







内存管理
1.介绍
内存管理,是指软件运行时对计算机内存资源的分配和使用的技术。其最主要的目的是如何高效,快速的分配,并且在适当的时候释放和回收内存资源。内存管理的实现方法有很多种,他们其实最终都是要实现 2 个函数:malloc 和 free;malloc 函数用于内存申请,free 函数用于内存释放。
2.分块式内存管理
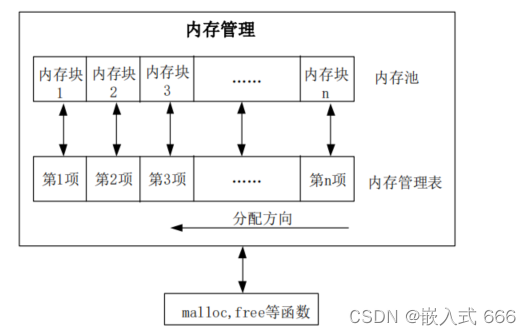
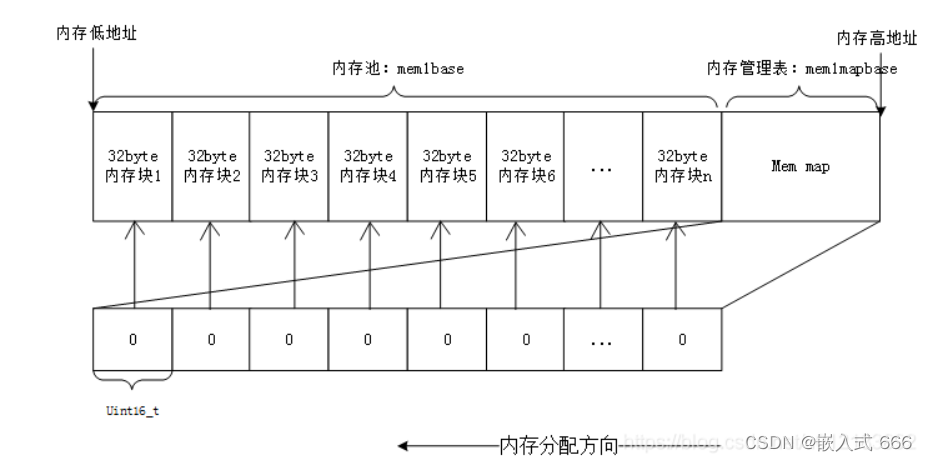
分块式内存管理由内存池和内存管理表两部分组成。内存池被等分为 n块,对应的内存管理表,大小也为 n,内存管理表的每一个项对应内存池的一块内存。
内存管理表的项值代表的意义为:当该项值为 0 的时候,代表对应的内存块未被占用,当该项值非零的时候,代表该项对应的内存块已经被占用,其数值则代表被连续占用的内存块数。比如某项值为 10,那么说明包括本项对应的内存块在内,总共分配了 10 个内存块给外部的某个指针。
内寸分配方向如图所示,是从顶→底的分配方向。即首先从最末端开始找空内存。当内存管理刚初始化的时候,内存表全部清零,表示没有任何内存块被占用。
分配原理
当指针 p 调用 malloc 申请内存的时候,先判断 p 要分配的内存块数(m),然后从第 n 项开始,向下查找,直到找到 m 块连续的空内存块(即对应内存管理表项为 0),然后将这 m 个内存管理表项的值都设置为 m(标记被占用),最后,把最后的这个空内存块的地址返回指针 p,完成一次分配。注意,如果当内存不够的时候(找到最后也没找到连续的 m 块空闲内存),则返回 NULL 给 p,表示分配失败。
释放原理
当 p 申请的内存用完,需要释放的时候,调用 free 函数实现。free 函数先判断 p 指向的内存地址所对应的内存块,然后找到对应的内存管理表项目,得到 p 所占用的内存块数目 m(内存管理表项目的值就是所分配内存块的数目),将这 m 个内存管理表项目的值都清零,标记释放,完成一次内存释放。
3.自然对齐
对齐跟数据在内存中的位置有关。如果一个变量的内存地址正好位于它长度的整数倍,他就被称做自然对齐。比如在32位cpu下,假设一个整型变量的地址为0x00000004,那它就是自然对齐的。
4.堆区和栈区的区别
1、栈是限定仅仅在表尾进行插入和删除操作的线性表,把允许插入和删除的一端称之为栈顶,另外一端称之为栈底。特点:后进先出,称之为后进先出线性表。堆是向上延伸,而栈是向下延伸。
2、是一种经过排序的树形数据结构,每一个节点都有一个值,通常所说堆的数据结构是二叉树,堆的存取是随意的。所以堆在数据结构中通常可以被看做是一棵树的数组对象。
