







MySQL(三)管理数据库和表
(一)关系型数据库基础
(二)MySQL安装
(三)管理数据库和表
(四)用户和权限管理
(五)函数,存储过程和触发器
(六)MySQL架构
(七)存储引擎
(八)MySQL服务器选项,系统和状态变量
(九)优化查询和索引管理
(十)锁和事务管理
(十一)日志管理
(十二)备份还原
(十三)MySQL集群
管理数据库和表的常见概念
关系型数据库的常见组件
-
数据库:database
数据库的核心就是存放数据,而在关系型数据中,存放数据的核心组件就是表。
表的定义:列名和对应的列应该采用的数据类型 -
表:table
行:row
列:column -
索引:index
-
视图:view
-
用户:user
-
权限:privilege
-
存储过程:procedure
-
存储函数:function
-
触发器:trigger
-
事件调度器:event scheduler,任务计划
SQL语言规范
-
在数据库系统中,SQL语句不区分大小写(建议用大写)
-
SQL语句可单行或多行书写,以“;”结尾
-
关键词不能跨多行或简写
-
用空格和缩进来提高语句的可读性
-
子句通常位于独立行,便于编辑,提高可读性
-
注释:
SQL标准:
\ /*注释内容*/ 多行注释
– 注释内容 单行注释,注意有空格
MySQL注释:
# #是mysql特有的注释方式
数据库对象
-
数据库的组件(对象):数据库中的各种资源
数据库、表、索引、视图、用户、存储过程、函数、触发器、事件调度器等 -
对象的命名规则:
必须以字母开头
可包括数字和三个特殊字符(# _ $)
不要使用MySQL的保留字
同一database(Schema)下的对象不能同名
SQL语句分类
-
DDL: Data Defination Language 数据定义语言
CREATE,DROP,ALTER -
DML: Data Manipulation Language 数据操纵语言
INSERT,DELETE,UPDATE -
DCL:Data Control Language 数据控制语言
GRANT,REVOKE,COMMIT,ROLLBACK -
DQL:Data Query Language 数据查询语言
SELECT(运维最核心的命令) -
另一种说法:CRUD(增删改查)CRUD=DML+DQL
SQL语句构成
- SQL语句构成:
Keyword组成clause
多条clause组成语句 - 示例:
SELECT * SELECT子句
FROM products FROM子句
WHERE price>400 WHERE子句 - 说明:一组SQL语句,由三个子句构成,SELECT,FROM和WHERE是关键字
数据库的相关操作
数据库的创建
- CREATE DATABASE|SCHEMA [IF NOT EXISTS] ‘DB_NAME’;
- CHARACTER SET 'character set name’COLLATE 'collate name
- 使用什么字符集和排序规则一般写至配置文件中,一般也不会修改,如果涉及修改库的字符集时得修改以前各个表和各表中各个字段分别修改,比较繁琐。
目前一般使用的字符集utf8 utf8mb4(增强的utf8,支持各种互联网表情)
创建库用法:
MariaDB [(none)]>help create database;
CREATE {DATABASE | SCHEMA} [IF NOT EXISTS] db_name
[create_specification]
create_specification:
[DEFAULT] CHARACTER SET [=] charset_name 指定字符集
| [DEFAULT] COLLATE [=] collation_name 指定排序规则
MariaDB [(none)]> SHOW VARIABLES like '%char%'; 查看默认字符集
character_set_server | latin1 默认字符集不支持中文
创建一个数据库之后,在其文件夹目录下db.opt文件
cat datadir/dbname/db.opt中包含有数据库相关信息
default-character-set=latin1
default-collation=latin1_swedish_ci
MariaDB [(none)]> show character set;
查看支持的字符集和字符集默认的排序规则
MariaDB [(none)]> show create database testdb;
可以查看当初是如何创建数据库的。
- 服务器配置文件中指定字符键,(排序规则一般使用字符集默认的排序规则)
配置方法:
[mysqld]
character_set_server=utf8mb4
客户端与服务器端的字符集应该相同
/etc/my.cnf.d/client.cnf
[mysql]
default-character-set=utf8mb4
服务器端、客户端、开发需要统一字符集
修改数据库:
- ALTER DATABASE DB_NAME character set utf8;
删除数据库:
-
DROP DATABASE|SCHEMA [IF EXISTS] ‘DB_NAME’;
将整个文件夹和文件夹中的所有数据均删除 -
手动删除对应的文件夹(一般不这么删)
查看与库相关的信息:
- 查看支持所有字符集:SHOW CHARACTER SET;
- 查看支持所有排序规则:SHOW COLLATION;
- 查看表的创建信息: show create database testdb;
表相关的操作:※※※※※
表的创建相关概念:
- 表:二维关系
- 设计表:遵循规范(符合范式)
- 定义:字段,索引
字段:字段名,字段数据类型,修饰符
约束,索引:应该创建在经常用作查询条件的字段上
字段的数据类型
1)数据类型:
- 数据是什么?数字or字符串?
