erase the 0 instance (the instance from the current row to iteself).
if(get_local_id(0)<height-1)
{
if(get_local_id(0)<currentGroupID)
{
localTempInst199[get_local_id(0)]=localInstanceNoSort[get_local_id(0)];
localTempPos199[get_local_id(0)]=get_local_id(0);
}
else
{
localTempInst199[get_local_id(0)]=localInstanceNoSort[get_local_id(0)+1];
localTempPos199[get_local_id(0)]=get_local_id(0)+1;
}
}
barrier(CLK_LOCAL_MEM_FENCE);
extract the first k min datas!!!
//use the 10 threads of a group ,every thread include 20 datas,k=5
//circle0 ,handle with 199 datas!
if(get_local_id(0)<10)
{
//copy the forward k data and position
float data[5];
int pos[5];
size_t ind=0;
for(size_t k0=get_local_id(0)*20;k0<get_local_id(0)*20+k;k0++,ind++)
{
data[ind]=localTempInst199[k0];
pos[ind]=localTempPos199[k0];
}
int the1st=get_local_id(0)*20+k;
int thelast=get_local_id(0)*20+20;
while(the1st<thelast)
{
if(get_local_id(0)==9 && the1st>198)
{
break;
}
//max from k
float kmaxdata=data[0];
int kmaxPos=pos[0];
int tempMaxPos=0;
for(size_t first=1;first<k;first++)
{
if(data[first]>kmaxdata)
{
kmaxdata=data[first];
kmaxPos=pos[first];
tempMaxPos=first;
}
}
if(localTempInst199[the1st]<kmaxdata)
{
data[tempMaxPos]=localTempInst199[the1st];
pos[tempMaxPos]=localTempPos199[the1st];
}
the1st+=1;
}
//result of circle0
for(size_t finalk0=0;finalk0<k;finalk0++)
{
localTempInst50[get_local_id(0)*k+finalk0]=data[finalk0];
localTempPos50[get_local_id(0)*k+finalk0]=pos[finalk0];
}
}
barrier(CLK_LOCAL_MEM_FENCE);
/*
if(get_local_id(0)==0)
{
for(int r=0;r<50;r++)
{
int instanceData=localTempPos50[r];
printf("%d \n",instanceData);
}
}
barrier(CLK_LOCAL_MEM_FENCE);
*/
//circle1
if(get_local_id(0)<3)
{
//copy the forward k data and position
float data[5];
int pos[5];
size_t ind=0;
for(size_t k0=get_local_id(0)*20;k0<get_local_id(0)*20+k;k0++,ind++)
{
data[ind]=localTempInst50[k0];
pos[ind]=localTempPos50[k0];
}
int the1st=get_local_id(0)*20+k;
int thelast=get_local_id(0)*20+20;
while(the1st<thelast)
{
if(get_local_id(0)==2 && the1st==50)
{
break;
}
//max from k
float kmaxdata=data[0];
int kmaxPos=pos[0];
int tempMaxPos=0;
for(size_t first=1;first<k;first++)
{
if(data[first]>kmaxdata)
{
kmaxdata=data[first];
kmaxPos=pos[first];
tempMaxPos=first;
}
}
if(localTempInst50[the1st]<kmaxdata)
{
data[tempMaxPos]=localTempInst50[the1st];
pos[tempMaxPos]=localTempPos50[the1st];
}
the1st+=1;
}
//result of circle1
for(size_t finalk0=0;finalk0<k;finalk0++)
{
localTempInst15[get_local_id(0)*k+finalk0]=data[finalk0];
localTempPos15[get_local_id(0)*k+finalk0]=pos[finalk0];
}
}
barrier(CLK_LOCAL_MEM_FENCE);
/*
if(currentGroupID<200 && get_local_id(0)==0)
{
printf("group:%d data:%f %f %f %f %f %f %f %f %f %f %f %f %f %f %f\n",(int)currentGroupID,localTempInst15[0],localTempInst15[1],localTempInst15[2],localTempInst15[3],localTempInst15[4],localTempInst15[5],localTempInst15[6],localTempInst15[7],localTempInst15[8],localTempInst15[9],localTempInst15[10],localTempInst15[11],localTempInst15[12],localTempInst15[13],localTempInst15[14]);
}
barrier(CLK_LOCAL_MEM_FENCE);
*/
//circle2
if(get_local_id(0)<1)
{
//copy the forward k data and position
float data[5];
int pos[5];
size_t ind=0;
for(size_t k0=get_local_id(0)*20;k0<get_local_id(0)*20+k;k0++,ind++)
{
data[ind]=localTempInst15[k0];
pos[ind]=localTempPos15[k0];
}
int the1st=get_local_id(0)*20+k;
int thelast=get_local_id(0)*20+20;
while(the1st<thelast)
{
if(the1st>14)
{
break;
}
//max from k
float kmaxdata=data[0];
int kmaxPos=pos[0];
int tempMaxPos=0;
for(size_t first=1;first<k;first++)
{
if(data[first]>kmaxdata)
{
kmaxdata=data[first];
kmaxPos=pos[first];
tempMaxPos=first;
}
}
if(localTempInst15[the1st]<kmaxdata)
{
data[tempMaxPos]=localTempInst15[the1st];
pos[tempMaxPos]=localTempPos15[the1st];
}
the1st+=1;
}
//result of circle2
for(size_t finalk0=0;finalk0<k;finalk0++)
{
instanceMatrix[currentGroupID*k+finalk0]=data[finalk0];
positionMatrix[currentGroupID*k+finalk0]=pos[finalk0];
}
}
barrier(CLK_LOCAL_MEM_FENCE);
/*
if(currentGroupID<200 && get_local_id(0)==0)
{
printf("group:%d data:%f %f %f %f %f\n\n",(int)currentGroupID,instanceMatrix[currentGroupID*k+0],instanceMatrix[currentGroupID*k+1],instanceMatrix[currentGroupID*k+2],instanceMatrix[currentGroupID*k+3],instanceMatrix[currentGroupID*k+4]);
}
barrier(CLK_LOCAL_MEM_FENCE);
*/
}
const int width=931;
const int height=200;
const int k=5;
void readTxt(const char *txtname,float *matrix)
{
//int width = 931, height = 200;
//float *matrix = new float[width*height];
//memset(matrix, 0,width*height * sizeof(float));
//ifstream infile("fea_sparse.txt");
ifstream infile(txtname);
vector<string> vec_str;
string line;
size_t curpos, pos_maohao, pos_kongge, pos_enter, prepos;//lineLength;
//char *end;
int lineID=0;
while (getline(infile, line))
{
if (line.size() == 0)
{
continue;
}
for (size_t maohao1 = 0; maohao1 < line.size(); maohao1 = pos_maohao+7)
{
pos_maohao = line.find_first_of(":");
pos_kongge = line.find_first_of(" ");
if (pos_maohao == string::npos || pos_kongge == string::npos)
{
continue;
}
string tempIndex = line.substr(pos_kongge + 1, pos_maohao - pos_kongge-1);
string tempData = line.substr(pos_maohao+1, 8);
line = line.substr(pos_maohao + 9);
//int ind = static_cast<int>(strtol(tempIndex.c_str(), &end, 10));
int ind = atoi(tempIndex.c_str());
float data = atof(tempData.c_str());
//cout << ind << ":"<< data << " ";
matrix[lineID*width + ind] = data;
}
lineID += 1;
//cout << endl;
}
/*
cout << endl << endl;
cout << "the matrix is..." << endl;
for (int i = 0; i < height;i++)
{
for (int j = 0; j < width;j++)
{
cout << matrix[i*width + j] << " ";
}
cout << endl;
}
*/
infile.close();
//delete[] matrix;
}
int main( int argc, const char** argv)
{
shrQAStart(argc, (char **)argv);
// set logfile name and start logs
shrSetLogFileName ("oclKnn4Robin.txt");
shrLog("%s Starting...\n\n", argv[0]);
//Get the NVIDIA platform
cl_platform_id cpPlatform;
cl_int ciErrNum = oclGetPlatformID(&cpPlatform);
oclCheckError(ciErrNum, CL_SUCCESS);
//Get the devices
cl_uint uiNumDevices;
ciErrNum = clGetDeviceIDs(cpPlatform, CL_DEVICE_TYPE_GPU, 0, NULL, &uiNumDevices);
oclCheckError(ciErrNum, CL_SUCCESS);
cl_device_id *cdDevices = (cl_device_id *)malloc(uiNumDevices * sizeof(cl_device_id) );
ciErrNum = clGetDeviceIDs(cpPlatform, CL_DEVICE_TYPE_GPU, uiNumDevices, cdDevices, NULL);
oclCheckError(ciErrNum, CL_SUCCESS);
//Create the context
cl_context cxGPUContext = clCreateContext(0, uiNumDevices, cdDevices, NULL, NULL, &ciErrNum);
oclCheckError(ciErrNum, CL_SUCCESS);
cl_device_id device ;
clGetDeviceIDs(cpPlatform,CL_DEVICE_TYPE_GPU,1,&device,NULL);
cl_command_queue commandQueue = clCreateCommandQueue(cxGPUContext, device, CL_QUEUE_PROFILING_ENABLE, &ciErrNum);
if (ciErrNum != CL_SUCCESS)
{
shrLog(" Error %i in clCreateCommandQueue call !!!\n\n", ciErrNum);
return ciErrNum;
}
//read kernel file and build it
size_t program_length;
char* source_path = shrFindFilePath("knn.cl", argv[0]);
oclCheckError(source_path != NULL, shrTRUE);
char *source = oclLoadProgSource(source_path, "", &program_length);
oclCheckError(source != NULL, shrTRUE);
// create the program
cl_program cpProgram = clCreateProgramWithSource(cxGPUContext, 1,(const char **)&source, &program_length, &ciErrNum);
oclCheckError(ciErrNum, CL_SUCCESS);
// build the program
ciErrNum = clBuildProgram(cpProgram, 0, NULL, "-cl-fast-relaxed-math", NULL, NULL);
if (ciErrNum != CL_SUCCESS)
{
// write out standard error, Build Log and PTX, then return error
shrLogEx(LOGBOTH | ERRORMSG, ciErrNum, STDERROR);
oclLogBuildInfo(cpProgram, oclGetFirstDev(cxGPUContext));
oclLogPtx(cpProgram, oclGetFirstDev(cxGPUContext), "oclknn.ptx");
return(EXIT_FAILURE);
}
cl_kernel ckKernel = clCreateKernel(cpProgram, "knnForRobin", &ciErrNum);
oclCheckError(ciErrNum, CL_SUCCESS);
//host data
float *matrix = new float[width*height];
const size_t matrixSize=width*height*sizeof(float);
memset(matrix, 0,matrixSize);
const char *txtfile="fea_sparse.txt";
readTxt(txtfile,matrix);
int *resultPosMatrix=new int[height*k];
size_t resultPosSize=height*k*sizeof(int);
memset(resultPosMatrix,0,resultPosSize);
float *resultInstanceMatrix=new float[height*k];
size_t resultInstanceSize=height*k*sizeof(float);
memset(resultInstanceMatrix,0,resultInstanceSize);
cl_mem matrix_buffer=clCreateBuffer(cxGPUContext, CL_MEM_READ_ONLY ,matrixSize, matrix, &ciErrNum);
cl_mem result_pos_buffer=clCreateBuffer(cxGPUContext,CL_MEM_WRITE_ONLY,resultPosSize,resultPosMatrix,&ciErrNum);
cl_mem result_ins_buffer=clCreateBuffer(cxGPUContext,CL_MEM_WRITE_ONLY,resultInstanceSize,resultInstanceMatrix,&ciErrNum);