3.栈区内存由系统自动分配,函数结束时释放;堆区内存由程序员自己申请,并指明大小。
4.栈区是一块连续的内存的区域,速度较快,效率较高。堆区是是不连续的内存区域,动态分配空间,存储空间大一些。
5.堆区存储的全部是对象,每个对象都包含一个与之对应的class的信息。栈区存放的是局部变量,基础数据类型的值以及基础数据的引用。
6.指针本身存在调用栈中,而指针指的数据在堆中。
5.C语言的内存模型分为5个区:栈区、堆区、静态区、常量区、代码区
在C/C++程序中,编译的程序占用内存分为5个区,分别为栈区、堆区、全局/静态存储区、常量存储区、代码区。
1、栈(stack)
栈又称堆栈,是用户存放程序临时创建的局部变量,也就是说我们函数括弧“{}”中定义的变量(但不包括static声明的变量,static意味着在数据段中存放变量),由编译器自动分配和释放,通常在函数执行完后就释放了,其操作方式类似于数据结构中的栈。除此以外,在函数被调用时,其参数也会被压入发起调用的进程栈中,并且待到调用结束后,函数的返回值也会被存放回栈中。由于栈的先进先出(FIFO)特点,所以栈特别方便用来保存/恢复调用现场。从这个意义上讲,我们可以把堆栈看成一个寄存、交换临时数据的内存区。包含在SRAM中
2.堆(heap)
堆是用于存放程序运行中被动态分配的内存段,它的大小并不固定,可动态扩张或缩减,需要用程序区释放。也就是常说的用malloc,calloc, realloc 等函数分配的变量空间是在堆上。当程序调用malloc等函数分配内存时,新分配的内存就被动态添加到堆上(堆被扩张);当利用free等函数释放内存时,被释放的内存从堆中被剔除(堆被缩减)。“内存泄漏”通常说的就是堆区。包含在单片机的SRAM空间内
3.静态区(Initialized data segment/Data segment)
全局变量和静态变量的存储是放在一块的,初始化的全局变量和静态变量在一块区域,未初始化的全局变量和未初始化的静态变量在相邻的另一块区域。程序结束后,由系统释放。包含在SRAM中
4.常量区
存放常量的区域、程序运行过程中不可被更改的量、只读区域、包含在ROM中
5.代码区(CodeSegment/Text Segment,代码段)
通常是指用来存放程序执行代码的一块内存区域,也就是存放CPU执行的机器指令(machineinstructions)。这部分区域的大小在程序运行前就已经确定,并且内存区域通常属于只读(某些架构也允许代码段为可写,即允许修改程序)。在代码段中,也有可能包含一些只读的常数变量,例如字符串常量等。存储在ROM中