- 数据需要多长空间存放?定义了数据类型,就确定了对应的存储空间大小
2)系统内置数据类型和用户定义数据类型
3)MySQL支持多种列类型:
- 数值类型
- 日期/时间类型
- 字符串类型
- https://dev.mysql.com/doc/refman/5.5/en/data-types.html
4)选择正确数据类型至关重要,选择数据类型的原则:
- 更小的通常更好,尽量使用可正确存储数据的最小数据类型
- 简单就好,简单数据类型的操作通常需要更少的CPU周期
- 尽量避免NUL,包含NULL的列,对MySQL更难优化
数据类型之数值型
1)数据类型:

2)整型
-
tinyint(m) 1个字节 范围(-128~127)
-
smallint(m) 2个字节 范围(-32768~32767)
-
mediumint(m) 3个字节 范围(-8388608~8388607)
-
int(m) 4个字节 范围(-2147483648~2147483647)
-
bigint(m) 8个字节 范围(±9.22*10的18次方)
-
最高位为符号位,表示无符号位前面加修饰符:unsigned
-
说明1:
1Byte=8bit
当表示unsigned 时
比如:unsigned int ==> 2^32
unsigned是修饰符 -
说明2:上述中的m,即**int(m) 表示示SELECT查询结果集中的显示宽度。
并不影响实际的取值范围,规定了MySQL的一些交互工具(例如MySQL命令行客户端)用来显示字符的个数。对于存储和计算来说,Int(1)和Int(20)是相同的。 -
BOOL,BOOLEAN:布尔型,是TINYINT(1)的同义词。zero值被视为假,非zero值视为真
3)浮点型(float和double),近似值,具有表示精度
- float(m,d) 单精度浮点型 8位精度(4字节) m总个数,d小数位
- double(m,d) 双精度浮点型16位精度(8字节) m总个数,d小数位
- 定义一个字段为float(6,3),如果插入一个数123.45678,实际数据库里存的是123.457,但总个数还以实际为准,即6位
4)定点数
-
在数据库中存放的是精确值,存为十进制
-
decimal(m,d) 参数m<65 是总个数,d<30且 d<m 是小数位
-
MySQL5.0和更高版本将数字打包保存到一个二进制字符串中(每4个字节存9个数字)。例如,decimal(18,9)小数点两边将各存储9个数字,一共使用9个字节:小数点前的数字用4个字节,小数点后的数字用4个字节,小数点本身占1个字节
-
浮点类型在存储同样范围的值时,通常比decimal使用更少的空间。float使 用4个字节存储。double占用8个字节
-
因为需要额外的空间和计算开销,所以应该尽量只在对小数进行精确计算时才使用decimal,例如存储财务数据。但在数据量比较大的时候,可以考虑使用bigint代替decimal
数据类型之字符型
1)char 与 varchar的区别
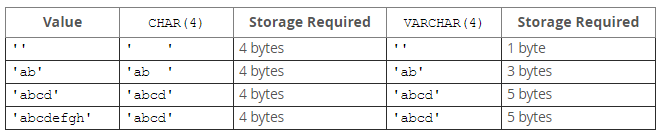
定长访问效率高,变长节约磁盘空间,根据实际需求选择,如果字符串数据长度相差不大,考虑使用char(#)。如果字符串差距比较大,而且还没有规律,考虑定义varchar(#)
2)字符串(char,varchar,_text)
- char(n) 固定长度,最多255个字符
- varchar(n) 可变长度,最多65535个字符
- tinytext 可变长度,最多255个字符
- text 可变长度,最多65535个字符
- mediumtext 可变长度,最多2的24次方-1个字符
- longtext 可变长度,最多2的32次方-1个字符
- BINARY(M) 固定长度,可存二进制或字符,长度为0-M字节
- VARBINARY(M) 可变长度,可存二进制或字符,允许长度为0-M字节
- 内建类型:ENUM枚举, SET集合
3)二进制数据:BLOB
- BLOB和text存储方式不同,TEXT以文本方式存储,英文存储区分大小写,而Blob是以二进制方式存储,不分大小写
- BLOB存储的数据只能整体读出
- TEXT可以指定字符集,BLOB不用指定字符集
数据类型之日期型
1)日期时间类型
- date 日期 ‘2008-12-2’
- time 时间 ‘12:25:36’
- datetime 日期时间 ‘2008-12-2 22:06:44’
- timestamp 自动存储记录修改时间
- YEAR(2), YEAR(4):年份
- timestamp字段里的时间数据会随其他字段修改的时候自动刷新,这个数据类型的字段可以存放这条记录最后被修改的时间
数据类型之枚举(复合型数据类型)
- enum(‘value1’,‘value2’,…)从列举的值中选择一个。
修饰符
1)所有类型:
- NULL 数据列可包含NULL值
- NOT NULL 数据列不允许包含NULL值
- DEFAULT 默认值
- PRIMARY KEY 主键
- UNIQUE KEY 唯一键
- CHARACTER SET name 指定一个字符集
2)数值型
- AUTO_INCREMENT 自动递增,适用于整数类型
- UNSIGNED 无符号
表的创建
创建表的方式:help create table
- 方式一:直接创建
CREATE [TEMPORARY] TABLE [IF NOT EXISTS] tbl_name
(create_definition,...)
