







 本文深入探讨Kafka的消费者与消费者组概念,解释消息投递模式,详细介绍了消费者应用、消费位移、控制消费、再平衡、拦截器以及重要参数设置,帮助读者理解Kafka消费者的工作原理和最佳实践。
本文深入探讨Kafka的消费者与消费者组概念,解释消息投递模式,详细介绍了消费者应用、消费位移、控制消费、再平衡、拦截器以及重要参数设置,帮助读者理解Kafka消费者的工作原理和最佳实践。
前言
前面讲解了 Kafka 的生产者,而与生产对应的就是消费者,程序中可以通过 KafkaConsumer 来订阅主题,并从订阅的主题中拉取消息。而 Kafka 中消费者比生产者多了个组的概念,也称消费者组,从而提升单机的消费速度。本文将介绍下消费者与消费者组的概念,然后再对客户端开发进行详细讲解。
一、消费者与消费者组
消费者负责订阅 Kafka 中的主题,并且从上面拉取消息,但与生产者不同的是它增加了消费者组的概念,这是因为很多时候 Kafka 的消费者在消费消息的时候经常会做一些高延时的动作,比如把数据写到数据库,读取数据进行计算处理等,这就相对于 producer 慢的多了,因此消费者组的增加是用来提升 Kafka 的消费能力而出现的,当同一个主题的消息再次过来的时候,这些消息就会被同一个消费者组的消费者来共同消费。
1.1 图解消费者模型
下面,我们来看看这个消费的过程。
情形一:
比如公司里有个打印服务,假设有 6 个打印分区,分别对应 彩印word、彩印excel、彩印ppt、黑白word、黑白excel、黑白ppt 六个分区内容,此时只要一台打印机。如下
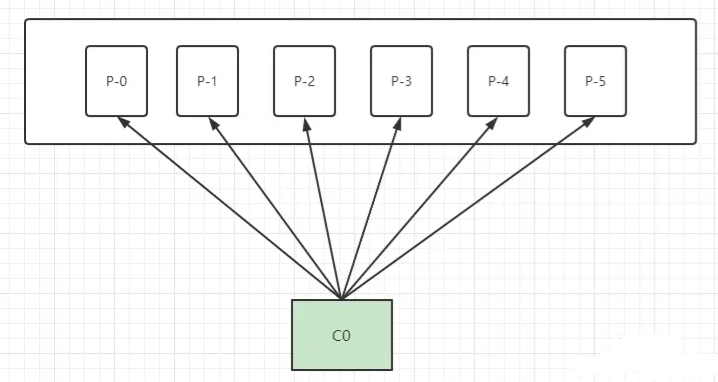
情形二:
但是这个打印机打印的效果实在太慢了,很多人一天到晚都挤在打印室排队打印文档。这时,公司就新购了台打印机,让它们分别处理打印请求,可以把它们放在一个消费者组中,同时消费这些分区的数据。
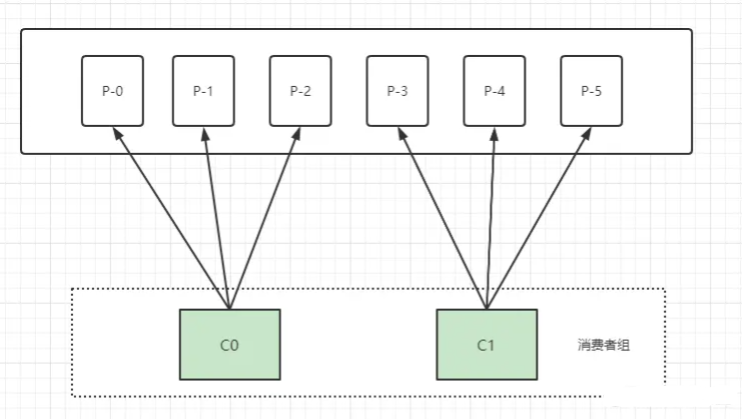
此时它们就分别处理所分配到分区的数据,逻辑上彼此不干扰。同一个主题中的消息只会发布给消费者组中的一个消费者。
情形三:
此时,公司想要加个打印备份功能,于是又采购了一个打印机,用来同步打印所有的打印文件。(ps :我也不知道这是什么奇葩公司,为了场景随便举的例子~)
如下:
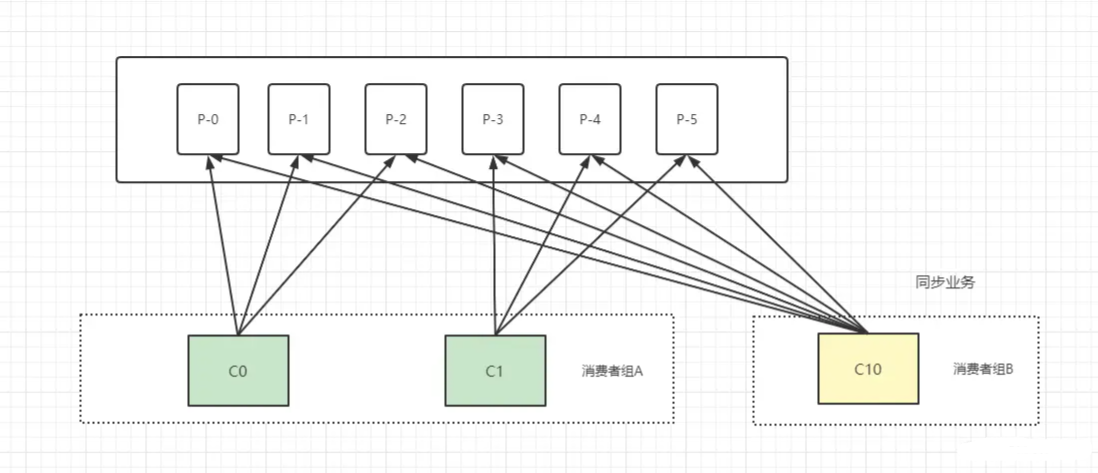
这时候每个分区的数据都会发送到消费者组B 中即同一个分区的消息可以被不同消费者组的消费者消费。
情形四:
此时,公司为了准备融资,给投资人秀秀自己的肌肉,于是又请购了五台打印机,这时候的场景如下:
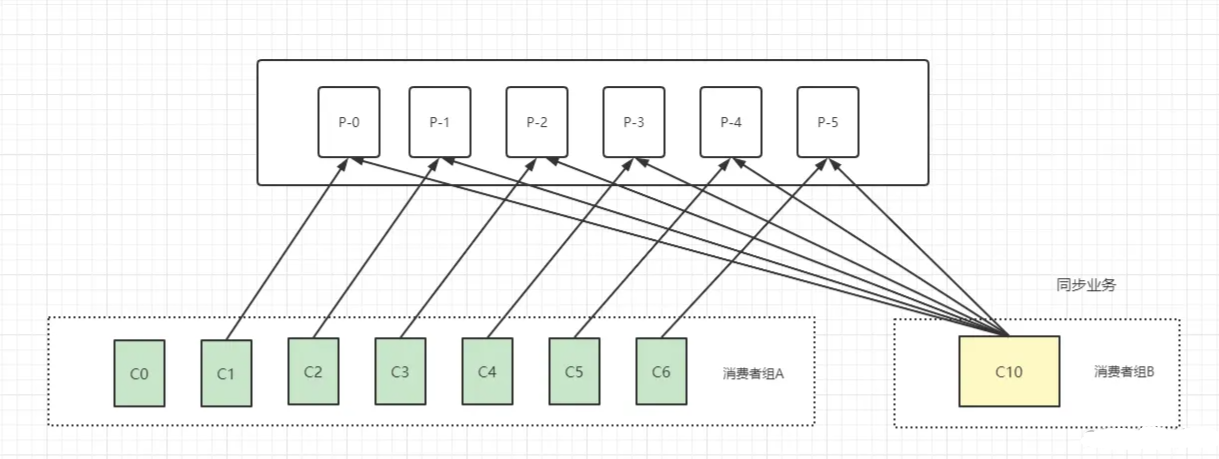
虽然说消费者与消费者组这种模型可以让整体的消费能力具备横向伸缩性,但是对于分区固定的情况下,增加消费者并不一定能提升消费能力,如图所示,此时就有一台打印机无法分配到分区而消费不了数据。
