










目录
1. 下载地址 点击超链接 kafka-eagle_2.0.8
一. 测试环境
| 信息 | 内容 |
| 主机版本 | centos7 |
| 机器数量 | 3台 |
| Kafka版本 | kafka_2.12-3.3.2 |
| 安装包解压路径 | /home/tools/kafka/ |
二. 配置文件<kafka_home>/config
server.properties
consumer.properties (在消费者客户端中配置,推荐java)
producer.properties (在生产者客户端中配置,推荐java)
server.properties服务配置 详细配置位置 超链接 简单配置
配置完成之后将整个包分发到剩余的两台节点,并修改server.properties中的broker.id,可以设置为1和2,不允许节点之间重复
三. kafka启动与停止
bin/kafka-server-start.sh -daemon config/server.properties
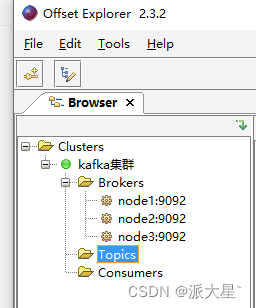
bin/kafka-server-stop.sh启动之后使用Offset Explorer可视化管理工具进行连接
注意在可视化工具的Tool->Setting->Topics里面修改 Key Value类型为String
四. kafka脚本的基本命令
| 查看topic列表 | kafka-topics.sh --bootstrap-server node1:9092,node2:9092,node3:9092 --list |
| 创建topic | kafka-topics.sh --bootstrap-server node1:9092,node2:9092,node3:9092 --create --partitions 2 --replication-factor 2 --topic topicName |
| 查看topic详情 | kafka-topics.sh --bootstrap-server node1:9092 --describe --topic topicName |
| 修改分区 (只能增加) | kafka-topics.sh --bootstrap-server node1:9092 --alter --topic topicName --partitions 3 |
| 删除topic | kafka-topics.sh --bootstrap-server node1:9092 --delete --topic topicName |
| 生产者 | kafka-console-producer.sh --bootstrap-server node1:9092 --topic topicName |
| 消费者 | kafka-console-consumer.sh --bootstrap-server node1:9092 --topic topicName (--from-beginning 从头消费 --group 指定消费组) |
| 查看 index/segment | kafka-run-class.sh kafka.tools.DumpLogSegments --print-data-log --files <kafka_home>/data/myTopicName/00000000000000000000.log kafka-run-class.sh kafka.tools.DumpLogSegments --files <kafka_home>/data/myTopicName/00000000000000000000.index |
| 查看偏移量 | kafka-console-consumer.sh --topic __consumer_offsets --bootstrap-server node1:9092 --formatter "kafka.coordinator.group.GroupMetadataManager\$OffsetsMessageFormatter" --from-beginning |
| 查看消费组积压量 | kafka-consumer-groups.sh --bootstrap-server node1:9092 --describe --group groupid |
五. kafka java Api
1. pom坐标
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>3.3.2</version>
</dependency>2. 生产者
import org.apache.kafka.clients.producer.*;
import org.apache.kafka.common.serialization.StringSerializer;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import java.util.HashMap;
import java.util.concurrent.ExecutionException;
public class KafkaUtil {
private final static Logger logger = LoggerFactory.getLogger(KafkaUtil.class);
public static void main(String[] args) throws ExecutionException, InterruptedException {
HashMap<String, Object> conf = new HashMap<>();// 1. 创建kafka生产者的配置对象
conf.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "node1:9092");// 2. 给kafka配置对象添加配置信息:bootstrap.servers
conf.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());// key,value序列化(必须):key.serializer,value.serializer
conf.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
conf.put(ProducerConfig.PARTITIONER_CLASS_CONFIG, MyPartitioner.class.getName());//传入自定义分区
KafkaProducer<String, String> kafkaProducer = new KafkaProducer<>(conf);// 3. 创建kafka生产者对象
kafkaProducer.send(new ProducerRecord<>("first", "消息"));// 4. 调用send方法,异步发送消息
// 5. 调用send方法,异步发送消息携带回调函数
kafkaProducer.send(new ProducerRecord<>("first", "消息"), (metadata, exception) -> System.out.println(String.format("发送到分区%d,对应的偏移量为%s", metadata.partition(), metadata.offset())));