[table_options]
[partition_options]
(create_definition 创建表的相关定义):列的名称和列的定义
列的定义:数据类型 [NOT NULL | NULL] [DEFAULT default_value]
[AUTO_INCREMENT] [UNIQUE [KEY] | [PRIMARY] KEY]
数据类型:BIT[(length)]
| TINYINT[(length)] [UNSIGNED] [ZEROFILL]
| SMALLINT[(length)] [UNSIGNED] [ZEROFILL]
........
ENUM(value1,value2,value3,...)
.......
-
方式二:通过查询已经创建的表,新表会被直接插入查询而来的数据
-
方式三:通过复制现存的表的表结构创建,但不复制数据
-
注意:
①Storage Engine是指表类型,也即在表创建时指明其使用的存储引擎,同一库中不同表可以使用不同的存储引擎
②同一个库中表建议要使用同一种存储引擎类型 -
CREATE TABLE [IF NOT EXISTS] ‘tbl_name’ (col1 type1 修饰符, col2 type2 修饰符, …
-
字段信息
col type1
PRIMARY KEY(col1,…)
INDEX(col1, …)
UNIQUE KEY(col1, …) -
表选项:
ENGINE [=] engine_name
SHOW ENGINES;查看支持的engine类型
ROW_FORMAT [=] {DEFAULT|DYNAMIC|FIXED|COMPRESSED|REDUNDANT|COMPACT}
创建的表对应于磁盘上来说:
较老版本对应的数据库目录下只有一个文件==>tbl_name.frm
老版本的数据放在datadir/ibdata1
较新版本对应的数据库目录下有两个文件==>tbl_name.frm和tbl_name.ibd
tbl_name.ibd文件即存放数据的文件
tbl_name.frm表的定义
这个对应的配置文件选项是:
innodb_file_table=on 每个表独立文件
新版本中默认innodb_file_per_table=on
查询数据库中此值的状态:
MariaDB [testdb]> show variables like "innodb_file%";
表操作
- 查看所有的引擎:SHOW ENGINES
- 查看表:SHOW TABLES [FROM db_name]
- 查看表结构:DESC [db_name.]tb_name
SHOW COLUMNS FROM [db_name.]tb_name - 删除表:DROP TABLE [IF EXISTS] tb_name
- 查看表创建命令:SHOW CREATE TABLE tbl_name
- 查看表状态:SHOW TABLE STATUS LIKE 'tbl_name’
如果字段过多,一行很横着显示比较难看,配合 \G 选项显示
MariaDB [testdb]> show table status like 'student'\G
- 查看库中所有表状态:SHOW TABLE STATUS FROM db_name
- 修改表: ALTER TABLE ‘tbl_name’
字段:
添加字段:add
ADD col1 data_type [FIRST|AFTER col_name]
删除字段:drop
修改字段:
alter(默认值), change(字段名), modify(字段属性)
索引:
添加索引:add index
删除索引:drop index
表选项
修改:
对于一张表来说,表一旦创建就很少对其字段进行修改,如果添加新字段,对
于现有的记录来说新加的字段没有值。
- 查看表上的索引:SHOW INDEXES FROM [db_name.]tbl_name;
表的DML语句:增删改
- DML: INSERT, DELETE, UPDATE
1) INSERT:一次插入一行或多行数据
- ①INSERT tbl_name [(col1,…)] VALUES (val1,…), (val21,…)
- ②INSERT [LOW_PRIORITY | DELAYED | HIGH_PRIORITY] [IGNORE]
[INTO] tbl_name
SET col_name={expr | DEFAULT}, …
[ ON DUPLICATE KEY UPDATE
col_name=expr
[, col_name=expr] … ] - ③INSERT [LOW_PRIORITY | HIGH_PRIORITY] [IGNORE]
[INTO] tbl_name [(col_name,…)]
SELECT …
[ ON DUPLICATE KEY UPDATE
col_name=expr
[, col_name=expr] … ]
2)UPDATE:
-
UPDATE [LOW_PRIORITY] [IGNORE] table_reference
SET col_name1={expr1|DEFAULT} [, col_name2={expr2|DEFAULT}] …
[WHERE where_condition]
[ORDER BY …]
[LIMIT row_count] -
注意:一定要有限制条件,否则将修改所有行的指定字段
限制条件:
WHERE
LIMIT -
mysql 选项:-U|–safe-updates| --i-am-a-dummy
避免没有添加限制条件时执行,导致所有行的指定字段均被修改
mysql -U
修改mysql客户端命令的配置文件:
vim /etc/my.cnf.d/client.cnf
[mysql]
safe-updates
MariaDB [test]> update student set gender='f';
ERROR 1175 (HY000): You are using safe update mode and you tried
to update a table without a WHERE that uses a KEY column
