










利用对比学习进行状态动作表征,基于表征筛选出合适的样本实现cross-domain
paper
code
ICML 2024
Intro
Source Domain 的数据与Target Domian可能存在dynamic mismatch使得基于offline RL的域自适应困难。基于域分类的方法往往需要域之间可转移的假设。本文提出一种基于对比学习的表征方式估算域之间的gap,并将表征结果看作一种数据筛选,选出合适的数据用于offline RL的策略学习。文中也证明这种表征方式可以恢复两个领域中dynamic 函数的互信息差距, 并且这种基于域间互信息。
Method
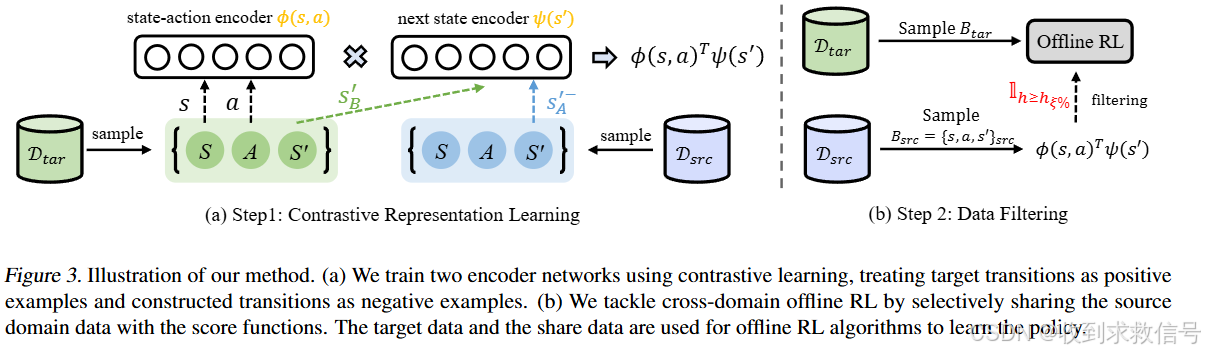
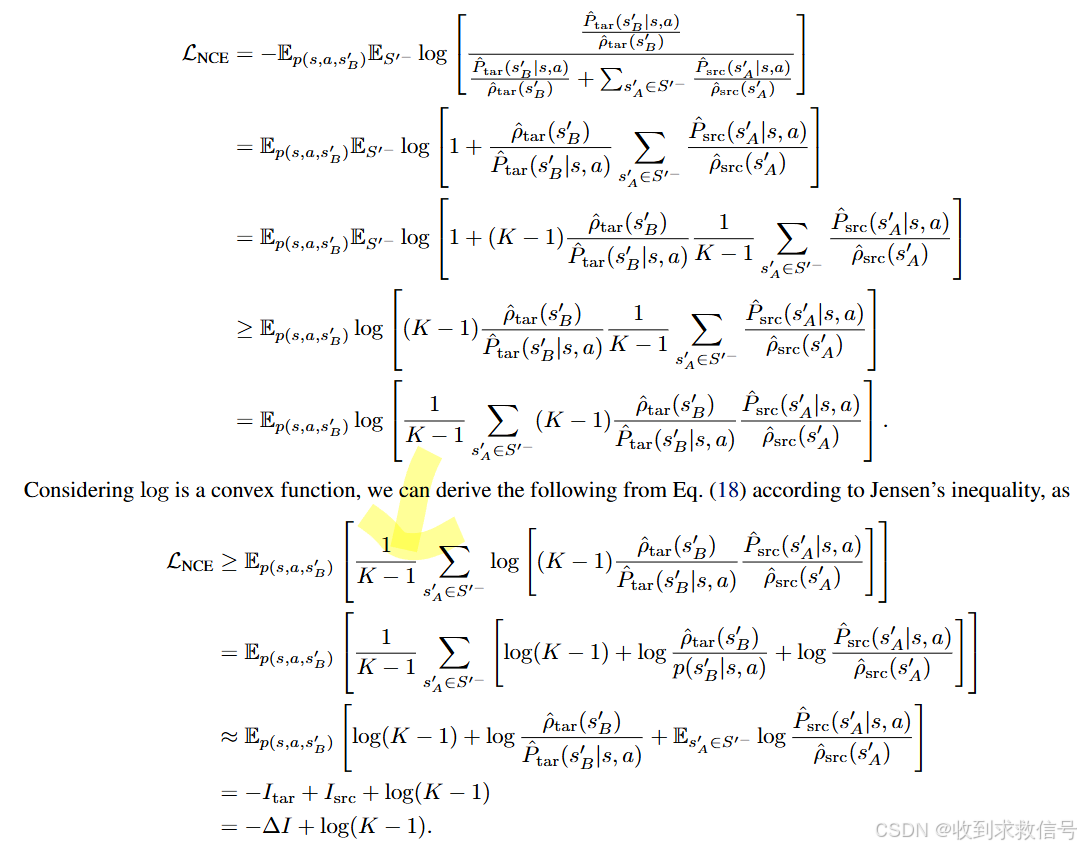
对比学习部分采用NCELoss。正样本对
(
s
,
a
,
s
B
′
(s,a,s'_{B}
(s,a,sB′来自target,负样本对则是由target采样的
(
s
,
a
)
(s,a)
(s,a)与source中采样的
S
A
′
S'_A
SA′构成。

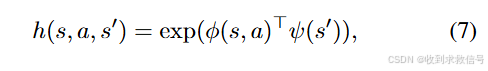
训练完成后便是基于
ϕ
\phi
ϕ与
ψ
\psi
ψ对source domain 的数据进行筛选,联合target的数据实现价值函数的学习
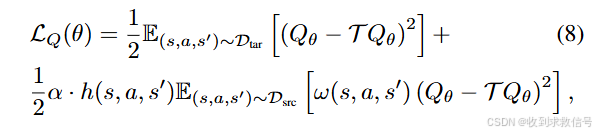
其中
ω
\omega
ω为指示函数,当
h
h
h大于某个阈值时为1。价值函数再结合offline RL的方法实现策略学习(IQL)
一点理论
利用源域与目标域之间的互信息
I
(
[
S
,
A
]
,
S
′
)
I([S,A],S')
I([S,A],S′)的gap,推导出其与对比学习NCE之间的关系
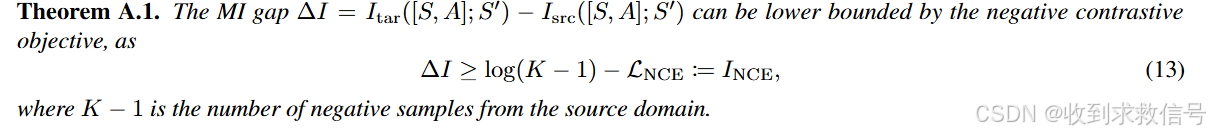
当有足够的负样本,这种Gap等价于
I
N
C
E
I_{NCE}
INCE,那利用对比学习中的表征函数筛选出的样本,也就具有很好信任度。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









