







关于分布式事务的理解
分布式事务之前先简单介绍下介于本地事务和分布式事务之间的两个事务:全局事务(Global Transactions)和共享事务(Share Transactions)的原理与实现。
先给全局事务做个限定:一种适用于单个服务使用多个数据源场景的事务解决方案。
典型实现方式三段式提交 canCommit preCommit doCommit
共享事务是指多个服务共用同一个数据源。
交易服务器根据不同服务节点传来的同一个事务 ID,使用同一个数据库连接来处理跨越多个服务的交易事务。不多见,因为一般系统都是数据库才是瓶颈。
分布式事务之可靠消息队列
前面几节课,我们谈论了事务处理中的本地事务(单个服务、单个数据源)、全局事务(单个服务、多个数据源)和共享事务(多个服务、单个数据源),这一讲我们将聚焦于事务处理中最复杂的分布式事务(多个服务、多个数据源)。
而这里的“分布式”是相对于服务而言的,它特指的是多个服务同时访问多个数据源的事务处理机制,严谨地说,它更应该被称为“在分布式服务环境下的事务处理机制”。
CAP 与 ACID 之间的矛盾
这个定理里,描述了一个分布式的系统中,当涉及到共享数据问题时,以下三个特性最多只能满足其中两个:
一致性(Consistency):代表在任何时刻、任何分布式节点中,我们所看到的数据都是没有矛盾的。这与 ACID 中的 C 是相同的单词,但它们又有不同的定义(分别指 Replication 的一致性和数据库状态的一致性)。
在分布式事务中,ACID 的 C 要以满足 CAP 中的 C 为前提。
可用性(Availability):代表系统不间断地提供服务的能力。
分区容忍性(Partition Tolerance):代表分布式环境中,当部分节点因网络原因而彼此失联(即与其他节点形成“网络分区”)时,系统仍能正确地提供服务的能力。
在分布式系统中,
如果放弃分区容错性(CA without P)我们将假设节点之间的通讯永远是可靠的。可是永远可靠的通讯在分布式系统中必定是不成立的。
如果放弃可用性(CP without A)
这意味着,我们将假设一旦发生分区,节点之间的信息同步时间可以无限制地延长。
比如A服务器的数据是要同步给B服务器的,现在网断了,A的数据传不过去了,我觉得保证数据对比较重要,如果A和B的数据对不上,后果很严重,为了保证A和B服务器的数据一致,干脆让A停止服务好了,直接给客户端返回错误信息,等网络恢复了,再上线,免得A和B的数据不一致。
如果放弃一致性(AP without C)
这意味着,我们将假设一旦发生分区,节点之间所提供的数据可能不一致。AP 系统目前是分布式系统设计的主流选择,大多数的 NoSQL 库和支持分布式的缓存都是 AP 系统。因为 P 是分布式网络的天然属性,你不想要也无法丢弃;而 A 通常是建设分布式的目的。