可见不加where 限定条件是不能执行update
3)DELETE:
- DELETE [LOW_PRIORITY] [QUICK] [IGNORE] FROM tbl_name
[WHERE where_condition]
[ORDER BY …]
[LIMIT row_count]
可先排序再指定删除的行数 - 注意:一定要有限制条件,否则将清空表中的所有数据
限制条件:
WHERE
LIMIT - TRUNCATE TABLE tbl_name; 清空表(瞬间清空表)
truncate table tbl_name;
防止没有添加限制条件时执行delete,与update一样,即
mysql -U 既可以防止update 也可以防止delete
表的DQL语句:SELECT ※※※※※
select用法一:省略表名时
1)省略对表进行查询,即select 不对具体的tbl_name进行查询
- 用法帮助:help select
示例:select可以相当于echo
MariaDB [(none)]> select "hello";
+-------+
| hello |
+-------+
| hello |
+-------+
MariaDB [(none)]> select "hello" as test; 给字段起别名,其中as可省略
+-------+
| test |
+-------+
| hello |
+-------+
MariaDB [(none)]> select 2*4 result;
+--------+
| result |
+--------+
| 8 |
+--------+
MariaDB [(none)]> select now() time;
+---------------------+
| time |
+---------------------+
| 2019-09-16 15:27:07 |
+---------------------+
select用法二:单表查询
此处单表查询时需要使用students表:其中的数据如下:
...>CREATE TABLE `students` (
-> `StuID` int(10) unsigned NOT NULL AUTO_INCREMENT,
->`Name` varchar(50) NOT NULL,
->`Age` tinyint(3) unsigned NOT NULL,
->`Gender` enum('F','M') NOT NULL,
->`ClassID` tinyint(3) unsigned DEFAULT NULL,
->`TeacherID` int(10) unsigned DEFAULT NULL,
->PRIMARY KEY (`StuID`)
->) ENGINE=InnoDB AUTO_INCREMENT=26 DEFAULT CHARSET=utf8;
...>INSERT INTO `students` VALUES
->(1,'Shi Zhongyu',22,'M',2,3),
->(2,'Shi Potian',22,'M',1,7),
->(3,'Xie Yanke',53,'M',2,16),
->(4,'Ding Dian',32,'M',4,4),
->(5,'Yu Yutong',26,'M',3,1),
->(6,'Shi Qing',46,'M',5,NULL),
->(7,'Xi Ren',19,'F',3,NULL),
->(8,'Lin Daiyu',17,'F',7,NULL),
->(9,'Ren Yingying',20,'F',6,NULL),
->(10,'Yue Lingshan',19,'F',3,NULL),
->(11,'Yuan Chengzhi',23,'M',6,NULL),
->(12,'Wen Qingqing',19,'F',1,NULL),
->(13,'Tian Boguang',33,'M',2,NULL),
->(14,'Lu Wushuang',17,'F',3,NULL),
->(15,'Duan Yu',19,'M',4,NULL),
->(16,'Xu Zhu',21,'M',1,NULL),
->(17,'Lin Chong',25,'M',4,NULL),
->(18,'Hua Rong',23,'M',7,NULL),
->(19,'Xue Baochai',18,'F',6,NULL),
->(20,'Diao Chan',19,'F',7,NULL),
->(21,'Huang Yueying',22,'F',6,NULL),
->(22,'Xiao Qiao',20,'F',1,NULL),
->(23,'Ma Chao',23,'M',4,NULL),
->(24,'Xu Xian',27,'M',NULL,NULL),
->(25,'Sun Dasheng',100,'M',NULL,NULL);
- 字段显示可以使用别名:
col1 AS alias1, col2 AS alias2, …
创建表时,表的字段名一般还是使用英文,查询时可以选择别名
MariaDB [hellodb]> select stuid,name,age from students;
select 后面直接选择查询的字段
> select stuid 学号,name 姓名,age 年龄 from students;
- DISTINCT 去除重复列
SELECT DISTINCT gender FROM students;
比如只查询性别字段时:
> select distinct gender from students;
实际有主键就不会出现重复的记录,满足范式
> select distinct * from students;过滤一张表中的重复记录
-
WHERE子句:指明过滤条件以实现“选择”的功能:
过滤条件:布尔型表达式算术操作符:+, -, *, /, %
比较操作符:
=,
<=>(相等或都为空),
<>,
!=(非标准SQL),
>,
>=,
<,
<=BETWEEN min_num AND max_num
