







大家好,我是带我去滑雪!
对中国电影票房排行数据的爬取和分析可视化具有多方面的用处:例如了解电影市场的历史趋势,包括不同类型电影的受欢迎程度、票房的季节性波动。识别观众对于不同类型电影的偏好,为电影制片方提供指导,以选择更有市场潜力的题材和类型。本期使用python爬取中国电影票房排行数据,并进行数据分析。
目录
一、爬取中国电影票房排行数据
(1) 传入网页和请求头
import requests; import pandas as pd
from flask import request
from bs4 import BeautifulSoup
url = 'https://piaofang.maoyan.com/rankings/year'
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/116.0.0.0 Safari/537.36 Edg/116.0.1938.62'}
response= requests1.get(url,headers=headers)
response.status_code(2)解析网页和获取信息
soup = BeautifulSoup(response.text, 'html.parser')
soup=soup.find('div', id='ranks-list')
movie_list = []
for ul_tag in soup.find_all('ul', class_='row'):
movie_info = {}
li_tags = ul_tag.find_all('li')
movie_info['序号'] = li_tags[0].text
movie_info['标题'] = li_tags[1].find('p', class_='first-line').text
movie_info['上映日期'] = li_tags[1].find('p', class_='second-line').text
movie_info['票房(亿)'] = f'{(float(li_tags[2].text)/10000):.2f}'
movie_info['平均票价'] = li_tags[3].text
movie_info['平均人次'] = li_tags[4].text
movie_list.append(movie_info1)
movie_list
movies=pd.DataFrame(movie_list)
movies.head(10)(3)部分数据爬取结果展示
| 序号 | 标题 | 上映日期 | 票房(亿) | 平均票价 | ||
| 0 | 1 | 长津湖 | 2021-09-30 上映 | 57.75 | 46.383896 | 22 |
| 1 | 2 | 战狼2 | 2017-07-27 上映 | 56.95 | 35.594273 | 37 |
| 2 | 3 | 你好,李焕英 | 2021-02-12 上映 | 54.13 | 44.756565 | 24 |
| 3 | 4 | 哪吒之魔童降世 | 2019-07-26 上映 | 50.36 | 35.692467 | 23 |
| 4 | 5 | 流浪地球 | 2019-02-05 上映 | 46.87 | 44.59698 | 29 |
| 5 | 6 | 满江红 | 2023-01-22 上映 | 45.44 | 49.512146 | 24 |
| 6 | 7 | 唐人街探案3 | 2021-02-12 上映 | 45.24 | 47.60257 | 29 |
| 7 | 8 | 复仇者联盟4:终局之战 | 2019-04-24 上映 | 42.50 | 48.958096 | 23 |
| 8 | 9 | 长津湖之水门桥 | 2022-02-01 上映 | 40.67 | 49.286682 | 19 |