ciErrNum = clEnqueueWriteBuffer(commandQueue, matrix_buffer, CL_FALSE, 0, matrixSize, matrix, 0, NULL, NULL);
oclCheckError(ciErrNum, CL_SUCCESS);
ciErrNum = clSetKernelArg(ckKernel, 0, sizeof(cl_mem), (void*)&matrix_buffer);
ciErrNum |= clSetKernelArg(ckKernel, 1, sizeof(int), &width);
ciErrNum |= clSetKernelArg(ckKernel, 2, sizeof(int), &height);
ciErrNum |= clSetKernelArg(ckKernel, 3, sizeof(int), &k);
ciErrNum |= clSetKernelArg(ckKernel, 4, sizeof(cl_mem), (void*)&result_pos_buffer);
ciErrNum |= clSetKernelArg(ckKernel, 5, sizeof(cl_mem), (void*)&result_ins_buffer);
ciErrNum |= clSetKernelArg(ckKernel, 6, 512*sizeof(float), 0);
ciErrNum |= clSetKernelArg(ckKernel, 7, height*sizeof(float), 0);
ciErrNum |= clSetKernelArg(ckKernel, 8, 199*sizeof(float), 0);
ciErrNum |= clSetKernelArg(ckKernel, 9, 199*sizeof(int), 0);
ciErrNum |= clSetKernelArg(ckKernel, 10, 50*sizeof(float), 0);
ciErrNum |= clSetKernelArg(ckKernel, 11, 50*sizeof(int), 0);
ciErrNum |= clSetKernelArg(ckKernel, 12, 15*sizeof(float), 0);
ciErrNum |= clSetKernelArg(ckKernel, 13, 15*sizeof(int), 0);
oclCheckError(ciErrNum, CL_SUCCESS);
size_t localsize[2]={512,1};
size_t globalsize[2]={1024,100};
clEnqueueNDRangeKernel(commandQueue, ckKernel, 2, NULL, globalsize, localsize,0, NULL, NULL);
int *positionHost=(int*)alloca(resultPosSize);
memset(positionHost,0,resultPosSize);
float *instanceHost=(float*)alloca(resultInstanceSize);
memset(instanceHost,0,resultInstanceSize);
ciErrNum = clEnqueueReadBuffer(commandQueue, result_pos_buffer, CL_TRUE, 0,resultPosSize, positionHost,0, NULL, NULL);
ciErrNum = clEnqueueReadBuffer(commandQueue, result_ins_buffer, CL_TRUE, 0,resultInstanceSize, instanceHost,0, NULL, NULL);
oclCheckError(ciErrNum, CL_SUCCESS);
//save as txt to check.
ofstream posOutfile("position.txt",ios::out);
ofstream instanceOutfile("instance.txt",ios::out);
for(size_t r=0;r<height;r++)
{
for(size_t c=0;c<k;c++)
{
int data=positionHost[r*k+c];
float instanceData=instanceHost[r*k+c];
posOutfile<<data<<"\t";
instanceOutfile<<instanceData<<"\t";
}
posOutfile<<endl;
instanceOutfile<<endl;
}
posOutfile.close();
instanceOutfile.close();
delete [] matrix;
delete [] resultPosMatrix;
delete [] resultInstanceMatrix;
clReleaseCommandQueue(commandQueue);
clReleaseContext(cxGPUContext);
clReleaseProgram(cpProgram);
clReleaseKernel(ckKernel);
shrLog("%s Successfully end.\n\n", argv[0]);
return 0;
}
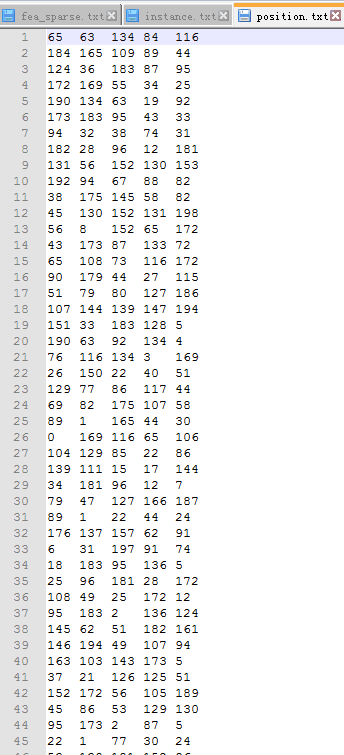
原稀疏矩阵:
另外大神说:

四、第4个KNN版本(仍旧是200X931的小测数据,但是计算距离时采用向下追溯节约时间)
__kernel void knn200ForRobin(__global float *matrix,int width,int height,int k,__global int *positionMatrix,__global float *instanceMatrix,__global float *localInstanceNoSort0)
{
///the first step : calculate the distances!!!!
uint currentGroupID=get_group_id(1)*get_num_groups(0)+get_group_id(0); //0--199
__global float *row=matrix+width*currentGroupID;
//__global float localInstanceNoSort0[40000];
__local float localSizeInstance[512];
localInstanceNoSort0[currentGroupID*height+currentGroupID]=0;
for(uint anotherID=currentGroupID+1;anotherID<height;anotherID++)
{
float sum=0;
const __global float *rowAnother=matrix+width*anotherID;
for(uint j=get_local_id(0);j<width;j+=get_local_size(0))
{
sum+=(row[j]-rowAnother[j])*(row[j]-rowAnother[j]);
}
barrier(CLK_LOCAL_MEM_FENCE);
localSizeInstance[get_local_id(0)]=sum;
for (uint stride = get_local_size(0) / 2; stride > 0; stride /= 2)
{
barrier(CLK_LOCAL_MEM_FENCE);
if (get_local_id(0) < stride)
{
localSizeInstance[get_local_id(0)] += localSizeInstance[get_local_id(0) + stride];
}
}
if (get_local_id(0) == 0)
{
localInstanceNoSort0[currentGroupID*height+anotherID] = localSizeInstance[0];
}
barrier(CLK_LOCAL_MEM_FENCE);
}
for(uint forward0=get_local_id(0);forward0<currentGroupID;forward0++)
{
localInstanceNoSort0[currentGroupID*height+forward0]=localInstanceNoSort0[forward0*height+currentGroupID];
}
barrier(CLK_LOCAL_MEM_FENCE);
//erase the 0 instance (the instance from the current row to iteself).
__local float localTempInst199[199];
__local int localTempPos199[199];
if(get_local_id(0)<height-1)
{
if(get_local_id(0)<currentGroupID)
{
localTempInst199[get_local_id(0)]=localInstanceNoSort0[currentGroupID*height+get_local_id(0)];
localTempPos199[get_local_id(0)]=get_local_id(0);
}
else
{
localTempInst199[get_local_id(0)]=localInstanceNoSort0[currentGroupID*height+get_local_id(0)+1];
localTempPos199[get_local_id(0)]=get_local_id(0)+1;
}
}
barrier(CLK_LOCAL_MEM_FENCE);
//extract the first k min datas!!!
__local float localTempInst50[50];
__local int localTempPos50[50];
//use the 10 threads of a group ,every thread include 20 datas,k=5
//circle0 ,handle with 199 datas!
if(get_local_id(0)<10)
{
//copy the forward k data and position
float data[5];
int pos[5];
size_t ind=0;
for(size_t k0=get_local_id(0)*20;k0<get_local_id(0)*20+k;k0++,ind++)
{
data[ind]=localTempInst199[k0];
pos[ind]=localTempPos199[k0];
}
int the1st=get_local_id(0)*20+k;
int thelast=get_local_id(0)*20+20;
while(the1st<thelast)
{
if(get_local_id(0)==9 && the1st>198)
{
break;
}
//max from k
float kmaxdata=data[0];
int kmaxPos=pos[0];
int tempMaxPos=0;
for(size_t first=1;first<k;first++)
{
if(data[first]>kmaxdata)
{
kmaxdata=data[first];
kmaxPos=pos[first];
tempMaxPos=first;
}
}
if(localTempInst199[the1st]<kmaxdata)
{
data[tempMaxPos]=localTempInst199[the1st];
pos[tempMaxPos]=localTempPos199[the1st];
}
the1st+=1;
}
//result of circle0
for(size_t finalk0=0;finalk0<k;finalk0++)
{
localTempInst50[get_local_id(0)*k+finalk0]=data[finalk0];
localTempPos50[get_local_id(0)*k+finalk0]=pos[finalk0];
}
}
barrier(CLK_LOCAL_MEM_FENCE);
/*
if(get_local_id(0)==0)
{
for(int r=0;r<50;r++)
{
int instanceData=localTempPos50[r];
printf("%d \n",instanceData);
}
}
barrier(CLK_LOCAL_MEM_FENCE);
*/
//circle1
__local float localTempInst15[15];
__local int localTempPos15[15];
if(get_local_id(0)<3)
{
//copy the forward k data and position
float data[5];
int pos[5];
size_t ind=0;
for(size_t k0=get_local_id(0)*20;k0<get_local_id(0)*20+k;k0++,ind++)
{
data[ind]=localTempInst50[k0];
pos[ind]=localTempPos50[k0];
}
int the1st=get_local_id(0)*20+k;
int thelast=get_local_id(0)*20+20;
while(the1st<thelast)
{
if(get_local_id(0)==2 && the1st==50)
{
break;
}
//max from k
float kmaxdata=data[0];
int kmaxPos=pos[0];
int tempMaxPos=0;
for(size_t first=1;first<k;first++)
{
if(data[first]>kmaxdata)
{
kmaxdata=data[first];
kmaxPos=pos[first];
tempMaxPos=first;
}
}
if(localTempInst50[the1st]<kmaxdata)
{
data[tempMaxPos]=localTempInst50[the1st];
pos[tempMaxPos]=localTempPos50[the1st];
}
the1st+=1;
}
//result of circle1
for(size_t finalk0=0;finalk0<k;finalk0++)
{
localTempInst15[get_local_id(0)*k+finalk0]=data[finalk0];
localTempPos15[get_local_id(0)*k+finalk0]=pos[finalk0];
}
}
barrier(CLK_LOCAL_MEM_FENCE);
/*
if(currentGroupID<200 && get_local_id(0)==0)
{
printf("group:%d data:%f %f %f %f %f %f %f %f %f %f %f %f %f %f %f\n",(int)currentGroupID,localTempInst15[0],localTempInst15[1],localTempInst15[2],localTempInst15[3],localTempInst15[4],localTempInst15[5],localTempInst15[6],localTempInst15[7],localTempInst15[8],localTempInst15[9],localTempInst15[10],localTempInst15[11],localTempInst15[12],localTempInst15[13],localTempInst15[14]);
}
barrier(CLK_LOCAL_MEM_FENCE);
*/
//circle2
if(get_local_id(0)<1)
{
//copy the forward k data and position
float data[5];
int pos[5];
size_t ind=0;
for(size_t k0=get_local_id(0)*20;k0<get_local_id(0)*20+k;k0++,ind++)
{
data[ind]=localTempInst15[k0];
pos[ind]=localTempPos15[k0];
}
int the1st=get_local_id(0)*20+k;
int thelast=get_local_id(0)*20+20;
while(the1st<thelast)
{
if(the1st>14)
{
break;
}
//max from k
float kmaxdata=data[0];
int kmaxPos=pos[0];
int tempMaxPos=0;
for(size_t first=1;first<k;first++)
{
if(data[first]>kmaxdata)
{
kmaxdata=data[first];
kmaxPos=pos[first];
tempMaxPos=first;
}
}
if(localTempInst15[the1st]<kmaxdata)
{
data[tempMaxPos]=localTempInst15[the1st];
pos[tempMaxPos]=localTempPos15[the1st];
}
the1st+=1;
}
//result of circle2
for(size_t finalk0=0;finalk0<k;finalk0++)
{
instanceMatrix[currentGroupID*k+finalk0]=data[finalk0];
positionMatrix[currentGroupID*k+finalk0]=pos[finalk0];
}
}
barrier(CLK_LOCAL_MEM_FENCE);
/*
if(currentGroupID<200 && get_local_id(0)==0)
{
printf("group:%d data:%f %f %f %f %f\n\n",(int)currentGroupID,instanceMatrix[currentGroupID*k+0],instanceMatrix[currentGroupID*k+1],instanceMatrix[currentGroupID*k+2],instanceMatrix[currentGroupID*k+3],instanceMatrix[currentGroupID*k+4]);
}
barrier(CLK_LOCAL_MEM_FENCE);
*/
}结果与前面一致,是正确的。时间第3个版本是:13262us,而此版本是:4960us!!!!!!!!整整一倍多的时间啊!!!!其实还可以继续优化的,不用每次比较k个中的最大值,上次没有变的最大值下次就不用比,这样会更快!