IN (element1, element2, …)
IS NULL
IS NOT NULL
示例:
> select stuid 学号,name 姓名,age 年龄 from students where age<20;
查询某字段为空的写法:where field is [not] null
空值查询的方式都与众不同,因此定义表数据时,尽量避免空值出现
> select * from students where teacherid is null;
介于某值之间的查询:两种写法如下
> select * from students where age>20 and age<30;
> select * from students where age between 20 and 30;
多个之间选一个的查询:in
> select * from students where age in (18,20,23);
-
逻辑操作符:
NOT
AND
OR
XOR -
LIKE:
% 任意长度的任意字符
_ 任意单个字符 -
RLIKE:正则表达式,索引失效,不建议使用
-
REGEXP:匹配字符串可用正则表达式书写模式,同上
查询某字段以什么开头的字段
> select * from students where name like 'l%';
注:'d%' ==> 表示的是以d字母开头的行,而不是包含d子母的行
'%d%' ==> 表示包含d字母的行
正则表达式将导致索引失效,在数据库查询中一般不使用正则表达式
- GROUP:根据指定的条件把查询结果进行“分组”以用于做“聚合”运算
avg(), max(), min(), count(), sum()
HAVING: 对分组聚合运算后的结果指定过滤条件
分组表示对数据库中的表做一些分类,再对分完类的数据进行统计。即分组统计
分组一般会用到一些和分组统计的函数即聚合函数:avg(), max()...
一:聚合函数演示:
MariaDB [hellodb]> select count(*) 记录数 from students;
①count(*)统计记录数,*表示所有字段
注意:> select count(teacherid) from students;
count()统计记录数时,一般不用跟某一字段,(主键可以)
count()统计的是非空值的数量,将自动过滤空值
②计算某个field的sum(),avg(),..
MariaDB [hellodb]> select avg(age) from students;
二:按照分组进行汇总统计
①按照性别统计平均年龄:
> select avg(age) from students group by gender;
+----------+ group by gender 对性别进行分类
| avg(age) |
+----------+
| 19.0000 |
| 33.0000 |
+----------+
> select gender 性别,avg(age) 平均年龄 from students group by gender;
+--------+--------------+
| 性别 | 平均年龄 |
+--------+--------------+
| F | 19.0000 |
| M | 33.0000 |
+--------+--------------+
注:> select name,avg(age) from students group by gender;
这种写法逻辑上是you问题的,在有些数据库中这种写法是错误的。
综上:分组统计时,一旦对某个field进行分组统计后,在select后面的信息只能
为两种: ①分组的field
②聚合函数
②分组多次:统计每个班的男生女生各有多少人
>select classid,gender,count(*) from students group by classid,gender;
注:group by classid,gender其中classid和gender的顺序没有影响,只
是显示效果上有区别。
三:分组之后再过滤:
比如:按班级分组统计平均年龄
> select classid,avg(age) from students group by classid;
+---------+----------+
| classid | avg(age) |
+---------+----------+
| NULL | 63.5000 |
| 1 | 20.5000 |
| 2 | 36.0000 |
| 3 | 20.2500 |
| 4 | 24.7500 |
| 5 | 46.0000 |
| 6 | 20.7500 |
| 7 | 19.6667 |
+---------+----------+
此处想将classid为null的值过滤掉
先分组后过滤时,关键字不能使用where即以下写法是错误的:
>select classid,avg(age) from students group by classid where \
classid is not null ;
将where 改为 having (先分组后过滤)
> select classid,avg(age) from students group by classid having\
classid is not null ;
+---------+----------+
| classid | avg(age) |
+---------+----------+
| 1 | 20.5000 |
| 2 | 36.0000 |
| 3 | 20.2500 |
| 4 | 24.7500 |
| 5 | 46.0000 |
| 6 | 20.7500 |
| 7 | 19.6667 |
+---------+----------+
当然可以先过滤在分组:
> select classid,avg(age) from students where classid is not\
null group by classid;
即要使用where 就必须将where放在group前面!
