







本文将从以下几个方面讲解Scrapy爬虫的基本操作
- Scrapy爬虫介绍
- Scrapy安装
- Scrapy实例——爬取1905电影网
- 相关资料
Scrapy 爬虫介绍
Scrapy是Python开发的一个快速,高层次的屏幕抓取和web抓取框架,用于抓取web站点并从页面中提取结构化的数据。Scrapy用途广泛,可以用于数据挖掘、监测和自动化测试。
Scrapy吸引人的地方在于它是一个框架,任何人都可以根据需求方便的修改。它也提供了多种类型爬虫的基类,如BaseSpider、sitemap爬虫等,最新版本又提供了web2.0爬虫的支持。
Scrapy 使用 Twisted这个异步网络库来处理网络通讯,架构清晰,并且包含了各种中间件接口,可以灵活的完成各种需求。整体架构如下图所示:
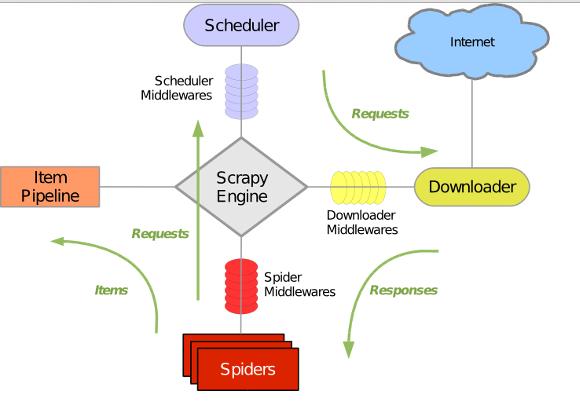
从上图中可以看到,Scrapy已经帮我们处理好了Downloader以及Scheduler。作为轻量级用户,我们完全不用关心爬虫是如何调度及下载的,只需要关注爬虫的爬去规则(Spiders)以及如何存储(Item Pipeline)。
Scrapy的安装
网上有许多关于Scrapy安装的博客,大家自行搜索,我是采用pip的安装方式
pip install scrapy