大神说: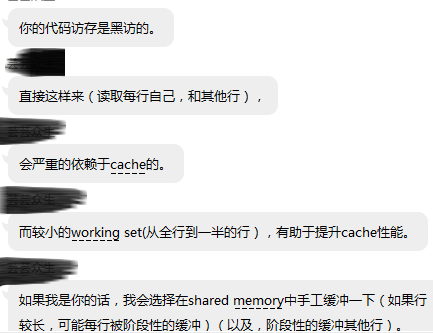
在写这个时,我开始是对localInstanceNoSort0[]这个是local型,OpenCL中只有barrier(CLK_LOCAL_MEM_FENCE)让同一个group内所有线程都到达这个栅栏点,再一起往下走。但opencl没有CLK_GLOBAL_MEM_FENCE这种说法,所以我后面的group中要拿前面某个group的结果,如果前面那个group还没有算完怎么给这个group!而且即使拿到了,第2个group的结果是data[]数组里,而第199个group的结果也是data[]。只是这两个data是并行,里面的东西不一样而已。但后面第199个group的data[]的前198个数要替换成第2个group的data[]的前198个数。虽然data是global型,但第199个group的data[0]要替换成第2个group的data[0],这无法做到啊因为分不清谁是谁的!所以我将这个变量改成了global类型,进行了一个变样,不过实质是达到了这个目的,这样就行了。也就是说几个Work Group,那么必须通过全局变量进行通信。
于是我开始是:__global float localInstanceNoSort0[40000]; 但报错说OpenCL不支持这样,然后我又在host端
ciErrNum |= clSetKernelArg(ckKernel, 6, 40000*sizeof(float), 0);结果报错说:<kernel>:error:global variables in function scope must have static storage class 所以后来我在host改成 正经的创建一个新数组,创建此数组的buffer然后写进kernel的第7个参数!这样才行了!所以我想应该是:kernel中要使用global类型的数组变量,此变量必须是从host传进来的实际变量,而不是像传local型一样给个大小赋0传进kernel就好了!
五、第5个KNN版本(2002350X931的矩阵,即假设稀疏矩阵还原后的样子)
__kernel void knn2002350ForRobin(__global float *matrix,int width,int height,int k,__global int *positionMatrix,__global float *instanceMatrix,__local float *localInstanceNoSort)
{
__local float localSizeInstance[931];
__local float localTempInst50[1024*5];
__local float localTempPos50[1024*5];
__local float localTempInst15[32*5];
__local float localTempPos15[32*5];
__local float localTempInst5[5*5];
__local float localTempPos5[5*5];
uint currentGroupID=get_group_id(1)*get_num_groups(0)+get_group_id(0);
for (size_t y = currentGroupID; y < height; y += get_local_size(0))
{
the first step : calculate the distances!!!!
__global float *row=matrix+width*y;
localInstanceNoSort[y*height+y]=0;
for(uint i=y+1;i<height;i+=1)
{
float sum=0;
const __global float *rowAnother=matrix+width*i;
for(uint j=get_local_id(0);j<width;j+=get_local_size(0))
{
sum+=(row[j]-rowAnother[j])*(row[j]-rowAnother[j]);
}
barrier(CLK_LOCAL_MEM_FENCE);
localSizeInstance[get_local_id(0)]=sum;
for (uint stride = get_local_size(0) / 2; stride > 0; stride /= 2)
{
barrier(CLK_LOCAL_MEM_FENCE);
if (get_local_id(0) < stride)
{
localSizeInstance[get_local_id(0)] += localSizeInstance[get_local_id(0) + stride];
}
}
if (get_local_id(0) == 0)
{
localInstanceNoSort[y*height+i] = localSizeInstance[0];
}
barrier(CLK_LOCAL_MEM_FENCE);
}
barrier(CLK_LOCAL_MEM_FENCE);
for(uint forward0=get_local_id(0);forward0<y;forward0+=get_local_size(0))
{
localInstanceNoSort[y*height+forward0]=localInstanceNoSort[forward0*height+y];
}
barrier(CLK_LOCAL_MEM_FENCE);
/erase the 0 instance (the instance from the current row to iteself).
__local float localTempInst199[2002349];
__local int localTempPos199[2002349];
for(uint t=get_local_id(0);t<height-1;t+=get_local_size(0))
{
if(t<currentGroupID)
{
localTempInst199[t]=localInstanceNoSort[currentGroupID*height+t];
localTempPos199[t]=t;
}
else
{
localTempInst199[t]=localInstanceNoSort[currentGroupID*height+t+1];
localTempPos199[t]=t+1;
}
}
barrier(CLK_LOCAL_MEM_FENCE);
///extract the first k min datas!!!
//use the 1024 threads of a group ,every thread include 1956 datas,k=5
//circle0 ,handle with 2002349 datas!
//copy the forward k data and position
float data[5];
int pos[5];
size_t ind=0;
for(size_t k0=get_local_id(0)*1956;k0<get_local_id(0)*1956+k;k0++,ind++)
{
data[ind]=localTempInst199[k0];
pos[ind]=localTempPos199[k0];
}
int the1st=get_local_id(0)*1956+k;
int thelast=get_local_id(0)*1956+1956;
while(the1st<thelast)
{
if(get_local_id(0)==1023 && the1st>2002348)
{
break;
}
//max from k
float kmaxdata=data[0];
int kmaxPos=pos[0];
int tempMaxPos=0;
for(size_t first=1;first<k;first++)
{
if(data[first]>kmaxdata)
{
kmaxdata=data[first];
kmaxPos=pos[first];
tempMaxPos=first;
}
}
if(localTempInst199[the1st]<kmaxdata)
{
data[tempMaxPos]=localTempInst199[the1st];
pos[tempMaxPos]=localTempPos199[the1st];
}
the1st+=1;
}
//result of circle0
for(size_t finalk0=0;finalk0<k;finalk0++)
{
localTempInst50[get_local_id(0)*k+finalk0]=data[finalk0];
localTempPos50[get_local_id(0)*k+finalk0]=pos[finalk0];
}
barrier(CLK_LOCAL_MEM_FENCE);
//circle1
if(get_local_id(0)<32)
{
//copy the forward k data and position
float data[5];
int pos[5];
size_t ind=0;
for(size_t k0=get_local_id(0)*32*k;k0<get_local_id(0)*32*k+k;k0++,ind++)
{
data[ind]=localTempInst50[k0];
pos[ind]=localTempPos50[k0];
}
int the1st=get_local_id(0)*32*k+k;
int thelast=get_local_id(0)*32*k+32*k;
while(the1st<thelast)
{
//max from k
float kmaxdata=data[0];
int kmaxPos=pos[0];
int tempMaxPos=0;
for(size_t first=1;first<k;first++)
{
if(data[first]>kmaxdata)
{
kmaxdata=data[first];
kmaxPos=pos[first];
tempMaxPos=first;
}
}
if(localTempInst50[the1st]<kmaxdata)
{
data[tempMaxPos]=localTempInst50[the1st];
pos[tempMaxPos]=localTempPos50[the1st];
}
the1st+=1;
}
//result of circle1
for(size_t finalk0=0;finalk0<k;finalk0++)
{
localTempInst15[get_local_id(0)*k+finalk0]=data[finalk0];
localTempPos15[get_local_id(0)*k+finalk0]=pos[finalk0];
}
}
barrier(CLK_LOCAL_MEM_FENCE);
//circle2
if(get_local_id(0)<5)
{
//copy the forward k data and position
float data[5];
int pos[5];
size_t ind=0;
for(size_t k0=get_local_id(0)*32;k0<get_local_id(0)*32*+k;k0++,ind++)
{
data[ind]=localTempInst50[k0];
pos[ind]=localTempPos50[k0];
}
int the1st=get_local_id(0)*32+k;
int thelast=get_local_id(0)*32+32;
while(the1st<thelast)
{
//max from k
float kmaxdata=data[0];
int kmaxPos=pos[0];
int tempMaxPos=0;
for(size_t first=1;first<k;first++)
{
if(data[first]>kmaxdata)
{
kmaxdata=data[first];
kmaxPos=pos[first];
tempMaxPos=first;
}
}
if(localTempInst15[the1st]<kmaxdata)
{
data[tempMaxPos]=localTempInst15[the1st];
pos[tempMaxPos]=localTempPos15[the1st];
}
the1st+=1;
}
//result of circle1
for(size_t finalk0=0;finalk0<k;finalk0++)
{
localTempInst5[get_local_id(0)*k+finalk0]=data[finalk0];
localTempPos5[get_local_id(0)*k+finalk0]=pos[finalk0];
}
}
barrier(CLK_LOCAL_MEM_FENCE);
//circle2
if(get_local_id(0)<1)
{
//copy the forward k data and position
float data[5];
int pos[5];
size_t ind=0;
for(size_t k0=get_local_id(0);k0<get_local_id(0)+k;k0++,ind++)
{
data[ind]=localTempInst5[k0];
pos[ind]=localTempPos5[k0];
}
int the1st=k;
int thelast=25;
while(the1st<thelast)
{
//max from k
float kmaxdata=data[0];
int kmaxPos=pos[0];
int tempMaxPos=0;
for(size_t first=1;first<k;first++)
{
if(data[first]>kmaxdata)
{
kmaxdata=data[first];
kmaxPos=pos[first];
tempMaxPos=first;
}
}
if(localTempInst15[the1st]<kmaxdata)
{
data[tempMaxPos]=localTempInst15[the1st];
pos[tempMaxPos]=localTempPos15[the1st];
}
the1st+=1;
}
//result of circle2
for(size_t finalk0=0;finalk0<k;finalk0++)
{
instanceMatrix[currentGroupID*k+finalk0]=data[finalk0];
positionMatrix[currentGroupID*k+finalk0]=pos[finalk0];
}
}
barrier(CLK_LOCAL_MEM_FENCE);
}
}但这个kernel不够好,改成下面这样线程利用率更高:
__kernel void knn2002350ForRobin(__global float *matrix,int width,int height,int k,__global int *positionMatrix,__global float *instanceMatrix,__local float *localInstanceNoSort)
{
__local float localSizeInstance[931];
__local float localTempInst50[1024*5];
__local float localTempPos50[1024*5];
__local float localTempInst15[32*5];
__local float localTempPos15[32*5];
__local float localTempInst5[5*5];
__local float localTempPos5[5*5];
uint currentGroupID=get_group_id(1)*get_num_groups(0)+get_group_id(0);
for (size_t y = currentGroupID; y < height; y += get_local_size(0))
{
the first step : calculate the distances!!!!