综上:先分组后过滤使用having
先过滤后分组使用where
- ORDER BY: 根据指定的字段对查询结果进行排序
升序:ASC
降序:DESC
order by field 对个字段进行排序(默认是正序)
order by field asc 正序 默认asc省略不写
order by field desc 倒序
> select * from students order by age;
> select * from students order by age asc;
> select * from students order by age desc;
MariaDB [hellodb]> select classid,gender,count(*) from students\
group by gender,classid order by classid ;
+---------+--------+----------+
| classid | gender | count(*) |
+---------+--------+----------+
| NULL | M | 2 |
| 1 | F | 2 |
| 1 | M | 2 |
| 2 | M | 3 |
| 3 | M | 1 |
| 3 | F | 3 |
| 4 | M | 4 |
| 5 | M | 1 |
| 6 | F | 3 |
| 6 | M | 1 |
| 7 | F | 2 |
| 7 | M | 1 |
+---------+--------+----------+
先分组统计然后排序,但是可见NULL值默认排在最前面
> select classid,gender,count(*) from students group by gender,、classid order by -classid desc;
+---------+--------+----------+
| classid | gender | count(*) |
+---------+--------+----------+
| 1 | F | 2 |
| 1 | M | 2 |
| 2 | M | 3 |
| 3 | F | 3 |
| 3 | M | 1 |
| 4 | M | 4 |
| 5 | M | 1 |
| 6 | F | 3 |
| 6 | M | 1 |
| 7 | F | 2 |
| 7 | M | 1 |
| NULL | M | 2 |
+---------+--------+----------+
让null值排在最后的办法:order by -field desc
仅是null在末尾,其余还是正序排列
- LIMIT [[offset,]row_count]:对查询的结果进行输出行数数量限制
> select distinct age from students order by age limit 2,3;
对输出结果取前三:limit 3;
对输出结果跳过两个取前三:limit 2,3;
- 对查询结果中的数据请求施加“锁”
FOR UPDATE: 写锁,独占或排它锁,只有一个读和写
LOCK IN SHARE MODE: 读锁,共享锁,同时多个读
SQL注入:实现非法验证
创建一个存放用户账户密码的简单表:如下
MariaDB [hellodb]> create table user(
-> id int unsigned auto_increment primary key,
-> name varchar(20),
-> password varchar(20)
-> );
MariaDB [hellodb]> desc user;
用户注册,即在其中添加几条记录
> insert user (name,password)values('alice','123456');
> insert user (name,password)values('admin','P@ssword!');
查看:
MariaDB [hellodb]> select * from user;
+----+-------+-----------+
| id | name | password |
+----+-------+-----------+
| 1 | alice | 123456 |
| 2 | admin | P@ssword! | admin是管理员
+----+-------+-----------+
用户验证机制:执行一个查询语句:
> select * from user where name='alice' and password='123456';
+----+-------+----------+
| id | name | password |
+----+-------+----------+
| 1 | alice | 123456 |
+----+-------+----------+
能查询出结果,验证成功,如果查询不到结果,验证失败。
SQL注入:构建一个奇怪的用户名和一个奇怪的密码实现验证。
> select * from user where name='admin'--' and password=''';
> select * from user where name='bob'--' and password=''';
--在SQL中表示单行注释
+----+-------+-----------+
| id | name | password |
+----+-------+-----------+
| 1 | alice | 123456 |
| 2 | admin | P@ssword! |
+----+-------+-----------+
不论用户是谁,均能查询至结果。即能通过验证。
另外一种方式:
> select * from user where name='xxx' and password=''or'1'='1';
select用法三:多表查询
- 为满足范式将一张表拆分为多表,查询时肯定涉及到多表查询。
3)两表查询:
两张表查询:除上面的studes表附加一张teachers表:
CREATE TABLE `teachers` (
`TID` smallint(5) unsigned NOT NULL AUTO_INCREMENT,
`Name` varchar(100) NOT NULL,
`Age` tinyint(3) unsigned NOT NULL,
`Gender` enum('F','M') DEFAULT NULL,
PRIMARY KEY (`TID`)
) ENGINE=InnoDB AUTO_INCREMENT=5 DEFAULT CHARSET=utf8;
INSERT INTO `teachers` VALUES
(1,'Song Jiang',45,'M'),
(2,'Zhang Sanfeng',94,'M'),
(3,'Miejue Shitai',77,'F'),
(4,'Lin Chaoying',93,'F');
- 将两张表的数据合并起来,然后将两张表的数据显示出来。可理解为将两张表合并起来。两张表合并的方式:
最简单的合并方式:纵向和横向合并
纵向合并:
参与合并的field数保持相同
参与合并的field数据应该是相同类型
横向合并:
纵向合并: union
参与合并的field数保持相同
参与合并的field数据应该是相同类型
将teacher和students两张表进行纵向合并:
MariaDB [hellodb]> desc teachers;输出部分显示
+--------+
| Field |
+--------+
| TID |
| Name |
| Age |
| Gender |
+--------+
MariaDB [hellodb]> desc students;
+-----------+
| Field |
+-----------+
| StuID |
| Name |
| Age |
| Gender |
| ClassID |
| TeacherID |
+-----------+
==>以上部分结果显示,teacher和students两张表的字段数目不相同,直接
使用union连接两张表是行不通的;
> select * from teachers union select * from students;
ERROR:The used SELECT statements have a different number of columns
==>想要将teacher和students两张表纵向合并,则可从两张表中各挑选出相同字段连接。
如下示例:
> select tid as id,name,age from teachers union select stuid,name,age from students;
+-----+---------------+-----+
| id | name | age |
+-----+---------------+-----+
| 1 | Song Jiang | 45 |
| 2 | Zhang Sanfeng | 94 |
| 3 | Miejue Shitai | 77 |
| 4 | Lin Chaoying | 93 |
| 1 | Shi Zhongyu | 22 |
| 2 | Shi Potian | 22 |
| 3 | Xie Yanke | 53 |
| 4 | Ding Dian | 32 |
| 5 | Yu Yutong | 26 |
| 6 | Shi Qing | 46 |
| 7 | Xi Ren | 19 |
| 8 | Lin Daiyu | 17 |
| 9 | Ren Yingying | 20 |
| 10 | Yue Lingshan | 19 |
| 11 | Yuan Chengzhi | 23 |
| 12 | Wen Qingqing | 19 |
| 13 | Tian Boguang | 33 |
| 14 | Lu Wushuang | 17 |
| 15 | Duan Yu | 19 |
| 16 | Xu Zhu | 21 |
| 17 | Lin Chong | 25 |
| 18 | Hua Rong | 23 |
| 19 | Xue Baochai | 18 |
| 20 | Diao Chan | 19 |
| 21 | Huang Yueying | 22 |
| 22 | Xiao Qiao | 20 |
| 23 | Ma Chao | 23 |
| 24 | Xu Xian | 27 |
| 25 | Sun Dasheng | 100 |
+-----+---------------+-----+
注:显示的字段名称是从第一张表继承的,因此可以考虑对字段名称用别名。
注:查询结果时来源原来的表,结果不能更改。
> select * from teachers union select * from teachers;
+-----+---------------+-----+--------+
| TID | Name | Age | Gender |
+-----+---------------+-----+--------+
| 1 | Song Jiang | 45 | M |
| 2 | Zhang Sanfeng | 94 | M |
| 3 | Miejue Shitai | 77 | F |
| 4 | Lin Chaoying | 93 | F |
+-----+---------------+-----+--------+
==>可见union可以排除相同的记录。
>select * from teachers union all select * from teachers;
union all 将不合并相同的记录
横向合并:横向笛卡尔(交叉连接) cross join
两张表横向合并即逻辑上两张表的每条记录互相组合一遍
即:studens表(6个字段,25个记录)和teachers表(4个字段,4条记录)
==>横向合并为(10个字,100条记录)
> select * from teachers cross join students;
teacher和students两张表的顺序和显示结果无关,只是显示有区别、
==>综上:交叉连接意义不大
交叉连接之后,显示时,由于两张表均有name,age等相同的字段,因此筛选时需
要指明哪个表的哪个字段。
但是如果表明比较长,重复写相同字段是比较麻烦,可以使用对表名定义别名
> select teachers.name 老师名字,teachers.age 老师年龄,students.name 学生名字,students.age 学生年龄 from teachers cross join students;
对表取别名 注:表取别名之后,前面的字段筛选时必须使用别名
> select t.name 老师名字,t.age 老师年龄,s.name 学生名字,s.age 学生年龄 from teachers as t cross join students as s;
- 横向合并取交集:内连接
两张表有一定的交集,即有一定的满足关系

横向合并取交集:
tab1 inner join tab2 on (tab1与tab2的交集条件)
teacher和students两张表的交集为teachers.tid=students.teacherid
> select t.name 老师名字,t.age 老师年龄,s.name 学生名字,s.age 学生年龄 from teachers as t cross join students as s where t.tid=s.teacherid;
> select t.name 老师名字,t.age 老师年龄,s.name 学生名字,s.age 学生年龄 from teachers as t,students as s where t.tid=s.teacherid;
以上两种使用where是以前的写法
> select * from students as s inner join teachers as t on s.teacherid=t.tid;