| 9 | 10 | 流浪地球2 | 2023-01-22 上映 | 40.29 | 50.792316 | 21 |
(4)数据清洗
数据清洗(Data Cleaning)是数据分析过程中至关重要的一步,其目的是确保数据的准确性、完整性和一致性。为了方便后续的数据分析,对爬取的数据进行清洗。
movies=movies.set_index('序号').loc[:'250',:]
movies['上映日期']=pd.to_datetime(movies['上映日期'].str.replace('上映',''))
movies[['票房(亿)','平均票价','平均人次']]=movies.loc[:,['票房(亿)','平均票价','平均人次']].astype(float)
movies['年份']=movies['上映日期'].dt.year ; movies['月份']=movies['上映日期'].dt.month
movies.head(5)清洗后数据部分展示:
| 序号 | 标题 | 上映日期 | 票房(亿) | 平均票价 | 平均人次 | 年份 | 月份 |
|---|---|---|---|---|---|---|---|
| 1 | 长津湖 | 2021-09-30 | 57.75 | 46.383896 | 22.0 | 2021 | 9 |
| 2 | 战狼2 | 2017-07-27 | 56.95 | 35.594273 | 37.0 | 2017 | 7 |
| 3 | 你好,李焕英 | 2021-02-12 | 54.13 | 44.756565 | 24.0 | 2021 | 2 |
| 4 | 哪吒之魔童降世 | 2019-07-26 | 50.36 | 35.692467 | 23.0 | 2019 | 7 |
| 5 | 流浪地球 | 2019-02-05 | 46.87 | 44.596980 | 29.0 | 2019 |
二、数据分析
(1)绘制排行榜前10的柱状图
import seaborn as sns
import matplotlib.pyplot as plt
plt.rcParams ['font.sans-serif'] ='SimHei' #显示中文
plt.rcParams ['axes.unicode_minus']=False
top_movies = movies.nlargest(10, '票房(亿)')
plt.figure(figsize=(7, 4),dpi=128)
ax = sns.barplot(x='票房(亿)', y='标题', data=top_movies, orient='h',alpha=0.5)
for p in ax.patches:
ax.annotate(f'{p.get_width():.2f}', (p.get_width(), p.get_y() + p.get_height() / 2.),
va='center', fontsize=8, color='gray', xytext=(5, 0),
textcoords='offset points')
plt.title('票房前10的电影')
plt.xlabel('票房数量(亿)')
plt.ylabel('电影名称')
plt.tight_layout()
plt.savefig("squares.png",
bbox_inches ="tight",
pad_inches = 1,
transparent = True,
facecolor ="w",
edgecolor ='w',
dpi=300,
orientation ='landscape')输出结果:

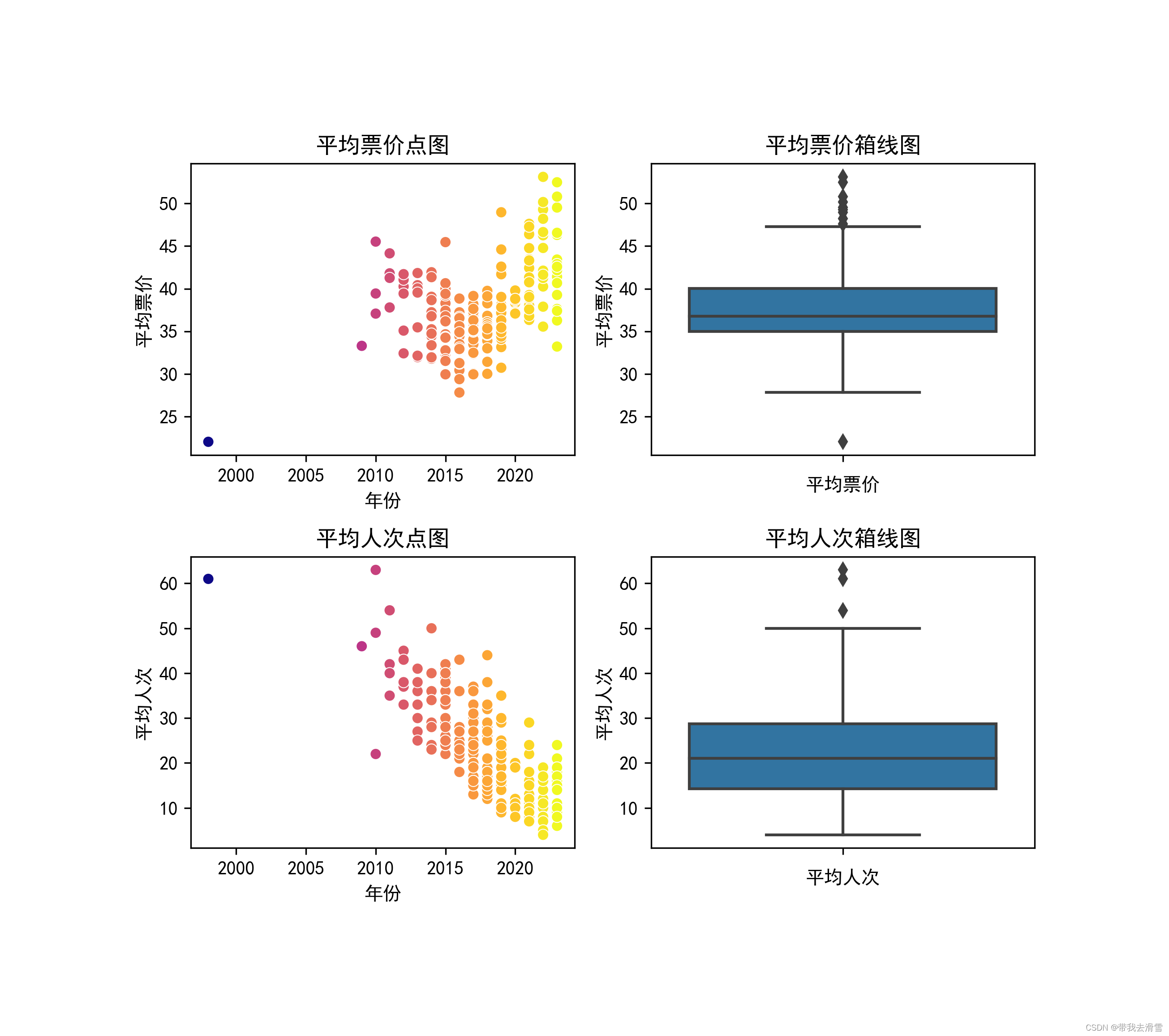
(2) 对平均票价和平均人次进行分析
plt.figure(figsize=(7, 6),dpi=128)
plt.subplot(2, 2, 1)