__global float *row=matrix+width*y;
localInstanceNoSort[y*height+y]=0;
for(uint i=get_local_id(0)+y+1;i<height;i+=get_local_size(0))
{
float sum=0;
const __global float *rowAnother=matrix+width*i;
for(uint j=0;j<width;j+=1)
{
sum+=(row[j]-rowAnother[j])*(row[j]-rowAnother[j]);
}
localInstanceNoSort[y*height+i] = sum;
}
barrier(CLK_LOCAL_MEM_FENCE);
for(uint forward0=get_local_id(0);forward0<y;forward0+=get_local_size(0))
{
localInstanceNoSort[y*height+forward0]=localInstanceNoSort[forward0*height+y];
}
barrier(CLK_LOCAL_MEM_FENCE);
/erase the 0 instance (the instance from the current row to iteself).
__local float localTempInst199[2002349];
__local int localTempPos199[2002349];
for(uint t=get_local_id(0);t<height-1;t+=get_local_size(0))
{
if(t<currentGroupID)
{
localTempInst199[t]=localInstanceNoSort[currentGroupID*height+t];
localTempPos199[t]=t;
}
else
{
localTempInst199[t]=localInstanceNoSort[currentGroupID*height+t+1];
localTempPos199[t]=t+1;
}
}
barrier(CLK_LOCAL_MEM_FENCE);
///extract the first k min datas!!!
//use the 1024 threads of a group ,every thread include 1956 datas,k=5
//circle0 ,handle with 2002349 datas!
//copy the forward k data and position
float data[5];
int pos[5];
size_t ind=0;
for(size_t k0=get_local_id(0)*1956;k0<get_local_id(0)*1956+k;k0++,ind++)
{
data[ind]=localTempInst199[k0];
pos[ind]=localTempPos199[k0];
}
int the1st=get_local_id(0)*1956+k;
int thelast=get_local_id(0)*1956+1956;
while(the1st<thelast)
{
if(get_local_id(0)==1023 && the1st>2002348)
{
break;
}
//max from k
float kmaxdata=data[0];
int kmaxPos=pos[0];
int tempMaxPos=0;
for(size_t first=1;first<k;first++)
{
if(data[first]>kmaxdata)
{
kmaxdata=data[first];
kmaxPos=pos[first];
tempMaxPos=first;
}
}
if(localTempInst199[the1st]<kmaxdata)
{
data[tempMaxPos]=localTempInst199[the1st];
pos[tempMaxPos]=localTempPos199[the1st];
}
the1st+=1;
}
//result of circle0
for(size_t finalk0=0;finalk0<k;finalk0++)
{
localTempInst50[get_local_id(0)*k+finalk0]=data[finalk0];
localTempPos50[get_local_id(0)*k+finalk0]=pos[finalk0];
}
barrier(CLK_LOCAL_MEM_FENCE);
//circle1
if(get_local_id(0)<32)
{
//copy the forward k data and position
float data[5];
int pos[5];
size_t ind=0;
for(size_t k0=get_local_id(0)*32*k;k0<get_local_id(0)*32*k+k;k0++,ind++)
{
data[ind]=localTempInst50[k0];
pos[ind]=localTempPos50[k0];
}
int the1st=get_local_id(0)*32*k+k;
int thelast=get_local_id(0)*32*k+32*k;
while(the1st<thelast)
{
//max from k
float kmaxdata=data[0];
int kmaxPos=pos[0];
int tempMaxPos=0;
for(size_t first=1;first<k;first++)
{
if(data[first]>kmaxdata)
{
kmaxdata=data[first];
kmaxPos=pos[first];
tempMaxPos=first;
}
}
if(localTempInst50[the1st]<kmaxdata)
{
data[tempMaxPos]=localTempInst50[the1st];
pos[tempMaxPos]=localTempPos50[the1st];
}
the1st+=1;
}
//result of circle1
for(size_t finalk0=0;finalk0<k;finalk0++)
{
localTempInst15[get_local_id(0)*k+finalk0]=data[finalk0];
localTempPos15[get_local_id(0)*k+finalk0]=pos[finalk0];
}
}
barrier(CLK_LOCAL_MEM_FENCE);
//circle2
if(get_local_id(0)<5)
{
//copy the forward k data and position
float data[5];
int pos[5];
size_t ind=0;
for(size_t k0=get_local_id(0)*32;k0<get_local_id(0)*32*+k;k0++,ind++)
{
data[ind]=localTempInst50[k0];
pos[ind]=localTempPos50[k0];
}
int the1st=get_local_id(0)*32+k;
int thelast=get_local_id(0)*32+32;
while(the1st<thelast)
{
//max from k
float kmaxdata=data[0];
int kmaxPos=pos[0];
int tempMaxPos=0;
for(size_t first=1;first<k;first++)
{
if(data[first]>kmaxdata)
{
kmaxdata=data[first];
kmaxPos=pos[first];
tempMaxPos=first;
}
}
if(localTempInst15[the1st]<kmaxdata)
{
data[tempMaxPos]=localTempInst15[the1st];
pos[tempMaxPos]=localTempPos15[the1st];
}
the1st+=1;
}
//result of circle1
for(size_t finalk0=0;finalk0<k;finalk0++)
{
localTempInst5[get_local_id(0)*k+finalk0]=data[finalk0];
localTempPos5[get_local_id(0)*k+finalk0]=pos[finalk0];
}
}
barrier(CLK_LOCAL_MEM_FENCE);
//circle2
if(get_local_id(0)<1)
{
//copy the forward k data and position
float data[5];
int pos[5];
size_t ind=0;
for(size_t k0=get_local_id(0);k0<get_local_id(0)+k;k0++,ind++)
{
data[ind]=localTempInst5[k0];
pos[ind]=localTempPos5[k0];
}
int the1st=k;
int thelast=25;
while(the1st<thelast)
{
//max from k
float kmaxdata=data[0];
int kmaxPos=pos[0];
int tempMaxPos=0;
for(size_t first=1;first<k;first++)
{
if(data[first]>kmaxdata)
{
kmaxdata=data[first];
kmaxPos=pos[first];
tempMaxPos=first;
}
}
if(localTempInst15[the1st]<kmaxdata)
{
data[tempMaxPos]=localTempInst15[the1st];
pos[tempMaxPos]=localTempPos15[the1st];
}
the1st+=1;
}
//result of circle2
for(size_t finalk0=0;finalk0<k;finalk0++)
{
instanceMatrix[currentGroupID*k+finalk0]=data[finalk0];
positionMatrix[currentGroupID*k+finalk0]=pos[finalk0];
}
}
barrier(CLK_LOCAL_MEM_FENCE);
}
}
#include <stdio.h>
#include <stdlib.h>
//#include <CL/cl.hpp>
#include <CL/cl.h>
#include <time.h>
#include <fstream>
#include <vector>
#include "oclUtils.h"
#include "shrQATest.h"
using namespace std;
const int width=931;
const int height=200;
const int height2=2002350;
const int k=5;
int64_t system_time()
{
struct timespec t;
clock_gettime(CLOCK_MONOTONIC,&t);
return (int64_t)(t.tv_sec)*1e9+t.tv_nsec;
}
int main( int argc, const char** argv)
{
shrQAStart(argc, (char **)argv);
// set logfile name and start logs
shrSetLogFileName ("oclKnn4Robin.txt");
shrLog("%s Starting...\n\n", argv[0]);
//Get the NVIDIA platform
cl_platform_id cpPlatform;
cl_int ciErrNum = oclGetPlatformID(&cpPlatform);
oclCheckError(ciErrNum, CL_SUCCESS);
//Get the devices
cl_uint uiNumDevices;
ciErrNum = clGetDeviceIDs(cpPlatform, CL_DEVICE_TYPE_GPU, 0, NULL, &uiNumDevices);
oclCheckError(ciErrNum, CL_SUCCESS);
cl_device_id *cdDevices = (cl_device_id *)malloc(uiNumDevices * sizeof(cl_device_id) );
ciErrNum = clGetDeviceIDs(cpPlatform, CL_DEVICE_TYPE_GPU, uiNumDevices, cdDevices, NULL);
oclCheckError(ciErrNum, CL_SUCCESS);
//Create the context
cl_context cxGPUContext = clCreateContext(0, uiNumDevices, cdDevices, NULL, NULL, &ciErrNum);
oclCheckError(ciErrNum, CL_SUCCESS);
cl_device_id device ;
clGetDeviceIDs(cpPlatform,CL_DEVICE_TYPE_GPU,1,&device,NULL);
cl_command_queue commandQueue = clCreateCommandQueue(cxGPUContext, device, CL_QUEUE_PROFILING_ENABLE, &ciErrNum);
if (ciErrNum != CL_SUCCESS)
{
shrLog(" Error %i in clCreateCommandQueue call !!!\n\n", ciErrNum);
return ciErrNum;
}
//read kernel file and build it
size_t program_length;
char* source_path = shrFindFilePath("knn2002350.cl", argv[0]);
oclCheckError(source_path != NULL, shrTRUE);
char *source = oclLoadProgSource(source_path, "", &program_length);
oclCheckError(source != NULL, shrTRUE);
// create the program
cl_program cpProgram = clCreateProgramWithSource(cxGPUContext, 1,(const char **)&source, &program_length, &ciErrNum);
oclCheckError(ciErrNum, CL_SUCCESS);
// build the program
ciErrNum = clBuildProgram(cpProgram, 0, NULL, "-cl-fast-relaxed-math", NULL, NULL);
if (ciErrNum != CL_SUCCESS)