1.2 消息投递模式
之前说过消息队列的两种模式,即点对点和发布订阅模式。而 Kafka 同时支持这两种模式。下面的这个理解很关键。
- 点对点模式基于队列,类似于同一个消费者组中的数据,由生产者发送数据到分区,然后消费者拉取分区的消息进行消费,此时消息只能被同一个消费者组的消费者消费一次。
- 发布订阅模式模式就是 kafka 中的分区消息可以被不同消费者组的消费者消费。这就是一对多的广播模式应用。
当然,消费者组是一个逻辑的概念,通过客户端参数 group.id 来配置,默认值为空字符串。而消费者并不是逻辑的概念,它是真正消费数据的实体,可以是线程、也可以是一个机器。
好,明白了消费者与消费者组的概念,接下来我们正式打开 消费者客户端的潘多拉魔盒。
二、Kafka 消费者的应用
同样,消费者也是依赖于 Kafak 的客户端,正常的消费逻辑是下面几个步骤:
- 1、配置消费者客户端参数及创建相应的消费者实例
- 2、订阅主题
- 3、拉取消息并消费
- 4、提交消费位移
- 5、关闭消费者实例
这里的位移可能我们还不清楚是什么意思,别急,我们后面会讲到,先来看下一个典型的消费者它应该怎么写。
2.1 消费者客户端演示
public class Consumer {
public static void main(String[] args) {
Properties props = new Properties();
props.put("bootstrap.servers", "192.168.81.101:9092");
props.put("group.id", "test"); //消费者组
props.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
props.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props);
consumer.subscribe(Arrays.asList("xiaolei2"));
while (true) {
ConsumerRecords<String, String> records = consumer.poll(100);
for (ConsumerRecord<String, String> record : records){
System.out.printf("offset = %d, key = %s, value = %s%n", record.offset(), record.key(), record.value());
}
}
}
}2.2 必要参数配置
在创建消费者的时候,Kafka 有 4 个参数 是必填的,比生产者多了一个。
- bootstrap.servers : 这个参数用来指定连接 Kafka 集群的 broker 地址列表,可以是单个地址,也可以用逗号分割填上 Kafka 集群地址。