比如A服务器的数据是要同步给B服务器的,现在网断了,A的数据传不过去了,我觉得暂时的数据不一致没什么大关系,系统能用最重要,那我就继续让A提供服务,等网络恢复了,再同步数据到B。
以 Redis 集群为例,如果某个 Redis 节点出现网络分区,那也不妨碍每个节点仍然会以自己本地的数据对外提供服务。但这时有可能出现这种情况,即请求分配到不同节点时,返回给客户端的是不同的数据。
那么看到这里,你是否感受到了一丝无奈?这个小章节所讨论的话题“事务”,原本的目的就是要获得“一致性”。而在分布式环境中,“一致性”却不得不成为了通常被牺牲、被放弃的那一项属性。
但无论如何,我们建设信息系统,终究还是要保证操作结果(在最终被交付的时候)是正确的。为此,人们又重新给一致性下了定义,把前面我们在 CAP、ACID 中讨论的一致性称为“强一致性”(Strong Consistency),有时也称为“线性一致性”(Linearizability),而把牺牲了 C 的 AP 系统,又要尽可能获得正确的结果的行为,称为追求“弱一致性”。
在弱一致性中,人们又总结出了一种特例,叫做“最终一致性”(Eventual Consistency)。它是指,如果数据在一段时间内没有被另外的操作所更改,那它最终将会达到与强一致性过程相同的结果,有时候面向最终一致性的算法,也被称为“乐观复制算法”。
那么,在“分布式事务”中,我们的设计目标同样也不得不从获得强一致性,降低为获得“最终一致性”,在这个意义上,其实“事务”一词的含义也已经被拓宽了。
相比于ACID等的“刚性事务”,我们称分布式事务为“柔性事务”
可靠事件队列
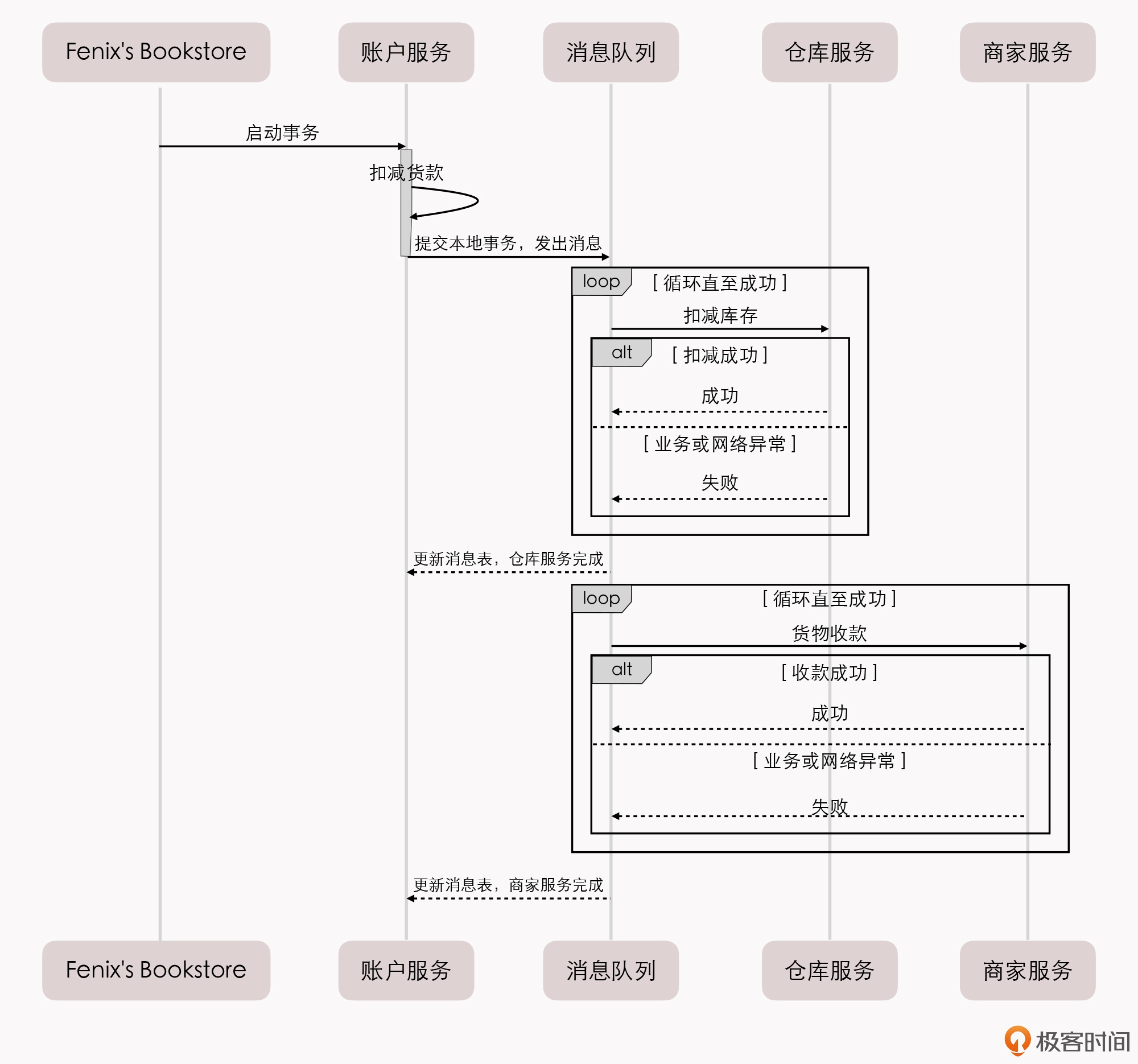
我们按照顺序,一步步来解读一下。
第一步,最终用户向 Fenix’s Bookstore 发送交易请求:购买一本价值 100 元的《深入理解 Java 虚拟机》。
第二步,Fenix’s Bookstore 应该对用户账户扣款、商家账户收款、库存商品出库这三个操作有一个出错概率的先验评估,根据出错概率的大小来安排它们的操作顺序(这个一般体现在程序代码中,有一些大型系统也可能动态排序)。比如,最有可能出错的地方,是用户购买了,但是系统不同意扣款,或者是账户余额不足;其次是商品库存不足;最后是商家收款,一般收款不会遇到什么意外。那么这个顺序就应该是最容易出错的最先进行,即:账户扣款 → 仓库出库 → 商家收款。
第三步,账户服务进行扣款业务,如果扣款成功,就在自己的数据库建立一张消息表,里面存入一条消息:“事务 ID:UUID;扣款:100 元(状态:已完成);仓库出库《深入理解 Java 虚拟机》:1 本(状态:进行中);某商家收款:100 元(状态:进行中)”。注意,这个步骤中“扣款业务”和“写入消息”是依靠同一个本地事务写入自身数据库的。