{
// write out standard error, Build Log and PTX, then return error
shrLogEx(LOGBOTH | ERRORMSG, ciErrNum, STDERROR);
oclLogBuildInfo(cpProgram, oclGetFirstDev(cxGPUContext));
oclLogPtx(cpProgram, oclGetFirstDev(cxGPUContext), "oclknn.ptx");
return(EXIT_FAILURE);
}
cl_kernel ckKernel = clCreateKernel(cpProgram, "knn2002350ForRobin", &ciErrNum);
oclCheckError(ciErrNum, CL_SUCCESS);
//host data
float *matrix;
const int matrixSizeNoFloat=width*height2;
const size_t matrixSize=matrixSizeNoFloat*sizeof(float);
matrix=(float*)malloc(matrixSize);
shrFillArray(matrix,matrixSizeNoFloat);
size_t resultPosSize=height2*k*sizeof(int);
int *resultPosMatrix=(int*)malloc(resultPosSize);
memset(resultPosMatrix,0,resultPosSize);
size_t resultInstanceSize=height2*k*sizeof(float);
float *resultInstanceMatrix=(float*)malloc(resultInstanceSize);
shrFillArray(resultInstanceMatrix,height2*k);
size_t localsize[2]={1024,1};
size_t globalsize[2]={1024,1024};
cl_mem matrix_buffer=clCreateBuffer(cxGPUContext, CL_MEM_READ_ONLY ,matrixSize, matrix, &ciErrNum);
cl_mem result_pos_buffer=clCreateBuffer(cxGPUContext,CL_MEM_WRITE_ONLY,resultPosSize,resultPosMatrix,&ciErrNum);
cl_mem result_ins_buffer=clCreateBuffer(cxGPUContext,CL_MEM_WRITE_ONLY,resultInstanceSize,resultInstanceMatrix,&ciErrNum);
ciErrNum = clEnqueueWriteBuffer(commandQueue, matrix_buffer, CL_FALSE, 0, matrixSize, matrix, 0, NULL, NULL);
oclCheckError(ciErrNum, CL_SUCCESS);
ciErrNum = clSetKernelArg(ckKernel, 0, sizeof(cl_mem), (void*)&matrix_buffer);
ciErrNum |= clSetKernelArg(ckKernel, 1, sizeof(int), &width);
ciErrNum |= clSetKernelArg(ckKernel, 2, sizeof(int), &height2);
ciErrNum |= clSetKernelArg(ckKernel, 3, sizeof(int), &k);
ciErrNum |= clSetKernelArg(ckKernel, 4, sizeof(cl_mem), (void*)&result_pos_buffer);
ciErrNum |= clSetKernelArg(ckKernel, 5, sizeof(cl_mem), (void*)&result_ins_buffer);
size_t NoSortSize=height2*height2*sizeof(float);
float *NoSort=(float*)malloc(NoSortSize);
memset(NoSort,0,NoSortSize);
cl_mem NoSort_buffer=clCreateBuffer(cxGPUContext,CL_MEM_READ_WRITE,NoSortSize,NoSort,&ciErrNum);
ciErrNum = clEnqueueWriteBuffer(commandQueue, NoSort_buffer, CL_FALSE, 0, NoSortSize, NoSort, 0, NULL, NULL);
ciErrNum |= clSetKernelArg(ckKernel, 6, sizeof(cl_mem), (void*)&NoSort_buffer);
oclCheckError(ciErrNum, CL_SUCCESS);
clFinish(commandQueue);
int64_t time_start=system_time();
clEnqueueNDRangeKernel(commandQueue, ckKernel, 2, NULL, globalsize, localsize,0, NULL, NULL);
clFinish(commandQueue);
int64_t time_end=system_time();
printf("kernel execute time: %f(us)\n",(time_end-time_start)/1e3);
int *positionHost=(int*)alloca(resultPosSize);
memset(positionHost,0,resultPosSize);
float *instanceHost=(float*)alloca(resultInstanceSize);
memset(instanceHost,0,resultInstanceSize);
ciErrNum = clEnqueueReadBuffer(commandQueue, result_pos_buffer, CL_TRUE, 0,resultPosSize, positionHost,0, NULL, NULL);
ciErrNum = clEnqueueReadBuffer(commandQueue, result_ins_buffer, CL_TRUE, 0,resultInstanceSize, instanceHost,0, NULL, NULL);
oclCheckError(ciErrNum, CL_SUCCESS);
//save as txt to check.
ofstream posOutfile("position2002350.txt",ios::out);
ofstream instanceOutfile("distance2002350.txt",ios::out);
for(size_t r=0;r<height2;r++)
{
for(size_t c=0;c<k;c++)
{
int data=positionHost[r*k+c];
float instanceData=instanceHost[r*k+c];
posOutfile<<data<<"\t";
instanceOutfile<<instanceData<<"\t";
}
posOutfile<<endl;
instanceOutfile<<endl;
}
posOutfile.close();
instanceOutfile.close();
free(matrix);
free(resultPosMatrix);
free(resultInstanceMatrix);
clReleaseCommandQueue(commandQueue);
clReleaseContext(cxGPUContext);
clReleaseProgram(cpProgram);
clReleaseKernel(ckKernel);
shrLog("%s Successfully end.\n\n", argv[0]);
return 0;
}大神说:
__local float localTempInst199[2002349];
__local int localTempPos199[2002349];
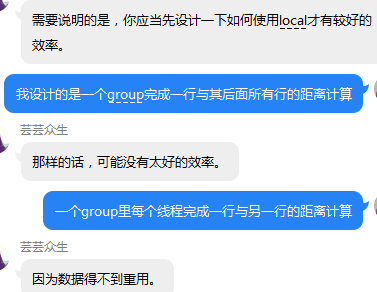
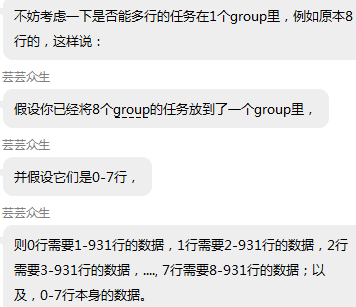
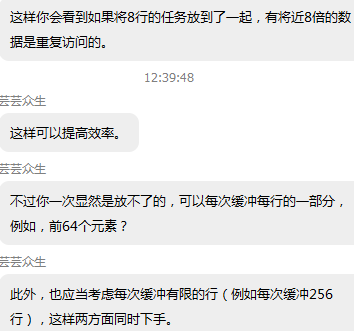
于是拆分成一节一节:即将原矩阵分成4个矩阵传进来,因为大神说:比如CL_DEVICE_MAX_MEM_ALLOC_SIZE:最大不能超过500M,而原本需要600MB的缓冲区,可以拆分成两个300MB的缓冲区传进kernel。
__kernel void knn2002350ForRobin(__global float *matrix,__global float *matrix2,__global float *matrix3,__global float *matrix4,
int width,int height,int k,__global int *positionMatrix,
__global float *instanceMatrix,__global float *localInstanceNoSort,
__local float *distanceK,__local float *positionK)
{
__local float localTempInst199[1024];
__local int localTempPos199[1024];
__local float localTempInst50[51*5+4];
__local float localTempPos50[51*5+4];
__local float localTempInst15[65];
__local int localTempPos15[65];
__local float localTempInst5[20];
__local int localTempPos5[20];
__local float localTempInst430[429];
__local int localTempPos430[429];
__local float localTempInst110[110];
__local int localTempPos110[110];
__local float localTempInst30[30];
__local int localTempPos30[30];
__local float localTempInst10[10];
__local int localTempPos10[10];
__local float localTempInst489[2445];
__local int localTempPos489[2445];
__local float localTempInst123[123*5];
__local int localTempPos123[123*5];
__local float localTempInst31[31*5];
__local int localTempPos31[31*5];
__local float localTempInst40[40];
__local int localTempPos40[40];
uint currentGroupID=get_group_id(1)*get_num_groups(0)+get_group_id(0);
for (size_t y = currentGroupID; y < height; y += get_local_size(0))
{
the first step : calculate the distances!!!!
__global float *row;
if(currentGroupID<500000)
{
row=matrix+width*y;
}
else if(currentGroupID>=500000 && currentGroupID<1000000)
{
row=matrix2+width*(y-500000);
}
else if(currentGroupID>=1000000 && currentGroupID<1500000)
{
row=matrix3+width*(y-1000000);
}
else
{
row=matrix4+width*(y-1500000);
}
localInstanceNoSort[y*height+y]=0;
const __global float *rowAnother;
for(uint i=get_local_id(0)+y+1;i<height;i+=get_local_size(0))
{
float sum=0;
if(i<500000)
{
rowAnother=matrix+width*i;
}
else if(i>=500000 && i<1000000)
{
rowAnother=matrix2+width*(i-500000);
}
else if(i>=1000000 && i<1500000)
{
rowAnother=matrix3+width*(i-1000000);
}
else
{
rowAnother=matrix4+width*(i-1500000);
}
for(uint j=0;j<width;j+=1)
{
sum+=(row[j]-rowAnother[j])*(row[j]-rowAnother[j]);
}
localInstanceNoSort[y*height+i] = sum;
}
barrier(CLK_LOCAL_MEM_FENCE);
for(uint forward0=get_local_id(0);forward0<y;forward0+=get_local_size(0))
{
localInstanceNoSort[y*height+forward0]=localInstanceNoSort[forward0*height+y];
}
barrier(CLK_LOCAL_MEM_FENCE);
//2002350=1955*1024+430
for(uint index=0;index<1955;index++)
{
//get 1024 datas from 2002350 every time .
uint t=get_local_id(0);
if(index*1024+t<currentGroupID)
{
localTempInst199[t]=localInstanceNoSort[currentGroupID*height+index*1024+t];
localTempPos199[t]=index*1024+t;
}
else
{
localTempInst199[t]=localInstanceNoSort[currentGroupID*height+index*1024+t+1];
localTempPos199[t]=index*1024+t+1;
}
barrier(CLK_LOCAL_MEM_FENCE);
/circle0 ,handle with 1024 datas!