kafkaProducer.send(new ProducerRecord<>("first", "消息")).get();// 6. 调用send方法,同步发送消息
kafkaProducer.close();//7. 关闭资源
logger.info("结束");
}
}3. 生产者自定义分区器
import org.apache.kafka.clients.producer.Partitioner;
import org.apache.kafka.common.Cluster;
import java.util.Map;
public class MyPartitioner implements Partitioner {
@Override
public int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster) {
System.out.println(key + ":" + value + ":" + topic);
//自定义分区
return 0;
}
@Override
public void close() {}
@Override
public void configure(Map<String, ?> configs) {}
}4. 消费者
import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import org.apache.kafka.common.serialization.StringDeserializer;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import java.time.Duration;
import java.util.Arrays;
import java.util.HashMap;
import java.util.concurrent.ExecutionException;
public class KafkaUtil {
private final static Logger logger = LoggerFactory.getLogger(KafkaUtil.class);
public static void main(String[] args) throws ExecutionException, InterruptedException {
HashMap<String, Object> conf = new HashMap<>();// 1. 创建消费者的配置对象
conf.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "node1:9092");// 2.给消费者配置对象添加参数
conf.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());//配置序列化 必须
conf.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
conf.put(ConsumerConfig.GROUP_ID_CONFIG, "test");// 配置消费者组(组名任意起名) 必须
conf.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, "earliest");// earliest/latest 配置消费格式,默认latest
//conf.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, false);// 是否自动提交offset
KafkaConsumer<String, String> kafkaConsumer = new KafkaConsumer<>(conf);// 创建消费者对象
kafkaConsumer.subscribe(Arrays.asList(new String[]{"mytopic"}));// 注册要消费的主题(可以消费多个主题)
//指定分区指定偏移量消费
//ArrayList<TopicPartition> topicPartitions = new ArrayList<>();
//TopicPartition topicPartition0 = new TopicPartition("mytopic", 0);
//TopicPartition topicPartition1 = new TopicPartition("mytopic", 1);
//TopicPartition topicPartition2 = new TopicPartition("mytopic", 2);
//topicPartitions.add(topicPartition0);
//topicPartitions.add(topicPartition1);
//topicPartitions.add(topicPartition2);
//kafkaConsumer.assign(topicPartitions);//指定分区消费
//kafkaConsumer.seek(topicPartition0, 3);//设置偏移量必须在assign方法之后
//kafkaConsumer.seek(topicPartition1, 3);
//kafkaConsumer.seek(topicPartition2, 3);
// 拉取数据打印
while (true) {
// 设置1s中消费一批数据
ConsumerRecords<String, String> consumerRecords = kafkaConsumer.poll(Duration.ofSeconds(1));
// 打印消费到的数据
for (ConsumerRecord<String, String> consumerRecord : consumerRecords) {
logger.info(String.format("主题:[%s],分区:[%s],偏移量:[%s],键:[%s],值:[%s]",
consumerRecord.topic(),
consumerRecord.partition(),
consumerRecord.offset(),
consumerRecord.key(),
consumerRecord.value()));
}
//consumer.commitAsync();//异步手动提交
//consumer.commitSync();// 同步手动提交
}
}
}六. kafka监控管理工具kafka-eagle
1. 下载地址 点击超链接 kafka-eagle_2.0.8
2. 修改配制
下载解压后修改配置文件 conf/system-config.properties
######################################
# multi zookeeper & kafka cluster list
# Settings prefixed with 'kafka.eagle.' will be deprecated, use 'efak.' instead
######################################
# 修改 cluster1为别名,固定不可修改
efak.zk.cluster.alias=cluster1
