







常用的优化方式
- 服务器硬件优化
- 服务器优化
- SQL本身优化
- 反范式设计优化
- 物理设计优化(字段类型,长度设计,存储引擎选择)
- 索引优化
1.服务器硬件优化
机械硬盘升级固态硬盘,效率提升可达10倍
2.服务器优化
MySQL部署在windows上很不稳定,没有Linux上稳定
3.SQL本身优化
3.1 子查询效率没有外联查询快
慢:
SELECT
快: ;
a.acode,
a.aname,
( SELECT b.bname FROM tabB WHERE a.acode = b.bcode )
FROM
tabA a
SELECT
a.acode,
a.aname,
b.bname
FROM tabA a, tabB b
WHERE a.acode = b.bcode
4.反范式设计
三大范式:
第一范式:数据库表的每一列都是不可分割的原子数据项。

第二范式:
 第三范式:
第三范式:

三大范式的作用:
对新增、删除、修改友好,解决了数据冗余的问题,但是对查询不友好,当需要查询额外信息时,要做额外查询动作。为解决这个问题可以在数据库设计时, 适当违反下范式,增加下冗余,用空间换时间。
反范式设计:在A表中冗余记录B表中的某个字段
5.物理设计优化
字段类型:
5.1 优先考虑数字类型
5.2 期次是日期、时间类型
5.3 最后是字符类型
5.4 对于相同级别的数据类型,应该优先选择占用空间小的数据类型
6.索引优化
索引:帮助高效获取数据的排好序的数据结构
使用的是B+树的结构,MySQL只显示支持B-Tree(BTree,不是B减tree,没有B减tree)
索引分类:

聚簇索引和非聚簇索引的区别:
SHOW VARIABLES LIKE '%datadir%'; #查看mysql数据库的数据库(数据存储的目录 )
该目录下的文件夹与mysql的db一一对应