//use the 52 threads of a group ,every thread handles 20 datas,k=5
//copy the forward k data and position
float data[5];
int pos[5];
int ind=0;
if(get_local_id(0)<52)
{
for(size_t k0=get_local_id(0)*20;k0<get_local_id(0)*20+k;k0++,ind++)
{
if(k0<1024)
{
data[ind]=localTempInst199[k0];
pos[ind]=localTempPos199[k0];
}
else
{
break;
}
}
int the1st=get_local_id(0)*20+k;
int thelast=get_local_id(0)*20+20;
while(the1st<thelast)
{
if(get_local_id(0)==52)
{
break;
}
//max from k
float kmaxdata=data[0];
int kmaxPos=pos[0];
int tempMaxPos=0;
for(size_t first=1;first<k;first++)
{
if(data[first]>kmaxdata)
{
kmaxdata=data[first];
kmaxPos=pos[first];
tempMaxPos=first;
}
}
if(localTempInst199[the1st]<kmaxdata)
{
data[tempMaxPos]=localTempInst199[the1st];
pos[tempMaxPos]=localTempPos199[the1st];
}
the1st+=1;
}
//result of circle0
if(get_local_id(0)<51)
{
for(size_t finalk0=0;finalk0<k;finalk0++)
{
localTempInst50[get_local_id(0)*k+finalk0]=data[finalk0];
localTempPos50[get_local_id(0)*k+finalk0]=pos[finalk0];
}
}
else
{
for(size_t finalk0=0;finalk0<k-1;finalk0++)
{
localTempInst50[get_local_id(0)*k+finalk0]=data[finalk0];
localTempPos50[get_local_id(0)*k+finalk0]=pos[finalk0];
}
}
}
barrier(CLK_LOCAL_MEM_FENCE);
/circle1 ,handle with 514 datas!
//use the 13 threads of a group ,every thread handles 20 datas,k=5
//copy the forward k data and position
//float data[5];
//int pos[5];
ind=0;
if(get_local_id(0)<13)
{
for(size_t k0=get_local_id(0)*20;k0<get_local_id(0)*20+k;k0++,ind++)
{
if(k0<259)
{
data[ind]=localTempInst50[k0];
pos[ind]=localTempPos50[k0];
}
else
{
break;
}
}
int the1st=get_local_id(0)*20+k;
int thelast=get_local_id(0)*20+20;
while(the1st<thelast)
{
if(get_local_id(0)==12 && the1st>18)
{
break;
}
//max from k
float kmaxdata=data[0];
int kmaxPos=pos[0];
int tempMaxPos=0;
for(size_t first=1;first<k;first++)
{
if(data[first]>kmaxdata)
{
kmaxdata=data[first];
kmaxPos=pos[first];
tempMaxPos=first;
}
}
if(localTempPos50[the1st]<kmaxdata)
{
data[tempMaxPos]=localTempInst50[the1st];
pos[tempMaxPos]=localTempPos50[the1st];
}
the1st+=1;
}
//result of circle1
for(size_t finalk0=0;finalk0<k;finalk0++)
{
localTempInst15[get_local_id(0)*k+finalk0]=data[finalk0];
localTempPos15[get_local_id(0)*k+finalk0]=pos[finalk0];
}
}
barrier(CLK_LOCAL_MEM_FENCE);
/circle2 ,handle with 65 datas!
//use the 4 threads of a group ,every thread handles 20 datas,k=5
//copy the forward k data and position
//float data[5];
//int pos[5];
ind=0;
if(get_local_id(0)<4)
{
for(size_t k0=get_local_id(0)*20;k0<get_local_id(0)*20+k;k0++,ind++)
{
if(k0<65)
{
data[ind]=localTempInst15[k0];
pos[ind]=localTempPos15[k0];
}
else
{
break;
}
}
int the1st=get_local_id(0)*20+k;
int thelast=get_local_id(0)*20+20;
while(the1st<thelast)
{
if(get_local_id(0)==4)
{
break;
}
//max from k
float kmaxdata=data[0];
int kmaxPos=pos[0];
int tempMaxPos=0;
for(size_t first=1;first<k;first++)
{
if(data[first]>kmaxdata)
{
kmaxdata=data[first];
kmaxPos=pos[first];
tempMaxPos=first;
}
}
if(localTempPos15[the1st]<kmaxdata)
{
data[tempMaxPos]=localTempInst15[the1st];
pos[tempMaxPos]=localTempPos15[the1st];
}
the1st+=1;
}
//result of circle2
for(size_t finalk0=0;finalk0<k;finalk0++)
{
localTempInst5[get_local_id(0)*k+finalk0]=data[finalk0];
localTempPos5[get_local_id(0)*k+finalk0]=pos[finalk0];
}
}
barrier(CLK_LOCAL_MEM_FENCE);
/circle3 ,handle with 20 datas!
//use the 1 thread of a group ,every thread handles 20 datas,k=5
//copy the forward k data and position
//float data[5];
//int pos[5];
ind=0;
if(get_local_id(0)<1)
{
for(size_t k0=0;k0<k;k0++,ind++)
{
data[ind]=localTempInst15[k0];
pos[ind]=localTempPos15[k0];
}
int the1st=k;
int thelast=20;
while(the1st<thelast)
{
//max from k
float kmaxdata=data[0];
int kmaxPos=pos[0];
int tempMaxPos=0;
for(size_t first=1;first<k;first++)
{
if(data[first]>kmaxdata)
{
kmaxdata=data[first];
kmaxPos=pos[first];
tempMaxPos=first;
}
}
if(localTempPos5[the1st]<kmaxdata)
{
data[tempMaxPos]=localTempInst5[the1st];
pos[tempMaxPos]=localTempPos5[the1st];
}
the1st+=1;
}
//result of circle2
for(size_t finalk0=0;finalk0<k;finalk0++)
{
distanceK[index*k+finalk0]=data[finalk0];
positionK[index*k+finalk0]=pos[finalk0];
}
}
barrier(CLK_LOCAL_MEM_FENCE);
}
get the last 430 or 429 datas from 2002350 .
uint t=get_local_id(0);
uint tt=1955*1024+t;
if(t<429)
{
if(currentGroupID<1955*1024)
{
localTempInst430[t]=localInstanceNoSort[currentGroupID*height+tt+1];
localTempPos430[t]=tt+1;
}
else
{
if(tt<currentGroupID)
{
localTempInst430[t]=localInstanceNoSort[currentGroupID*height+tt];
localTempPos430[t]=tt;
}
else
{
localTempInst430[t]=localInstanceNoSort[currentGroupID*height+tt+1];
localTempPos430[t]=tt+1;
}
}
}
barrier(CLK_LOCAL_MEM_FENCE);
/circle0 ,handle with 430 or 429 datas!
//use the 22 threads of a group ,every thread handles 20 datas,k=5
//copy the forward k data and position
float data[5];
int pos[5];
int ind=0;
if(get_local_id(0)<22)
{
for(size_t k0=get_local_id(0)*20;k0<get_local_id(0)*20+k;k0++,ind++)
{
data[ind]=localTempInst430[k0];
pos[ind]=localTempPos430[k0];
}
int the1st=get_local_id(0)*20+k;
int thelast=get_local_id(0)*20+20;
while(the1st<thelast)
{
if(get_local_id(0)==21 && the1st==429)
{
break;
}
//max from k
float kmaxdata=data[0];
int kmaxPos=pos[0];
int tempMaxPos=0;
for(size_t first=1;first<k;first++)
{
if(data[first]>kmaxdata)
{
kmaxdata=data[first];
kmaxPos=pos[first];
tempMaxPos=first;
}
}
if(localTempInst430[the1st]<kmaxdata)
{
data[tempMaxPos]=localTempInst430[the1st];
pos[tempMaxPos]=localTempPos430[the1st];
}
the1st+=1;
}
//result circle0
for(size_t finalk0=0;finalk0<k;finalk0++)
{
localTempInst110[get_local_id(0)*k+finalk0]=data[finalk0];
localTempPos110[get_local_id(0)*k+finalk0]=pos[finalk0];
}
}
barrier(CLK_LOCAL_MEM_FENCE);
/circle1 ,handle with 110 datas!
//use the 5 threads of a group ,every thread handles 20 datas,k=5
//copy the forward k data and position
//float data[5];
//int pos[5];
ind=0;
if(get_local_id(0)<6)
{
for(size_t k0=get_local_id(0)*20;k0<get_local_id(0)*20+k;k0++,ind++)
{
data[ind]=localTempInst110[k0];
pos[ind]=localTempPos110[k0];
}
int the1st=get_local_id(0)*20+k;
int thelast=get_local_id(0)*20+20;
while(the1st<thelast)
{
if(get_local_id(0)==5 && the1st==10)
{
break;
}
//max from k
float kmaxdata=data[0];
int kmaxPos=pos[0];
int tempMaxPos=0;
for(size_t first=1;first<k;first++)
{
if(data[first]>kmaxdata)
{
kmaxdata=data[first];
kmaxPos=pos[first];
tempMaxPos=first;
}
}
if(localTempInst110[the1st]<kmaxdata)
{
data[tempMaxPos]=localTempInst110[the1st];
pos[tempMaxPos]=localTempPos110[the1st];
}
the1st+=1;
}
//result circle1
for(size_t finalk0=0;finalk0<k;finalk0++)
{
localTempInst30[get_local_id(0)*k+finalk0]=data[finalk0];
localTempPos30[get_local_id(0)*k+finalk0]=pos[finalk0];
}
}
barrier(CLK_LOCAL_MEM_FENCE);
/circle2 ,handle with 30 datas!
//use the 2 threads of a group ,every thread handles 15 datas,k=5
//copy the forward k data and position
//float data[5];
//int pos[5];
ind=0;
if(get_local_id(0)<2)
{
for(size_t k0=get_local_id(0)*15;k0<get_local_id(0)*15+k;k0++,ind++)
{
data[ind]=localTempInst110[k0];
pos[ind]=localTempPos110[k0];
}
int the1st=get_local_id(0)*15+k;
int thelast=get_local_id(0)*15+15;
while(the1st<thelast)
{
//max from k
float kmaxdata=data[0];
int kmaxPos=pos[0];
int tempMaxPos=0;
for(size_t first=1;first<k;first++)
{
if(data[first]>kmaxdata)
{
kmaxdata=data[first];
kmaxPos=pos[first];
tempMaxPos=first;
}
}
if(localTempInst30[the1st]<kmaxdata)
{
data[tempMaxPos]=localTempInst30[the1st];
pos[tempMaxPos]=localTempPos30[the1st];
}
the1st+=1;
}
//result circle1
for(size_t finalk0=0;finalk0<k;finalk0++)
{
localTempInst10[get_local_id(0)*k+finalk0]=data[finalk0];
localTempPos10[get_local_id(0)*k+finalk0]=pos[finalk0];
}
}
barrier(CLK_LOCAL_MEM_FENCE);
/circle3 ,handle with 20 datas!