cluster1.zk.list=node1:2181,node2:2181,node3:2181/kafka
######################################
# zookeeper enable acl
######################################
cluster1.zk.acl.enable=false
cluster1.zk.acl.schema=digest
cluster1.zk.acl.username=test
cluster1.zk.acl.password=test123
######################################
# broker size online list
######################################
cluster1.efak.broker.size=20
######################################
# zk client thread limit
######################################
kafka.zk.limit.size=16
######################################
# EFAK webui port
######################################
efak.webui.port=8048
######################################
# EFAK enable distributed
######################################
efak.distributed.enable=false
efak.cluster.mode.status=master
efak.worknode.master.host=localhost
efak.worknode.port=8085
######################################
# kafka jmx acl and ssl authenticate
######################################
cluster1.efak.jmx.acl=false
cluster1.efak.jmx.user=keadmin
cluster1.efak.jmx.password=keadmin123
cluster1.efak.jmx.ssl=false
cluster1.efak.jmx.truststore.location=/data/ssl/certificates/kafka.truststore
cluster1.efak.jmx.truststore.password=ke123456
######################################
# kafka offset storage
######################################
# 修改配置offset保存在kafka
cluster1.efak.offset.storage=kafka
######################################
# kafka jmx uri
######################################
cluster1.efak.jmx.uri=service:jmx:rmi:///jndi/rmi://%s/jmxrmi
######################################
# kafka metrics, 15 days by default
######################################
efak.metrics.charts=true
efak.metrics.retain=15
######################################
# kafka sql topic records max
######################################
efak.sql.topic.records.max=5000
efak.sql.topic.preview.records.max=10
######################################
# delete kafka topic token
######################################
efak.topic.token=keadmin
######################################
# kafka sasl authenticate
######################################
cluster1.efak.sasl.enable=false
cluster1.efak.sasl.protocol=SASL_PLAINTEXT
cluster1.efak.sasl.mechanism=SCRAM-SHA-256
cluster1.efak.sasl.jaas.config=org.apache.kafka.common.security.scram.ScramLoginModule required username="kafka" password="kafka-eagle";
cluster1.efak.sasl.client.id=
cluster1.efak.blacklist.topics=
cluster1.efak.sasl.cgroup.enable=false
cluster1.efak.sasl.cgroup.topics=
cluster2.efak.sasl.enable=false
cluster2.efak.sasl.protocol=SASL_PLAINTEXT
cluster2.efak.sasl.mechanism=PLAIN
cluster2.efak.sasl.jaas.config=org.apache.kafka.common.security.plain.PlainLoginModule required username="kafka" password="kafka-eagle";
cluster2.efak.sasl.client.id=
cluster2.efak.blacklist.topics=
cluster2.efak.sasl.cgroup.enable=false
cluster2.efak.sasl.cgroup.topics=
######################################
# kafka ssl authenticate
######################################
cluster3.efak.ssl.enable=false
cluster3.efak.ssl.protocol=SSL
cluster3.efak.ssl.truststore.location=
cluster3.efak.ssl.truststore.password=
cluster3.efak.ssl.keystore.location=
cluster3.efak.ssl.keystore.password=
cluster3.efak.ssl.key.password=
cluster3.efak.ssl.endpoint.identification.algorithm=https
