







 文章描述了Kubernetes(k8s)集群中证书过期导致的无法连接节点的问题,以及相应的解决步骤。首先备份kubernetes配置,然后使用kubeadm检查和更新证书。虽然证书已成功更新,但后续出现认证错误。通过更新$HOME/.kube/config文件并重启kubelet,以及kube-apiserver、kube-controller-manager、kube-scheduler等服务,最终解决了所有问题,使集群恢复正常运行。
文章描述了Kubernetes(k8s)集群中证书过期导致的无法连接节点的问题,以及相应的解决步骤。首先备份kubernetes配置,然后使用kubeadm检查和更新证书。虽然证书已成功更新,但后续出现认证错误。通过更新$HOME/.kube/config文件并重启kubelet,以及kube-apiserver、kube-controller-manager、kube-scheduler等服务,最终解决了所有问题,使集群恢复正常运行。
一、问题:k8s证书过期
[root@nb001 ~]# kubectl get node
Unable to connect to the server: x509: certificate has expired or is not yet valid: current time 2022-12-10T10:26:21+08:00 is after 2022-12-10T01:55:52Z
二、解决方案:
2.1 处理步骤
# 备份 kubernetes配置
cp -r /etc/kubernetes /etc/kubernetes_bak
# 检测证书过期
kubeadm certs check-expiration
# 更新证书
kubeadm certs renew all
2.2 处理步骤详细情况
[root@nb001 ~]# kubeadm certs check-expiration
[check-expiration] Reading configuration from the cluster...
[check-expiration] FYI: You can look at this config file with 'kubectl -n kube-system get cm kubeadm-config -o yaml'
[check-expiration] Error reading configuration from the Cluster. Falling back to default configuration
CERTIFICATE EXPIRES RESIDUAL TIME CERTIFICATE AUTHORITY EXTERNALLY MANAGED
admin.conf Dec 10, 2022 01:55 UTC <invalid> no
apiserver Dec 10, 2022 01:55 UTC <invalid> ca no
apiserver-etcd-client Dec 10, 2022 01:55 UTC <invalid> etcd-ca no
apiserver-kubelet-client Dec 10, 2022 01:55 UTC <invalid> ca no
controller-manager.conf Dec 10, 2022 01:55 UTC <invalid> no
etcd-healthcheck-client Dec 10, 2022 01:55 UTC <invalid> etcd-ca no
etcd-peer Dec 10, 2022 01:55 UTC <invalid> etcd-ca no
etcd-server Dec 10, 2022 01:55 UTC <invalid> etcd-ca no
front-proxy-client Dec 10, 2022 01:55 UTC <invalid> front-proxy-ca no
scheduler.conf Dec 10, 2022 01:55 UTC <invalid> no
CERTIFICATE AUTHORITY EXPIRES RESIDUAL TIME EXTERNALLY MANAGED
ca Dec 08, 2031 01:55 UTC 8y no
etcd-ca Dec 08, 2031 01:55 UTC 8y no
front-proxy-ca Dec 08, 2031 01:55 UTC 8y no
如上,发现很多证书都是<invalid>的状态,接着更新证书:
[root@nb001 .kube]# kubeadm certs renew all
[renew] Reading configuration from the cluster...
[renew] FYI: You can look at this config file with 'kubectl -n kube-system get cm kubeadm-config -o yaml'
[renew] Error reading configuration from the Cluster. Falling back to default configuration
certificate embedded in the kubeconfig file for the admin to use and for kubeadm itself renewed
certificate for serving the Kubernetes API renewed
certificate the apiserver uses to access etcd renewed
certificate for the API server to connect to kubelet renewed
certificate embedded in the kubeconfig file for the controller manager to use renewed
certificate for liveness probes to healthcheck etcd renewed
certificate for etcd nodes to communicate with each other renewed
certificate for serving etcd renewed
certificate for the front proxy client renewed
certificate embedded in the kubeconfig file for the scheduler manager to use renewed
Done renewing certificates. You must restart the kube-apiserver, kube-controller-manager, kube-scheduler and etcd, so that they can use the new certificates.
[root@nb001 .kube]# kubectl get node