//use the 1 thread of a group ,every thread handles 10 datas,k=5
//copy the forward k data and position
//float data[5];
//int pos[5];
ind=0;
if(get_local_id(0)<1)
{
for(size_t k0=0;k0<k;k0++,ind++)
{
data[ind]=localTempInst10[k0];
pos[ind]=localTempPos10[k0];
}
int the1st=k;
int thelast=10;
while(the1st<thelast)
{
//max from k
float kmaxdata=data[0];
int kmaxPos=pos[0];
int tempMaxPos=0;
for(size_t first=1;first<k;first++)
{
if(data[first]>kmaxdata)
{
kmaxdata=data[first];
kmaxPos=pos[first];
tempMaxPos=first;
}
}
if(localTempPos10[the1st]<kmaxdata)
{
data[tempMaxPos]=localTempInst10[the1st];
pos[tempMaxPos]=localTempPos10[the1st];
}
the1st+=1;
}
//result of circle2
for(size_t finalk0=0;finalk0<k;finalk0++)
{
distanceK[1955*k+finalk0]=data[finalk0];
positionK[1955*k+finalk0]=pos[finalk0];
}
}
barrier(CLK_LOCAL_MEM_FENCE);
result of a group :1956*5 data
/circle0,handle with 1956*5 datas!
//use the 489 thread of a group ,every thread handles 20 datas,k=5
//copy the forward k data and position
//float data[5];
//int pos[5];
ind=0;
if(get_local_id(0)<489)
{
for(size_t k0=get_local_id(0)*20;k0<get_local_id(0)*20+k;k0++,ind++)
{
data[ind]=distanceK[k0];
pos[ind]=positionK[k0];
}
int the1st=get_local_id(0)*20+k;
int thelast=get_local_id(0)*20+20;
while(the1st<thelast)
{
//max from k
float kmaxdata=data[0];
int kmaxPos=pos[0];
int tempMaxPos=0;
for(size_t first=1;first<k;first++)
{
if(data[first]>kmaxdata)
{
kmaxdata=data[first];
kmaxPos=pos[first];
tempMaxPos=first;
}
}
if(distanceK[the1st]<kmaxdata)
{
data[tempMaxPos]=distanceK[the1st];
pos[tempMaxPos]=distanceK[the1st];
}
the1st+=1;
}
//result circle1
for(size_t finalk0=0;finalk0<k;finalk0++)
{
localTempInst489[get_local_id(0)*k+finalk0]=data[finalk0];
localTempPos489[get_local_id(0)*k+finalk0]=pos[finalk0];
}
}
barrier(CLK_LOCAL_MEM_FENCE);
/circle1,handle with 489*5 datas!
//use the 123 thread of a group ,every thread handles 20 datas,k=5
//copy the forward k data and position
//float data[5];
//int pos[5];
ind=0;
if(get_local_id(0)<123)
{
for(size_t k0=get_local_id(0)*20;k0<get_local_id(0)*20+k;k0++,ind++)
{
data[ind]=distanceK[k0];
pos[ind]=positionK[k0];
}
int the1st=get_local_id(0)*20+k;
int thelast=get_local_id(0)*20+20;
while(the1st<thelast)
{
if(get_local_id(0)==122)
{
break;
}
//max from k
float kmaxdata=data[0];
int kmaxPos=pos[0];
int tempMaxPos=0;
for(size_t first=1;first<k;first++)
{
if(data[first]>kmaxdata)
{
kmaxdata=data[first];
kmaxPos=pos[first];
tempMaxPos=first;
}
}
if(distanceK[the1st]<kmaxdata)
{
data[tempMaxPos]=distanceK[the1st];
pos[tempMaxPos]=distanceK[the1st];
}
the1st+=1;
}
//result circle1
for(size_t finalk0=0;finalk0<k;finalk0++)
{
localTempInst123[get_local_id(0)*k+finalk0]=data[finalk0];
localTempPos123[get_local_id(0)*k+finalk0]=pos[finalk0];
}
}
barrier(CLK_LOCAL_MEM_FENCE);
/circle2,handle with 123*5 datas!
//use the 31 thread of a group ,every thread handles 20 datas,k=5
//copy the forward k data and position
//float data[5];
//int pos[5];
ind=0;
if(get_local_id(0)<31)
{
for(size_t k0=get_local_id(0)*20;k0<get_local_id(0)*20+k;k0++,ind++)
{
data[ind]=distanceK[k0];
pos[ind]=positionK[k0];
}
int the1st=get_local_id(0)*20+k;
int thelast=get_local_id(0)*20+20;
while(the1st<thelast)
{
if(get_local_id(0)==30 && the1st>614)
{
break;
}
//max from k
float kmaxdata=data[0];
int kmaxPos=pos[0];
int tempMaxPos=0;
for(size_t first=1;first<k;first++)
{
if(data[first]>kmaxdata)
{
kmaxdata=data[first];
kmaxPos=pos[first];
tempMaxPos=first;
}
}
if(distanceK[the1st]<kmaxdata)
{
data[tempMaxPos]=distanceK[the1st];
pos[tempMaxPos]=distanceK[the1st];
}
the1st+=1;
}
//result circle1
for(size_t finalk0=0;finalk0<k;finalk0++)
{
localTempInst31[get_local_id(0)*k+finalk0]=data[finalk0];
localTempPos31[get_local_id(0)*k+finalk0]=pos[finalk0];
}
}
barrier(CLK_LOCAL_MEM_FENCE);
/circle3,handle with 31*5 datas!
//use the 8 thread of a group ,every thread handles 20 datas,k=5
//copy the forward k data and position
//float data[5];
//int pos[5];
ind=0;
if(get_local_id(0)<8)
{
for(size_t k0=get_local_id(0)*20;k0<get_local_id(0)*20+k;k0++,ind++)
{
data[ind]=distanceK[k0];
pos[ind]=positionK[k0];
}
int the1st=get_local_id(0)*20+k;
int thelast=get_local_id(0)*20+20;
while(the1st<thelast)
{
if(get_local_id(0)==7 && the1st>154)
{
break;
}
//max from k
float kmaxdata=data[0];
int kmaxPos=pos[0];
int tempMaxPos=0;
for(size_t first=1;first<k;first++)
{
if(data[first]>kmaxdata)
{
kmaxdata=data[first];
kmaxPos=pos[first];
tempMaxPos=first;
}
}
if(distanceK[the1st]<kmaxdata)
{
data[tempMaxPos]=distanceK[the1st];
pos[tempMaxPos]=distanceK[the1st];
}
the1st+=1;
}
//result circle1
for(size_t finalk0=0;finalk0<k;finalk0++)
{
localTempInst40[get_local_id(0)*k+finalk0]=data[finalk0];
localTempPos40[get_local_id(0)*k+finalk0]=pos[finalk0];
}
}
barrier(CLK_LOCAL_MEM_FENCE);
/circle4,handle with 40 datas!
//use the 2 thread of a group ,every thread handles 20 datas,k=5
//copy the forward k data and position
//float data[5];
//int pos[5];
ind=0;
if(get_local_id(0)<2)
{
for(size_t k0=get_local_id(0)*20;k0<get_local_id(0)*20+k;k0++,ind++)
{
data[ind]=distanceK[k0];
pos[ind]=positionK[k0];
}
int the1st=get_local_id(0)*20+k;
int thelast=get_local_id(0)*20+20;
while(the1st<thelast)
{
//max from k
float kmaxdata=data[0];
int kmaxPos=pos[0];
int tempMaxPos=0;
for(size_t first=1;first<k;first++)
{
if(data[first]>kmaxdata)
{
kmaxdata=data[first];
kmaxPos=pos[first];
tempMaxPos=first;
}
}
if(distanceK[the1st]<kmaxdata)
{
data[tempMaxPos]=distanceK[the1st];
pos[tempMaxPos]=distanceK[the1st];
}
the1st+=1;
}
//result circle1
for(size_t finalk0=0;finalk0<k;finalk0++)
{
localTempInst10[get_local_id(0)*k+finalk0]=data[finalk0];
localTempPos10[get_local_id(0)*k+finalk0]=pos[finalk0];
}
}
barrier(CLK_LOCAL_MEM_FENCE);
/circle5,handle with 10 datas!