innodb 和 myisam的区别:
| innodb(聚簇) | myisam(非聚簇) |
| xxx.frm(表格式文件) | xxx.frm表格式文件) |
| xxx.ibd(index bind data ) | xxx.MYD(data) |
| xxx.MYI(index) |
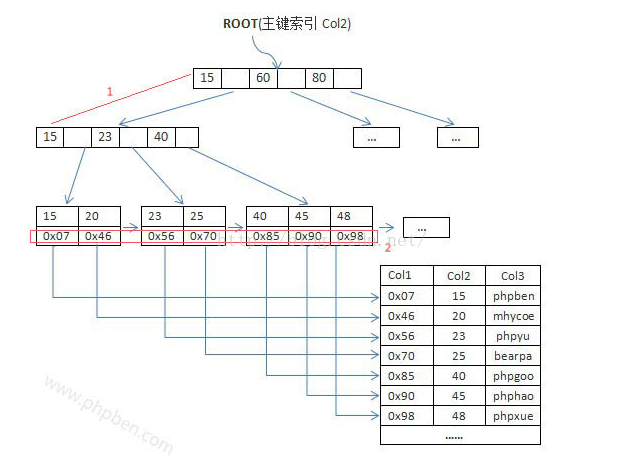
MyISAM引擎索引结构的叶子节点的数据域,存放的并不是实际的数据记录,而是数据记录的地址。索引文件与数据文件分离,这样的索引称为“非聚簇索引”。MyISAM的主索引与辅助索引区别并不大,只是主键索引不能有重复的关键字。
如下图所示为非聚簇索引的主键索引:
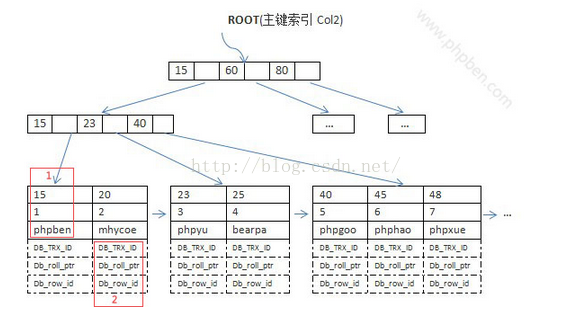
InnoDB引擎索引结构的叶子节点的数据域,存放的就是实际的数据记录(对于主索引,此处会存放表中所有的数据记录;对于辅助索引此处会引用主键,检索的时候通过主键到主键索引中找到对应数据行),或者说,InnoDB的数据文件本身就是主键索引文件,这样的索引被称为“聚簇索引”,一个表只能有一个聚簇索引。
如下图所示为聚簇索引的主键索引:
索引创建后是否用到了索引:
explain 的结果中是否有key,key有值就代表走了索引
索引创建后是否充分用到了索引:
看explain 的结果中的key_len:可以计算出用了索引的哪些字段
key_len:键的长度,计算方法:
1.数据类型:varchar +2, char +0
2.是否为空:允许为空+1,不允许为空+0
3.字段本身的长度(varchar和char是字符,其他的是字节,一个字符占3个字节)
4.字符集:UTF-8占3个字节
索引优化:
1. 尽量全值匹配
当建立索引后,能再where条件中使用索引列,就尽量使用。可以提高key_len
2. 最佳左前缀法则
如果是复合索引,就要遵守最左前缀法则,意思是:查询从最左前列开始,并且不跳过索引中的列
3. 不在索引列上做任何操作
不在索引列上(计算,函数,自动或者手动的进行类型转换),会导致索引失效。
4. 范围条件放最后(是指索引定义顺序的最后)
CREATE TABLE `tabA` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`code` varchar(20) DEFAULT NULL,
`name` varchar(50) DEFAULT NULL,
`type` int(1) DEFAULT NULL,
`status` int(1) DEFAULT NULL,
PRIMARY KEY (`id`) USING BTREE,
KEY `idx_query` (`code`,`name`,`type`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4EXPLAIN
select * from tabA where code ='1' and name ='1' and type=1 (key_len =291,走了全部字段)中间有范围查询会导致后面的索引列全部失效:
EXPLAIN
select * from tabA where code >'1' and name ='1' and type=1(key_len=83,只走了code,name和type没走)EXPLAIN
select * from tabA where code ='1' and name >'1' and type=1 (key_len=286,只走了code和name,type没走)EXPLAIN
select * from tabA where code ='1' and name ='1' and type>1 (key_len =291,走了全部字段)
对于in条件查询,如果索引没有生效,使用in不会有影响;如果索引有效,使用in则会进行全表扫描
EXPLAIN
select * from tabA where code ='1' and name ='1' and type in (1,2) (全表扫描)EXPLAIN
select * from tabA where code ='1' and type in (1,2) (key_len=83,只走了code,name和type没走)
5. 尽量使用覆盖索引
覆盖索引(只访问索引的查询(索引列和查询列一致)),而尽量避免 select *
EXPLAIN
select code,name,type from tabA where name ='1' and type=1 (key_len =291,虽然不是最左原则,但也走了所以,走了全部字段)EXPLAIN
select code,name,type from tabA where type=1 (key_len =291,虽然不是最左原则,但也走了所以,走了全部字段)
6. 不等于要慎用
在使用不等于(!= 或者<>),会导致索引失效
EXPLAIN
select * from tabA where code !='1' (全表扫描)
如果定要需要使用不等于,请用覆盖索引
EXPLAIN
select name from tabA where code !='1'(key_len =291,走索引)
EXPLAIN
select code from tabA where code !='1'(key_len =291,走索引)EXPLAIN
select code from tabA where name !='1'(key_len =291,走索引)
7. NULL和Not NULL要慎用
在字段为NOT NULL的情况下,如果使用 is null 或者 is not null,会导致索引失效。解决方案(覆盖索引)
alter table tabA modify `code` varchar(20) not null;
EXPLAIN
select * from tabA where code is not null (索引失效)
EXPLAIN
select code,name,type from tabA where code is not null(ken_len=290,字段不允许为空+0,可以使用索引)
|-- 在字段为可以为NULL的情况下,使用IS NULL,索引正常;使用 IS NOT NULL,则索引失效。(解决方案同上,覆盖索引)
8. LIKE查询要当心
like时以通配符开头('%xxx...')索引失效会变成全表扫描。
EXPLAIN
select * from tabA where code like '%1%' (索引失效,一定要用的话,用覆盖索引)
EXPLAIN
select * from tabA where code like '1%'(key_len=290,走覆盖索引)
EXPLAIN
select * from tabA where code like '1%' (可以使用索引,类似遵循最左前缀原则)
9. 字符类型加引号,避免隐式转换
EXPLAIN
select * from tabA where code =1 (索引失效)
10. OR改UNION效率高
EXPLAIN
select * from tabA where code ='1' or name ='1'(索引失效,解决方案UNION或者覆盖索引)如果索引是(code,name,type)的联合索引,union也不是很好,name='1'的查询还是全表
除非是code 和name都能单独走索引,才比较好,,所以还是走覆盖索引比较靠谱:
CREATE TABLE `tabB` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`code` varchar(20) NOT NULL,
`name` varchar(50) DEFAULT NULL,
`type` int(1) DEFAULT NULL,
`status` int(1) DEFAULT NULL,
PRIMARY KEY (`id`) USING BTREE,
KEY `idx_query` (`code`,`type`),
KEY `idx_name` (`name`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4EXPLAIN
select * from tabB where code ='1'
union
select * from tabB where name ='1'