第四步,系统建立一个消息服务,定时轮询消息表,将状态是“进行中”的消息同时发送到库存和商家服务节点中去。这时候可能会产生以下几种情况:
1商家和仓库服务成功完成了收款和出库工作,向用户账户服务器返回执行结果,用户账户服务把消息状态从“进行中”更新为“已完成”。整个事务宣告顺利结束,达到最终一致性的状态。
2商家或仓库服务有某些或全部因网络原因,未能收到来自用户账户服务的消息。此时,由于用户账户服务器中存储的消息状态,一直处于“进行中”,所以消息服务器将在每次轮询的时候,持续地向对应的服务重复发送消息。这个步骤的可重复性,就决定了所有被消息服务器发送的消息都必须具备幂等性。通常我们的设计是让消息带上一个唯一的事务 ID,以保证一个事务中的出库、收款动作只会被处理一次。
3商家或仓库服务有某个或全部无法完成工作。比如仓库发现《深入理解 Java 虚拟机》没有库存了,此时,仍然是持续自动重发消息,直至操作成功(比如补充了库存),或者被人工介入为止。
4商家和仓库服务成功完成了收款和出库工作,但回复的应答消息因网络原因丢失。此时,用户账户服务仍会重新发出下一条消息,但因消息幂等,所以不会导致重复出库和收款,只会导致商家、仓库服务器重新发送一条应答消息。此过程会一直重复,直至双方网络恢复。
5也有一些支持分布式事务的消息框架,如 RocketMQ,原生就支持分布式事务操作,这时候前面提到的情况 2、4 也可以交给消息框架来保障。
前面这种靠着持续重试来保证可靠性的操作,在计算机中就非常常见,它有个专门的名字,叫做“最大努力交付”(Best-Effort Delivery),比如 TCP 协议中的可靠性保障,就属于最大努力交付。而“可靠事件队列”有一种更普通的形式,被称为“最大努力一次提交”(Best-Effort 1PC),意思就是系统会把最有可能出错的业务,以本地事务的方式完成后,通过不断重试的方式(不限于消息系统)来促使同个事务的其他关联业务完成。
小结
这节课,我第一次引入了 CAP 定理,希望你能通过事务处理的上下文场景去理解它。这套理论不仅是在事务处理中,而且在一致性、共识,乃至整个分布式所有涉及到数据的知识点中,都有重要的应用,后面讲到分布式共识算法、微服务中多种基础设施等内容的时候,我们还会多次涉及到它。除了可靠事件队列之外,下一讲我还会给你介绍 TCC 和 SAGA 这两种主流的实现方式,它们都有各自的优缺点和应用场景。分布式系统中不存在放之四海皆准的万能事务解决方案,针对具体场景,选择合适的解决方案,达到一致性与可用性之间的最佳平衡,是我们作为一名设计者必须具备的技能。















 295
295











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