//use the 1 thread of a group ,every thread handles 10 datas,k=5
//copy the forward k data and position
//float data[5];
//int pos[5];
ind=0;
if(get_local_id(0)<1)
{
for(size_t k0=0;k0<k;k0++,ind++)
{
data[ind]=distanceK[k0];
pos[ind]=positionK[k0];
}
int the1st=k;
int thelast=10;
while(the1st<thelast)
{
//max from k
float kmaxdata=data[0];
int kmaxPos=pos[0];
int tempMaxPos=0;
for(size_t first=1;first<k;first++)
{
if(data[first]>kmaxdata)
{
kmaxdata=data[first];
kmaxPos=pos[first];
tempMaxPos=first;
}
}
if(distanceK[the1st]<kmaxdata)
{
data[tempMaxPos]=distanceK[the1st];
pos[tempMaxPos]=distanceK[the1st];
}
the1st+=1;
}
//result circle1
for(size_t finalk0=0;finalk0<k;finalk0++)
{
instanceMatrix[currentGroupID*k+finalk0]=data[finalk0];
positionMatrix[currentGroupID*k+finalk0]=pos[finalk0];
}
}
barrier(CLK_LOCAL_MEM_FENCE);
}
}
#include <stdio.h>
#include <stdlib.h>
//#include <CL/cl.hpp>
#include <CL/cl.h>
#include <time.h>
#include <fstream>
#include <vector>
#include "oclUtils.h"
#include "shrQATest.h"
using namespace std;
const int width=931;
const int height=200;
const int height2=500000;
const int height3=2350;
//const int height2=2002350; 2002350=500000*4+2350
const int k=5;
int64_t system_time()
{
struct timespec t;
clock_gettime(CLOCK_MONOTONIC,&t);
return (int64_t)(t.tv_sec)*1e9+t.tv_nsec;
}
int main( int argc, const char** argv)
{
shrQAStart(argc, (char **)argv);
// set logfile name and start logs
shrSetLogFileName ("oclKnn4Robin.txt");
shrLog("%s Starting...\n\n", argv[0]);
//Get the NVIDIA platform
cl_platform_id cpPlatform;
cl_int ciErrNum = oclGetPlatformID(&cpPlatform);
oclCheckError(ciErrNum, CL_SUCCESS);
//Get the devices
cl_uint uiNumDevices;
ciErrNum = clGetDeviceIDs(cpPlatform, CL_DEVICE_TYPE_GPU, 0, NULL, &uiNumDevices);
oclCheckError(ciErrNum, CL_SUCCESS);
cl_device_id *cdDevices = (cl_device_id *)malloc(uiNumDevices * sizeof(cl_device_id) );
ciErrNum = clGetDeviceIDs(cpPlatform, CL_DEVICE_TYPE_GPU, uiNumDevices, cdDevices, NULL);
oclCheckError(ciErrNum, CL_SUCCESS);
//Create the context
cl_context cxGPUContext = clCreateContext(0, uiNumDevices, cdDevices, NULL, NULL, &ciErrNum);
oclCheckError(ciErrNum, CL_SUCCESS);
cl_device_id device ;
clGetDeviceIDs(cpPlatform,CL_DEVICE_TYPE_GPU,1,&device,NULL);
cl_command_queue commandQueue = clCreateCommandQueue(cxGPUContext, device, CL_QUEUE_PROFILING_ENABLE, &ciErrNum);
if (ciErrNum != CL_SUCCESS)
{
shrLog(" Error %i in clCreateCommandQueue call !!!\n\n", ciErrNum);
return ciErrNum;
}
//read kernel file and build it
size_t program_length;
char* source_path = shrFindFilePath("knn2002350advance.cl", argv[0]);
oclCheckError(source_path != NULL, shrTRUE);
char *source = oclLoadProgSource(source_path, "", &program_length);
oclCheckError(source != NULL, shrTRUE);
// create the program
cl_program cpProgram = clCreateProgramWithSource(cxGPUContext, 1,(const char **)&source, &program_length, &ciErrNum);
oclCheckError(ciErrNum, CL_SUCCESS);
// build the program
ciErrNum = clBuildProgram(cpProgram, 0, NULL, "-cl-fast-relaxed-math", NULL, NULL);
if (ciErrNum != CL_SUCCESS)
{
printf("cannot build program successfully!\n");
size_t logSize;
ciErrNum = clGetProgramBuildInfo(cpProgram, device, CL_PROGRAM_BUILD_LOG,0, NULL, &logSize);
char *log = (char*)malloc(logSize);
ciErrNum = clGetProgramBuildInfo(cpProgram, device, CL_PROGRAM_BUILD_LOG,logSize, log, NULL);
printf("%s\n", log);
free(log);
exit(-1);
}
cl_kernel ckKernel = clCreateKernel(cpProgram, "knn2002350ForRobin", &ciErrNum);
oclCheckError(ciErrNum, CL_SUCCESS);
//host data
float *matrix,*matrix2,*matrix3,*matrix4;
const int matrixSizeNoFloat=width*height2;
const size_t matrixSize=matrixSizeNoFloat*sizeof(float);
matrix=(float*)malloc(matrixSize);
memset(matrix,0,matrixSize);
matrix2=(float*)malloc(matrixSize);
memset(matrix2,0,matrixSize);
matrix3=(float*)malloc(matrixSize);
memset(matrix3,0,matrixSize);
const size_t matrixSize4=width*height3*sizeof(float);
matrix4=(float*)malloc(matrixSize4);
memset(matrix4,0,matrixSize4);
//shrFillArray(matrix,matrixSizeNoFloat);
size_t resultPosSize=height2*k*sizeof(int);
int *resultPosMatrix=(int*)malloc(resultPosSize);
memset(resultPosMatrix,0,resultPosSize);
size_t resultInstanceSize=height2*k*sizeof(float);
float *resultInstanceMatrix=(float*)malloc(resultInstanceSize);
shrFillArray(resultInstanceMatrix,height2*k);
size_t localsize[2]={1024,1};
size_t globalsize[2]={1024,1024};
cl_mem matrix_buffer=clCreateBuffer(cxGPUContext, CL_MEM_READ_ONLY ,matrixSize, matrix, &ciErrNum);
cl_mem result_pos_buffer=clCreateBuffer(cxGPUContext,CL_MEM_WRITE_ONLY,resultPosSize,resultPosMatrix,&ciErrNum);
cl_mem result_ins_buffer=clCreateBuffer(cxGPUContext,CL_MEM_WRITE_ONLY,resultInstanceSize,resultInstanceMatrix,&ciErrNum);
ciErrNum = clEnqueueWriteBuffer(commandQueue, matrix_buffer, CL_FALSE, 0, matrixSize, matrix, 0, NULL, NULL);
oclCheckError(ciErrNum, CL_SUCCESS);
cl_mem matrix2_buffer=clCreateBuffer(cxGPUContext, CL_MEM_READ_ONLY ,matrixSize, matrix2, &ciErrNum);
ciErrNum = clEnqueueWriteBuffer(commandQueue, matrix2_buffer, CL_FALSE, 0, matrixSize, matrix2, 0, NULL, NULL);
oclCheckError(ciErrNum, CL_SUCCESS);
cl_mem matrix3_buffer=clCreateBuffer(cxGPUContext, CL_MEM_READ_ONLY ,matrixSize, matrix3, &ciErrNum);
ciErrNum = clEnqueueWriteBuffer(commandQueue, matrix3_buffer, CL_FALSE, 0, matrixSize, matrix3, 0, NULL, NULL);
oclCheckError(ciErrNum, CL_SUCCESS);
cl_mem matrix4_buffer=clCreateBuffer(cxGPUContext, CL_MEM_READ_ONLY ,matrixSize4, matrix4, &ciErrNum);
ciErrNum = clEnqueueWriteBuffer(commandQueue, matrix4_buffer, CL_FALSE, 0, matrixSize4, matrix4, 0, NULL, NULL);
oclCheckError(ciErrNum, CL_SUCCESS);
ciErrNum = clSetKernelArg(ckKernel, 0, sizeof(cl_mem), (void*)&matrix_buffer);
ciErrNum = clSetKernelArg(ckKernel, 1, sizeof(cl_mem), (void*)&matrix2_buffer);
ciErrNum = clSetKernelArg(ckKernel, 2, sizeof(cl_mem), (void*)&matrix3_buffer);
ciErrNum = clSetKernelArg(ckKernel, 3, sizeof(cl_mem), (void*)&matrix4_buffer);
ciErrNum |= clSetKernelArg(ckKernel, 4, sizeof(int), &width);
ciErrNum |= clSetKernelArg(ckKernel, 5, sizeof(int), &height2);
ciErrNum |= clSetKernelArg(ckKernel, 6, sizeof(int), &k);
ciErrNum |= clSetKernelArg(ckKernel, 7, sizeof(cl_mem), (void*)&result_pos_buffer);
ciErrNum |= clSetKernelArg(ckKernel, 8, sizeof(cl_mem), (void*)&result_ins_buffer);
size_t NoSortSize=height2*height2*sizeof(float);
float *NoSort=(float*)malloc(NoSortSize);
memset(NoSort,0,NoSortSize);
cl_mem NoSort_buffer=clCreateBuffer(cxGPUContext,CL_MEM_READ_WRITE,NoSortSize,NoSort,&ciErrNum);
ciErrNum = clEnqueueWriteBuffer(commandQueue, NoSort_buffer, CL_FALSE, 0, NoSortSize, NoSort, 0, NULL, NULL);
ciErrNum |= clSetKernelArg(ckKernel, 9, sizeof(cl_mem), (void*)&NoSort_buffer);
oclCheckError(ciErrNum, CL_SUCCESS);
size_t KDistanceSize=1956*5*sizeof(float);
float *KDistance=(float*)malloc(KDistanceSize);
memset(KDistance,0,KDistanceSize);
cl_mem KDistance_buffer=clCreateBuffer(cxGPUContext,CL_MEM_READ_WRITE,KDistanceSize,KDistance,&ciErrNum);
ciErrNum = clEnqueueWriteBuffer(commandQueue, KDistance_buffer, CL_FALSE, 0, KDistanceSize, KDistance, 0, NULL, NULL);
ciErrNum |= clSetKernelArg(ckKernel, 10, sizeof(cl_mem), (void*)&KDistance_buffer);
oclCheckError(ciErrNum, CL_SUCCESS);
size_t KPositinSize=1956*5*sizeof(float);
float *KPosition=(float*)malloc(KPositinSize);
memset(KPosition,0,KPositinSize);
cl_mem KPosition_buffer=clCreateBuffer(cxGPUContext,CL_MEM_READ_WRITE,KPositinSize,KPosition,&ciErrNum);
ciErrNum = clEnqueueWriteBuffer(commandQueue, KDistance_buffer, CL_FALSE, 0, KPositinSize, KPosition, 0, NULL, NULL);
ciErrNum |= clSetKernelArg(ckKernel, 11, sizeof(cl_mem), (void*)&KPosition_buffer);
oclCheckError(ciErrNum, CL_SUCCESS);
clFinish(commandQueue);
int64_t time_start=system_time();
clEnqueueNDRangeKernel(commandQueue, ckKernel, 2, NULL, globalsize, localsize,0, NULL, NULL);
clFinish(commandQueue);
int64_t time_end=system_time();
printf("kernel execute time: %f(us)\n",(time_end-time_start)/1e3);
int *positionHost=(int*)alloca(resultPosSize);
memset(positionHost,0,resultPosSize);
float *instanceHost=(float*)alloca(resultInstanceSize);
memset(instanceHost,0,resultInstanceSize);
ciErrNum = clEnqueueReadBuffer(commandQueue, result_pos_buffer, CL_TRUE, 0,resultPosSize, positionHost,0, NULL, NULL);
ciErrNum = clEnqueueReadBuffer(commandQueue, result_ins_buffer, CL_TRUE, 0,resultInstanceSize, instanceHost,0, NULL, NULL);
oclCheckError(ciErrNum, CL_SUCCESS);
//save as txt to check.
ofstream posOutfile("position2002350.txt",ios::out);
ofstream instanceOutfile("distance2002350.txt",ios::out);
for(size_t r=0;r<height2;r++)
{
for(size_t c=0;c<k;c++)
{
int data=positionHost[r*k+c];
float instanceData=instanceHost[r*k+c];
posOutfile<<data<<"\t";
instanceOutfile<<instanceData<<"\t";
}
posOutfile<<endl;
instanceOutfile<<endl;
}
posOutfile.close();
instanceOutfile.close();
free(matrix);
free(resultPosMatrix);
free(resultInstanceMatrix);
free(NoSort);
free(KDistance);
free(KPosition);
clReleaseCommandQueue(commandQueue);
clReleaseContext(cxGPUContext);
clReleaseProgram(cpProgram);
clReleaseKernel(ckKernel);
shrLog("%s Successfully end.\n\n", argv[0]);
return 0;
}第一次WriteBuffer通过了,第二次WriteBuffer时返回 -4.超过限制?!
















 317
317

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