cluster3.efak.blacklist.topics=
cluster3.efak.ssl.cgroup.enable=false
cluster3.efak.ssl.cgroup.topics=
######################################
# kafka sqlite jdbc driver address
######################################
#efak.driver=org.sqlite.JDBC
#efak.url=jdbc:sqlite:/hadoop/kafka-eagle/db/ke.db
#efak.username=root
#efak.password=www.kafka-eagle.org
######################################
# kafka mysql jdbc driver address
######################################
# 修改数据库连接,空数据库
efak.driver=com.mysql.jdbc.Driver
efak.url=jdbc:mysql://node1:3306/ke?useUnicode=true&characterEncoding=UTF-8&zeroDateTimeBehavior=convertToNull
efak.username=root
efak.password=123456
3. 配制环境
1)配置kafka-eagle/bin下的环境变量
2)修改kafka启动脚本kafka-server-start.sh,这个配置文件需要分发,监控9999端口获取cpu内存
if [ "x$KAFKA_HEAP_OPTS" = "x" ]; then
export KAFKA_HEAP_OPTS="-Xmx1G -Xms1G"
fi
# =========↑↑修改为↓↓===========
if [ "x$KAFKA_HEAP_OPTS" = "x" ]; then
export KAFKA_HEAP_OPTS="-server -Xms2G -Xmx2G -XX:PermSize=128m -XX:+UseG1GC -XX:MaxGCPauseMillis=200 -XX:ParallelGCThreads=8 -XX:ConcGCThreads=5 -XX:InitiatingHeapOccupancyPercent=70"
export JMX_PORT="9999"
#export KAFKA_HEAP_OPTS="-Xmx1G -Xms1G"
fi
4. 启动停止
ke.sh start/stop 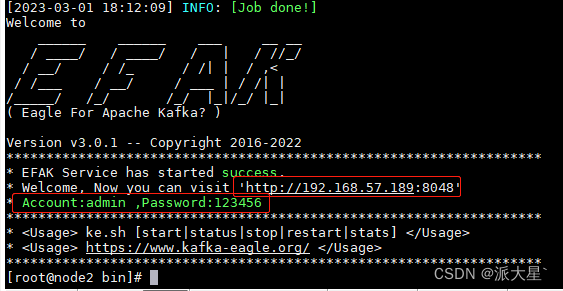
5. 访问监控页面
| 默认用户名/密码 | admin/123456 |
| web访问地址 | http://192.168.57.189:8048 |
七. Kafka-Kraft集群部署
1. 修改核心配制文件
Kraft不需要依赖zookeeper,修改配置文件
<kafka_home>/config/kraft/server.properties
####################核心配置#####################
#不重复的别名
node.id=1
#broker对外暴露的地址
advertised.listeners=PLAINTEXT://node1:9092
#全Controller列表
controller.quorum.voters=1@node1:9093,2@node2:9093,3@node3:9093
#kafka数据存储目录
log.dirs=/home/tools/kafka/kraft/data
#kafka的角色
process.roles=broker,controller
####################核心配置#####################
#controller服务协议别名
controller.listener.names=CONTROLLER
#不同服务器绑定的端口
listeners=PLAINTEXT://:9092,CONTROLLER://:9093
#broker服务协议别名
inter.broker.listener.name=PLAINTEXT
#协议别名到安全协议的映射
listener.security.protocol.map=CONTROLLER:PLAINTEXT,PLAINTEXT:PLAINTEXT,SSL:SSL,SASL_PLAINTEXT:SASL_PLAINTEXT,SASL_SSL:SASL_SSL
num.network.threads=3
num.io.threads=8
socket.send.buffer.bytes=102400
socket.receive.buffer.bytes=102400
socket.request.max.bytes=104857600
num.partitions=1
num.recovery.threads.per.data.dir=1
offsets.topic.replication.factor=1
transaction.state.log.replication.factor=1
transaction.state.log.min.isr=1
#log.flush.interval.messages=10000
#log.flush.interval.ms=1000
log.retention.hours=168
#log.retention.bytes=1073741824
log.segment.bytes=1073741824
log.retention.check.interval.ms=3000002. 分发配制修改过安装包
scp -r kraft/ node2:$PWD
scp -r kraft/ node3:$PWD3. 修改其他节点的核心配制
node.id (配置数值需要与controller.quorum.voters中对应的@前面的数字配置对应)
advertised.Listeners (需要根据各自的主机名称,修改相应的地址)
4. 生成目录唯一id
修改配置完成之后先要在任意节点生成存储目录唯一ID
(也可以直接使用J7s9e8PPTKOO47PxzI39VAzhege这个ID)
kafka-storage.sh random-uuid
J7s9e8PPTKOO47PxzI39VA (初始化得到的唯一ID)
5. 根据ID格式化kafka的存储目录
在每三台节点上的kafka根目录用该ID格式化kafka的存储目录(三个节点使用相同id)
<kafka_home>bin/kafka-storage.sh format -t J7s9e8PPTKOO47PxzI39VA -c /home/tools/kafka/kraft/config/kraft/server.properties
6. 启动/停止kafka集群
kafka-server-start.sh -daemon config/kraft/server.properties
kafka-server-stop.sh

















 4万+
4万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











