







Kafka 一个特点就是吞吐量大,而且是大数据场景的首选消息队列。根据真实生产环境数据,Kafka 单机能达到同时生产和消费百万级量级的数据量。
这到底是怎样的一个概念呢?我们结合生产环境中对生产端发送消息的某个测试来说明下。
- 生产环境配置:8 核 CPU,32G 内存,3 台机器分别安装 3 个 Broker,内网带宽很高,网络带宽瓶颈忽略不计。
- 测试方法:每个消息大小设计为 100B,然后分别测试 1、2、3 生产者生产消息,同时 1、2、3 消费者消费消息,最后得出生产和消费成功的消息数和消息字节数。
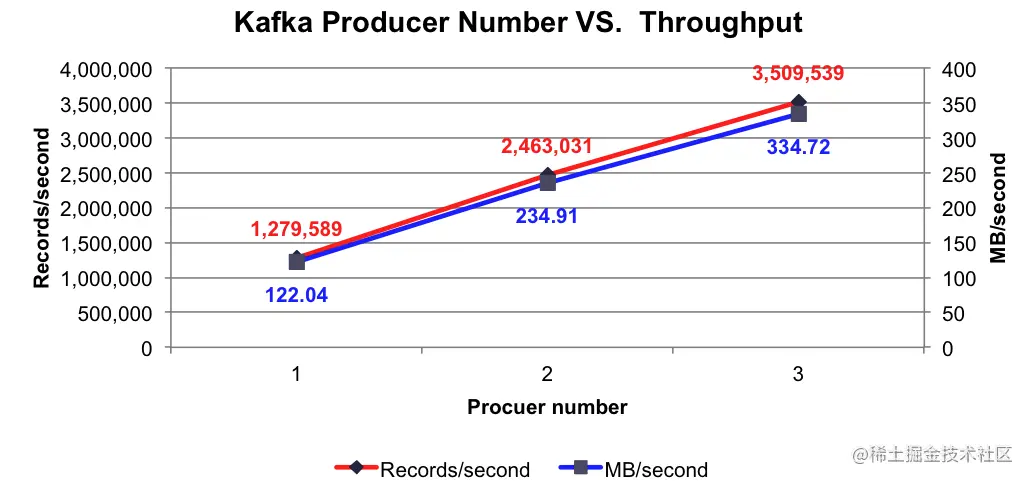
生产者发送消息的吞吐量
当 3 个 Producer 往 3 个 Broker 发送消息的时候,生产者每秒平均向每台 Broker 生产 100 万条消息。
下面是测试结果:
消费者消费消息的吞吐量
下面是测试结果:
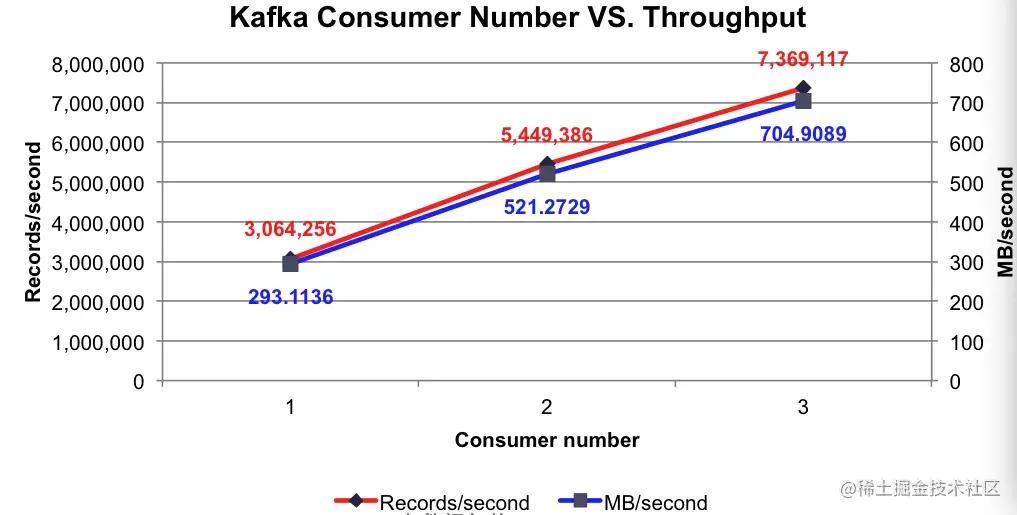
当 3 个 Consumer 向 3 个 Broker 拉取消息的时候,消费者每秒平均向每台 Broker 拉取 200 万条以上的消息。这个效果是不是很赞?
那么,Kafka 到底是如何做到这么高的吞吐量的呢?
Kafka 高吞吐架构特点
Kafka 采用了一系列的技术优化来保证高吞吐,这其中包括批量处理、压缩、零拷贝、磁盘顺序读写、页面缓存技术、Reactor 网络架构设计模式等。
- 采用到的技术有很多,这里我讲解的方式会跟前面课程讨论 Kafka 消息可靠性一样,主要从生产端、服务端和消费端三个方面来剖析和讨论。
- 除了讨论 Kafka 设计原理的内容以外,我还会介绍相关的参数配置和对应的源码,必要时也会分
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 67
67











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