sns.scatterplot(y='平均票价', x='年份', data=movies,c=movies['年份'],cmap='plasma')
plt.title('平均票价点图')
plt.ylabel('平均票价')
#plt.xticks([])
plt.subplot(2, 2, 2)
sns.boxplot(y='平均票价', data=movies)
plt.title('平均票价箱线图')
plt.xlabel('平均票价')
plt.subplot(2, 2, 3)
sns.scatterplot(y='平均人次', x='年份', data=movies,c=movies['年份'],cmap='plasma')
plt.title('平均人次点图')
plt.ylabel('平均人次')
plt.subplot(2, 2, 4)
sns.boxplot(y='平均人次', data=movies)
plt.title('平均人次箱线图')
plt.xlabel('平均人次')
plt.tight_layout()
plt.savefig("squares1.png",
bbox_inches ="tight",
pad_inches = 1,
transparent = True,
facecolor ="w",
edgecolor ='w',
dpi=300,
orientation ='landscape')输出结果:
(3) 绘制词云图
import numpy as np
def randomcolor():
colorArr = ['1','2','3','4','5','6','7','8','9','A','B','C','D','E','F']
color ="#"+''.join([np.random.choice(colorArr) for i in range(6)])
return color
[randomcolor() for i in range(3)]
from wordcloud import WordCloud
from matplotlib import colors
from imageio.v2 import imread
mask = imread('底板.png')
word_freq = dict(zip(movies['标题'], movies['票房(亿)']))
color_list=[randomcolor() for i in range(20)]
wordcloud = WordCloud(width=500, height=500, background_color='white',font_path='simhei.ttf',
max_words=250, max_font_size=250,random_state=42,mask = mask,
colormap=colors.ListedColormap(color_list)).generate_from_frequencies(word_freq)
plt.figure(figsize=(10, 5),dpi=300)
plt.imshow(wordcloud, interpolation='bilinear')
plt.axis('off')
plt.savefig("squares1.png",
bbox_inches ="tight",
pad_inches = 1,
transparent = True,
facecolor ="w",
edgecolor ='w',
dpi=300,
orientation ='landscape')输出结果:

更多优质内容持续发布中,请移步主页查看。
若有问题可邮箱联系:1736732074@qq.com
博主的WeChat:TCB1736732074
点赞+关注,下次不迷路!



















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