如果使用pip安装时遇到 KeyError: u’\u6e29’ 的问题,可以参考我的博客
python2.7 pip install 报错KeyError: u’\u6e29’解决方案
Scrapy 实例
爬虫任务介绍
这次要爬去1905电影网的所有中国电影,共14499部电影
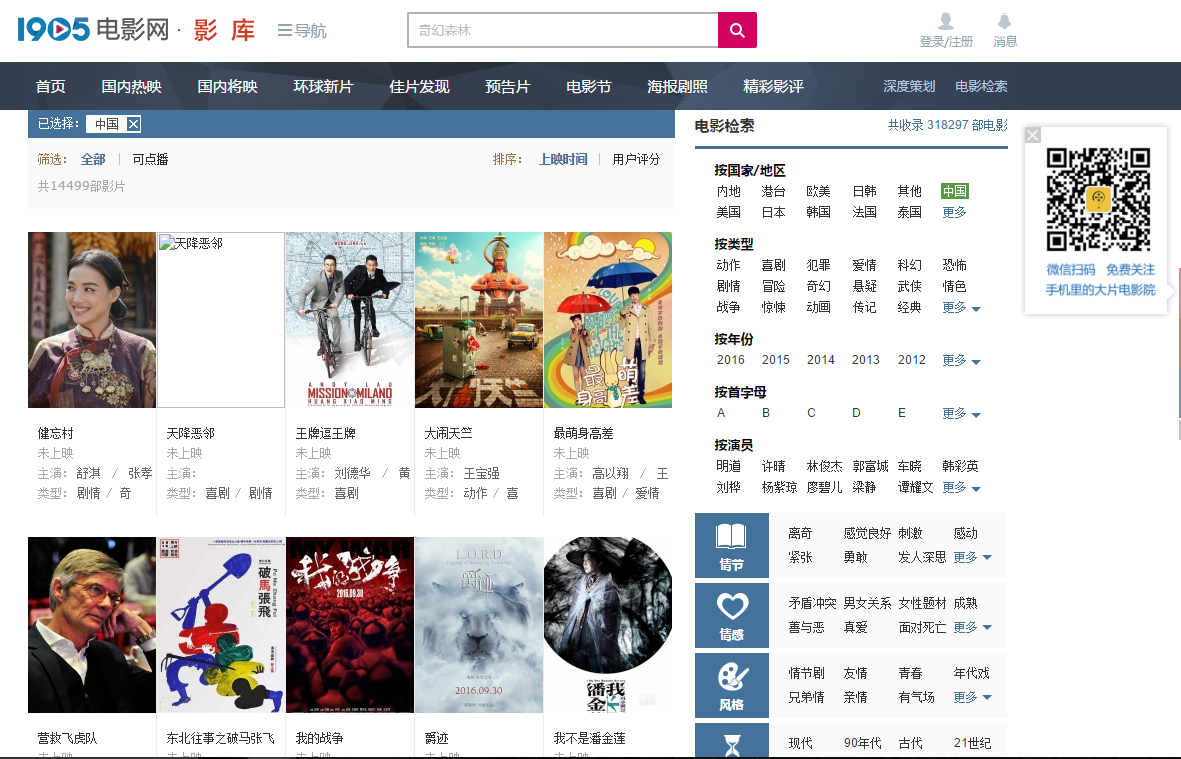
下图为目录页,每个目录页有30个电影,共有486个目录页
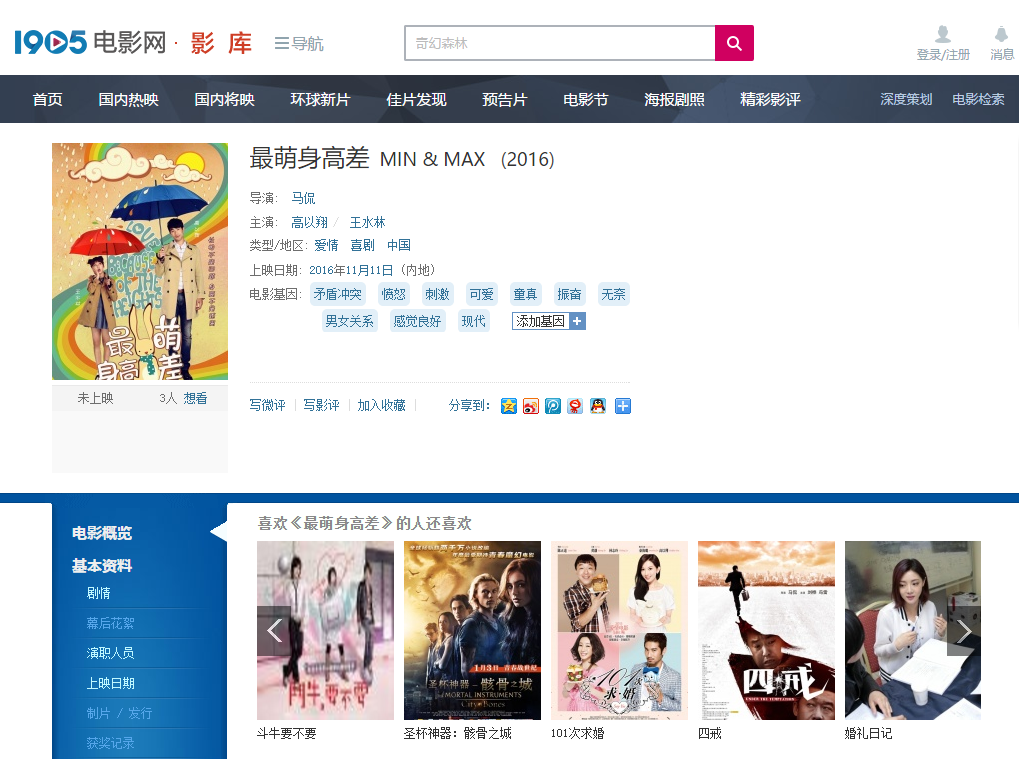
下图为需要保存的电影页面,我们将其保存到本地,以后再解析
我们观察到目录页url是有规律的,
第一页 http://www.1905.com/mdb/film/list/country-China/o0d0p0.html
第二页 http://www.1905.com/mdb/film/list/country-China/o0d0p1.html
最后页 http://www.1905.com/mdb/film/list/country-China/o0d0p484.html <
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 4420
4420

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