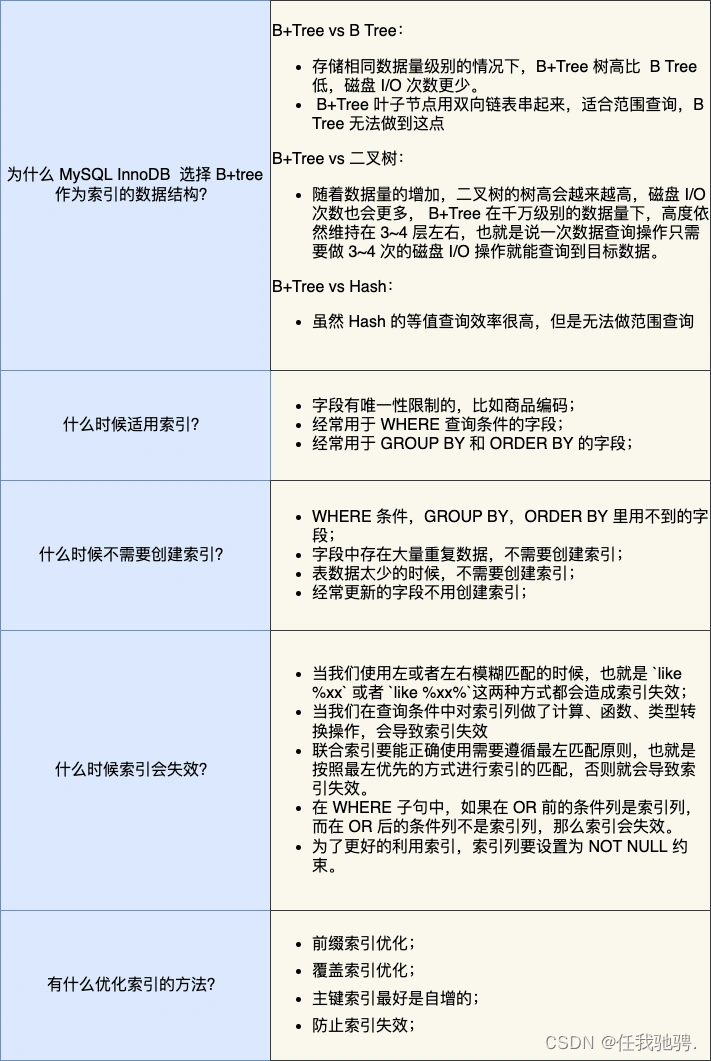
小结:














 1210
1210











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