> select t.name 老师名字,t.age 老师年龄,s.name 学生名字,s.age 学生年龄 from students as s inner join teachers as t on s.teacherid=t.tid;
- 左外连接与右外连接
注:此时左右有区别
左边外连接:左边表记录全显示,右边表只选择有交集的部分如下图

右边外连接:右边表记录全显示,左边表只选择有交集的部分如下图

左外连接:tab1 left outer join tab2 on (tab1与tab2的交集条件)
右外连接:tab1 right outer join tab2 on (tab1与tab2的交集条件)
左外连接示例:
> select t.name 老师名字,t.age 老师年龄,s.name 学生名字,s.age 学生年龄 from teachers as t left outer join students as s on t.tid=s.teacherid;
> select * from teachers as t left outer join students as s on t.tid=s.teacherid;
综上:左外连接显示记录数为左边表的记录数
右外连接显示记录数为右边表的记录数
- 左/右外连接的扩展


左/右外连接扩展,左外连接再将交集的地方排除
> select t.name 老师名字,t.age 老师年龄,s.name 学生名字,s.age 学生年龄 from teachers t left outer join students s on t.tid=s.teacherid where s.teacherid is null;
- 完全外连接
mysql 不支持full outer join 这种写法

mysql左外连接和有外连接纵向连接
> tab1 left outer join tab2 on (tab1与tab2的交集条件)
--> union
--> tab1 right outer join tab2 on (tab1与tab2的交集条件);
> select * from teachers left outer join students on teachers.tid=students.teacherid union select * from teachers right outer join students on teachers.tid=students.teacherid;
- 自连接 ==> 内外连接的变种
有这样一张表:
MariaDB [hellodb]> select * from emp;
+------+------+----------+
| id | name | leaderid |
+------+------+----------+
| 1 | zhou | NULL |
| 2 | wu | 1 |
| 3 | li | 2 |
+------+------+----------+
如今要查询的是emp以及对应lead
==>将一张表想象成两张表,可以利用别名实现,对应于两张表~
> select e.name 员工,l.name 领导 from emp as e left outer join emp as l on e.leaderid=l.id;
+--------+--------+
| 员工 | 领导 |
+--------+--------+
| wu | zhou |
| li | wu |
| zhou | NULL |
+--------+--------+
注: left outer join
如果是inner join 将会丢失领导为null的记录
- 子查询:一个SQL语句中调用另一个SQL语句的执行结果
例1:查询学生表的平均年龄
> select avg(age) from students;
例2:查询所有小于以上平均年龄的学生的姓名和年龄
> select name 姓名,age 年龄 from students where age < (select avg(age) from students);
注:子查询不一定是select调用select,而是SQL语句之间的相互调用。
- 完全外连接之后去除交集 ==>完全外连接的扩展

MariaDB [hellodb]> select * from (select s.stuid,s.name s_name,s.teacherid,t.tid,t.name t_name from students s left outer join teachers t on s.teacherid=t.tid union select s.stuid,s.name,s.teacherid,t.tid,t.name from students s right outer join teachers t on s.teacherid=t.tid) as a where a.teacherid is null or a.tid is null;
(select s.stuid,s.name s_name,s.teacherid,t.tid,t.name t_name from students s left outer join teachers t on s.teacherid=t.tid union select s.stuid,s.name,s.teacherid,t.tid,t.name from students s right outer join teachers t on s.teacherid=t.tid)
将此作为一张xin表作为一个整体
==>
以上内连接、外连接(左外和右外)、外连接扩展、完全外连接、完全外连接扩展以及自连接均是在横向连接的基础上满足两张表的有交集条件的基础上实现的。
4)三张表的查询
- 表示多对多的关系,一般最多涉及三表查询,超过三张表,说明表的设计有问题
where ... and ...实现
> select st.name,co.course,sc.score from scores as sc,students as st,courses as co where sc.stuid=st.stuid and sc.courseid=co.courseid;
多表连接时,尽量小表驱动大表,即小表 join 大表
> select st.name,co.course,sc.score from scores as sc inner join students as st on st.stuid=sc.stuid inner join courses as co on sc.courseid=co.courseid;
select语句的处理顺序
- FROM–>ON–>JOIN–>WHERE–>GROUP BY–>HAVING–>SELECT(挑选字段)–>DISTINCT–>ORDER BY–>LIMIT
















 1070
1070











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