Unable to connect to the server: x509: certificate has expired or is not yet valid: current time 2022-12-10T10:33:16+08:00 is after 2022-12-10T01:55:52Z
如下,更新证书后,证书过期时间已经更新为365d
[root@nb001 .kube]# kubeadm certs check-expiration
[check-expiration] Reading configuration from the cluster...
[check-expiration] FYI: You can look at this config file with 'kubectl -n kube-system get cm kubeadm-config -o yaml'
[check-expiration] Error reading configuration from the Cluster. Falling back to default configuration
CERTIFICATE EXPIRES RESIDUAL TIME CERTIFICATE AUTHORITY EXTERNALLY MANAGED
admin.conf Dec 10, 2023 02:33 UTC 364d no
apiserver Dec 10, 2023 02:33 UTC 364d ca no
apiserver-etcd-client Dec 10, 2023 02:33 UTC 364d etcd-ca no
apiserver-kubelet-client Dec 10, 2023 02:33 UTC 364d ca no
controller-manager.conf Dec 10, 2023 02:33 UTC 364d no
etcd-healthcheck-client Dec 10, 2023 02:33 UTC 364d etcd-ca no
etcd-peer Dec 10, 2023 02:33 UTC 364d etcd-ca no
etcd-server Dec 10, 2023 02:33 UTC 364d etcd-ca no
front-proxy-client Dec 10, 2023 02:33 UTC 364d front-proxy-ca no
scheduler.conf Dec 10, 2023 02:33 UTC 364d no
CERTIFICATE AUTHORITY EXPIRES RESIDUAL TIME EXTERNALLY MANAGED
ca Dec 08, 2031 01:55 UTC 8y no
etcd-ca Dec 08, 2031 01:55 UTC 8y no
front-proxy-ca Dec 08, 2031 01:55 UTC 8y no
三、新的问题①及解决方案
3.1 再次查看kubectl get node,发现有新的错误:error: You must be logged in to the server (Unauthorized)
[root@nb001 .kube]# kubectl get node
error: You must be logged in to the server (Unauthorized)
3.2 上述错误解决方案
- 备份配置文件
cp -rp $HOME/.kube/config $HOME/.kube/config.bak,并生成新的配置文件sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config - 执行
kubectl get node查看解决结果
详情如下:
[root@nb001 .kube]# cd /etc/kubernetes
[root@nb001 kubernetes]# ls
admin.conf controller-manager.conf kubelet.conf manifests pki scheduler.conf
[root@nb001 kubernetes]# cd $HOME/.kube/
[root@nb001 .kube]# ls
cache config
[root@nb001 .kube]# cp -rp config config.bak
[root@nb001 .kube]# ls
cache config config.bak
[root@nb001 .kube]# sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
cp: overwrite ‘/root/.kube/config’? y
[root@nb001 .kube]# ls -lrth
total 20K
-rw------- 1 root root 5.5K Dec 10 2021 config.bak
drwxr-x--- 4 root root 4.0K Dec 10 2021 cache
-rw------- 1 root root 5.5K Dec 10 10:35 config
[root@nb001 .kube]# kubectl get node
NAME STATUS ROLES AGE VERSION
nb001 Ready control-plane,master 365d v1.21.5
nb002 Ready <none> 365d v1.21.5
nb003 Ready <none> 241d v1.21.5
四、新的问题②及解决方案
4.1 上述问题解决后,执行kubectl apply、kubectl create命令可以正常执行,但无法实际操作资源
换句话说:就是执行了,但没生效
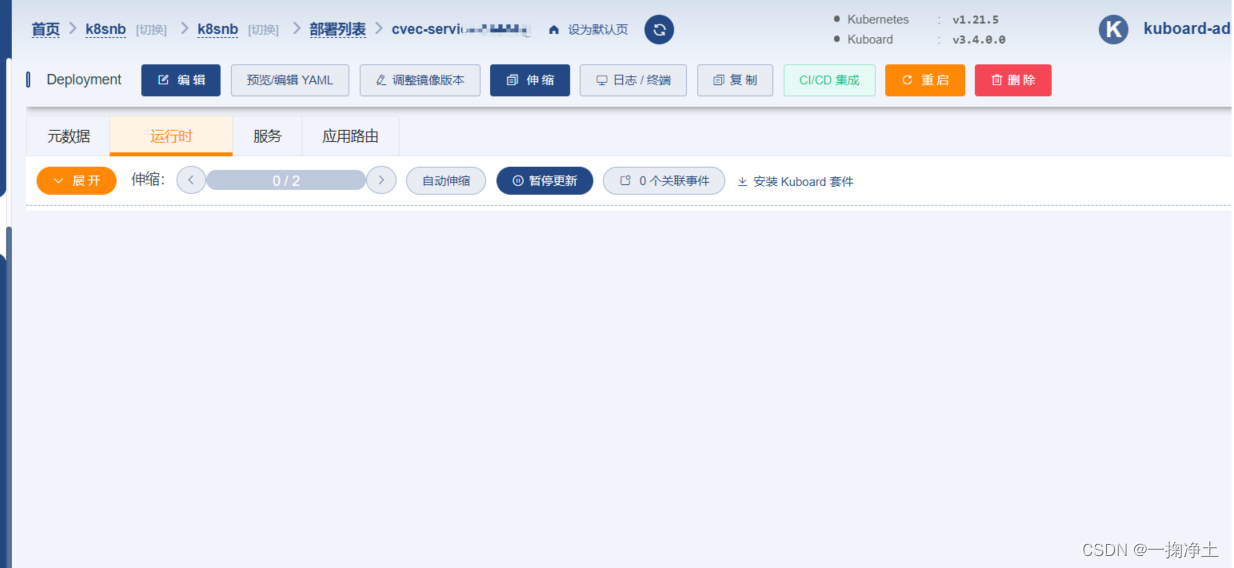
举例: 比如你更新 service-user.yaml 调整了镜像版本,想重新部署下user服务。执行kubectl apply -f service-user.yaml ,但实际pod还是上次部署的pod,并没有重新部署。其余不生效的情况类似。
此外:在kuboard上的表现如下图,都是空的:
4.2 解决方案
- 重启kubelet
systemctl restart kubelet
- 重启kube-apiserver、kube-controller-manage、kube-scheduler
# 如果是docker作为容器的话,可执行如下命令。其余容器方法类似
docker ps |grep kube-apiserver|grep -v pause|awk '{print $1}'|xargs -i docker restart {}
docker ps |grep kube-controller-manage|grep -v pause|awk '{print $1}'|xargs -i docker restart {}
docker ps |grep kube-scheduler|grep -v pause|awk '{print $1}'|xargs -i docker restart {}
- 重新部署user服务即可
至此,由于k8s证书过期引起的问题得到彻底解决。



















 1610
1610

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