注:BSS段(BlockStarted by Symbol):BSS段通常是指用来存放程序中未初始化的全局变量的一块内存区域。BSS段属于静态内存分配。
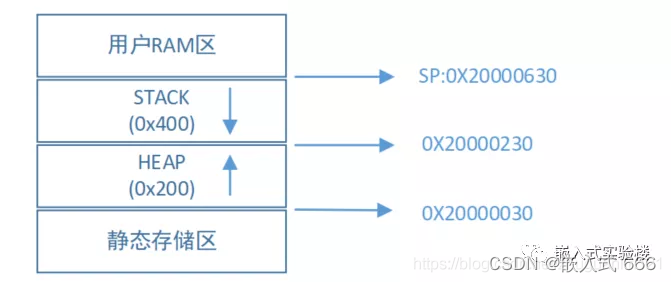
注:
栈:向低地址扩展,堆:向高地址扩展。如果依次定义变量,先定义的栈变量的内存地址比后定义的栈变量的内存地址要大,先定义的堆变量的内存地址比后定义的堆变量的内存地址要小。
6.计算机的内存管理方式
①、自动存储:
1.函数内部定义的常规常量使用自动存储空间,该变量称为自动变量 (局部变量)。
2.调用函数时产生(进栈),函数结束时消亡(出栈)。后进先出(LIFO)。因此在一个函数块中,该区域将不断的
增大或者减小。
3.该区域我们一般称为栈区。
②、静态存储:
1.静态存储是一种整个程序执行期间都存在的存储方式。
2.定义该变量的方式有两种:在函数外面定义它/在声明变量时使用关键字:static。
③、动态存储:
1 new(malloc)和delete(free)运算符(函数)提供了一种比自动变量和静态变量更加灵活的方法。
2.它们管理了一个内存池,这在C++中被称为自由存储空间或堆(heap)。
3.这种存储方式独立于另外两种,可以由程序员决定变量的产生和消亡。
我们大可以把这三个区域理解成stm32的SRAM存储区。
7.stm32的内存架构
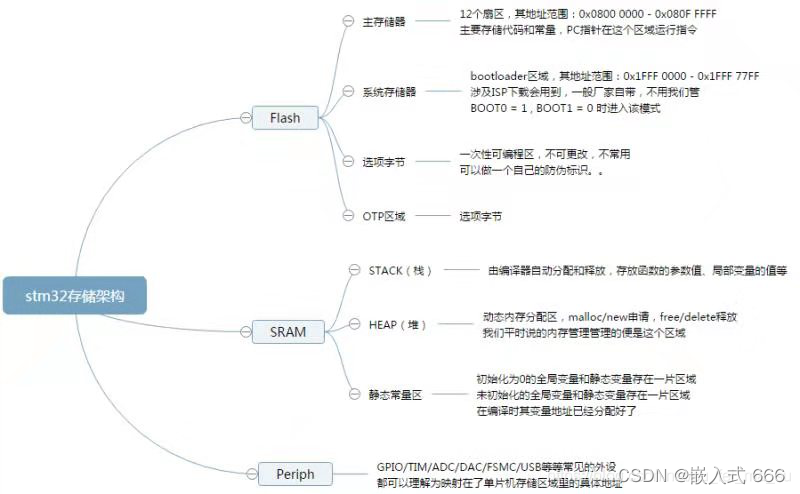
STM32大都属于Cortex-M系列的处理器,可以对32的存储器进行寻址,因此存储器的寻址空间能够达到4G,这就意味着指令和数据共用相同的地址空间,也就是将程序存储器、数据存储器、寄存器和输入输出端口被组织在同一个4GB的线性地址空间内。数据字节以小端格式存放在存储器中。一个字里的最低地址字节被认为是该字的最低有效字节,而最高地址字节是最高有效字节。ST将4GB空间分成8个块,每个块512MB,如下图所示:


8.c语言中__align()关键字的作用
__align(n):__align 关键字指示编译器在 n 字节边界上对齐变量。__align 是一个存储类修饰符。它不影响函数的类型。其中:n是对齐边界。对于局部变量,n 值可为 1、2、4 或 8。对于全局变量,n 可以具有最大为 2 的 0x80000000 次幂的任何值。__align 关键字紧靠变量名称前面放置。
__attribute __((align(n))), 如果n大于此结构体中小大基本数据类型size,那么依据最大基本数据类型size对齐;否则,依据n进行对齐;
在数组中我们用__align(32)关键字修饰,则这个数组的首地址在32字节的边界上(以空间换时间)
9.小端格式和大端格式(Little-Endian&Big-Endian)
(1)字节序
字节序,也就是字节的顺序,指的是多字节的数据在内存中的存放顺序。在几乎所有的机器上,多字节对象都被存储为连续的字节序列。
(2)LE(Little-Endian)
地址低位存储值的低位,地址高位存储值的高位。x86系列,VAX,PDP-11等处理器采用Little0Endian方式存储数据。举个例子:在内存中双字0x01020304(DWORD)和0x1234abcd的存储方式。

(3) BE(Big-Endian)
地址低位存储值的高位,地址高位存储值的低位。Motorola 6800,PowerPC 970,SPARC(除V9外)等处理器采用Big-Endian方式存储数据。举个例子:在内存中双字0x01020304(DWORD)和0x1234abcd的存储方式。

注:每个地址存1个字节,每个字有4个字节。2位16进制数是1个字节(0xFF=11111111)。
10.STM32的SRAM
不同类型的STM32单片机的SRAM大小是不一样的,但起始地址都是0x2000 0000,终止地址都是0x2000 0000+其固定的容量大小。
SRAM的理解比较简单,其作用是用来存取各种动态的输入输出数据、中间计算结果以及与外部存储器交换的数据和暂存数据。设备断电后,SRAM中存储的数据就会丢失。
11.STM32的Flash
STM32的Flash,严格说,应该是Flash模块。该Flash模块包括:Flash主存储区(Main memory)、Flash信息区(Informationblock),以及Flash存储接口寄存器区(Flash memory interface)。三个组成部分分别在0x0000 0000——0xFFFF FFFF不同的区域,如下表所示。

STM32的闪存模块由:主存储器、信息块和闪存储器块3部分组成。
主存储器,该部分用来存放代码和数据常数(如加const类型的数据)。对于大容量产品,其被划分为256页,每页2K,注意,小容量和中容量产品则每页只有1K字节。主存储起的起始地址为0X08000000,B0、B1都接GND的时候,就从0X08000000开始运行代码。
信息块,该部分分为2个部分,其中启动程序代码,是用来存储ST自带的启动程序,用于串口下载,当B0接3.3V,B1接GND时,运行的就这部分代码,用户选择字节,则一般用于配置保护等功能。
闪存储器块,该部分用于控制闪存储器读取等,是整个闪存储器的控制机构。
对于主存储器和信息块的写入有内嵌的闪存编程管理;编程与擦除的高压由内部产生。在执行闪存写操作时,任何对闪存的读操作都会锁定总线,在写完成后才能正确进行,在进行读取或擦除操作时,不能进行代码或者数据的读取操作。
12.STM32程序占用ROM(FLASH)和RAM的大小分析

Code代表执行的代码,程序中所有的函数都位于此处。即上述的text段。
RO-data(Read Only)代表只读数据,程序中所定义的全局常量数据和字符串都位于此处,如const型。
RW-data(Read Write)代表已初始化的读写数据,程序中定义并且初始化的全局变量和静态变量位于此处。
ZI-data(Zero Initialize)代表未初始化的读写数据,程序中定义了但没有初始化的全局变量和静态变量位于此处。Keil编译器默认是把你没有初始化的变量都赋值为例0。即上述的bss段。
值得注意的是,这些参数的单位是Byte。
Code和RO-Data两个段统称为RO段,它们和RW段,需要烧录到FLASH等非易失性器件中。
RW段需要烧录到FLASH中,而ZI段则不用,但在运行时,它们都必须装载到可读可写的RAM中。
因此我们可以计算出FLASH和RAM的大小:
Flash = Code + RO Data + RW Data
RAM = RW-data + ZI-data
参考
1.内存管理















 1057
1057











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