- key.deserializer 和 value. deserializer :因为消息发送的时候将key 和 value 进行序列化生成字节数组,因此消费数据的时候需要反序列化为原来的数据。
- group.id : 消费者所在组的名称,默认值为 ”“,如果设置为空,则会抛出异常 Exception in thread "main" org.apache.kafka.common.errors.InvalidGroupIdException: To use the group management or offset commit APIs, you must provide a valid group.id in the consumer configuration. 复制代码
2.3 订阅主题与分区
在创建出 consumer 之后,我们需要为它订阅相关的主题,一个消费者可以订阅一个或多个主题。这里可以使用两个 API
- consumer.subscribe(Collection topics) :指明需要订阅的主题的集合;
- consumer.subscribe(Pattern pattern) :使用正则来匹配需要订阅的集合。
对于它订阅的是个集合,我们也容易理解,Kafka 可以通过正则表达式 来匹配相关主题,例如下面的这样:
consumer.subscribe(Pattern.compile("topic-.*"));但是如果 consumer 重复定义的话,就以后面的为准,下面订阅的就是 xiaolei3 这个主题。
consumer.subscribe(Arrays.asList("xiaolei2"));
consumer.subscribe(Arrays.asList("xiaolei3"));订阅完主题,我们讲讲它怎么定义分区。
直接订阅特定分区。
consumer.assign(Arrays.asList(new TopicPartition("xiaolei2",0)));这里面使用了 assing 方法来订阅特定分区。那如果不知道有哪些分区怎么办呢?
可以使用 KafkaConsumer 的 partitionsFor() 方法用来查询指定主题的元数据信息。
下面这种实现:
consumer.assign(Arrays.asList(new TopicPartition("xiaolei2",0)));
ArrayList<TopicPartition> topicPartitions = new ArrayList<>();
List<PartitionInfo> partitionInfos  最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 4466
4466











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









